
Selenium 如何使用代理 IP 进行 Web 爬虫(包括无认证实现、有账号密码认证实现)
文章目录
- 版本
- 无账号密码使用 Selenium 实现 HTTP 代理
- 万万没想到加上账号密码会难度升级 + N
- GPT 提供的带账号密码的 HTTP 代理解决方案
- 代理 IP
- 如何获取
- Selenium-Chrome-HTTP-Private-Proxy HTTP 代理解决方案
- 如何实现
- 总结
- 总结
- 个人简介
版本
- Python 3.x
无账号密码使用 Selenium 实现 HTTP 代理
- 最近一个朋友私聊了我一个问题,Selenium 如何使用代理 IP 进行爬虫,我心想这不是很简单,马上让 GPT 帮忙写一个:
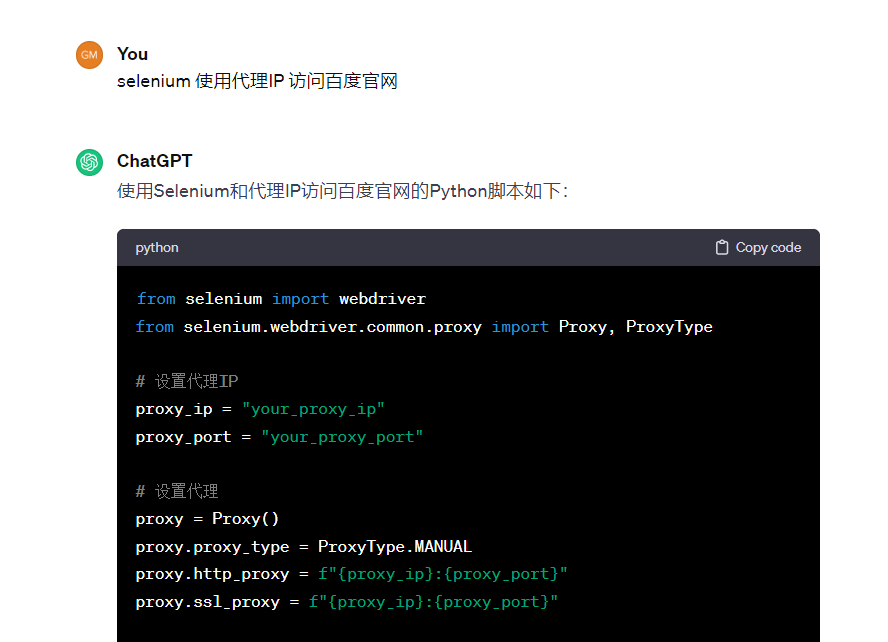
- 完整代码如下:
from selenium import webdriver from selenium.webdriver.common.proxy import Proxy, ProxyType # 设置代理IP proxy_ip = "your_proxy_ip" proxy_port = "your_proxy_port" # 设置代理 proxy = Proxy() proxy.proxy_type = ProxyType.MANUAL proxy.http_proxy = f"{proxy_ip}:{proxy_port}" proxy.ssl_proxy = f"{proxy_ip}:{proxy_port}" # 配置浏览器选项 chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--proxy-server=http://{}:{}'.format(proxy_ip, proxy_port)) # 启动浏览器 driver = webdriver.Chrome(executable_path='path/to/chromedriver', options=chrome_options) # 访问百度官网 driver.get('https://www.baidu.com') # 在这里执行你的操作,比如查找元素、输入搜索关键词等 # 关闭浏览器 driver.quit()- GPT 提供的代码有时候并不准确,需要简单修改一下,运行成功:
import time from selenium import webdriver from selenium.webdriver.chrome.service import Service # 设置代理IP proxy_ip = "127.0.0.1" proxy_port = "1080" # 配置浏览器选项 chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--proxy-server=http://{}:{}'.format(proxy_ip, proxy_port)) # 启动浏览器 chrome_service = Service("./chromedriver.exe") driver = webdriver.Chrome(service=chrome_service, options=chrome_options) # 访问百度官网 driver.get('https://www.baidu.com') # 在这里执行你的操作,比如查找元素、输入搜索关键词等 time.sleep(30) # 关闭浏览器 driver.quit()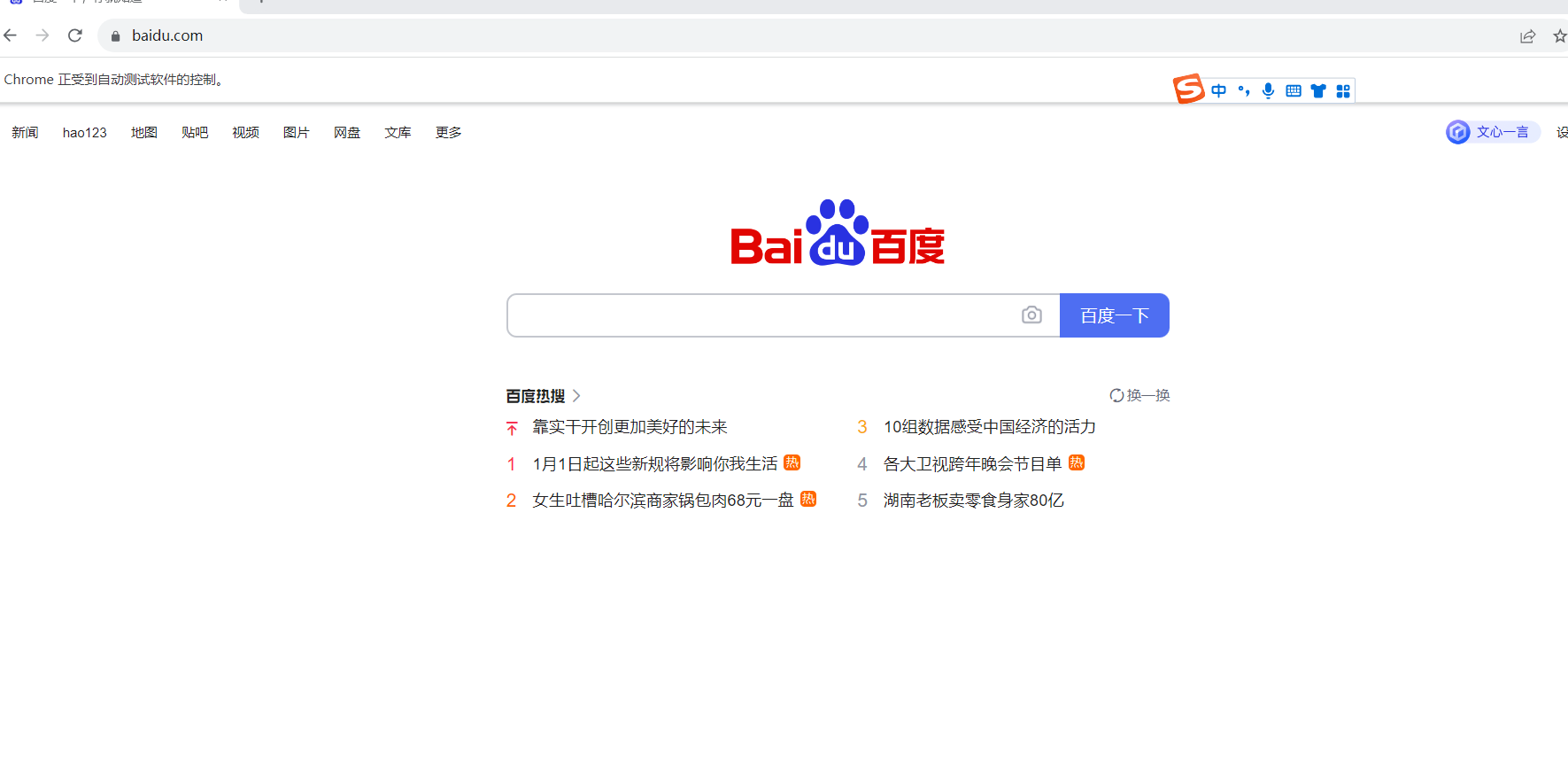
