
文心一言 VS 讯飞星火 VS chatgpt (242)-- 算法导论17.4 1题
一、假定我们希望实现一个动态的开地址散列表。为什么我们需要当装载因子达到一个严格小于 1 的值 a 时就认为表满?简要描述如何为动态开地址散列表设计一个插入算法,使得每个插入操作的摊还代价的期望值为 O(1) 。为什么每个插入操作的实际代价的期望值不必对所有插入操作都是 O(1) ? 如果要写代码,请用go语言。
文心一言:
动态开地址散列表(也称为哈希表或哈希映射)是一种常见的数据结构,用于存储键值对,并通过键进行高效查找。开地址散列表通过哈希函数将键映射到数组的索引,并在该索引位置存储相应的值。当两个或多个键哈希到同一个索引时,就需要使用某种冲突解决策略,如线性探测、二次探测或双重哈希。
为什么装载因子达到一个严格小于 1 的值 a 时就认为表满?
装载因子是散列表中存储的元素数量与散列表大小(即数组的长度)的比率。当装载因子过高时,冲突的概率会显著增加,导致查找和插入操作的效率降低。因此,为了保持哈希表的高效性,我们通常会在装载因子达到某个阈值(严格小于 1)时进行表格扩展(即重新分配更大的数组并重新哈希所有元素)。这个阈值通常是根据经验设定的,例如 0.75 或 0.8,以在空间和效率之间找到平衡。
如何为动态开地址散列表设计一个插入算法,使得每个插入操作的摊还代价的期望值为 O(1)?
为了实现摊还代价为 O(1) 的插入操作,我们可以采用以下策略:
初始化:创建一个初始大小合适的数组,并设定一个装载因子的阈值(如 0.75)。
哈希函数:设计一个合适的哈希函数,将键映射到数组的索引。
插入操作:
计算键的哈希值。
检查对应的数组位置是否为空。如果为空,则直接插入键值对。
如果位置已占用,则使用线性探测、二次探测或双重哈希等策略解决冲突,直到找到一个空位置插入键值对。
如果在探测过程中发现装载因子超过了设定的阈值,则执行表格扩展操作:
分配一个新的、更大的数组。
重新计算所有已存储元素的哈希值,并将它们插入到新数组中。
释放旧数组的空间。
更新装载因子。
摊还代价的期望值为 O(1) 是因为虽然表格扩展操作可能需要 O(n) 的时间(其中 n 是当前哈希表中的元素数量),但这个操作不是每次插入都需要进行的。在平均情况下,由于我们提前扩展了哈希表,每次插入操作只需要常数时间的探测即可找到空位置。因此,如果将表格扩展的代价分摊到多次插入操作中,每次插入的平均代价就是常数。
为什么每个插入操作的实际代价的期望值不必对所有插入操作都是 O(1)?
虽然摊还代价期望是 O(1),但每个插入操作的实际代价可能会因为冲突和表格扩展而有所波动。在极端情况下,如果哈希函数设计得不好或者键的分布非常不均匀,可能导致大量冲突,使得某个特定插入操作的代价非常高。此外,表格扩展操作本身就是一个相对昂贵的操作,它会在扩展时显著增加插入操作的代价。然而,由于摊还分析考虑了这些高代价操作在长时间内的平均效果,因此即使存在这些波动,摊还代价仍然可以保持为 O(1)。
下面是使用 Go 语言实现的一个简单示例:
package main
import (
"fmt"
"math/rand"
"time"
)
type HashTable struct {
table []*Entry
size int
threshold float64
loadFactor float64
}
type Entry struct {
key string
value interface{}
}
