
【xgboost】XGBoost
XGBoost
- p.s. 参考链接(very nice)
- 1. 原理改进及特点
- 1.1 遵循Boosting算法的基本建模流程
- 1.2 平衡精确性与复杂度
- 1.3 降低模型复杂度、提升运行效率
- 1.4 保留部份GBDT属性
- 1.5 Boosting算法的改进历程
- 2. sklearn接口(回归)
- 2.1 导库 & 数据
- 2.2 sklearn api普通训练
- 2.3 sklearn api交叉验证
- 2.4 查看属性接口
- 2.5 参数意义&调参指导(chat-gpt版)
- 3. xgboost原生代码(回归)
- 3.1 导包
- 3.2 DMatrix数据 xgboost.DMatrix()
- 3.3 params参数 params={}
- 3.4 不交叉验证 xgboost.train()
- 3.4.1 参数 & 代码
- 3.4.2 评估指标
- 3.5 交叉验证 xgboost.cv()
- 4. xgboost实现分类
- 4.1 sklearn接口
- 4.2 xgboost原生代码
p.s. 参考链接(very nice)
知乎 - xgboost的参数解释和调整
1. 原理改进及特点
1.1 遵循Boosting算法的基本建模流程
依据上一个弱评估器f(x)k-1的结果,计算损失函数L;
并使用L自适应地影响下一个弱评估器f(x)k的构建。
集成模型输出的结果,受所有弱评估器f(x)0~f(x)K的影响.
1.2 平衡精确性与复杂度
树模型的学习能力和过拟合风险需要平衡,即预测精确性与模型复杂度之间的平衡,经验风险与结构风险之间的平衡。
一般建立模型后手动剪枝调节复杂度,XGBoost在迭代过程中实现平衡。
- XGBoost为损失函数加入结构风险项
AdaBoost、GBDT追求损失函数L(y,y^)最小化;
XGBoost追求目标函数O(y,y^) = L(y,y^) + 结构风险项最小化。
XGBoost利用结构风险项控制过拟合,其他树模型依赖树结构max_depth,min_impurity_decrease等。
- XGBoost使用新不纯度衡量指标
一般算法建CART树,分类使用信息增益,回归使用MSE或弗里德曼MSE;
XGBoost设定分支指标结构分数,基于结构分数的结构分数增益,向整体结构简单的方向建树。
1.3 降低模型复杂度、提升运行效率
决策树建树,需要对每一个特征上所有潜在的分支节点进行不纯度计算。XGBoost多种优化技巧优化提升效率:
- 全新建树流程
使用估计贪婪算法、平行学习、分位数草图算法等,适用于大数据。
- 提升硬件运算性能
使用感知缓存访问技术、核外计算技术。
- 建树增加随机性
引入Dropout技术。
1.4 保留部份GBDT属性
- 弱评估器是回归器,借助sigmoid或softmax实现分类。
- 拟合负梯度
GBDT中每次用于建立评估器的是样本X,以及当下集成输出H(xi)与真是标签y之间的伪残差(负梯度)。
当损失函数是1/2 MSE时,负梯度等同于残差。
XGBoost同样依赖于拟合残差来影响后续弱评估器建立。
- 抽样思想
对样本和特征进行抽样增大弱评估器之间的独立性。
1.5 Boosting算法的改进历程

2. sklearn接口(回归)
2.1 导库 & 数据
from sklearn.model_selection import KFold, cross_validate from sklearn.model_selection import train_test_split from xgboost import XGBRegressor ''' xgboost提供的sklearn api XGBRegressor() 实现xgboost回归 XGBClassifier() 实现xgboost分类 XGBRanker() 实现xgboost排序 XGBRFClassifier() 基于xgboost库实现随机森林分类 XGBRFRegressor() 基于xgboost库实现随机森林回归 '''from sklearn.datasets import load_digits data = load_digits() X = data.data y = data.target Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=1412) print(Xtrain.shape, Xtest.shape) ''' (1257, 64) (540, 64) '''2.2 sklearn api普通训练