万万没想到加上账号密码会难度升级 + N
- 代码提供给朋友后,他突然回了一句,我的代理 IP 有账号密码,我心想这不简单,加上账号密码不就行了,然后我又转头把任务交给了 GPT,GPT 又给我提供了一份代码(下面的代码经过微调,还是上面的问题):
GPT 提供的带账号密码的 HTTP 代理解决方案
import time from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.proxy import Proxy, ProxyType # 设置代理IP proxy_ip = "your_proxy_ip" proxy_port = "your_proxy_port" proxy_username = "your_proxy_username" proxy_password = "your_proxy_password" # 设置代理 proxy = Proxy() proxy.proxy_type = ProxyType.MANUAL proxy.http_proxy = f"{proxy_ip}:{proxy_port}" # 配置代理的认证信息 capabilities = webdriver.DesiredCapabilities.CHROME.copy() proxy_auth = f"{proxy_username}:{proxy_password}" capabilities['proxy'] = { 'httpProxy': proxy.http_proxy, 'ftpProxy': proxy.http_proxy, 'sslProxy': proxy.http_proxy, 'proxyType': 'MANUAL', 'socksUsername': proxy_username, 'socksPassword': proxy_password } # 配置浏览器选项 chrome_options = webdriver.ChromeOptions() chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"]) chrome_options.add_argument('--proxy-server=http://{}:{}'.format(proxy_ip, proxy_port)) # 启动浏览器 chrome_service = Service("./chromedriver.exe") driver = webdriver.Chrome(service=chrome_service, options=chrome_options) # 访问百度官网 driver.get('https://www.baidu.com') # 在这里执行你的操作,比如查找元素、输入搜索关键词等 time.sleep(30) # 关闭浏览器 driver.quit()代理 IP
- 代码写好后不想改本地正常稳定使用的代理配置,使用了最近常使用的一个免费代理 IP (一连代理),支持主流的http/https/socks5协议,使用API快速拉取IP达到 50-300ms 响应时间,基本可以保证 99.99% 的IP可用性,有需要的小伙伴可以试试(有付费需求的小伙伴报暗号-Lorin洛林 可以打85折)。