func NewHashTable(initialSize int, threshold float64) *HashTable {
return &HashTable{
table: make([]*Entry, initialSize),
size: initialSize,
threshold: threshold,
loadFactor: 0,
}
}
func (ht *HashTable) Insert(key string, value interface{}) {
if ht.loadFactor >= ht.threshold {
ht.resize()
}
hash := ht.hash(key)
for ht.table[hash] != nil && ht.table[hash].key != key {
hash = (hash + 1) % ht.size
}
if ht.table[hash] == nil {
ht.table[hash] = &Entry{key: key, value: value}
ht.loadFactor++
} else {
ht.table[hash].value = value
}
}
func (ht *HashTable) hash(key string) int {
// 使用简单的哈希函数,实际应用中应使用更复杂的哈希函数以减少冲突
h := 0
for i := 0;
i
这个简单的示例展示了如何初始化一个开地址散列表,并实现了插入操作。当装载因子超过阈值时,它会触发表格扩展。请注意,这个示例使用了非常简单的哈希函数和线性探测策略,实际应用中可能需要更复杂的哈希函数和冲突解决策略。此外,示例没有包括错误检查或异常处理,这在实际应用中也是需要考虑的。
讯飞星火:
我们需要在装载因子达到一个严格小于1的值a时认为表满,因为这样可以在空间和时间之间找到一个平衡。当装载因子接近1时,散列表的空间利用率较高,但冲突的可能性也增大,导致查找、插入和删除操作的时间效率降低。而当装载因子较小时,虽然空间利用率较低,但冲突的可能性减小,操作的时间效率较高。因此,选择一个合适的装载因子阈值,可以在空间和时间之间取得较好的平衡。
为了实现动态开地址散列表的插入算法,使得每个插入操作的摊还代价的期望值为O(1),我们可以采用线性探测法(Linear Probing)或二次探测法(Quadratic Probing)等开放寻址策略。这些策略在处理冲突时会尝试不同的探测序列,从而减少冲突的概率。
以下是使用Go语言实现的动态开地址散列表插入算法:
package main
import (
"fmt"
)
type HashTable struct {
table []int
capacity int
size int
loadFactor float64
}
func NewHashTable(capacity int, loadFactor float64) *HashTable {
return &HashTable{
table: make([]int, capacity),
capacity: capacity,
loadFactor: loadFactor,
}
}
func (h *HashTable) Insert(key int) {
if h.size >= int(float64(h.capacity)*h.loadFactor) {
h.resize()
}
index := key % h.capacity
for h.table[index] != 0 {
