
数据库(SQL)中触发器(trigger)的使用以及视图(view)的基本实现
温馨提示:这篇文章已超过611天没有更新,请注意相关的内容是否还可用!
trigger_name必须是触发命令,最多64个字符,建议使用表名_trigger类型的缩写方式来命名。例如,ttlsa_posts_biDEFINER子句在激活触发器时检查访问权限,以确保触发器的安全使用。可以设置为在行记录更改之前或之后发生。trigger_event 定义触发器触发事件。例如 INSERT、LOAD DATA 和 REPLACE 语句。一个表上不能创建多个具有相同触发事件和触发时间的触发器。但是,您可以创建 BEFORE UPDATE 和 BEFORE INSERT 或 BEFORE UPDATE 和 AFTER UPDATE 触发器。trigger_body 子句包含触发执行的 SQL 语句。GOODS表中的数据实现使用视图查看具体信息。很多情况下,如果需要修改当前表,大多数时候会使用set new。
对于触发器,首先要明确以下几点:
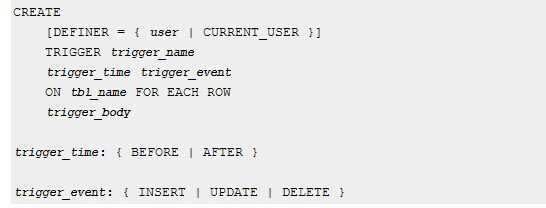
trigger_name必须是触发命令,最多64个字符,建议使用表名_trigger类型的缩写方式来命名。 例如,ttlsa_posts_bi(表ttlsa_posts,触发器发生在插入之前)DEFINER子句在激活触发器时检查访问权限,以确保触发器的安全使用。 trigger_time 定义触发器何时触发。 可以设置为在行记录更改之前或之后发生。 trigger_event 定义触发器触发事件。 触发的事件有: INSERT:在表中插入新行时触发。 例如 INSERT、LOAD DATA 和 REPLACE 语句。 UPDATE:当一行数据更改时触发。 如UPDATE语句。 DELETE:从表中删除行时触发。 例如 DELETE 和 REPLACE 语句。 注意:DROP TABLE 和 TRUNCATE TABLE 语句不会触发此触发器,因为它们不使用 DELETE。 同样,删除分区表也不会触发。 可能会出现混淆,例如 INSERT INTO ... ON DUPLICATE KEY UPDATE ... 取决于是否存在重复的键行。 一个表上不能创建多个具有相同触发事件和触发时间的触发器。 例如,您不能为一个表创建两个 BEFORE UPDATE 触发器。 但是,您可以创建 BEFORE UPDATE 和 BEFORE INSERT 或 BEFORE UPDATE 和 AFTER UPDATE 触发器。