# sklearn普通训练:实例化,fit,score # booster 使用弱评估器建树,可选gbtree,gbliner,dart xgb_sk = XGBRegressor(random_state=1412) xgb_sk.fit(Xtrain, Ytrain) xgb_sk.score(Xtest, Ytest) # 默认评估指标R^2 ''' 0.831818417176343 '''2.3 sklearn api交叉验证
# sklearn交叉验证:实例化,交叉验证,结果求平均 xgb_sk = XGBRegressor(random_state=1412) cv = KFold(n_splits=5, shuffle=True, random_state=1412) result_xgb_sk = cross_validate(xgb_sk ,X,y ,scoring='neg_root_mean_squared_error' #-RMSE ,return_train_score=True ,verbose=True ,n_jobs=-1 ) result_xgb_sk ''' {'fit_time': array([1.49709201, 1.51305127, 1.5214994 , 1.52006483, 1.49009109]), 'score_time': array([0.00797772, 0.0069809 , 0.02449441, 0.00797725, 0.01301908]), 'test_score': array([-1.3107202 , -1.3926962 , -1.34945876, -1.18663263, -1.49893354]), 'train_score': array([-0.0196779 , -0.02156499, -0.0167526 , -0.01670659, -0.02254371])} '''def RMSE(result, name): return abs(result[name].mean()) RMSE(result_xgb_sk, 'train_score') ''' 0.019449156665978885 ''' RMSE(result_xgb_sk, 'test_score') ''' 1.347688263452443 '''2.4 查看属性接口
# sklearn查看属性接口 xgb_sk = XGBRegressor(max_depth=5).fit(X,y) xgb_sk.feature_importances_ # 特征重要性 ''' array([0. , 0.00225333, 0.00230321, 0.00326973, 0.00863725, 0.00895859, 0.00746422, 0.00157759, 0. , 0.00096148, 0.00569782, 0.00173326, 0.02128937, 0.00525403, 0.00283347, 0.00028462, 0.00450659, 0.00130977, 0.01772124, 0.00536137, 0.04007934, 0.06141694, 0.00869896, 0.00226618, 0. , 0.00413993, 0.01785861, 0.03045771, 0.0369929 , 0.03439412, 0.04346734, 0.00481802, 0. , 0.04838382, 0.01810016, 0.03241276, 0.06217332, 0.00609181, 0.00342981, 0. , 0. , 0.00546112, 0.04138443, 0.00643031, 0.00676051, 0.00443247, 0.00591809, 0. , 0. , 0.00230393, 0.00367385, 0.02346367, 0.0843313 , 0.01382598, 0.00216754, 0.00023067, 0. , 0.00051113, 0.01587264, 0.00686751, 0.01672259, 0.01588235, 0.00281848, 0.18434276], dtype=float32) '''# 调出单独的树 xgb_sk.get_booster()[1] ''' ''' # 一共建立树数量,n_estimators取值 xgb_sk.get_num_boosting_rounds() ''' 100 '''# 获取参数取值 xgb_sk.get_params() ''' {'objective': 'reg:squarederror', 'base_score': 0.5, 'booster': 'gbtree', 'callbacks': None, 'colsample_bylevel': 1, 'colsample_bynode': 1, 'colsample_bytree': 1, 'early_stopping_rounds': None, 'enable_categorical': False, 'eval_metric': None, 'gamma': 0, 'gpu_id': -1, 'grow_policy': 'depthwise', 'importance_type': None, 'interaction_constraints': '', 'learning_rate': 0.300000012, 'max_bin': 256, 'max_cat_to_onehot': 4, 'max_delta_step': 0, 'max_depth': 5, 'max_leaves': 0, 'min_child_weight': 1, 'missing': nan, 'monotone_constraints': '()', 'n_estimators': 100, 'n_jobs': 0, 'num_parallel_tree': 1, 'predictor': 'auto', 'random_state': 0, 'reg_alpha': 0, 'reg_lambda': 1, 'sampling_method': 'uniform', 'scale_pos_weight': 1, 'subsample': 1, 'tree_method': 'exact', 'validate_parameters': 1, 'verbosity': None} '''2.5 参数意义&调参指导(chat-gpt版)
- n_estimators: 弱学习器(决策树)的数量,即梯度提升迭代的次数。增加此参数可能会导致过拟合,因为模型更多地关注训练集,而不是泛化到新数据上。