index = (index + 1) % h.capacity
}
h.table[index] = key
h.size++
}
func (h *HashTable) resize() {
newCapacity := h.capacity * 2
newTable := make([]int, newCapacity)
for i := 0; i
每个插入操作的实际代价的期望值不必对所有插入操作都是O(1),因为在最坏情况下,当所有元素都发生冲突时,插入操作的代价可能会达到O(n)。然而,通过使用开放寻址策略和适当的装载因子阈值,我们可以使实际代价的期望值接近O(1)。
360智脑:
在动态开地址散列表中,装载因子(load factor)是指散列表中已使用的桶数与总桶数的比例。当装载因子接近1时,意味着散列表中的元素越来越多,冲突的可能性也随之增加。为了避免性能下降,我们需要在装载因子达到某个阈值(例如,0.75或0.8)时对散列表进行重新hash,即扩大散列表的大小,以减少冲突的概率。
为了保证每个插入操作的摊还代价的期望值为 O(1),我们可以采用双散列(double hashing)技术来解决冲突。双散列是指在发生冲突时,使用第二个哈希函数计算下一个探测位置,直到找到一个空桶为止。这种方法可以减少聚集现象,提高查找和插入的效率。
下面是一个简化的Go语言实现:
type DoubleHashing struct {
keys []int // 存放键值
values []int // 存放对应值
size int // 当前元素数量
capacity int // 桶的总数
hashFunc1 func(int) int // 第一个哈希函数
hashFunc2 func(int) int // 第二个哈希函数
}
// 初始化双散列结构
func NewDoubleHashing(initialCapacity int, hashFunc1 func(int) int, hashFunc2 func(int) int) *DoubleHashing {
return &DoubleHashing{
keys: make([]int, initialCapacity),
values: make([]int, initialCapacity),
capacity: initialCapacity,
size: 0,
hashFunc1: hashFunc1,
hashFunc2: hashFunc2,
}
}
// 当装载因子达到阈值时,扩大散列表的大小
func (dh *DoubleHashing) resize(newCapacity int) {
newKeys := make([]int, newCapacity)
newValues := make([]int, newCapacity)
for i := 0; i = 0.75 {
// 选择新的容量,通常是现有容量的2倍
newCapacity := dh.capacity * 2
dh.resize(newCapacity)
}
}
// 其他操作,如查找、删除等,可以根据上述代码适当扩展
请注意,上述代码仅提供了一个基本的示例,实际应用中可能需要考虑更多的细节,比如哈希函数的选择、内存分配效率、以及如何处理删除操作等。
