
Java集成结巴中文分词器、Springboot项目整合jieba分词,实现语句最精确的切分、自定义拆词
文章目录
- 一、jieba介绍
- 二、集成
- 三、原理
- 四、自定义拆词
- 4.1、方式一:在源码的dict.txt中修改然后重新打包(推荐)
- 4.2、新建文件自定义拆词
- 五、其他问题
一、jieba介绍
jieba是一个分词器,可以实现智能拆词,最早是提供了python包,后来由花瓣(huaban)开发出了java版本。
源码:https://github.com/huaban/jieba-analysis
分词的模式
- search 精准的切开,用于对用户查询词分词
- index 对长词再切分,提高召回率
二、集成
1.引入相关依赖
com.huaban jieba-analysis 1.0.22.核心代码
public class Demo { public static void main(String[] args) { JiebaSegmenter js = new JiebaSegmenter(); List resultList = js.sentenceProcess("我爱中国"); //[我, 爱, 中国] System.out.println(resultList); } }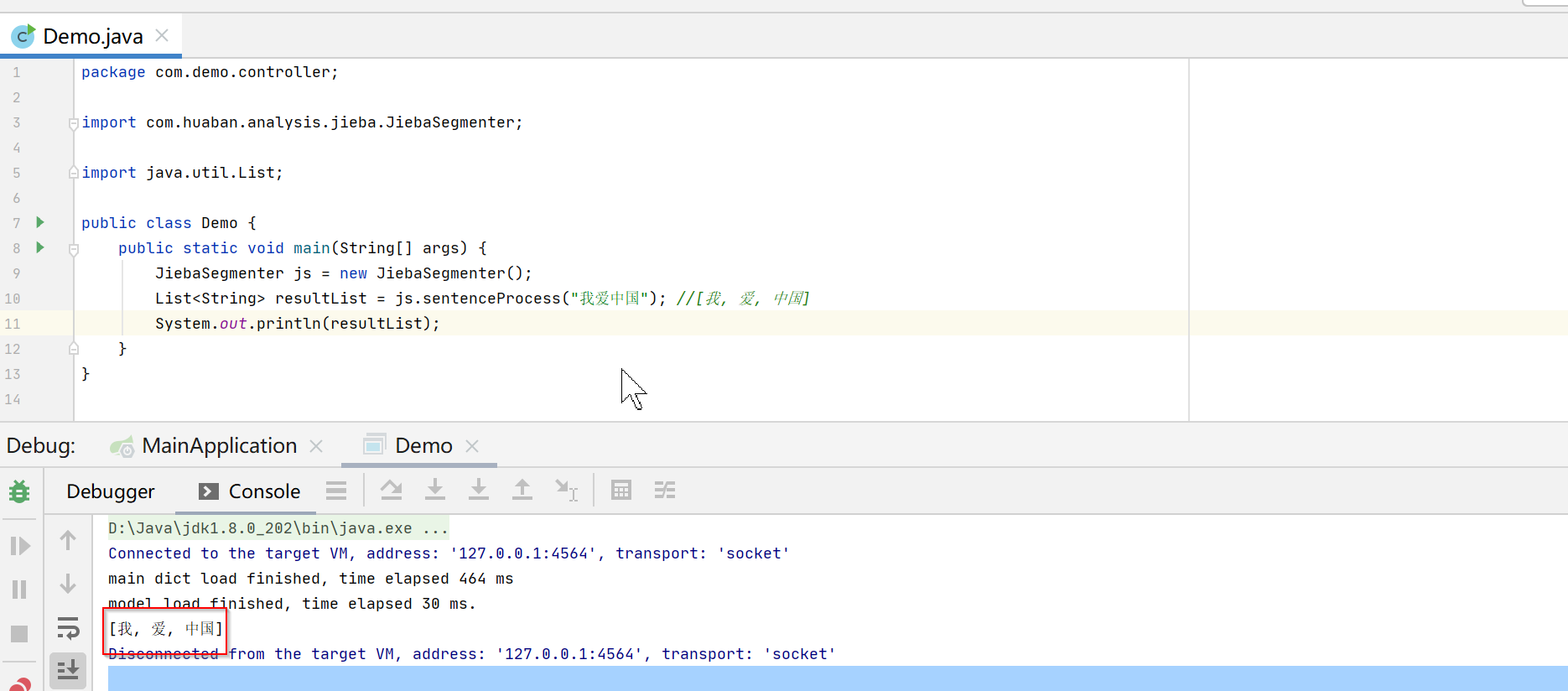
三、原理
为什么jieba可以实现智能拆词?是否可以自己增加拆词呢?
