
JavaWeb XML详解 解析XML
温馨提示:这篇文章已超过392天没有更新,请注意相关的内容是否还可用!
XML
XML的全称是EXtensible Markup Language,可扩展标记语言编写,XML就是编写标签,与HTML非常类似,扩展名.xml。拥有良好的人机可读性。
用途:
- Java程序的配置描述文件
- 用于保存程序产生的数据
- 网络间的数据传输
XML和HTML的区别
- XML与HTML非常相似,都是编写标签,XML的语法严格,HTML语法松散
- XML没有预定义标签,HTML存在大量预定义标签
- XML重在保存与传输数据,HTML用于显示信息
XML文档结构
- 第一行必须是XML声明
- 有且只有一个根节点
- XML标签的书写规则与HTML相同
XML声明
XML声明说明XML文档的基本信息,包括版本号与字符集,写在XML第一行。
- version:代表版本号1.0/1.1
- encoding:UTF-8设置字符集,用于支持中文
- standalone:是否独立
- yes:不依赖其他文件
- no:依赖其他文件
XML标签书写规则
合法的标签名
- 标签名要有意义
- 建议使用英文小写字母,单词之间使用 - 分割
- 建议多级标签之间不要存在重名的情况
适当的注释与缩进
- 适当的注释与缩进可以让XML文档更容易阅读
合理使用属性
- 标签属性用于描述标签不可或缺的信息
- 对标签分组或为标签设置ID时常用属性表示
有序的子元素
- 在XML多层嵌套的子元素中,标签前后顺序应保持一致
特殊字符与CDATA标签
- 标签体中,出现 特殊字符,会破坏文档结构
- 使用实体引用或者CDATA标签
实体引用 对应符号 说明 < 大于 & & 和号 ' ' 单引号 " " 双引号 CDATA 指的是不应由 XML 解析器进行解析的文本数据,从 结束
张三 30 4000 市场部 xx大厦-B1003 李四 28 5000 财务部 xx大厦-B1004XML语义约束
XML文档结构正确,但可能不是有效的。XML语义约束有两种定义方式:DTD与XML Schema。
DTD约束
DTD(Document Type Definition,文档类型定义)是一种简单易用的语义约束方式,DTD文件的扩展名为.dtd。
DTD定义节点
利用DTD中的标签,可以定义XML文档中允许出现的节点及数量:
- employee>:定义hr节点下只允许出现1个employee子节点
- :节点下必须包含以下四个节点,且按顺序出现
- :定义name标签体只能是文本,#PCDATA代表文本元素
如某个子节点需要多次重复出现,则需要在子节点后增加相应的描述符:
- :hr节点下最少出现1个employee子节点
- :hr节点下可出现0…n个employee子节点
- :hr节点下最多出现1个employee子节点
XML引用DTD
在XML中使用标签来引用DTD文件:
- :本地引用
- :网络引用
Schema约束
XML Schema比DTD更为复杂,提供了数据类型、格式限定、数据范围等特性,是 W3C 标准。
- :引入
定义约束:
解析XML
解析xml的方式
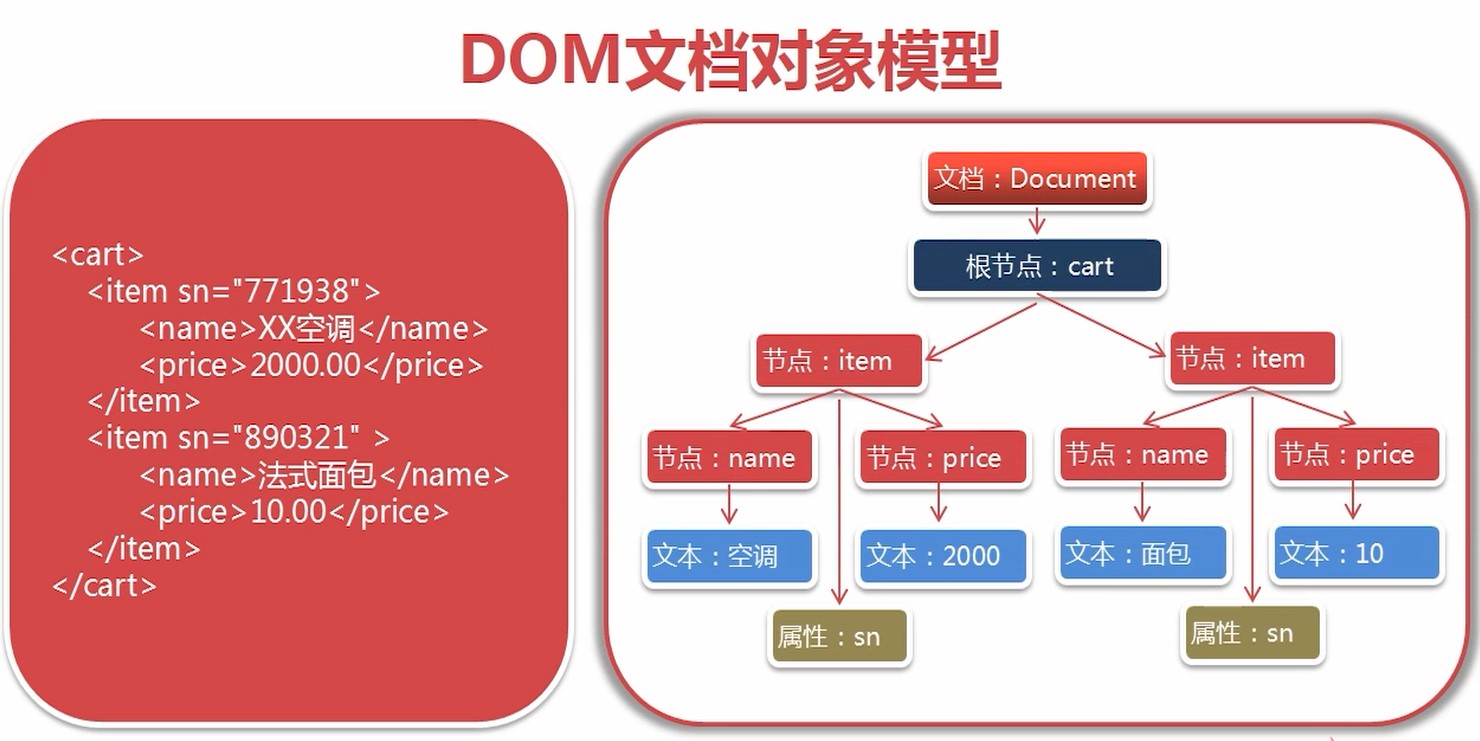
DOM
将标记语言文档一次性加载进内存,在内存中形成一颗dom树
- 优点: 操作方便,可以对文档进行CRUD的所有操作
- 缺点: 占内存
SAX
逐行读取,基于事件驱动的
- 优点: 不占内存
- 缺点: 只能读取,不能增删改
xml常见的解析器
JAXP:
sun公司提供的解析器,支持dom和sax两种思想。
DOM4J:
是一个易用的、开源的库,用于解析XML。它应用于Java平台,具有性能优异、功能强大和极其易使用的特点。Dom4j将XML视为Document对象,XML标签被Dom4j定义为Element对象。
Jsoup:
是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
PULL:
Android操作系统内置的解析器,sax方式的。
DOM4J
是一个易用的、开源的库,用于解析XML。它应用于Java平台,具有性能优异、功能强大和极其易使用的特点。Dom4j将XML视为Document对象,XML标签被Dom4j定义为Element对象。
需要JDK1.8以上
下载地址:https://dom4j.github.io/
读取XML文档
/** * 描述:通过DOM4J读取xml文件 */ public class HrReader { public void readXML() { String file = "E:\\IdeaProjects\\study\\xml-study\\src\\hr.xml"; // SAXReader类是读取XML文件的核心类,用于将XML解析后以树的形式保存在内存中。 SAXReader reader = new SAXReader(); try { Document document = reader.read(file); // 获取XML文档的根节点,就是