至于为什么每个插入操作的实际代价的期望值不必对所有插入操作都是 O(1),这是因为当散列表的装载因子接近1时,即元素数量接近桶的总数时,冲突的概率会非常高,这时插入操作的实际代价可能会接近O(n),其中n是散列表中元素的数量。因此,在这种情况下,插入操作的实际代价的期望值会随着元素数量的增加而增加,而不是始终保持在O(1)。
智谱清言:
在动态开地址散列表中,装载因子是指表中已占用的位置与总位置的比例。传统上,当装载因子达到某个阈值时(通常是0.7或0.75),我们就认为哈希表几乎已满,需要进行扩容操作,以保持哈希表的高效率。
然而,在动态开地址散列表中,我们希望即使在装载因子严格小于1的情况下,也能进行扩容。这是因为,哈希表的性能不仅取决于装载因子,还取决于冲突的数量和处理冲突的代价。当装载因子很小时,表面上看起来表还有很多空位,但如果这些空位是由于之前的删除操作造成的,那么它们可能分布在表的不同位置,导致新的插入操作发生大量的冲突。因此,为了保持操作的效率,我们可能需要在装载因子还未达到1时就开始扩容。
为了设计一个使每个插入操作的摊还代价的期望值为O(1)的动态开地址散列表插入算法,我们可以采用以下策略:
- 当装载因子达到一个严格小于1的值a时,进行扩容操作,将容量翻倍,并重新散列所有现有的项目到新的桶中。
- 使用线性探测或分离链接法来处理哈希冲突。
- 确保每次扩容操作后,装载因子始终保持在较低水平。
为什么每个插入操作的实际代价的期望值不必对所有插入操作都是O(1)呢?这是因为“摊还分析”考虑的是大量操作的平均性能,而不是单次操作的性能。在动态开地址散列表中,插入操作可能会有两种情况:
- 如果表还有足够的空位,插入操作的代价接近于O(1)。
- 如果表接近满或者由于之前的删除操作导致很多空位分散在表中,插入操作可能需要重新散列很多次,甚至可能需要进行扩容操作,此时插入操作的代价会显著增加。
然而,如果扩容操作足够频繁,且每次扩容后的装载因子都保持在较低水平,那么平均来看,每个插入操作仍然只需要移动到新的位置进行查找和插入,这样的操作次数是常数的,因此摊还代价是O(1)。
以下是一个用Go语言实现的简单动态开地址散列表插入算法的示例:
package main
import (
"fmt"
)
const (
InitialCapacity = 16
LoadFactor = 0.5 // 装载因子
)
type HashTable struct {
capacity int
size int
buckets [InitialCapacity]*Bucket
itemCount int
}
type Bucket []*Item
type Item struct {
key string
value interface{}
}
func NewHashTable() *HashTable {
return &HashTable{
capacity: InitialCapacity,
size: 0,
buckets: make([]*Bucket, InitialCapacity),
itemCount: 0,
}
}
func (h *HashTable) Len() int {
return h.size
}
func (h *HashTable) Cap() int {
return h.capacity
}
func (h *HashTable) hash(key string) int {
hash := 0
for _, char := range key {
hash = 31*hash + int(char)
}
return hash % h.capacity
}
