
决策树及其拓展 吴恩达课程
看到了个关于决策树很好的文章:链接
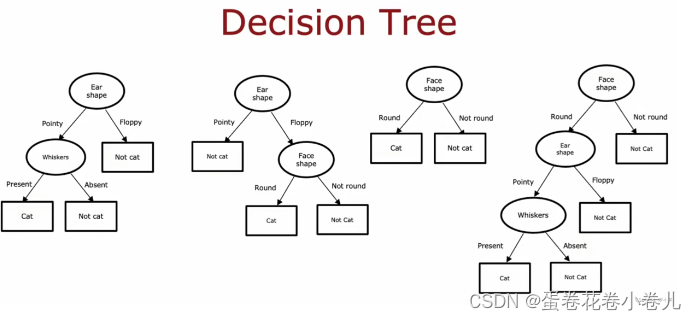
决策树
在所有可能的决策树中,选择一个在训练集上表现良好,并能很好的推广到新数据(即交叉验证集和测试集)的决策树。
参考文章
熵


信息增益
信息增益越大,表示该特征对数据集划分所获得的“纯度提升”越大。所以信息增益可以用于决策树划分属性的选择,即选择信息增益最大的属性。


关于信息增益的另一篇参考文章
构建决策树的过程
计算所有可能的信息增益,并选择最高的信息增益,根据选择的特征拆分数据集,并创建左右节点。继续递归调用以上拆分过程,直到达到阈值标准为止:
1.当某个节点的纯度为100%,即该节点的所有样本都属于一个类
2.当拆分节点后,导致树的深度超过最大深度
3.当拆分节点后,信息增益小于阈值时
4.当节点中的样本个数小于阈值时
参考文章
另一篇详细讲解构建决策树的文章
独热编码
独热编码用来解决类别型数据的离散值问题
- 优:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
- 缺:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA来减少维度。而且one hot encoding+PCA这种组合在实际中也非常有用。
独热编码详细解说
连续值处理
吴恩达讲解视频里是设定阈值。
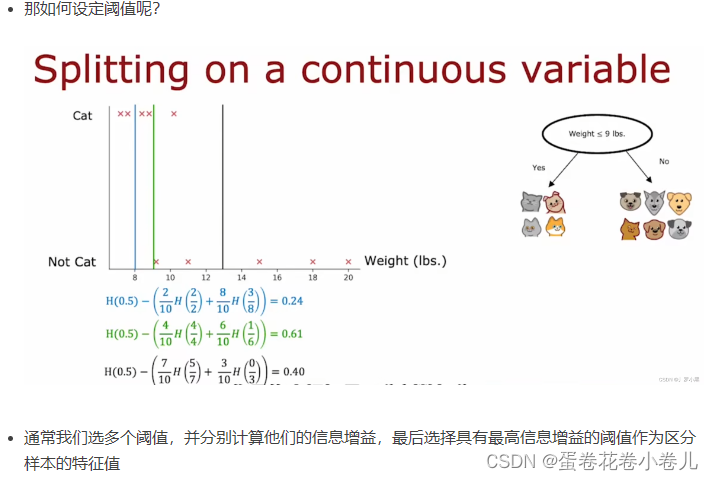
另一篇文章不一样的方法:离散化策略——二分法
决策树不仅可以用来分类,也可以用于回归问题(连续的值):
参考文章
分类树与回归树的区别
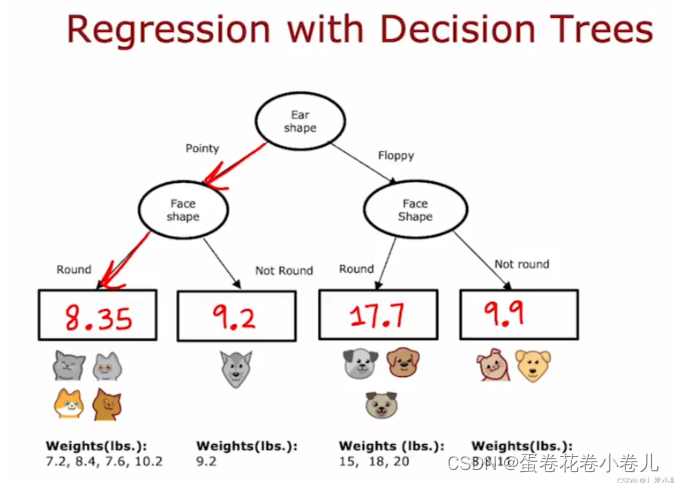
从根节点开始,一步一步划分,直到到达叶子节点,最后输出预测特征值
决策树集合
单个决策树可能会对数据的微小变化高度敏感,即鲁棒性(意思稳定性差)很差。所以使用多个决策树。
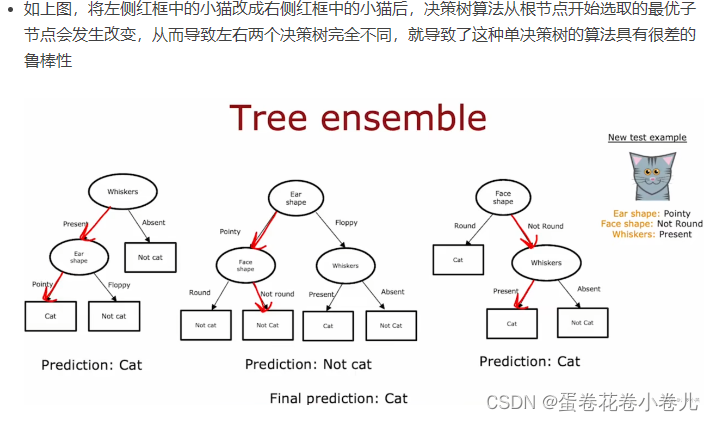
对每个决策树分别进行预测,最后统计结果,选择多数的结果作为最终预测结果。
参考文章
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