标签 Element rootElement = document.getRootElement(); // 用于获取指定标签的集合 List elementList = rootElement.elements("employee"); for (Element employee : elementList) { // 用于获取element唯一子节点 Element name = employee.element("name"); // 用于获取标签中的文本 String nameText = name.getText(); System.out.print("姓名:" + nameText); System.out.print(",年龄:" + employee.elementText("age")); System.out.print(",工资:" + employee.elementText("salary")); // 获取节点 Element department = employee.element("department"); String dname = department.element("dname").getText(); System.out.print(",部门:" + dname); System.out.print(",工作地点:" + department.elementText("address")); // 获取属性 Attribute att = employee.attribute("no"); String no = att.getText(); System.out.println(",工号:" + no); } } catch (DocumentException e) { e.printStackTrace(); } } public static void main(String[] args) { HrReader hrReader = new HrReader(); hrReader.readXML(); } }更新XML文档
/** * 描述:通过DOM4J更新xml文件 */ public class HrWriter { public void writeXML(){ String file = "E:\\IdeaProjects\\study\\xml-study\\src\\hr.xml"; SAXReader reader = new SAXReader(); try { Document document = reader.read(file); Element rootElement = document.getRootElement(); // 创建一个属于rootElement对象的employee节点 Element employee = rootElement.addElement("employee"); // 创建no属性 employee.addAttribute("no", "3311"); // 创建一个属于employee对象的name节点 Element name = employee.addElement("name"); // 设置name节点的值 name.setText("王五"); employee.addElement("age").setText("22"); employee.addElement("salary").setText("3500"); Element department = employee.addElement("department"); department.addElement("dname").setText("市场部"); department.addElement("address").setText("xx大厦-B1003"); // 创建字符输出流 Writer writer = new OutputStreamWriter(new FileOutputStream(file), "UTF-8"); // 将创建的节点写入文件中 document.write(writer); writer.close(); } catch (Exception e) { e.printStackTrace(); } } public static void main(String[] args) { HrWriter hrWriter = new HrWriter(); hrWriter.writeXML(); } }Jsoup
Jsoup是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
- 导入jar包
- 获取Document对象
- 获取对应的标签Element对象
- 获取数据
//2.1获取student.xml的path String path = JsoupDemo1.class.getClassLoader().getResource("student.xml").getPath(); //2.2解析xml文档,加载文档进内存,获取dom树--->Document Document document = Jsoup.parse(new File(path), "utf-8"); //3.获取元素对象 Element Elements elements = document.getElementsByTag("name"); System.out.println(elements.size()); //3.1获取第一个name的Element对象 Element element = elements.get(0); //3.2获取数据 String name = element.text(); System.out.println(name);Jsoup类