如何获取
- 前往官网进入套餐详情页(https://yilian.top)
- 按需选择参数,领取4种见面礼
- 前往【控制台】—【产品管理】提取 IP

- 我使用的是 API 文档中的 simple 模式获取:
http://api.yilian.top/v2/proxy/proxies?num=1&type=1&token=XUzBRPIdCesGx7DYyaHerdaP2XkuXk2m&format=txt] { "errcode": 0, "errmsg": "获取ip地址成功,共1个", "data": [ { "real_ip": "182.114.35.123", "ip": "182.114.35.123", "prov": "河南", "city": "三门峡", "isp": "联通", "proxy_user": "9ER62CtIr", "proxy_pass": "fGGVvqedX", "proxy_port": 10007, "usage": "curl -x 182.114.35.123:10007 -U 9ER62CtIr:fGGVvqedX https://www.baidu.com", "expire_time": "2023-12-31 17:49:59", "expire_timestamp": 1704016199 } ] }- 申请好代理IP后替换代码中账号密码然后点击运行,发现并没有通过认证:

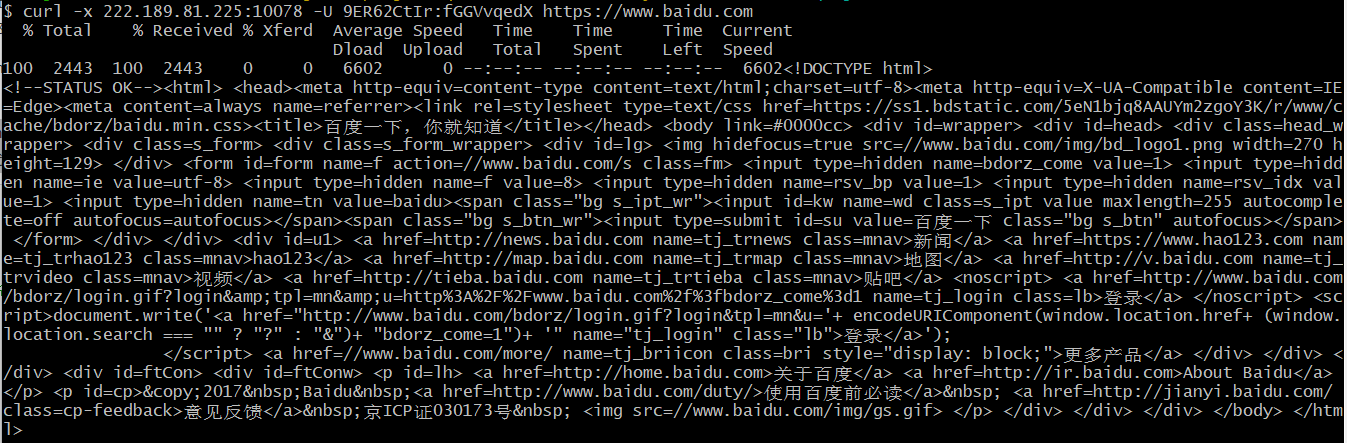
- 为了排除是代理本身的问题,使用 curl 命令确认代理 IP 是否可以正常访问,说明是使用上的问题,经过15分钟的搜索和验证,最后让我找到了解决方案 - 使用 Selenium-Chrome-HTTP-Private-Proxy。
Selenium-Chrome-HTTP-Private-Proxy HTTP 代理解决方案
- 默认情况下,Chrome的–proxy-server="http://ip:port"参数不支持设置用户名和密码认证。因此"Selenium + Chrome Driver"无法使用HTTP Basic Authentication的HTTP代理。一种变通的方式就是采用IP地址认证,但在国内网络环境下,大多数用户都采用ADSL形式网络接入,IP是变化的,也无法采用IP地址绑定认证。因此迫切需要找到一种让Chrome自动实现HTTP代理用户名密码认证的方案。
- Stackoverflow上有人分享了一种利用Chrome插件实现自动代理用户密码认证的方案非常不错,详细地址:http://stackoverflow.com/questions/9888323/how-to-override-basic-authentication-in-selenium2-with-java-using-chrome-driver
- 鲲之鹏的技术人员在此思路的基础上用Python实现了自动化的Chrome插件创建过程,即根据指定的代理“username:password@ip:port”自动创建一个Chrome代理插件,然后可以在"Selenium + Chrome Driver"中通过安装该插件实现代理配置功能(插件地址:https://github.com/RobinDev/Selenium-Chrome-HTTP-Private-Proxy)
如何实现
- 1、访问插件地址下载插件,放在项目目录中供使用