- learning_rate: 每个决策树对模型的贡献系数,用于缩小每个决策树的影响。默认0.1。较小的学习率可以降低过拟合的风险,但也可能增加训练时间。
- max_depth: 决策树的最大深度,用于控制决策树的复杂度。较大的值可能导致过拟合。
- subsample: 每次迭代使用的样本比例,用于控制样本的随机性。较小的子样本比例可能会降低过拟合的风险,但也可能减少模型的预测能力。
- colsample_bytree: 每次迭代使用的特征比例,用于控制特征的随机性。较小的特征比例可能会降低过拟合的风险,但也可能减少模型的预测能力。
- gamma: 决策树节点分裂的最小损失函数下降值。在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。增加此参数可能会降低过拟合的风险,设置过高会导致欠拟合。
- reg_alpha和reg_lambda: L1和L2正则化的权重,用于控制模型的复杂度。较大的正则化权重可能会降低过拟合的风险,但也可能降低模型的预测能力。
- min_child_weight: 决策树节点所需的最小叶子节点样本权重和,用于避免过拟合。增加此参数可以减少过拟合的风险,避免学习局部特殊样本。
- scale_pos_weight: 正样本权重与负样本权重的比例,用于解决类别不平衡问题。
除了上述参数外,Scikit-Learn接口实现还支持许多其他参数,例如min_child_weight、scale_pos_weight等。这些参数的含义和XGBoost原生API实现中的含义基本相同,但可能存在一些差异。用户在使用时应该根据自己的需求和数据特点选择合适的参数值。
调参步骤&举例
3. xgboost原生代码(回归)
3.1 导包
from sklearn.datasets import load_digits import xgboost # 原生代码只需导入xgboost data = load_digits() X = data.data y = data.target print(X.shape,y.shape) ''' (1797, 64) (1797,) '''3.2 DMatrix数据 xgboost.DMatrix()
- 必须使用xgboost自定义的数据结构DMatrix
''' 返回专用的DMatrix对象 不能索引和循环读取, 即不可查看和修改 不分X,y,特征和标签同时打包,训练时作为dtrain的输入 ''' data_xgb = xgboost.DMatrix(X,y) print(data_xgb)
''' 若需划分训练测试集,需提前划分再转换类型 ''' from sklearn.model_selection import train_test_split Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=1412) dtrain = xgboost.DMatrix(Xtrain, Ytrain) dtest = xgboost.DMatrix(Xtest, Ytest) print(dtrain, dtest) ''' '''3.3 params参数 params={}
''' 定义参数 参数名称会与sklearn有区别,seed随机数种子 这里的seed是boosting过程的随机数种子 ''' params = {'max_depth':5, 'seed':1412}3.4 不交叉验证 xgboost.train()
3.4.1 参数 & 代码
''' xgboost.train() 包含了实例化和训练过程,返回实例 训练时没区分回归分类,默认执行回归算法 .train()中,params外 num_boost_round 控制建树数量(迭代次数) 提前停止 一般来说除了上述两个参数,其余参数设置在params中 params中 xgb_model 指定弱评估器,可选gbtree,gbliner,dart评估器有不同的params列表 eta boosting算法中的学习率 objective 用于优化的损失函数,分类使用 base_score 初始化预测结果H0的值 max_delta_step 一次迭代中允许的最大迭代值 目标函数参数 https://www.bilibili.com/video/BV1Au411B7bC gamma,lambda,alpha 放大可控制过拟合 '''reg = xgboost.train(params, data_xgb, num_boost_round=100) y_pred = reg.predict(data_xgb) y_pred ''' array([-0.10801424, 0.84069467, 2.083782 , ..., 8.143546 , 8.9779825 , 8.03064 ], dtype=float32) '''3.4.2 评估指标