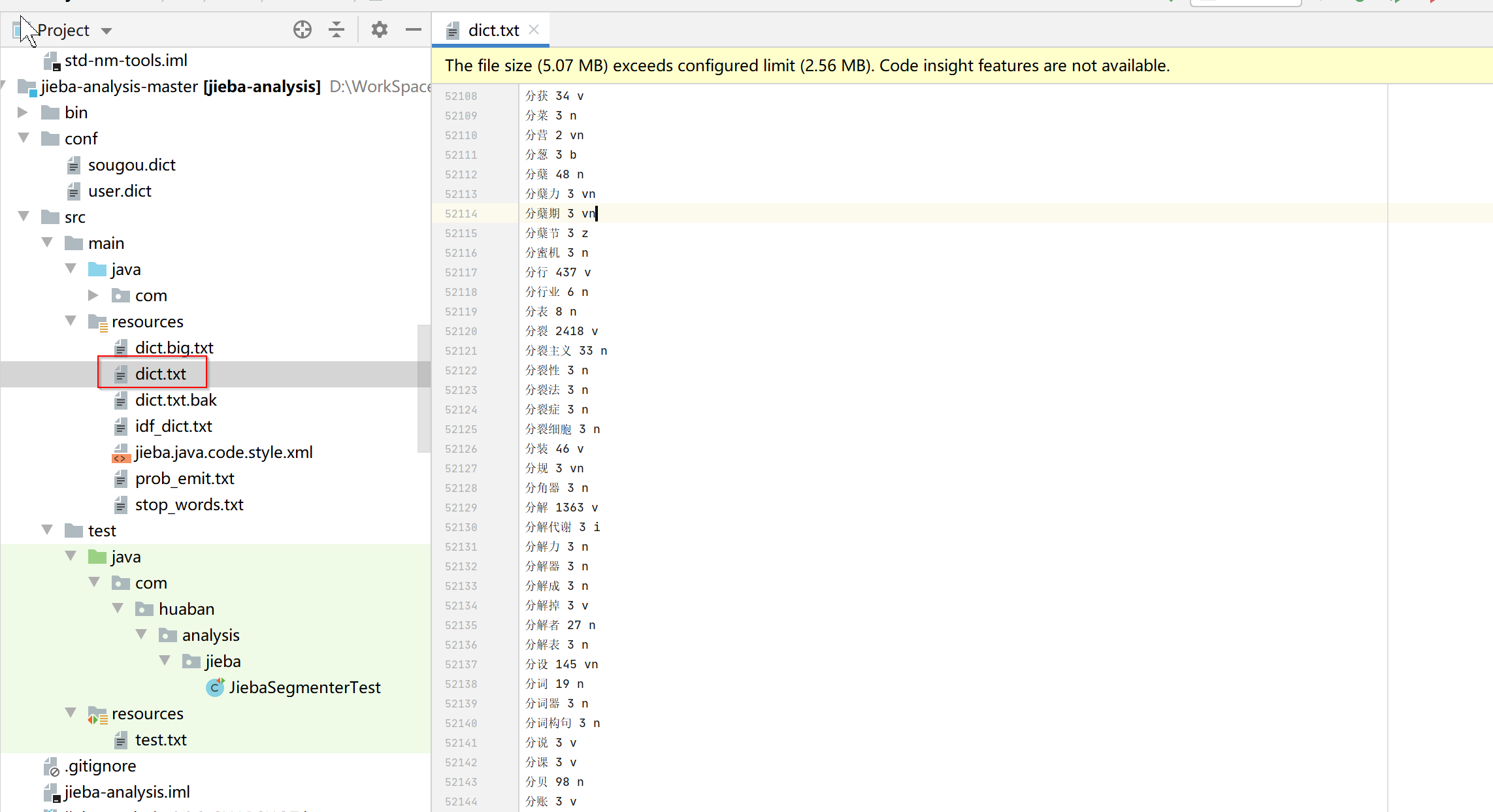
jieba项目resource目录下有个dict.txt文件,里面维护了非常多的拆词,jieba就是根据这个文件进行拆词的。自己也可以在这个文件中添加自定义拆词,或者新建一个文件。
四、自定义拆词
4.1、方式一:在源码的dict.txt中修改然后重新打包(推荐)