FOR EACH ROW 子句定义触发器执行间隔。 FOR EACH ROW 子句定义触发器每隔一行执行一次操作,而不是对整个表执行一次。 trigger_body 子句包含触发执行的 SQL 语句。 可以是任何合法的语句,包括复合语句(需要使用BEGIN...END结构)、流程控制语句(if、case、while、loop、for、repeat、leave、iterate)、变量声明(declare)和允许赋值(set)、异常处理语句、条件语句,但这里的语句受到与函数相同的限制。 OLD和NEW 在触发器的SQL语句中,表中的任意列都可以关联起来,通过OLD和NEW列名来标识,如OLD.col_name、NEW.col_name。 OLD.col_name 指现有行中更新或删除之前的列值。 NEW.col_name 关联新行的列值以插入或更新现有行。 对于 INSERT 语句,只有 NEW 才是合法的。 否则会报错: ERROR 1363 (HY000): There is no OLD row in on INSERT trigger 对于 DELETE 语句,只有 OLD 是合法的。 否则会报错: ERROR 1363 (HY000): There is no NEW row in on DELETE trigger 对于 UPDATE 语句,可以同时使用 NEW 和 OLD。代码中实现的功能: 订单号从1401,订单自动更新,同时可以更新GOODS表中的数据(通过触发器实现)。 一共定义了三个触发器,包括ORDERS表的增删改查,同时触发修改。 GOODS表中的数据实现使用视图查看具体信息
需要注意的问题:
数据库中的分隔符语句:简单来说就是用来定义使用某个符号来结束语句,就像我们使用“;”一样默认结束语句。 当有时候我们想要执行更多的语句时,比如定义一个触发器,我们就需要重新定义它。 用符号代替“;”,直接使用“declare;” 当不需要的时候。

什么时候修改表中内容的值? 很多情况下,如果需要修改当前表(触发后发生改变的表被认为是触发表),大多数时候会使用set new。 直接属性声明。 当然此时需要使用before update/delete/insert,因为先Set再update才能成功修改值。
如何使用条件语句
if then
(执行语句)
else
(执行语句)
end if上面的代码:
DROP TABLE IF EXISTS GOODS;
DROP TABLE IF EXISTS ORDERS;
create table goods(
id int,
name char(10),
price int,
number int,
primary key(id)
);
