
2022年数学建模国赛C题完整思路
目录
一、古代玻璃制品的成分分析与鉴别
二、整体思路
1.问题一
2.问题二
3.问题三
4.问题四
三、模型建立
1.问题一
(1)预处理
(2)建立
2.问题二
(1)预处理
(2)建立
3.问题三
1.线性回归模型建立
2.分类结果的敏感性分析
4.问题四
总结
一、古代玻璃制品的成分分析与鉴别
C题:古代玻璃制品的成分分析与鉴别
丝绸之路是古代中西方文化交流的通道,其中玻璃是早期贸易往来的宝贵物证。早期的玻璃在西亚和埃及地区常被制作成珠形饰品传入我国,我国古代玻璃吸收其技术后在本土就地取材制作,因此与外来的玻璃制品外观相似,但化学成分却不相同。
玻璃的主要原料是石英砂,主要化学成分是二氧化硅(SiO2)。由于纯石英砂的熔点较高,为了降低熔化温度,在炼制时需要添加助熔剂。古代常用的助熔剂有草木灰、天然泡碱、硝石和铅矿石等,并添加石灰石作为稳定剂,石灰石煅烧以后转化为氧化钙(CaO)。添加的助熔剂不同,其主要化学成分也不同。例如,铅钡玻璃在烧制过程中加入铅矿石作为助熔剂,其氧化铅(PbO)、氧化钡(BaO)的含量较高,通常被认为是我国自己发明的玻璃品种,楚文化的玻璃就是以铅钡玻为主。钾玻璃是以含钾量高的物质如草木灰作为助熔剂烧制而成的,主要流行于我国岭南以及东南亚和印度等区域。
古代玻璃极易受埋藏环境的影响而风化。在风化过程中,内部元素与环境元素进行大量交换,导致其成分比例发生变化,从而影响对其类别的正确判断。如图 1 的文物标记为表面无风化,表面能明显看出文物的颜色、纹饰,但不排除局部有较浅的风化;图 2 的文物标记为表面风化,表面大面积灰黄色区域为风化层,是明显风化区域,紫色部分是一般风化表面。在部分风化的文物中,其表面也有未风化的区域。