func (h *HashTable) Insert(key string, value interface{}) {
if h.Len()/h.Cap() > LoadFactor {
// 扩容逻辑
h.resize(2 * h.Cap())
}
index := h.hash(key)
for i := 0; i
天工:
在动态开地址散列表中,当装载因子(load factor)达到某个特定值a(a
size int
length int
table []int
}
func NewHashTable() *HashTable {
return &HashTable{
size: DEFAULT_SIZE,
length: 0,
table: make([]int, DEFAULT_SIZE),
}
}
func (ht *HashTable) insert(key int) bool {
if ht.length = float64(ht.size)*LOAD_FACTOR {
ht.resize()
}
// 计算散列地址
index := key % ht.size
// 线性探测
for i := index; i
在上述代码中,我们使用了线性探测来解决散列表中的冲突。当装载因子超过预设的阈值时,我们调用resize方法进行散列表扩容。扩容后的散列表将重新映射所有元素到新的散列表中。这样设计的目的是为了保持散列表的性能稳定,避免因为过多的冲突导致性能下降。
chatgpt:
当装载因子达到严格小于 1 的值 a 时认为表满的原因是为了保证散列表中的冲突尽可能少,提高插入和查找操作的效率。如果装载因子过高,冲突将会增多,导致查找元素时需要遍历更多的位置。
下面是一个简要描述如何设计一个插入算法,使得每个插入操作的摊还代价的期望值为 O(1):
- 创建一个初始大小为 m 的动态开地址散列表(m 可以根据需求设定)。
- 定义装载因子阈值 a(例如 0.7),即当散列表中的元素个数达到 m*a 时,进行扩容操作。
- 插入元素时,首先计算元素的哈希值,并根据当前散列表大小取模得到存储位置 index。
- 如果该位置为空,则直接将元素存放在该位置;如果该位置已被占用,则使用某种冲突解决策略(如线性探测、二次探测等)寻找下一个空闲位置并存放元素。
- 每次成功插入元素后,更新散列表中元素数量 count。
- 当 count 达到装载因子阈值 m*a 时,进行扩容操作:
- 创建新的散列表大小为当前散列表的两倍(或根据需要进行调整)。
- 将原有散列表中的元素重新哈希,并存放到新散列表中。
- 更新散列表大小为新大小,重置 count 为当前元素个数。
- 最后返回插入操作成功。
每个插入操作的摊还代价的期望值为 O(1) 意味着在平均情况下,每次插入操作所需的时间是常数级别的。然而,实际代价可能会受到特定插入序列、哈希函数性能等因素的影响,导致某些操作耗时较长,但总体上仍保持期望值为 O(1)。
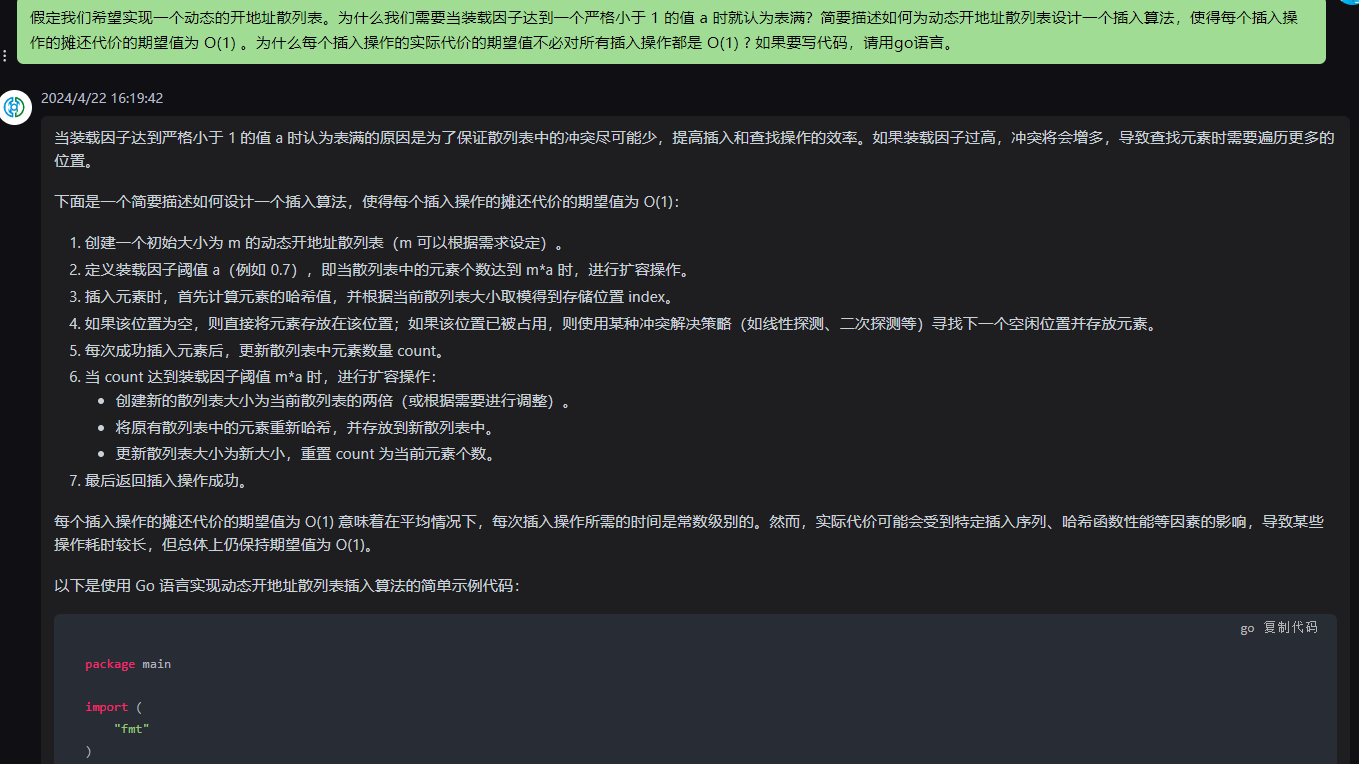
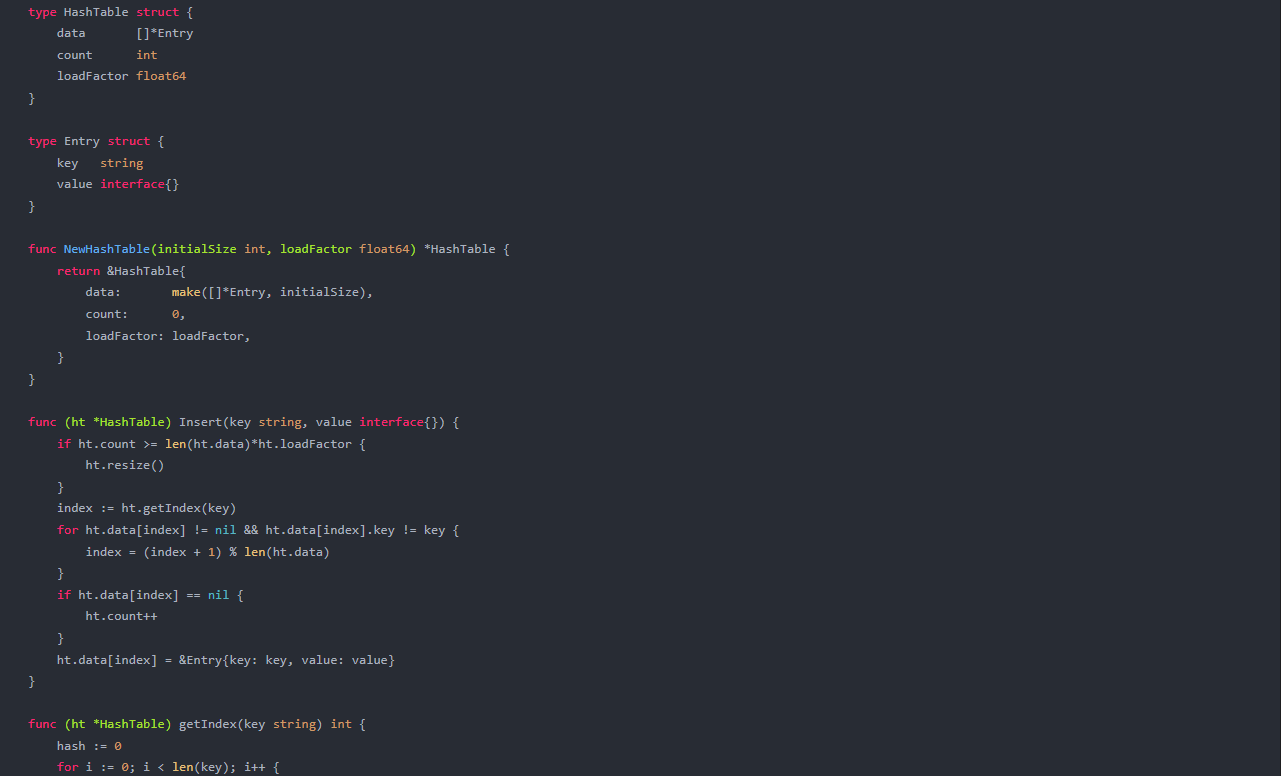
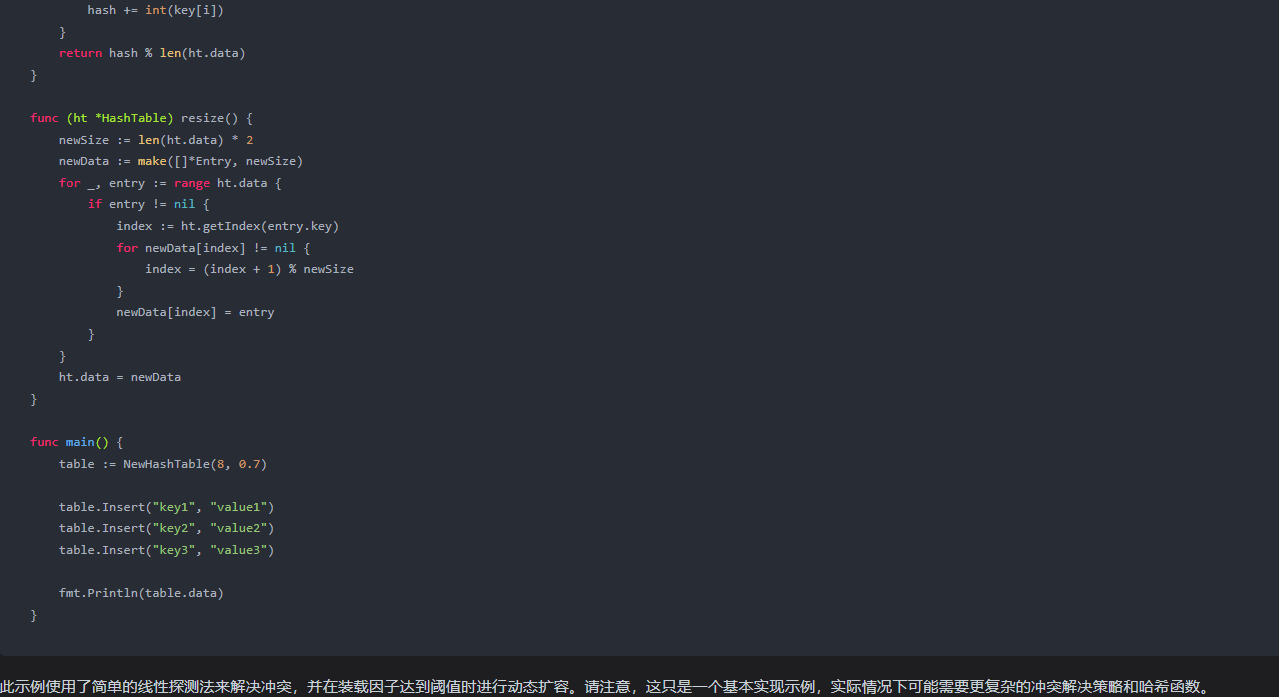
以下是使用 Go 语言实现动态开地址散列表插入算法的简单示例代码:
package main
import (
"fmt"
)
type HashTable struct {
data []*Entry
count int
loadFactor float64