create table orders(
order_id int auto_increment,
good_id int,
number int,
primary key(order_id)
)
auto_increment = 1401;
delimiter //
create trigger order_good
before insert on orders
for each row
begin
if new.number > 20 then
update goods set goods.number=goods.number - 20 where
new.good_id = goods.id;
set new.number = '20';
else
update goods set goods.number=goods.number -
new.number where new.good_id = goods.id;
end if;
end
//
create trigger cancel_order
after delete on orders
for each row
begin
update goods set goods.number = (goods.number + old.number)
where goods.id = old.good_id;
end
//
create trigger change_order
before update on orders
for each row
begin
if new.number > 20 then
update goods set goods.number=(goods.number + old.number
- 20) where new.good_id = goods.id;
set new.number = 20;
else
update goods set goods.number=(goods.number + old.number
- new.number) where new.good_id = goods.id;
end if;
end
create trigger
//
/*
INSERT INTO GOODS VALUES('1001', 'T-Shirt', '20', '1000');
INSERT INTO GOODS VALUES('1002', 'Mobile-pho', '1000', '20');
INSERT INTO GOODS VALUES('1003', 'Cup', '10', '800');
INSERT INTO ORDERS(GOOD_ID, NUMBER) VALUES('1001','100');
INSERT INTO ORDERS(GOOD_ID, NUMBER) VALUES('1002','10');
DELETE FROM ORDERS WHERE ORDERS.ORDER_ID = '1402';
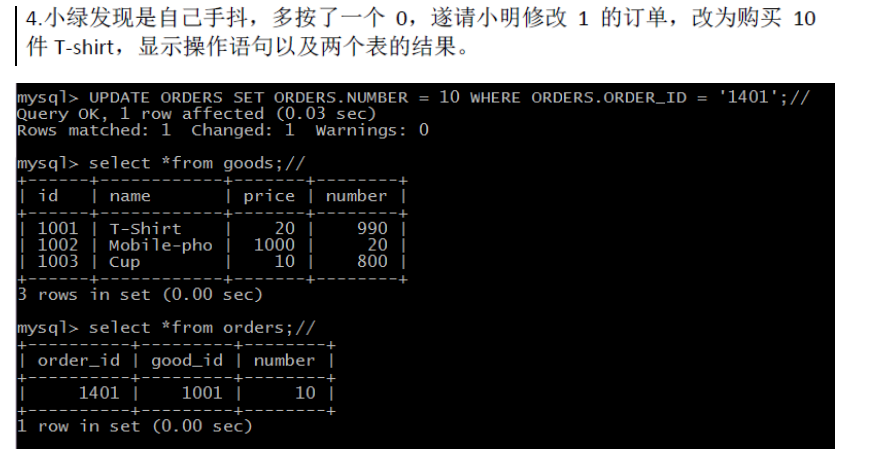
UPDATE ORDERS SET ORDERS.NUMBER = 10 WHERE ORDERS.ORDER_ID = '1401';
*/
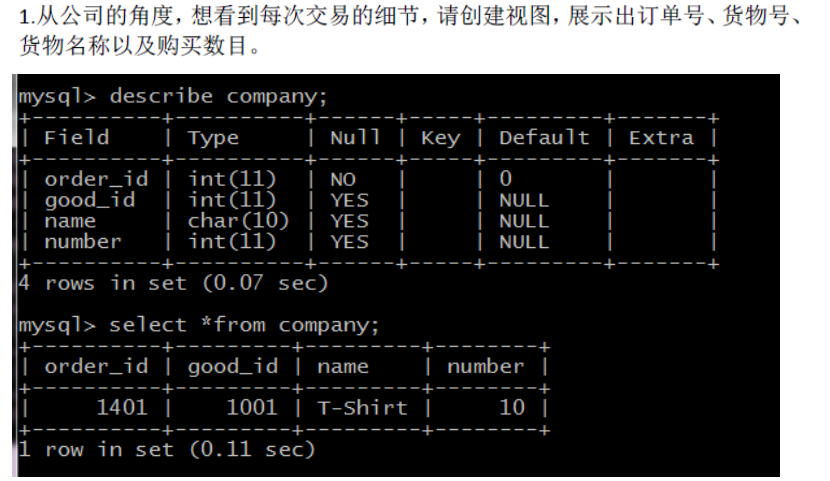
#创建视图:
create or replace view company(order_id, good_id, name, number)
as select orders.order_id, orders.good_id, goods.name, orders.number
from orders, goods
where orders.good_id = goods.id;
#展示视图:
select * from company;
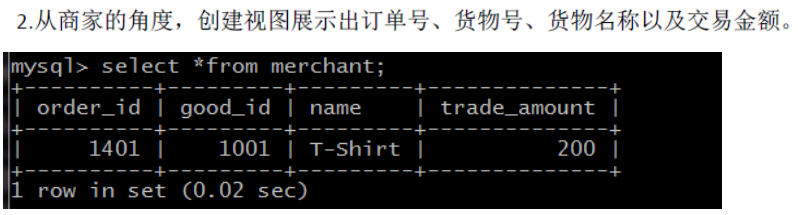
create or replace view merchant(order_id,good_id, name, trade_amount)
as select orders.order_id, orders.good_id, goods.name,
goods.price*orders.number
from orders, goods
where orders.good_id = goods.id;实现效果:

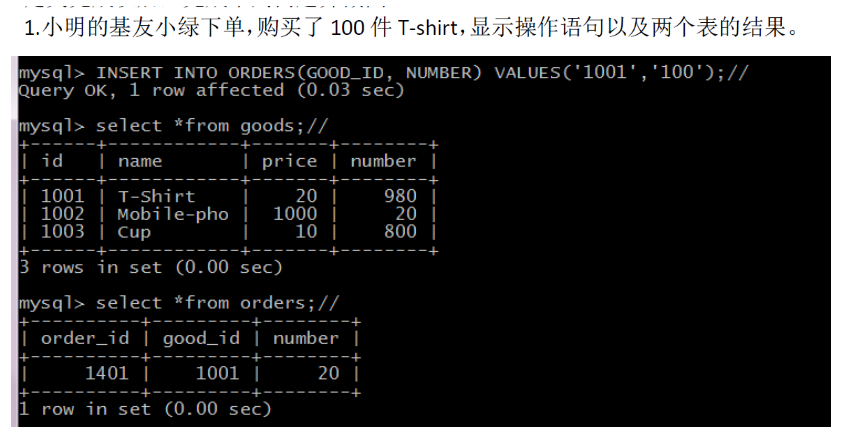
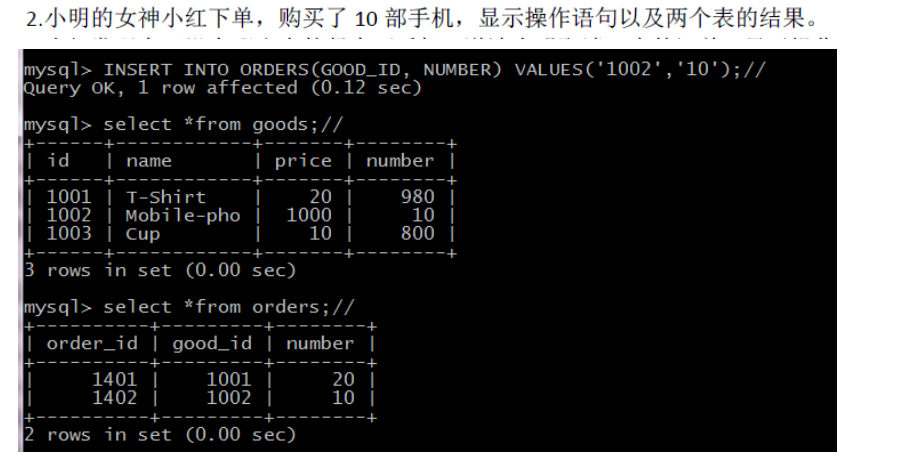
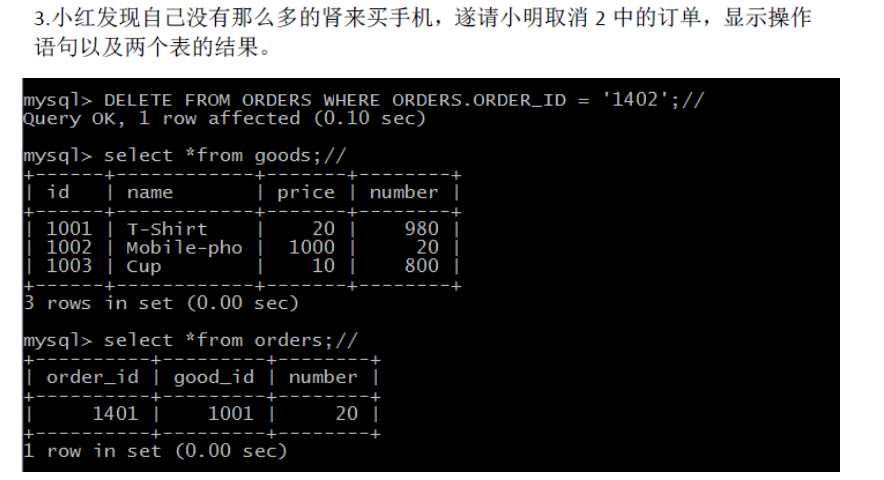
有关触发器的信息,另请参阅:
行为驱动开发(BDD)是一种优秀的开发模式。 它可以帮助开发者养成每天清理、关闭的好习惯,从而避免甚至消除“最后一刻”的情况,因此对于提高代码质量大有裨益。 其测试结构和设计形式与Gherkin语法相结合,使其对于团队所有成员(包括非技术人员)具有高度可读性。
所有代码都必须经过测试,这意味着系统上线时的缺陷会被最小化甚至消除。 这就需要搭配一套完整的测试套件,从整体上控制软件行为,以便检测和维护能够有序进行。 这就是BDD的魅力,你不兴奋吗?
什么是 BDD?