- 2、编写代码
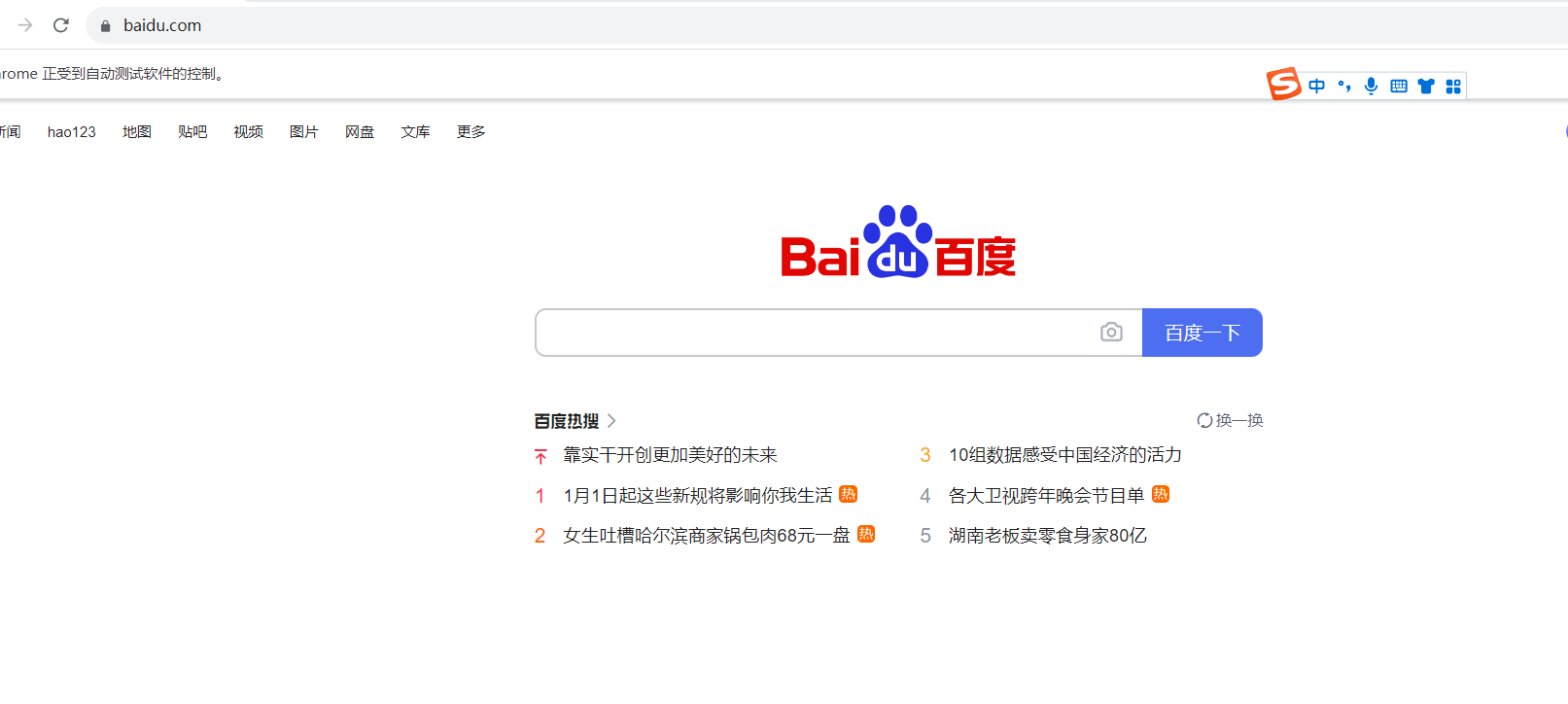
import time from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service def create_proxyauth_extension(proxy_host, proxy_port, proxy_username, proxy_password, scheme='http', plugin_path=None): """Proxy Auth Extension args: proxy_host (str): domain or ip address, ie proxy.domain.com proxy_port (int): port proxy_username (str): auth username proxy_password (str): auth password kwargs: scheme (str): proxy scheme, default http plugin_path (str): absolute path of the extension return str -> plugin_path """ import string import zipfile if plugin_path is None: plugin_path = 'Selenium-Chrome-HTTP-Private-Proxy.zip' manifest_json = """ { "version": "1.0.0", "manifest_version": 2, "name": "Chrome Proxy", "permissions": [ "proxy", "tabs", "unlimitedStorage", "storage", "", "webRequest", "webRequestBlocking" ], "background": { "scripts": ["background.js"] }, "minimum_chrome_version":"22.0.0" } """ background_js = string.Template( """ var config = { mode: "fixed_servers", rules: { singleProxy: { scheme: "${scheme}", host: "${host}", port: parseInt(${port}) }, bypassList: ["foobar.com"] } }; chrome.proxy.settings.set({value: config, scope: "regular"}, function() {}); function callbackFn(details) { return { authCredentials: { username: "${username}", password: "${password}" } }; } chrome.webRequest.onAuthRequired.addListener( callbackFn, {urls: [""]}, ['blocking'] ); """ ).substitute( host=proxy_host, port=proxy_port, username=proxy_username, password=proxy_password, scheme=scheme, ) with