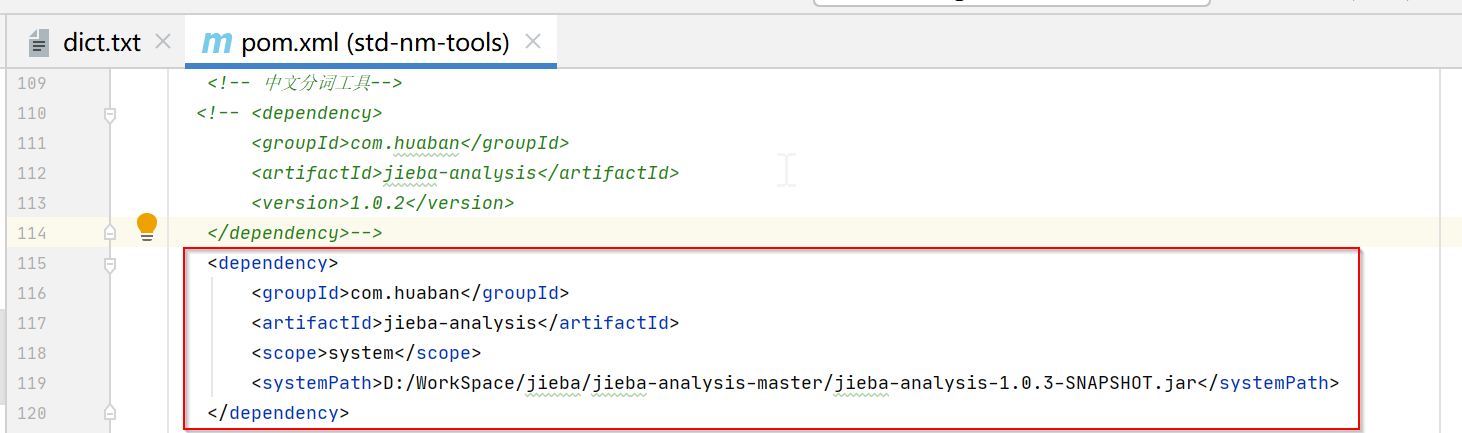
我们可以把源码下载下来,然后修改dict.txt文件后重新打包,这种方式是比较推荐的。还有一种方式就是新建一个txt文件然后引用,但是新增文件会导致在两个地方维护了拆词,而且新增文件中的拆词有时候会跟jieba里的dict.txt冲突,导致影响其他拆词。
1.下载源码