现有一批我国古代玻璃制品的相关数据,考古工作者依据这些文物样品的化学成分和其他检测手段已将其分为高钾玻璃和铅钡玻璃两种类型。附件表单 1 给出了这些文物的分类信息,附件表单 2 给出了相应的主要成分所占比例(空白处表示未检测到该成分)。这些数据的特点是成分性,即各成分比例的累加和应为 100%,但因检测手段等原因可能导致其成分比例的累加和非 100%的情况。本题中将成分比例累加和介于 85%~105%之间的数据视为有效数据。

请你们团队依据附件中的相关数据进行分析建模,解决以下问题:
问题 1 对这些玻璃文物的表面风化与其玻璃类型、纹饰和颜色的关系进行分析;结合玻璃的类型,分析文物样品表面有无风化化学成分含量的统计规律,并根据风化点检测数据,预测其风化前的化学成分含量。
问题 2 依据附件数据分析高钾玻璃、铅钡玻璃的分类规律;对于每个类别选择合适的化学成分对其进行亚类划分,给出具体的划分方法及划分结果,并对分类结果的合理性和敏感性进行分析。
问题 3 对附件表单 3 中未知类别玻璃文物的化学成分进行分析,鉴别其所属类型,并对分类结果的敏感性进行分析。
问题 4 针对不同类别的玻璃文物样品,分析其化学成分之间的关联关系,并比较不同类别之间的化学成分关联关系的差异性。
二、整体思路
1.问题一
对表单一中的数据进行处理:补全缺失值并对数据进行简化和量化;剔除表单2中的无效数据,将表单1的纹饰、类型、颜色和表面风化与表单2文物采样点的数据对应起来。
要研究表面分化和纹饰,颜色,类型相关关系,先进行卡方检验比较P值是否呈现显著性,确定分量间是否有相关性,之后才能采用SPSS建立对应分析模型,并利用散点图判断之间的关系。
结合玻璃类型分析文物样品表面有无风化化学成分含量的统计规律时,对处理的表单2的化学成分含量据计算均值和方差并进行正态性检验,得到统计性描述数据来分析化学成分含量规律。
建立移位平均模型来预测分化前的化学成分含量,分别计算高钾和铅钡玻璃化学成分风化和无分化风化的平均值,接着分别求高钾和铅钡玻璃风化和无风化的平均值的差,把各类型的差值与各个玻璃风化的化学成分数值相加,得到的数值为风化前的化学成分含量。