BDD的概念和理论源于TDD(测试驱动开发)。 与TDD类似,理论上的要点是在编码之前编写测试。 不同的是,除了使用单元测试进行细粒度测试外,整个程序还使用验收测试。 接下来我们结合Lettuce测试框架进行讲解。

BDD流程可以简单概括为:
在每个功能中,如有必要,请重复上述步骤。
敏捷开发中的 BDD
在敏捷开发中,BDD就像鱼如鱼得水。
如果项目的新功能和需求每周或每两周发生变化,团队需要配合快节奏的测试和编码。 Python 中的验收和单元测试可以帮助实现这一目标。
众所周知,验收测试使用包含测试以及单独测试的英语“属性”描述文件。 这样做的好处是整个项目团队都参与进来,除了开发人员之外,还有经理、业务分析师等非技术成员,不参与实际的测试过程。
特性文件的编写遵循全体人员可读的规则,使技术人员和非技术人员都能清楚地理解和接受。 如果只包含单元测试,可能会导致需求分析不完整或无法达成共识。 接受测试的最大优点是适用性强,无论项目大小,都可以自由使用。
小黄瓜语法
验收测试通常使用 Gherkin 编写,它来自 Cucumber 框架并用 Ruby 编写。 Gherkin 语法非常简单。 在Lettuce Python中,主要用以下8点来定义特征和测试:
安装
Lettuce包的安装可以使用Python中常用的pip install语句完成:
$ pip install lettuce
$ lettuce /path/to/example.feature 用于运行测试。 您一次只能运行一个测试文件,也可以提交目录名来运行该目录下的所有文件。
为了使编写和使用测试更容易,我们建议还安装nosetests:

$ pip install nose
轮廓
功能文件以英语编写,描述了测试所涵盖的程序范围。 还包括创建测试的任务。 换句话说,除了编写测试之外,您还必须约束自己在程序的各个方面编写良好的文档。 这样做的好处是让自己对代码上下有清醒的认识,知道下一步该做什么。 随着项目规模的扩大,文档的重要性会逐渐显现; 例如,审查某个函数或对调用 API 进行回溯等。
接下来,将结合 TDD 中的实例创建属性文件。 此示例是一个用 Python 编写的简单计算器,它将演示编写测试的基本方法。 目录构成建议创建两个文件夹,一个是app,用来放置calculator.py等代码文件;一个是app,用于放置calculator.py等代码文件; 另一个是tests,用来放置feature文件夹。
calculator.py:
class Calculator(object):
def add(self, x, y):
number_types = (int, long, float, complex)
if isinstance(x, number_types) and isinstance(y, number_types):
return x + y
else:
raise ValueError
功能文件calculator.feature位于tests/features目录下
Feature: As a writer for NetTuts I wish to demonstrate How easy writing Acceptance Tests In Python really is. Background: Given I am using the calculator Scenario: Calculate 2 plus 2 on our calculator Given I input "2" add "2" Then I should see "4"
从这个例子中不难看出,属性文件的描述非常简单,所有成员都可以理解。
属性文件的三个要点:
步骤文件
除了特征文件之外,步骤文件也是必要的,这就是“见证奇迹的时刻”。 显然,特征文件本身不会产生任何结果; 需要将step文件依次与Python执行代码一一映射,才有最终的结果输出。 这里应用了正则表达式。
正则表达式? 会不会太复杂了? 事实上,在 BDD 世界中,正则表达式通常用于捕获整个字符串或从某一行获取变量。 所以熟能生巧。
正则表达式? 在测试中使用会不会太复杂? 不是生菜,但很简单。
以下是相应步骤文件的准备:
from lettuce import *
from nose.tools import assert_equals
from app.calculator import Calculator
@step(u'I am using the calculator')
def select_calc(step):
print ('Attempting to use calculator...')
world.calc = Calculator()
@step(u'I input "([^"]*)" add "([^"]*)"')
def given_i_input_group1_add_group1(step, x, y):
world.result = world.calc.add(int(x), int(y))
@step(u'I should see "([^"]+)"')
def result(step, expected_result):
actual_result = world.result
assert_equals(int(expected_result), actual_result)
文件的第一部分是标准导入措辞。 比如Calculator的接入和Lettuce工具的导入,以及nosetest包中assert_equals判断方法的导入。 接下来,您可以开始为属性文件的每一行定义步骤。 如前所述,正则表达式通常用于提取整个字符串,除非有时需要在某一行访问变量。
在这个例子中,@step中起到了解码和提取的作用; u 字母表示 unicode 编码中的表达式执行。 接下来就是用正则表达式来匹配引用的内容,这里是要添加的数字。
然后将变量传递给Python方法。 变量名可以任意定义。 这里,x和y用作计算器add方法的传入变量名。
另外,还需要引入世界变量的使用。 world是一个全局容器,允许在同一场景的不同步骤中使用变量。 否则,所有变量仅可用于它们所在的方法。 例如,在某个步骤中存储add方法的运算结果,在另一个步骤中确定结果。

功能执行
功能文件和步骤文件完成后,可以运行测试看看是否通过。使用内置测试运行器执行 Lettuce 非常简单,例如
lettuce test/features/calculator.feature: $ lettuce tests/features/calculator.feature Feature: As a writer for NetTuts # tests/features/calculator.feature:1 I wish to demonstrate # tests/features/calculator.feature:2 How easy writing Acceptance Tests # tests/features/calculator.feature:3 In Python really is. # tests/features/calculator.feature:4 Background: Given I am using the calculator # tests/features/steps.py:6 Given I am using the calculator # tests/features/steps.py:6 Scenario: Calculate 2 plus 2 on our calculator # tests/features/calculator.feature:9 Given I input "2" add "2" # tests/features/steps.py:11 Then I should see "4" # tests/features/steps.py:16 1 feature (1 passed) 1 scenario (1 passed) 2 steps (2 passed)
Lettuce的输出非常整洁,它清楚地显示了哪一行配置文件代码被执行,然后成功执行的行以绿色突出显示。 另外,还显示正在运行的特征文件和行号,这对于测试失败时查找特征文件中的缺陷行非常有帮助。 输出的末尾是功能、场景、执行步骤数和传递次数的摘要。 本示例中所有测试均通过。 但如果出现问题,Lettuce将如何处理呢?