https://github.com/huaban/jieba-analysis
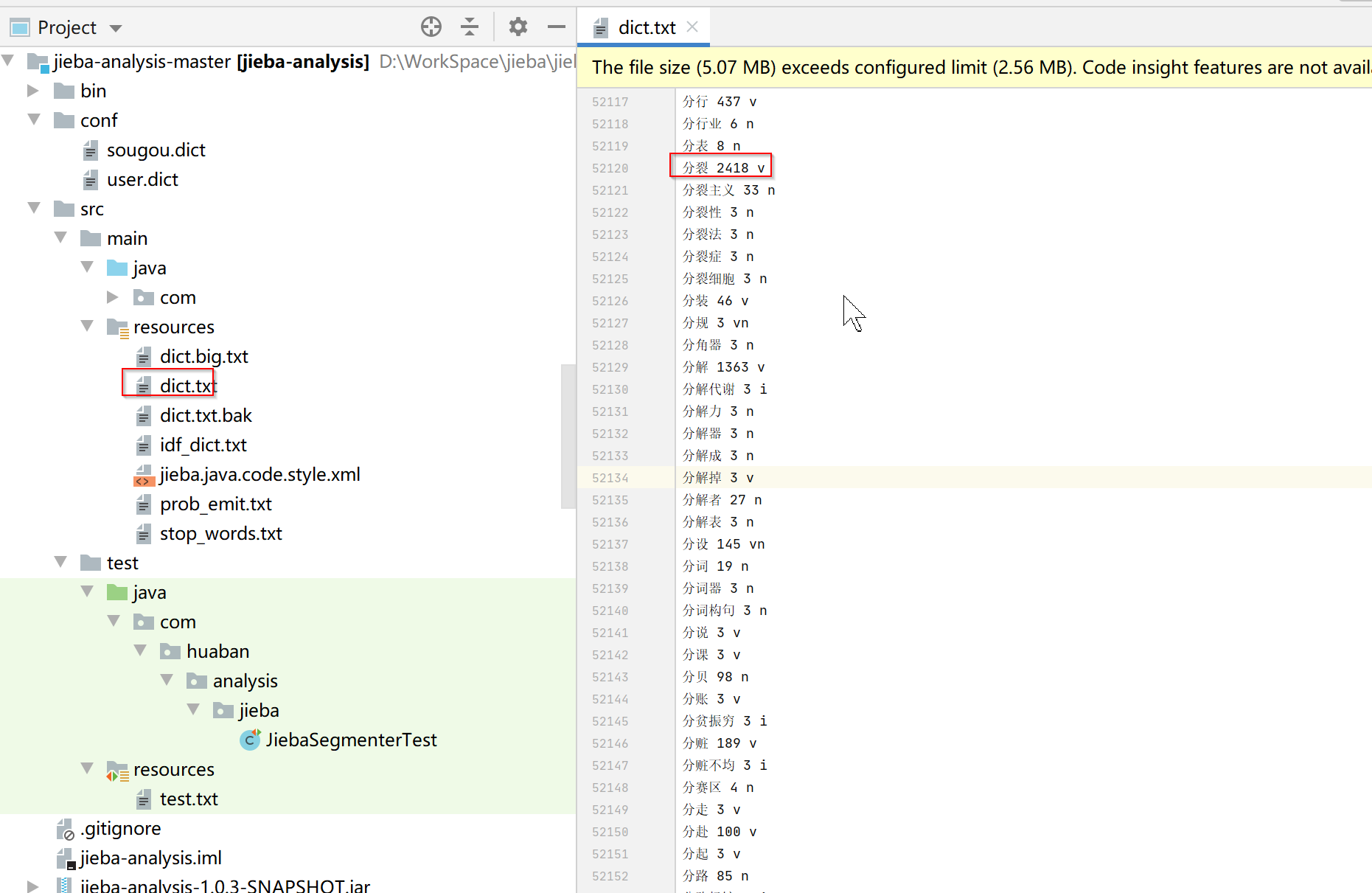
2.修改dict.txt文件
dict.txt文件中是按照字母顺序排序的,每一行包括分词、词频、词性
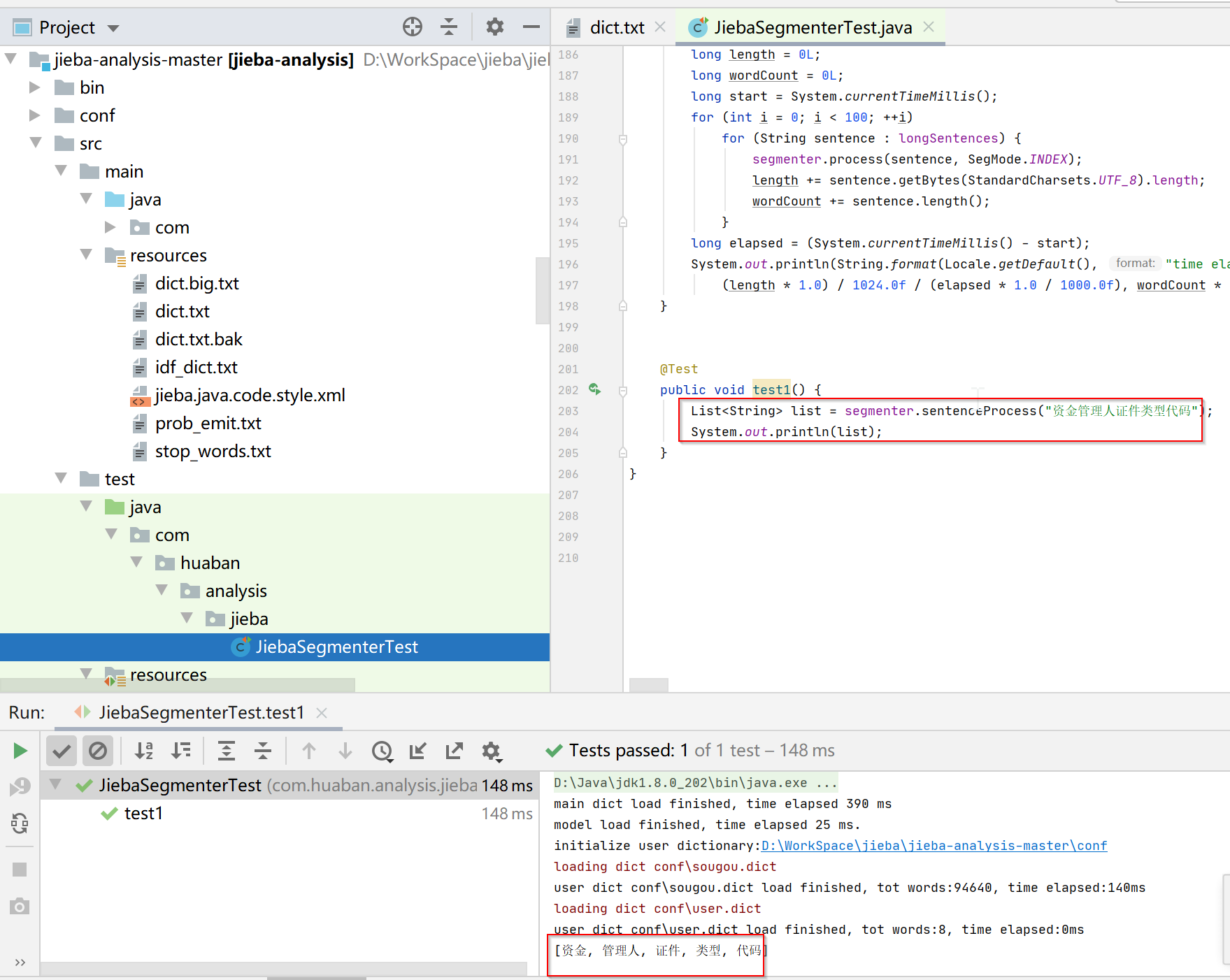
3.测试
4.重新打包并引用
4.2、新建文件自定义拆词
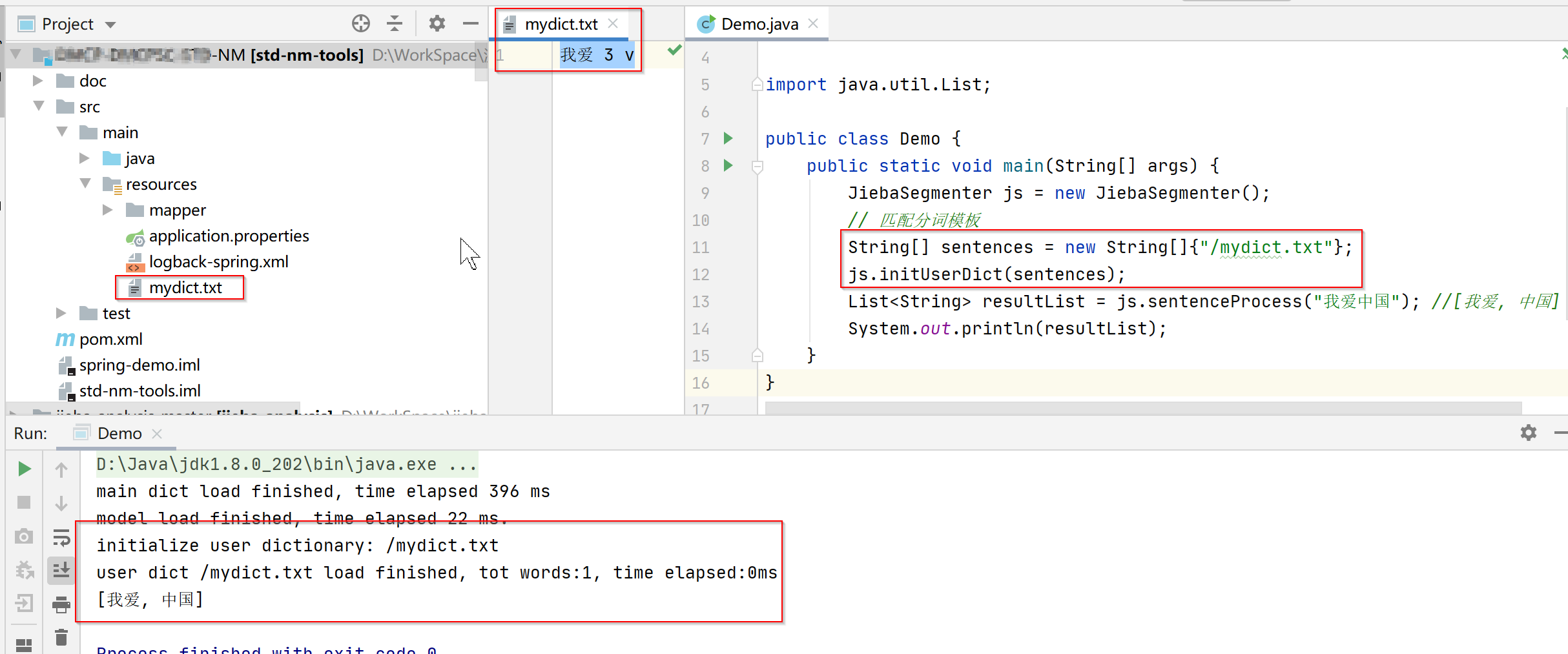
resource目录下新增txt文件,通过initUserDict方法进行初始化
五、其他问题
- 新增或修改拆词后可能会导致其他拆词出现问题,所以有条件的最好都测试一下
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