2.问题二
根据附件来分析高钾玻璃、铅钡玻璃的分类规律,先将表单1纹饰、类型、颜色和表面风化和表单2的数据整合在一张表中,补全颜色缺失的部分。使用CRT生长法来进行决策树分类,得出高钾、铅钡玻璃的分类规律。
对两类玻璃根据化学成分进行亚类划分,先对每个化学成分进行显著性分析并判断是否存在显著性差异,提取出具有显著性差异的化学成分,对高钾和铅钡玻璃有显著性差异的化学成分建立系统聚类模型,得出划分结果。最后使用近似值矩阵来判断分类结果的的合理性,若近似值越大,合理性越强,其敏感性通过增加或减少化学成分的含量,重新进行系统聚类,比较新,旧两种聚类结果,分析敏感性。
3.问题三
预测未知玻璃文物的类型,对已知的表单2的化学成分和类型之间的规律分析,进行显著性,正态性检验,得出数据具有线性关系,可以建立类型和化学成分之间的多元线性回归方程,基于最小二乘法,利用SPSSPRO得出回归系数,进而在给定的化学成分下,预测玻璃文物的类型。
最后对回归模型进行敏感性研究,可以通过改变回归模型中一个自变量来观察因变量的变化,预测结果变化的大小,得出敏感度系数,通过系数即可判断出敏感性程度,对分类结果的敏感性进行总结。
4.问题四
要得出每个类别的化学成分之间的关联关系,分别对两类玻璃的化学成分进行相关分析,得出相关系数结果表和相关系数热力图,针对相关系数做出成分之间的相关强度的统计图,根据以上图表总结关联关系和比较两类玻璃化学成分的差异性。
三、模型建立
1.问题一
(1)预处理
1)表单1数据的缺失处理
表单1的数据量较小,并且有部分数据缺失,如果直接删除缺失项,则可能会影响对数据的分析,因此把缺失的数据项补全,应当是定性数据且对个体精度要求不大,采取相同条件下出现次数最多的值也就是众数来补缺失值。
2)表单1数据的量化
数据量化是将一些不具体,模糊的因素用具体的数据来表示,以一定范围内线性变换的数据反映自然界或社会的状态,从而达到分析比较的目的。
