
走进SQL审计视图——《OceanBase诊断系列》之二
温馨提示:这篇文章已超过386天没有更新,请注意相关的内容是否还可用!
1. 前言
在SQL性能诊断上,OceanBase有一个非常实用的功能 —— SQL审计视图(gv$sql_audit)。在OceanBase 4.0.0及更高版本中,该功能是 gv$ob_sql_audit。它可以使开发和运维人员更方便地排查在OceanBase上运行过的任意一条SQL,无论这些SQL是成功与否,都有详细的运行信息记录。这些信息包括客户端和服务端的IP端口、SQL语句、执行时间、执行节点、执行计划ID、会话ID、执行时间、等待时间、总时间、排队时间、以及相关的块读取信息和执行报错信息等。
| 查询方式 | 说明 |
| (g)v$ob_sql_audit | OceanBase 4.0.0.0 及以上版本,gv$xx查询该租户所有机器v$xxx查询该租户本机器(不保证路由准确) |
| (g)v$sql_audit | OceanBase 4.0.0.0 以下版本gv$xx查询该租户所有机器v$xxx查询该租户本机器(不保证路由准确) |
sql_audit是基于虚拟表__all_virtual_sql_audit的视图, 该虚拟表对应的数据存放在一个可配置的内存空间中,能够记录并显示每一次SQL请求的来源、执行状态及统计信息,由于存放这些记录的内存是有限的,因此到达一定内存使用量,会触发淘汰。
- sql_audit 每隔 1s 会检测后台任务并根据以下标准决定是否淘汰:
- sql_audit 内存最大可使用上限为 avail_mem_limit = min (OBServer 可使用内存 *10%,sql_audit_memory_limit)。
- 当 avail_mem_limit 在 [64M, 100M] 范围内时, 内存使用达到 avail_mem_limit-20M 时触发淘汰。
- 当 avail_mem_limit 在 [100M, 5G] 范围内时, 内存使用达到 availmem_limit*0.8 时触发淘汰。
- 当 avail_mem_limit 在 [5G, +∞)范围内时, 内存使用达到 availmem_limit-1G 时触发淘汰。
- 当 sql_audidt 记录数超过 900 万条时,触发淘汰。
- sql_audit 根据以下标准决定是否停止淘汰:
- 如果是达到内存上限触发淘汰则:
- 当 avail_mem_limit 在 [64M, 100M] 时, 内存使用淘汰到 avail_mem_limit-40M 时停止淘汰。
- 当 avail_mem_limit 在 [100M, 5G] 时, 内存使用淘汰到 availmem_limit*0.6 时停止淘汰。
- 当 avail_mem_limit 在 [5G, +∞] 时, 内存使用淘汰到 availmem_limit-2G 时停止淘汰。
- 如果是达到记录数上限触发的淘汰则淘汰到 800 万行记录时停止淘汰。
2. sql_audit视图字段介绍
字段名称 类型 描述 SVR_IP varchar(32) ip地址 SVR_PORT bigint(20) 端口号 REQUEST_ID bigint(20) 请求的id号 TRACE_ID varchar(128) 这条语句的trace_id CLIENT_IP varchar(32) 发送请求的client ip CLIENT_PORT bigint(20) 发送请求的client port TENANT_ID bigint(20) 发送请求的租户id TENANT_NAME varchar(64) 发送请求的租户 名称 USER_ID bigint(20) 发送请求的用户id USER_NAME varchar(64) 发送请求的用户名称 SQL_ID varchar(32) 这条SQL的id QUERY_SQL varchar(32768) 实际的SQL语句 PLAN_ID bigint(20) 执行计划id AFFECTED_ROWS bigint(20) 影响行数 RETURN_ROWS bigint(20) 返回行数 PARTITION_CNT bigint(20) 该请求涉及的分区数 RET_CODE bigint(20) 执行结果返回码 EVENT varchar(64) 最长等待事件名称 P1TEXT varchar(64) 等待事件参数1 P1 bigint(20) unsigned 等待事件参数1的值 P2TEXT varchar(64) 等待事件参数2 P2 bigint(20) unsigned 等待事件参数2的值 P3TEXT varchar(64) 等待事件参数3 P3 bigint(20) unsigned 等待事件参数3的值 LEVEL bigint(20) 等待事件的level级别 WAIT_CLASS_ID bigint(20) 