
【大语言视觉助手+LLaVA1.5】23.10.LLaVA-1.5改善后视觉语言大模型: Improved Baselines with Visual Instruction Tuning
LLaVa 家族 (Large Language and Vision Assistant )
官方资源汇总: 项目主页 || https://huggingface.co/liuhaotian
23.04.LLaVA1.0论文: Large Language and Vision Assistant(Visual Instruction Tuning)
23.06 LLaVA-Med(医学图片视觉助手): Training a Large Language-and-Vision Assistant for Biomedicine in One Day
23.10 LLaVA-1.5论文: Improved Baselines with Visual Instruction Tuning
23.11 LLaVA-Plus(外接其他模型工具)**:LLaVA-Plus: Large Language and Vision Assistants that Plug and Learn to Use Skills
24.01 LLaVA-1.6 博客(论文还未出): LLaVA-NeXT: Improved reasoning, OCR, and world knowledge

图from 多模态综述
一、前置解析博客、论文
23.04.LLaVA1.0:.论文解析、原理、本地部署: (一)
【LLaVA所用的预训练大语言模型LLMs】23.03.Vicuna: 类似GPT4的开源聊天机器人( 90%* ChatGPT Quality)
参考的论文 (可跳过)
22.02.BLIP 图片简单描述生成: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
23.06.BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
23.06.InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
23.08.Qwen-VL 阿里的视觉语言模型: A Frontier Large Vision-Language Model with Versatile Abilities
二、LLaVA1.5的简介
2.1 结构与改进
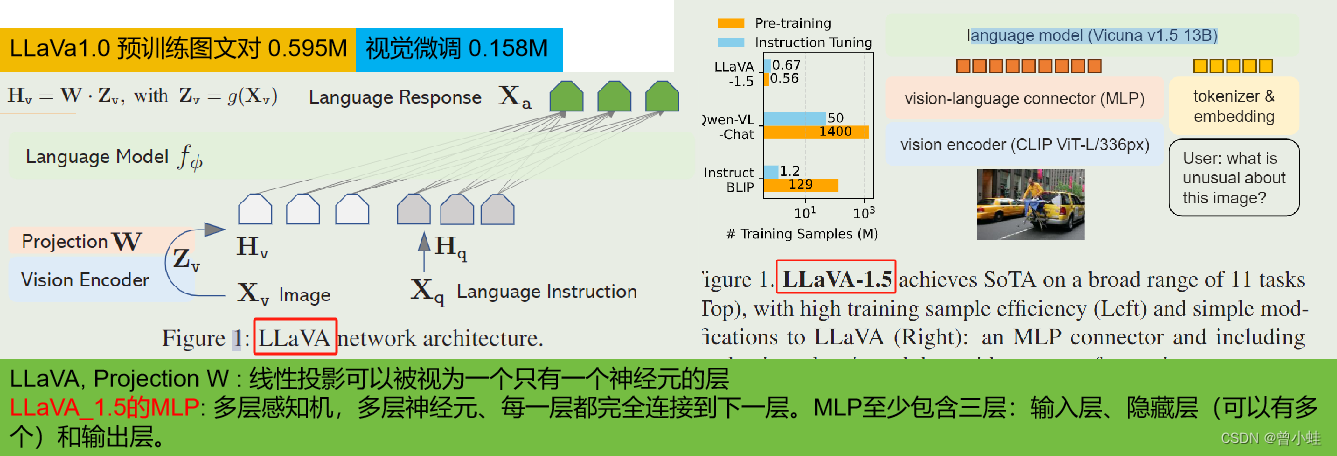
下图左边部分为LLaVA1.0的模型结构与训练数据量,右侧为改进LLaVA1.5
- 结构上,将视觉特征提取器从 CLIP-vit-L-14 (224x224图像输入)改为了CLIP-vit-L/336(将真实图像resize到336x336再输入编码器)
- 结构上,视觉特征从线性映射(单个神经元),改进为多层告感知机(MLP)
- 数据上,大量提高数据量,特别是视觉微调 158K到了560K。。
- 训练上,LLaVA1.5可以使用Lora微调:Finetune_Custom_Data.md
2.2 论文展示效果
2.2.1 原文表3 回答棘手问题
在提示验证问题时可以检测和回答棘手的问题。

2.2.2 原图4 LLAAVA-1.5 可以根据所需的格式从图像中提取信息和答案,
但与 GPT-4V 相比有一些差距

2.3 性能测试(在12个专门测试数据集)
2.3.0 测评数据集全称
VQAv2: Visual Question Answering version 2
GQA: General Question Answering
VizWiz: Visual Question Answering for the visually impaired
TextVQA: Text-based Visual Question Answering
SQA-IMG: Sequential Question Answering - Images
。。。。
2.3.1 与当时的 InstructBLIP ,Qwen-VL对比

2.3.2 具体指标 (基础大语言模型、图像分辨率、微调数据量)
PT: 预训练的数据量(文本图像对,训练图像特征到语言特征)
IT: 详细视觉图片微调,基于GPT4制作

2.4 原文摘要
大型多模态模型 (LMM或MLLM) 最近在视觉指令微调(visual instruction tuning)方面显示出令人鼓舞的进展。我们注意到,我们表明 LLAVA 中的全连接视觉语言跨模态连接器(fully-connected vision-language cross-modal connector*)非常强大和数据效率。
通过对LLAVA1.0 进行简单的修改,即使用带有MLP projection 的CLIP-ViT-L-336px,
并添加具有简单响应格式提示的面向学术任务的VQA数据,我们建立了更强的模型——可以在11个基准测试中实现最先进的性能。
最终的 13B 模型仅使用约 1.2M (120W数据)公开可用数据,并在单8卡-A100 训练约 1 天的完整训练
三、本地部署
主要参考上一篇博文:第三小节,本地部署部分。
23.04.LLaVA1.0:.论文解析、原理、本地部署: (一)

四、训练用到的数据集 (了解后,才知道如何制作自己的数据集)
指令微调用到的对话数据集:主要由llava_v1_5_mix665k.json
- COCO: train2017
- GQA: images
- OCR-VQA: download script, ** .jpg** || huggingface 直接查看 || 论文
- TextVQA: train_val_images
- VisualGenome: part1, part2

整理后的结构
├── coco │ └── train2017 ├── gqa │ └── images ├── ocr_vqa │ └── images ├── textvqa │ └── train_images └── vg ├── VG_100K └── VG_100K_2文章目录
- LLaVa 家族 (`L`arge `L`anguage `a`nd `V`ision `A`ssistant )
- 一、前置解析博客、论文
- 参考的论文 (可跳过)
- 二、LLaVA1.5的简介
- 2.1 结构与改进
- 2.2 论文展示效果
- 2.2.1 原文表3 回答棘手问题
- 2.2.2 原图4 LLAAVA-1.5 可以根据所需的格式从图像中提取信息和答案,
- 2.3 性能测试(在12个专门测试数据集)
- 2.3.0 测评数据集全称
- 2.3.1 与当时的 **InstructBLIP ,Qwen-VL**对比
- 2.3.2 具体指标 (基础大语言模型、图像分辨率、微调数据量)
- 2.4 原文摘要
- 三、本地部署
- 四、训练用到的数据集 (了解后,才知道如何制作自己的数据集)