zipfile.ZipFile(plugin_path, 'w') as zp: zp.writestr("manifest.json", manifest_json) zp.writestr("background.js", background_js) return plugin_path def configure_headless_browser(proxy_config): chrome_options = Options() chrome_options.add_argument("--start-maximized") proxyauth_plugin_path = create_proxyauth_extension( proxy_host=proxy_config[0], proxy_port=proxy_config[1], proxy_username=proxy_config[2], proxy_password=proxy_config[3] ) chrome_options.add_extension(proxyauth_plugin_path) # chrome_options.add_argument('--headless') # chrome_options.add_argument( # "user-agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'") chrome_service = Service("./chromedriver.exe") return webdriver.Chrome(service=chrome_service, options=chrome_options) # 设置代理IP proxy_config = ["175.153.142.127""", "10033", "9ER62CtIr", "fGGVvqedX"] # 启动浏览器 driver = configure_headless_browser(proxy_config) # 访问百度官网 driver.get('https://www.baidu.com') # 在这里执行你的操作,比如查找元素、输入搜索关键词等 time.sleep(30) # 关闭浏览器 driver.quit()- 点击测试运行,运行成功,并确认正确使用代理IP:

总结
- 本文介绍了 Selenium 使用无账号和有账号密码进行代理爬虫的方式,无账号密码主要基于浏览器 --proxy-server 参数实现,而有账号密码的方式基于 Selenium-Chrome-HTTP-Private-Proxy 插件实现;同时分享了一种免费获取代理IP的方式(一连代理),感兴趣的朋友可以试试。
总结
- 本文介绍了 Selenium 使用无账号和有账号密码进行代理爬虫的方式,无账号密码主要基于浏览器 --proxy-server 参数实现,而有账号密码的方式基于 Selenium-Chrome-HTTP-Private-Proxy 插件实现;同时分享了一种免费获取代理IP的方式(一连代理),感兴趣的朋友可以试试。
个人简介
👋 你好,我是 Lorin 洛林,一位 Java 后端技术开发者!座右铭:Technology has the power to make the world a better place.