等待事件所属的class id WAIT_CLASS# bigint(20) 等待事件所属的class 的下标 WAIT_CLASS varchar(64) 等待事件所属的class 名称 STATE varchar(19) 等待事件的状态 WAIT_TIME_MICRO bigint(20) 该等待事件所等待的时间 TOTAL_WAIT_TIME_MICRO bigint(20) 执行过程所有等待的总时间 TOTAL_WAITS bigint(20) 执行过程总等待的次数 RPC_COUNT bigint(20) 发送rpc个数 PLAN_TYPE bigint(20) 执行计划类型 IS_INNER_SQL tinyint(4) 是否内部sql请求 IS_EXECUTOR_RPC tinyint(4) 当前请求是否rpc请求 IS_HIT_PLAN tinyint(4) 是否命中plan_cache REQUEST_TIME bigint(20) 开始执行时间点 ELAPSED_TIME bigint(20) 接收到请求到执行结束消耗 总时间 NET_TIME bigint(20) 发送rpc到接收到请求时间 NET_WAIT_TIME bigint(20) 接收到请求到进入队列时间 QUEUE_TIME bigint(20) 请求在队列等待事件 DECODE_TIME bigint(20) 出队列后decode时间 GET_PLAN_TIME bigint(20) 开始process到获得plan时间 EXECUTE_TIME bigint(20) plan执行消耗时间 APPLICATION_WAIT_TIME bigint(20) unsigned 所有application类事件的总时间 CONCURRENCY_WAIT_TIME bigint(20) unsigned 所有concurrency类事件的总时间 USER_IO_WAIT_TIME bigint(20) unsigned 所有user_io类事件的总时间 SCHEDULE_TIME bigint(20) unsigned 所有schedule类事件的时间 ROW_CACHE_HIT bigint(20) 行缓存命中次数 BLOOM_FILTER_CACHE_HIT bigint(20) bloom filter缓存命中次数 BLOCK_CACHE_HIT bigint(20) 块缓存命中次数 BLOCK_INDEX_CACHE_HIT bigint(20) 块索引缓存命中次数 DISK_READS bigint(20) 物理读次数 EXECUTION_ID bigint(20) 执行ID SESSION_ID bigint(20) session id RETRY_CNT bigint(20) 重试次数 TABLE_SCAN tinyint(4) 判断该请求是否含全表扫描 CONSISTENCY_LEVEL bigint(20) 一致性级别 MEMSTORE_READ_ROW_COUNT bigint(20) MEMSTORE中的读行数 SSSTORE_READ_ROW_COUNT bigint(20) SSSTORE中读的行数 REQUEST_MEMORY_USED bigint(20) 该请求消耗的内存 - 一些重要的事件间隔
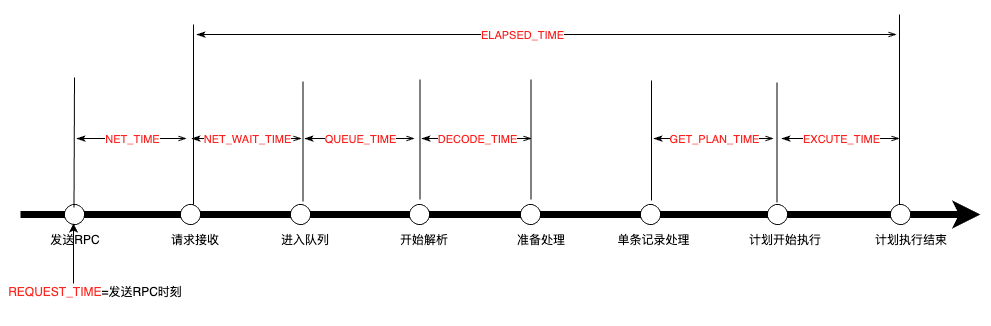
3. 基于sql_audit的诊断case
3.1. 最近100s某个租户的TOP SQL耗时监控
- 检查语句:
-- OceanBase 4.0.0.0及以上版本,请替换tenant_name的值为实际的租户名 select /*+read_consistency(weak),query_timeout(100000000)*/ SQL_ID,count(1),avg(ELAPSED_TIME),avg(EXECUTE_TIME),avg(QUEUE_TIME),avg(AFFECTED_ROWS),avg(GET_PLAN_TIME) from gv$ob_sql_audit where time_to_usec(now(6))-request_time (time_to_usec(now()) - 1000000) and request_time
3.3. 某个时间段请求次数排在 TOP-N 的 SQL
- 思路:我们首先可以查出某个时间段内数据库中所有 SQL 并按照 sql_id 级别进行聚合,再统计该时间段内每个SQL_ID的 QPS,取出top值。
- 语句:
-- OceanBase 4.0.0.0及以上版本,请替换tenant_id的值为实际租户的值 select SQL_ID, count(*) as QPS, avg(t1.elapsed_time) RT from oceanbase.gv$ob_sql_audit t1 where tenant_id = 1001 and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 10000000) and request_time (time_to_usec(now()) - 10000000) and request_time