}
type Entry struct {
key string
value interface{}
}
func NewHashTable(initialSize int, loadFactor float64) *HashTable {
return &HashTable{
data: make([]*Entry, initialSize),
count: 0,
loadFactor: loadFactor,
}
}
func (ht *HashTable) Insert(key string, value interface{}) {
if ht.count >= len(ht.data)*ht.loadFactor {
ht.resize()
}
index := ht.getIndex(key)
for ht.data[index] != nil && ht.data[index].key != key {
index = (index + 1) % len(ht.data)
}
if ht.data[index] == nil {
ht.count++
}
ht.data[index] = &Entry{key: key, value: value}
}
func (ht *HashTable) getIndex(key string) int {
hash := 0
for i := 0; i
此示例使用了简单的线性探测法来解决冲突,并在装载因子达到阈值时进行动态扩容。请注意,这只是一个基本实现示例,实际情况下可能需要更复杂的冲突解决策略和哈希函数。
kimi:
在动态开地址散列表中,装载因子(load factor)是表中已使用的槽位数与总槽位数的比值。装载因子达到 1 意味着散列表已经完全填满,此时无法再进行插入操作而不发生冲突。因此,为了在插入新元素时留出一定的空间以减少冲突,装载因子通常设置为一个严格小于 1 的值 ( a )。这样做的目的是为了避免频繁地重新散列和扩展散列表,从而提高性能。
为了设计一个插入算法,使得每个插入操作的摊还代价的期望值为 O(1),我们可以采取以下策略:
-
探测序列:选择一个好的探测序列,例如线性探测、二次探测或双重散列,以减少冲突。
-
散列表大小:当装载因子达到预设的阈值 ( a ) 时,增加散列表的大小。新的大小应该是当前大小的倍数,以保证原有的探测序列仍然有效。
-
重新散列:当散列表扩容后,将所有元素从旧表重新插入到新表中。这个过程可以分摊到未来的每个插入操作上,从而使得每个插入操作的摊还代价的期望值为 O(1)。
-
扩容阈值:选择一个合适的装载因子 ( a ),使得在扩容时,散列表的大小增加导致的额外空间可以被未来一定数量的插入操作所摊还。
为什么每个插入操作的实际代价的期望值不必对所有插入操作都是 O(1)?这是因为在散列表的生命周期中,会有一些插入操作导致散列表扩容和重新散列,这些操作的代价会高于 O(1)。但是,如果我们将重新散列的代价分摊到后续的插入操作上,那么在足够长的时间和足够多的操作序列中,每个插入操作的摊还代价的期望值可以是 O(1)。
以下是使用 Go 语言实现的简单动态开地址散列表的示例代码:
package main
import (
"fmt"
"math"
)
type HashTable struct {
size int
capacity int
elements []int
threshold int
}
func NewHashTable(capacity int) *HashTable {