🚀 我对技术的热情是我不断学习和分享的动力。我的博客是一个关于Java生态系统、后端开发和最新技术趋势的地方。
🧠 作为一个 Java 后端技术爱好者,我不仅热衷于探索语言的新特性和技术的深度,还热衷于分享我的见解和最佳实践。我相信知识的分享和社区合作可以帮助我们共同成长。
💡 在我的博客上,你将找到关于Java核心概念、JVM 底层技术、常用框架如Spring和Mybatis 、MySQL等数据库管理、RabbitMQ、Rocketmq等消息中间件、性能优化等内容的深入文章。我也将分享一些编程技巧和解决问题的方法,以帮助你更好地掌握Java编程。
🌐 我鼓励互动和建立社区,因此请留下你的问题、建议或主题请求,让我知道你感兴趣的内容。此外,我将分享最新的互联网和技术资讯,以确保你与技术世界的最新发展保持联系。我期待与你一起在技术之路上前进,一起探讨技术世界的无限可能性。
📖 保持关注我的博客,让我们共同追求技术卓越。
- 本文介绍了 Selenium 使用无账号和有账号密码进行代理爬虫的方式,无账号密码主要基于浏览器 --proxy-server 参数实现,而有账号密码的方式基于 Selenium-Chrome-HTTP-Private-Proxy 插件实现;同时分享了一种免费获取代理IP的方式(一连代理),感兴趣的朋友可以试试。
- 本文介绍了 Selenium 使用无账号和有账号密码进行代理爬虫的方式,无账号密码主要基于浏览器 --proxy-server 参数实现,而有账号密码的方式基于 Selenium-Chrome-HTTP-Private-Proxy 插件实现;同时分享了一种免费获取代理IP的方式(一连代理),感兴趣的朋友可以试试。
- 点击测试运行,运行成功,并确认正确使用代理IP:
- 为了排除是代理本身的问题,使用 curl 命令确认代理 IP 是否可以正常访问,说明是使用上的问题,经过15分钟的搜索和验证,最后让我找到了解决方案 - 使用 Selenium-Chrome-HTTP-Private-Proxy。
- 申请好代理IP后替换代码中账号密码然后点击运行,发现并没有通过认证:
- 我使用的是 API 文档中的 simple 模式获取:
- 前往【控制台】—【产品管理】提取 IP
- 按需选择参数,领取4种见面礼
- 前往官网进入套餐详情页(https://yilian.top)
- 代码写好后不想改本地正常稳定使用的代理配置,使用了最近常使用的一个免费代理 IP (一连代理),支持主流的http/https/socks5协议,使用API快速拉取IP达到 50-300ms 响应时间,基本可以保证 99.99% 的IP可用性,有需要的小伙伴可以试试(有付费需求的小伙伴报暗号-Lorin洛林 可以打85折)。
- 代码提供给朋友后,他突然回了一句,我的代理 IP 有账号密码,我心想这不简单,加上账号密码不就行了,然后我又转头把任务交给了 GPT,GPT 又给我提供了一份代码(下面的代码经过微调,还是上面的问题):
- GPT 提供的代码有时候并不准确,需要简单修改一下,运行成功:
- 完整代码如下:
- 最近一个朋友私聊了我一个问题,Selenium 如何使用代理 IP 进行爬虫,我心想这不是很简单,马上让 GPT 帮忙写一个:
- Python 3.x
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



