
【冰糖Python】深度森林 DeepForest
此文为记录DeepForest的简单使用
原文《Deep Forest: Towards an Alternative to Deep Neural Networks》
“A key advantage of deep forest is its adaptive model complexity depending on the dataset. The default setting on hyper-parameters enables it to perform reasonably well across all datasets. ”
深层森林的一个关键优势是其自适应模型的复杂性取决于数据集。超参数的默认设置使它能够在所有数据集上执行得相当好。
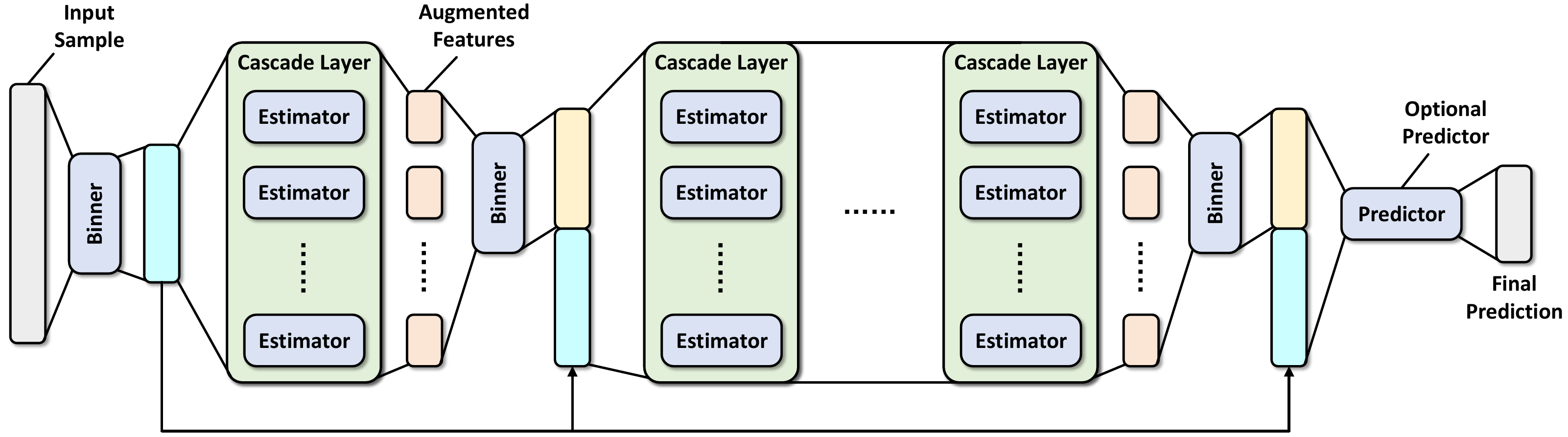
一、训练与预测
1、训练阶段从将训练样本的特征值离散化为n_bins唯一值开始,这是加速构建决策树的常用技术。然后,使用binned数据生成DF21中带有n_estimators估值器的第一个级联层(注意,默认情况下n_estuators将在内部乘以2)。此外,每个估计器由采用分裂准则的n_trees决策树组成,满足max_depth和min_samples_leaf施加的约束。
2、数据离散化并构建第一个级联层后,进入主训练循环:
1)使用新binner,将前一级联层的袋外预测结果离散化(由上图中的增强特征表示)
2)将增强特征连接到离散化后的训练样本,作为待构建级联层的新训练数据
3)使用串联的训练数据构建一个新层,遵循与构建第一个级联层相同的训练模式
4)获取层的袋外预测结果,并估计其泛化性能
5)如果估计性能优于所有以前构建的层,将继续构建新层。否则,会触发提前停止,如果n_tolerant_rounds回合的性能没有提高,将在达到max_layers之前终止训练阶段
3、作为可选步骤,如果use_predictor设置为True,将构建另一个预测器。该预测器接收来自最后一个级联层的串联训练数据的输入,并输出分类问题的预测类概率和回归问题的预测值。可以使用随机森林或GBDT等设置预测器。此外可以通过设置predictor_kwargs来更好地配置它。
4、评估阶段遵循训练的顺序结构。首先,使用第一个binner将测试样本离散化,并传递到第一层。然后,将增强特征设置为当前级联层的输出,并使用后续binner对其进行分类。在将增强特征连接到binned测试样本之后,移动到下一层,直到到达最后一个级联层或预测器。
二、主要模型
主要模型为CascadeForestClassifier
classdeepforest.CascadeForestClassifier(n_bins=255, bin_subsample=200000, bin_type='percentile', max_layers=20, criterion='gini', n_estimators=2, n_trees=100, max_depth=None, min_samples_split=2, min_samples_leaf=1, use_predictor=False, predictor='forest', predictor_kwargs={}, backend='custom', n_tolerant_rounds=2, delta=1e-05, partial_mode=False, n_jobs=None, random_state=None, verbose=1)
参数说明:
n_bins (int, default=255) – The number of bins used for non-missing values. In addition to the n_bins bins, one more bin is reserved for missing values. Its value must be no smaller than 2 and no greater than 255. 用于非缺失值的存储箱数。除了n_bins bins之外,还为缺少的值保留了一个bin。其值必须不小于2且不大于255
bin_subsample (int, default=200,000) – The number of samples used to construct feature discrete bins. If the size of training set is smaller than bin_subsample, then all training samples will be used.用于构造特征离散箱的样本数。如果训练集的大小小于bin_subsample,