return &HashTable{
size: 0,
capacity: capacity,
elements: make([]int, capacity),
threshold: int(math.Ceil(float64(capacity) * 0.75)), // 装载因子为 0.75
}
}
func (h *HashTable) insert(key int) {
if h.size >= h.threshold {
h.resize()
}
// 使用线性探测
probed := 0
for {
index := h.hash(key, h.capacity)
if h.elements[index] == 0 {
h.elements[index] = key
h.size++
return
}
probed++
if probed >= h.capacity {
panic("hash table is full")
}
}
}
func (h *HashTable) hash(key, capacity int) int {
return key % capacity
}
func (h *HashTable) resize() {
oldElements := h.elements
h.capacity *= 2
h.elements = make([]int, h.capacity)
h.threshold = int(math.Ceil(float64(h.capacity) * 0.75))
for _, key := range oldElements {
h.insert(key)
}
}
func main() {
ht := NewHashTable(10)
for i := 1; i
ht.insert(i)
fmt.Println("Inserted:", i)
}
}
size int
count int
elements []int
}
func NewHashTable(size int) *HashTable {
return &HashTable{
size: size,
elements: make([]int, size),
}
}
func (h *HashTable) hash(key int) int {
hasher := fnv.New32a()
hasher.Write([]byte(fmt.Sprintf("%d", key)))
return int(hasher.Sum32()) % h.size
}
func (h *HashTable) rehash(oldIndex int) int {
return (oldIndex + 1) % h.size
}
func (h *HashTable) Insert(key int) {
if h.count = int(float64(h.size)*loadFactor) {
h.resize()
}
index := h.hash(key)
for h.elements[index] != 0 {
index = h.rehash(index)
}
h.elements[index] = key
h.count++
}
func (h *HashTable) resize() {
newSize := h.size * 2
newElements := make([]int, newSize)
for i := 0; i 