首先,需要修改calculator.py代码,将add方法改为两个数字相减:
class Calculator(object):
def add(self, x, y):
number_types = (int, long, float, complex)
if isinstance(x, number_types) and isinstance(y, number_types):
return x - y
else:
raise ValueError
再次运行一下,看看Lettuce是如何解释这个错误的:
$ lettuce tests/features/calculator.feature
Feature: As a writer for NetTuts # tests/features/calculator.feature:1
I wish to demonstrate # tests/features/calculator.feature:2
How easy writing Acceptance Tests # tests/features/calculator.feature:3
In Python really is. # tests/features/calculator.feature:4
Background:
Given I am using the calculator # tests/features/steps.py:6
Given I am using the calculator # tests/features/steps.py:6
Scenario: Calculate 2 plus 2 on our calculator # tests/features/calculator.feature:9
Given I input "2" add "2" # tests/features/steps.py:11
Then I should see "4" # tests/features/steps.py:16
Traceback (most recent call last):
File "/Users/user/.virtualenvs/bdd-in-python/lib/python2.7/site-packages/lettuce/core.py", line 144, in __call__
ret = self.function(self.step, *args, **kw)
File "/Users/user/Documents/Articles - NetTuts/BDD_in_Python/tests/features/steps.py", line 18, in result
assert_equals(int(expected_result), actual_result)
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/unittest/case.py", line 515, in assertEqual
assertion_func(first, second, msg=msg)
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/unittest/case.py", line 508, in _baseAssertEqual
raise self.failureException(msg)
AssertionError: 4 != 0
1 feature (0 passed)
1 scenario (0 passed)
2 steps (1 failed, 1 passed)
List of failed scenarios:
Scenario: Calculate 2 plus 2 on our calculator # tests/features/calculator.feature:9
显然,实际结果0与预期结果4不一致。Lettuce清楚地表明了问题所在,接下来就是调试排查,直到通过为止。
其他工具
Python中也提供了很多不同的工具来执行类似的测试,这些工具基本上都源自Cucumber。 例如:
无论使用什么工具,只要熟练使用一种工具,自然就能掌握其他工具。 熟悉教程文档是成功的第一步。
优势
充满信心地重构代码
使用完整的测试套件的优点是显而易见的。 找到一个强大的测试套件会让代码重构事半功倍,让你充满信心。
随着项目规模的不断扩大,缺乏有效的工具将会导致回溯和重构变得困难。 如果有一套完整的验收测试与每个功能一一对应,那么变更工作就会有条不紊地进行,而不会对现有的功能模块造成破坏。
所有成员都可以参与的验收测试将大大提高团队的战斗力,并从一开始就朝着同一个目标前进。 程序员可以专注于精确的目标,避免在需求范围内失去控制; 测试人员可以一一查看功能文件,以最大限度地提高测试过程。 最终形成良性循环,使程序的每一个功能都得到完美的交付。
审查
结合上述流程和工具,我们在过去合作过的团队中取得了良好的成果。 BDD 开发方法使整个团队保持专注、自信、充满活力,并最大限度地减少潜在错误。