# 评估指标 # 借用sklearn.metrics from sklearn.metrics import mean_squared_error as MSE # squared=False 使用RMSE MSE(y, y_pred, squared=False) ''' 0.10822869258896699 '''# 特征重要性 from xgboost import plot_importance plot_importance(reg) ''' '''
3.5 交叉验证 xgboost.cv()
''' 不会返回模型,train()可以返回模型 返回评估指标和数值 ''' result = xgboost.cv(params, data_xgb, num_boost_round=100 ,nfold=5 # 5折 # 交叉验证的随机数种子 # params中seed是建树的随机数种子 ,seed=1412 )''' 返回DataFrame 100行代表num_boost_round定义迭代100次 每一次迭代都会进行5折交叉验证,显示结果为5次的平均 4列,训练集/测试集 上的 均值/标准差 很适合用来绘制图像 ''' result
train-rmse-mean train-rmse-std test-rmse-mean test-rmse-std 0 3.638185 0.039632 3.677730 0.202608 1 2.763450 0.028739 2.878112 0.173517 2 2.128277 0.020819 2.303325 0.152110 3 1.677589 0.027772 1.911049 0.117346 4 1.373573 0.034642 1.657949 0.097172 ... ... ... ... ... 95 0.094639 0.004466 1.076697 0.055437 96 0.092524 0.004142 1.076498 0.055798 97 0.091061 0.003936 1.076479 0.055860 98 0.089755 0.003874 1.076414 0.055971 99 0.088533 0.003673 1.076586 0.056002 100 rows × 4 columns
import matplotlib.pyplot as plt # dpi=300分辨率,figsize=[,]画布大小 plt.figure() plt.plot(result['train-rmse-mean']) plt.plot(result['test-rmse-mean']) plt.legend(['train', 'test']) plt.title('xgboost 5fold cv')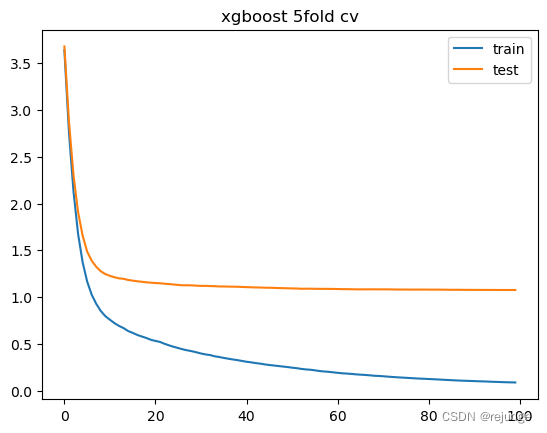
4. xgboost实现分类
4.1 sklearn接口
from xgboost import XGBClassifier
4.2 xgboost原生代码
''' objective: “reg:linear” 线性回归. “reg:logistic" 逻辑回归. “binary:logistic” 二分类的逻辑回归问题,输出为概率. “binary:logitraw” 二分类的逻辑回归问题,输出的为wTx. “count:poisson” 计数问题的poisson回归,输出结果为poisson分布.max_delta_step默认为0.7.(used to safeguard optimization) “multi:softmax” softmax处理多分类问题,同时需要设置参数num_class(类别个数). “multi:softprob” 输出各个分类概率,ndata*nclass向量,表示样本所属于每个类别的概率. “rank:pairwise” set XGBoost to do ranking task by minimizing the pairwise loss. ''' params = {'learning_rate':0.1 ,'max_depth':5 ,'objective':'multi:softmax' # ,'objective':'multi:softprob' ,'num_class':10 ,'random_state':1412 , 'eta':0.8 # boosting算法中的学学习率 }model = xgboost.train(params, data_xgb, num_boost_round=10) y_pred = model.predict(data_xgb) y_pred ''' array([0., 1., 2., ..., 8., 9., 8.], dtype=float32) '''
- 全新建树流程
- XGBoost为损失函数加入结构风险项