3.4. 定位所有SQL中消耗CPU最多的sql
思路:消耗CPU的时间是elapsed_time - queue_time,因为queue_time的过程中是在排队,并不消耗cpu. 排查消耗CPU最多的sql在cpu飙高的场景非常有用
语句:
-- OceanBase 4.0.0.0及以上版本,请替换tenant_id的值为实际租户的值 select sql_id, substr(query_sql, 1, 20) as query_sql, sum(elapsed_time - queue_time) sum_t, count(*) cnt, avg(get_plan_time), avg(execute_time) from oceanbase.gv$ob_sql_audit where tenant_id = 1001 and request_time > (time_to_usec(now()) - 10000000) and request_time (time_to_usec(now()) - 10000000) and request_time3.5. 查看SQL的执行是否出现大量请求不合理的使用了远程执行
思路:sql_audit的PLAN_TYPE字段可以看到该SQL的执行计划类型,
- plan_type=1 :本地执行计划。性能最好。
- plan_type=2 : 远程执行计划。
- plan_type=3 : 分布式执行计划。包含本地执行计划和远程执行计划。
一般情况下,如果出现远程执行比较多时可能时出现切主或proxy客户端路由不准的情况。
语句:
-- OceanBase 4.0.0.0及以上版本,请替换tenant_id的值为实际租户的值 select count(*), plan_type from oceanbase.gv$ob_sql_audit where tenant_id = 1001 and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 10000000) and request_time (time_to_usec(now()) - 10000000) and request_time3.6. 查询全表扫描的SQL
思路:sql_audit的TABLE_SCAN字段是标识语句是否走了全表扫描,=1 表示全表扫描了。可以进一步分析一下SQL是否可以添加索引来防止全表扫描:
语句:
-- OceanBase 4.0.0.0及以上版本,请替换tenant_id的值为实际租户的值 select query_sql from oceanbase.gv$ob_sql_audit where table_scan = 1 and tenant_id = 1001 group by sql_id; -- OceanBase 4.0.0.0以下版本,请替换tenant_id的值为实际租户的值 select query_sql from oceanbase.gv$sql_audit where table_scan = 1 and tenant_id = 1001 group by sql_id;
3.7 如何分析RT突然抖动的SQL?
在线上如果出现RT抖动,但RT并不是持续很高的情况,可以考虑在抖动出现后,立刻将sql audit关闭(alter system set ob_enable_sql_audit = 0),从而确保该抖动的SQL请求在sql audit中存在;然后通过3.3章节的【某个时间段请求次数排在 TOP-N 的 SQL】,分析有异常的SQL。
如果在sql_audit中找到了对应的RT异常请求,则可以分析该请求在sql audit中记录:
- 查看retry次数是否很多(RETRY_CNT, 如果次数很多,则是否考虑是否有锁冲突或切主等情况)
- 查看queue time是不是很大(QUEUE_TIME字段)
- 查看获取执行计划时间(GET_PLAN_TIME), 如果时间很长,一般会伴随IS_HIT_PLAN = 0, 表示没有命中plan cache)
- 查看EXECUTE_TIME是否很长,如果很长,则
a. 查看是否有很长等待事件耗时
b. 查看访问的行数是否很多, 看SSSTORE_READ_ROW_COUNT, MEMSTORE_READ_ROW_COUNT两个字段, 比如大小账号场景可能导致rt抖动。
第一篇 “神医”的修炼秘籍——《OceanBase诊断系列》之一 第二篇 一起走进sql_audit性能视图——《OceanBase诊断系列》之二
- 检查语句:



