
机器学习笔记 - PyTorch 分布式训练概览
一、简述
对于大规模的数据集,只能进行分布式训练,分布式训练会尽可能的利用我们的算力,使模型训练更加高效。PyTorch提供了Data Parallel包,它可以实现单机、多GPU并行。
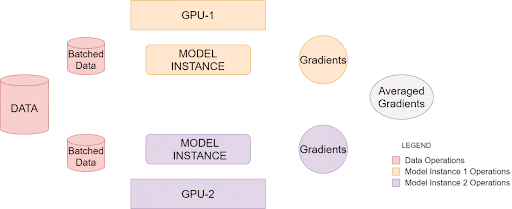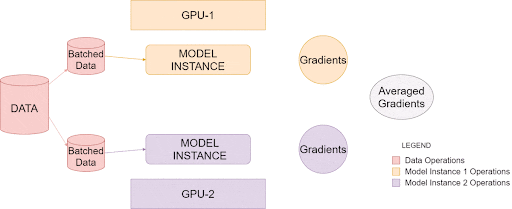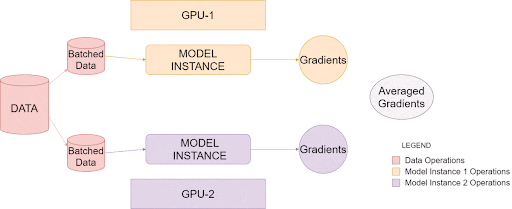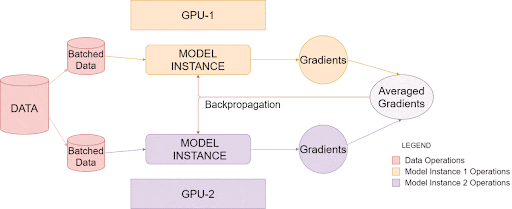 PyTorch 数据并行模块的内部工作原理
PyTorch 数据并行模块的内部工作原理
上面的图像说明了PyTorch 如何在单个系统中利用多个 GPU,这称为数据并行训练,您可以使用具有多个 GPU 的单个主机系统来提高处理大量数据的效率。
一旦被调用,就会在每个GPU上创建单独的模型实例。然后,数据被分成相等的部分,每个模型实例一个。最后,每个实例创建自己的梯度,然后在所有可用实例之间进行平均和反向传播。
这里首先看看单机多卡的训练,弄明白了以后多机多卡就差不多了。
下面就进入代码,看看如何进行分布式训练,这里写的基本都是从别人哪里借鉴来的,基本算是个记录,回头实操完事再来补充一些东西和遇到的问题。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