3)表单2的处理
玻璃文物的化学文物成分比例介于85%~105%之间的数据为有效数据,用EXCEL对成分比例求和,按顺序排列后,剔除不符合的行。
将表单1中的类型和表面风化与表单2整合在一张表中,并进行量化 。
(2)建立
对表面风化和纹饰,颜色,类型的相关关系的分析,采用对应分析的方法。做对应分析之前,需要对交叉表进行卡方检验,只有卡方检验结果显示两个分类变量之间具有相关性,才作对应分析,如果没有,分析出的结果没有普遍性。
- 卡方检验
卡方检验(Pearson)是比较定类变量与定类变量之间的差异性分析。通过统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。
卡方检验公式:

其中:A是实际值,T为理论值,χ2就是衡量理论与实际的差异程度,χ2越大,说明定类变量之间有关系的可能性大。具体操作使用SPSSAU为分析工具。

2.对应分析
对玻璃文物的表面风化与其玻璃类型、纹饰和颜色的关系进行对应分析之前,需要先对其进行卡方检验,检验数据之间是否独立。
对应分析R型因子分析和Q型因子分析都是反应一个整体的不同侧面,因而存在一是R-Q型因子分析,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。由于定联系。对应分析就是通过对应变换后的标准化矩阵Z将两者有机地集合起来。
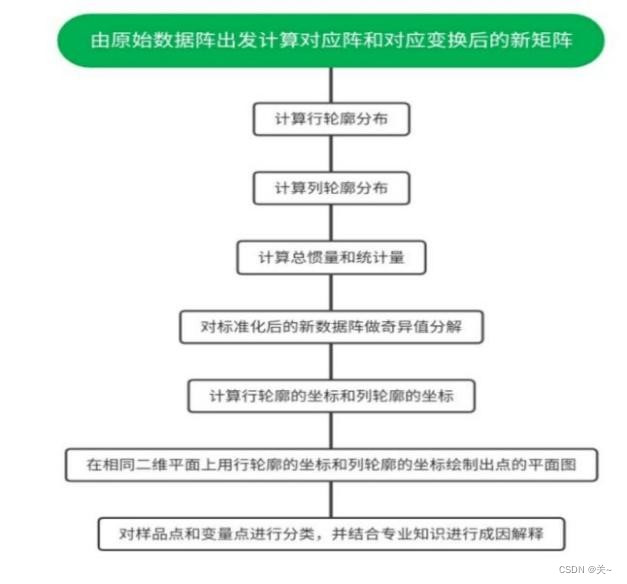
得出结论:铅钡玻璃容易风化,高钾玻璃不易风化;纹饰B容易风化,AC不易风化。
颜色的卡方检验P值过大,不易进行对应分析。根据表单1中的数据,大致得出:深蓝色和绿色不易被风化,其他颜色与表面风化得不出什么密切联系。
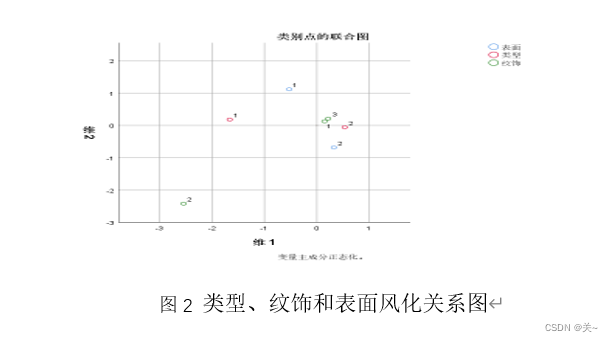
3.描述性统计
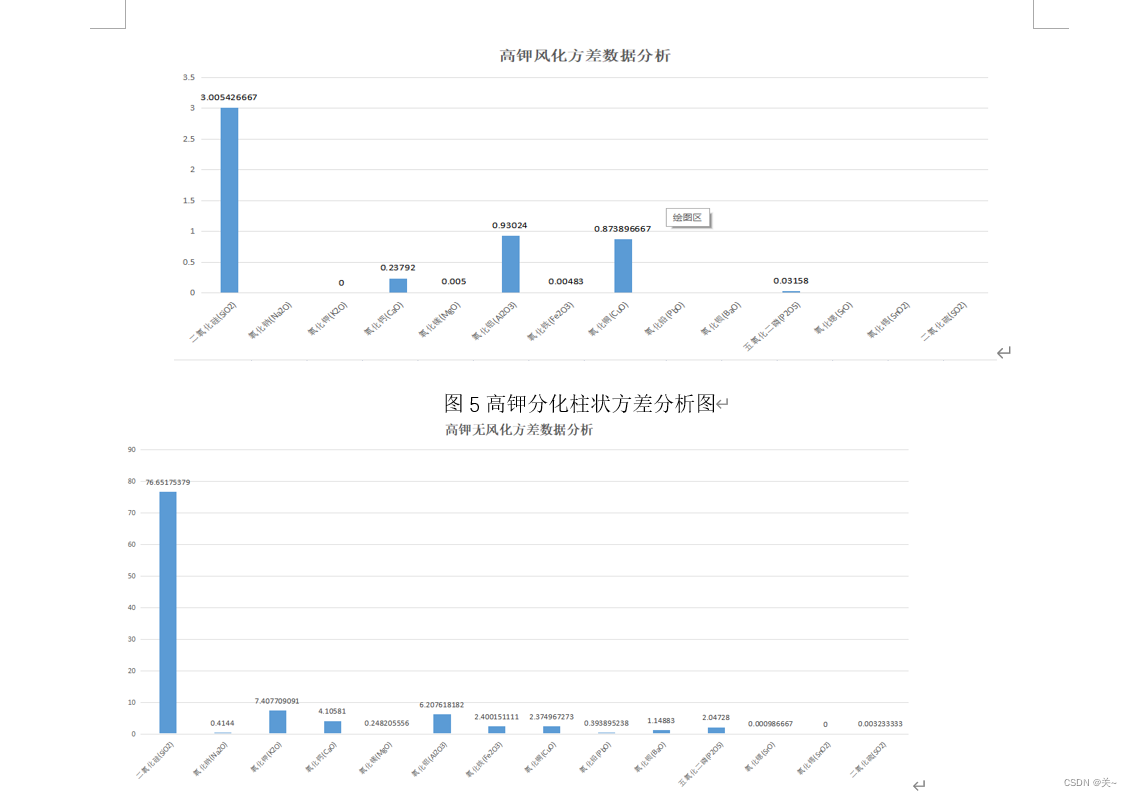