工具类,可以解析html或xml文档,返回Document
- parse:解析html或xml文档,返回Document
- parse(File in, String charsetName):解析xml或html文件的。
- parse(String html):解析xml或html字符串
- parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
Document类
文档对象。代表内存中的dom树。
获取Element对象:
- getElementById(String id):根据id属性值获取唯一的element对象
- getElementsByTag(String tagName):根据标签名称获取元素对象集合
- getElementsByAttribute(String key):根据属性名称获取元素对象集合
- getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
Elements类
元素Element对象的集合。可以当做 ArrayList 来使用
Element类
元素对象
获取子元素对象:
- getElementById(String id):根据id属性值获取唯一的element对象
- getElementsByTag(String tagName):根据标签名称获取元素对象集合
- getElementsByAttribute(String key):根据属性名称获取元素对象集合
- getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
获取属性值:
- String attr(String key):根据属性名称获取属性值
获取文本内容:
- String text():获取文本内容
- String html():获取标签体的所有内容(包括字标签的字符串内容)
Node类
节点对象,是Document和Element的父类
快捷查询方式
selector: 选择器
- 使用的方法:Elements select(String cssQuery)
- 语法:参考Selector类中定义的语法
XPath: XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言
- 使用Jsoup的Xpath需要额外导入jar包。
- 查询w3cshool参考手册,使用xpath的语法完成查询
//1.获取student.xml的path String path = JsoupDemo6.class.getClassLoader().getResource("student.xml").getPath(); //2.获取Document对象 Document document = Jsoup.parse(new File(path), "utf-8"); //3.根据document对象,创建JXDocument对象 JXDocument jxDocument = new JXDocument(document); //4.结合xpath语法查询 //4.1查询所有student标签 List jxNodes = jxDocument.selN("//student"); for (JXNode jxNode : jxNodes) { System.out.println(jxNode); } System.out.println("--------------------"); //4.2查询所有student标签下的name标签 List jxNodes2 = jxDocument.selN("//student/name"); for (JXNode jxNode : jxNodes2) { System.out.println(jxNode); } System.out.println("--------------------"); //4.3查询student标签下带有id属性的name标签 List jxNodes3 = jxDocument.selN("//student/name[@id]"); for (JXNode jxNode : jxNodes3) { System.out.println(jxNode); } System.out.println("--------------------"); //4.4查询student标签下带有id属性的name标签 并且id属性值为itcast List jxNodes4 = jxDocument.selN("//student/name[@id='itcast']"); for (JXNode jxNode : jxNodes4) { System.out.println(jxNode); }XPath 查找XML数据
XPath路径表达式是XML文档中查找数据的语言,可以极大的提高在提取数据时的开发效率。
参考:https://www.w3school.com.cn/xpath/index.asp
- String attr(String key):根据属性名称获取属性值
- :引入
- 在XML多层嵌套的子元素中,标签前后顺序应保持一致
- 适当的注释与缩进可以让XML文档更容易阅读