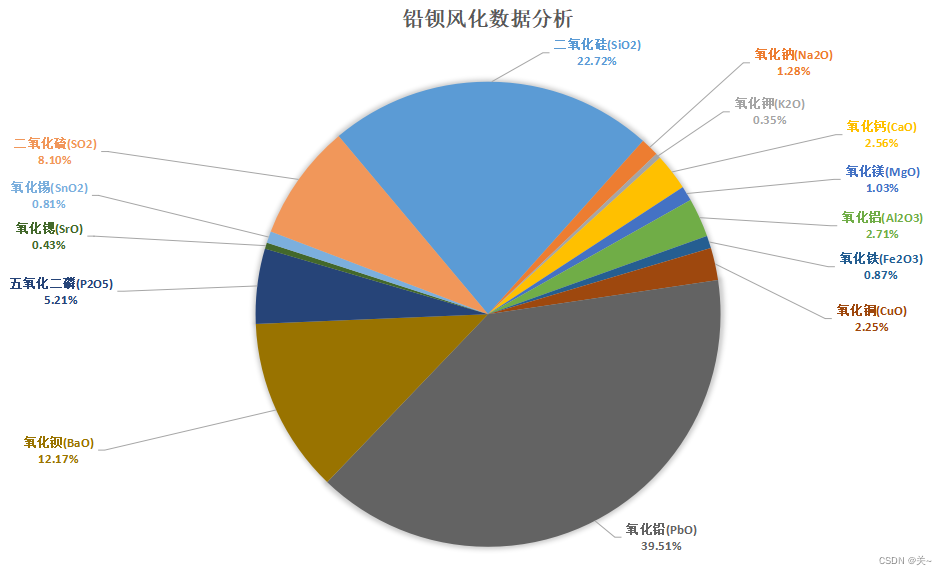
对数据计算均值和方差并进行正态性检验,得到统计性描述数据来分析化学成分含量规律。
2.问题二
(1)预处理
- 将表单1和表单2中的数据按文物编号匹配合并在同一张EXCEL表。
- 将类型和表面分化做量化处理
- 剔除不合理的数据行
(2)建立
分析高钾玻璃、铅钡玻璃的分类规律,在已知玻璃的化学成分比例下,选择建立决策树模型来找出划分两类玻璃的划分标准,具体操做如下
- 决策树分类
决策树分类依据梳理出的数据中的属性,比较按照某种特定属性划分后的数据的信息熵增益,选择信息熵增益最大的那个属性作为第一划分依据,然后继续选择第二属性,以此类推。其中信息熵越大,样本的纯度越低,信息增益=信息熵-条件熵。
决策树采用的是自顶向下的递归方法,以信息熵为度量构造一颗熵值下降最快的树,到叶子节点的熵值为0。
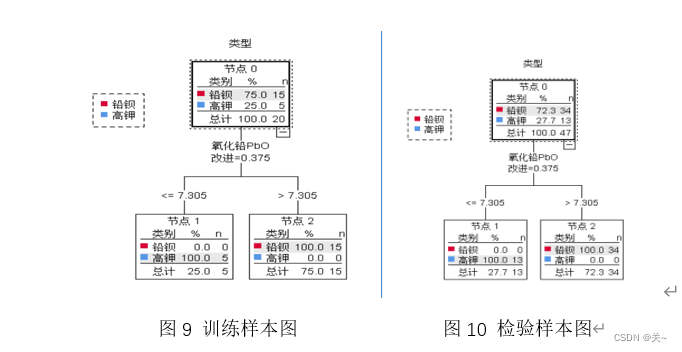
对高钾玻璃和铅钡玻璃进行亚类划分时,选用化学成分有显著性的建立系统聚类模型,得出划分结果。
2)显著性
显著性的含义是指两个群体的态度之间的任何差异是由于系统因素而不是偶然因素的影响。
这里求解分组变量的显著型差异采用事后多重比较的方法,得出方差分析结果显示哪些化学成分水平上存在显著性,将具有显著性的成分作为系统聚类分析的变量,求出亚类划分的结果。
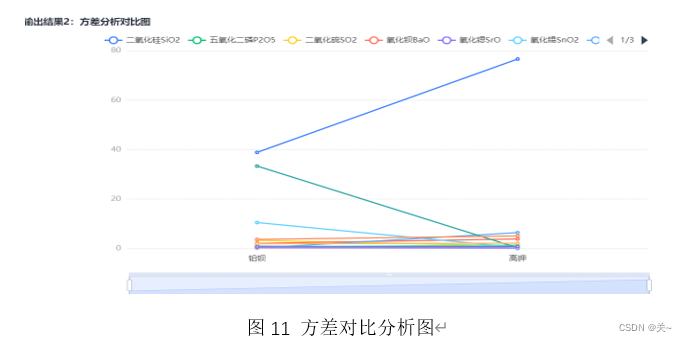
3)系统聚类
系统聚类分析(Hierarchical Cluster Analysis)的基本思想是,按照距离远近,将距离相近的变量先聚成类,距离较远的变量后聚成类,依次进行,直到每个变量都归入合适的类中。
组间平均距离连接法:合并两类的结果使所有的两两项对之间的平均距离最小
使用平方欧氏距离,将距离相近的变量聚成一类。
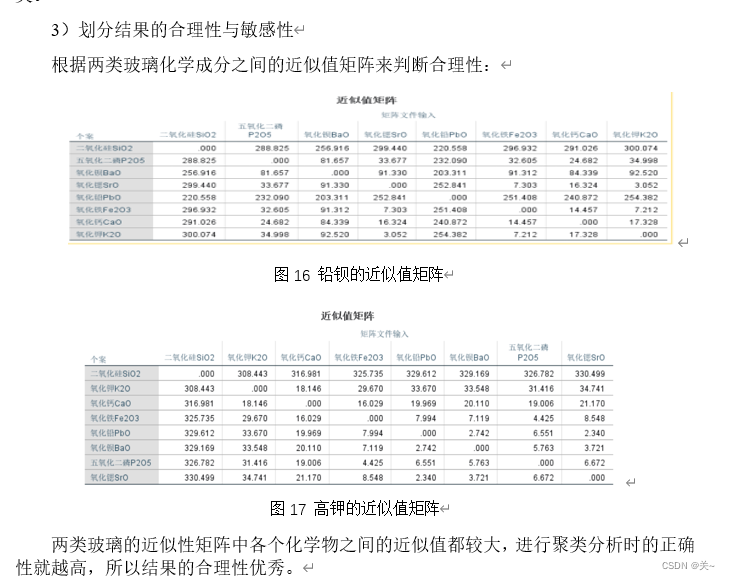
4)近似值矩阵
根据近似值矩阵,越接近0近似值越小,近似性数值越大,说明越相似,以矩阵的方式呈现分类结果的合理性。
3.问题三
1.线性回归模型建立
建立多元线性回归方程求回归因子(自变量为化学成分,因变量为玻璃类型),在给定的化学成分下,,基于最小二乘法,使用SPSSPRO建立线性回归模型,求解模型的标准化系数B,t值,VIF值,R2,调整R2等,用于模型的检验,并分析模型的公式。
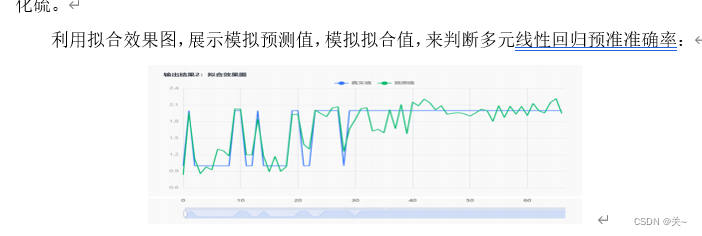
根据上图得出拟合效果优秀,预测值和真实值的偏差并不大,使用多元线性回归预测出的结果准确率高,可以去预测未知类型的文物。

2.分类结果的敏感性分析
令化学成分在可能的取值范围内变动,研究和预测化学成分的变动对模型输出值的影响程度。将影响程度的大小称为该属性的敏感性系数。敏感系数越大,说明化学成分对模型输出的影响越大。其中敏感系数数值的大小不是计算该项的目的,重要的是各不确定因素敏感系数的相对值,借此了解各不确定因素的相对影响程度,以选出敏感度较大的不确定因素,来分析结果的敏感性。
4.问题四
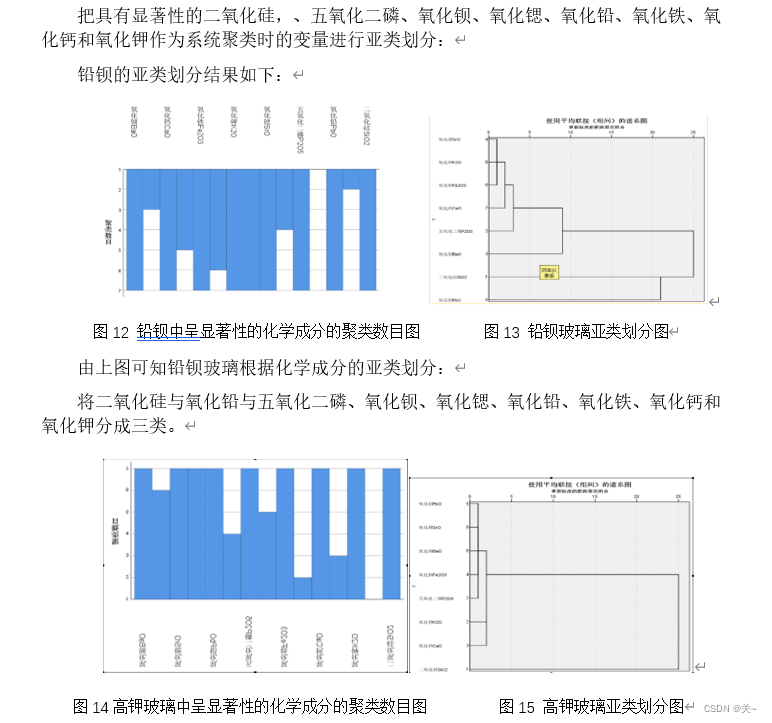
由问题四分析,分别对两类玻璃文物样品的化学成分之间的关联性进行分析,可以看作是根据一个变量与另一各变量是否大于临界值,判断两个因素是否相关,根据相关系数大小判断两个因素关系的密切程度,相关系数越大,说明两者关系约密切,因此建立相关性分析模型即可得出化学成分之间的关联性。
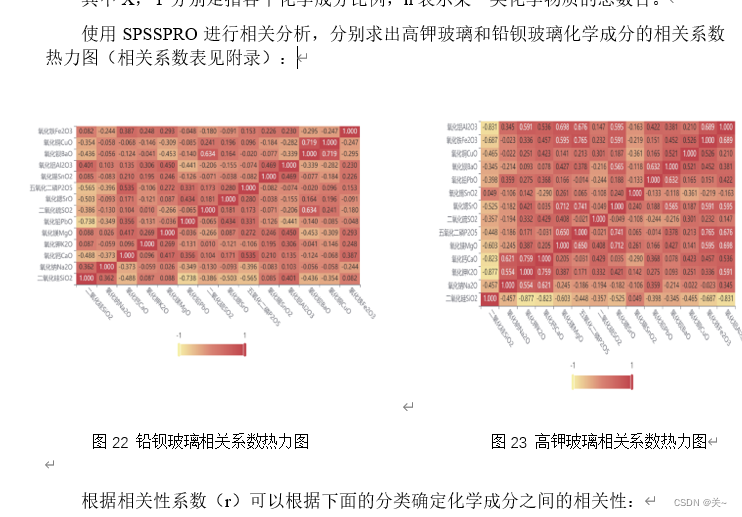
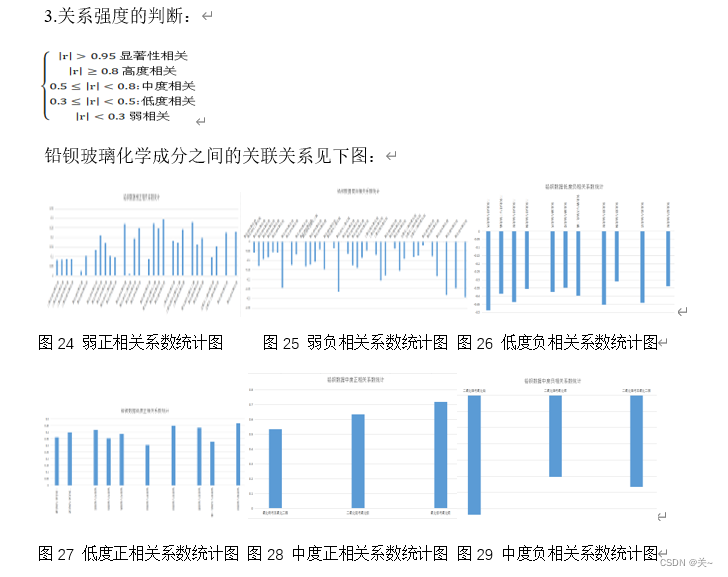
总结
以上就是今天要讲的内容,本文仅仅介绍了自己的22年数学建模c题的思路和解法模型,如有问题和疑问可在下方评论。



