
机器学习(五) -- 监督学习(7) --SVM1
系列文章目录及链接
上篇:机器学习(五) -- 监督学习(6) --逻辑回归
下篇:
前言
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
一、通俗理解及定义
1、什么叫支持向量机(What)
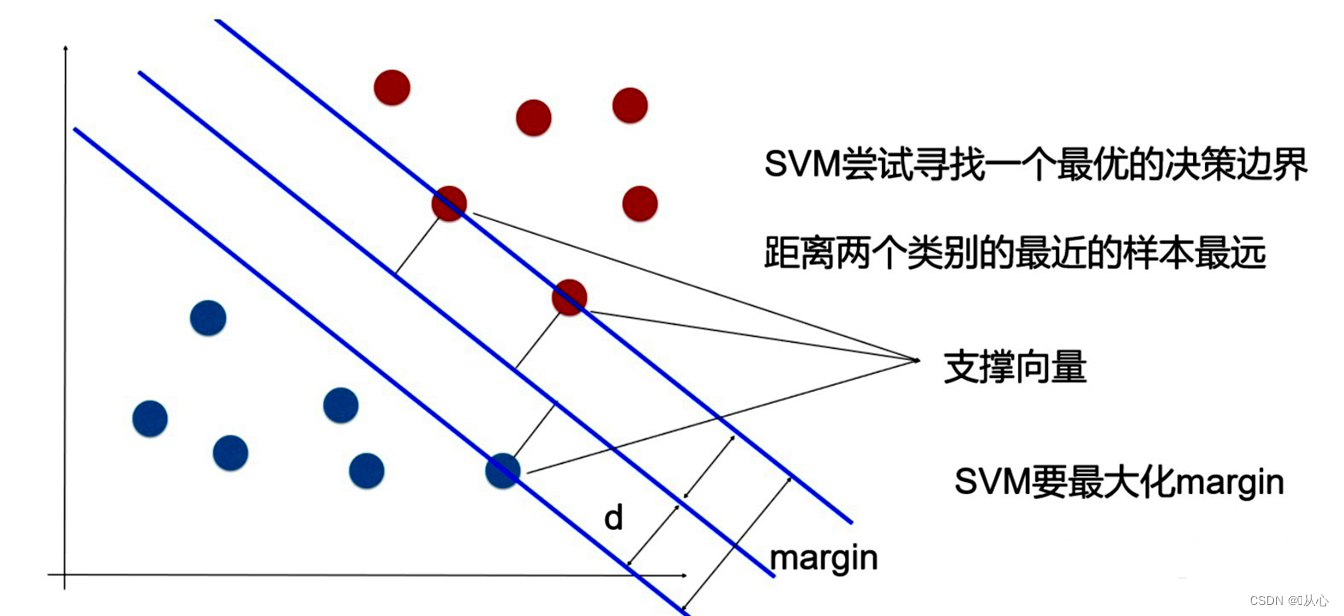
支持向量机(SVM,Support Vector Machine)是一种二类分类模型,他的基本模型是定义在特征空间上的间隔最大的线性分类器,SVM的学习策略就是间隔最大化。
间隔最大化,可以形式化为一个求解凸二次规划的问题,支持向量机的学习算法是求解凸二次规划的最优化算法。
相关概念
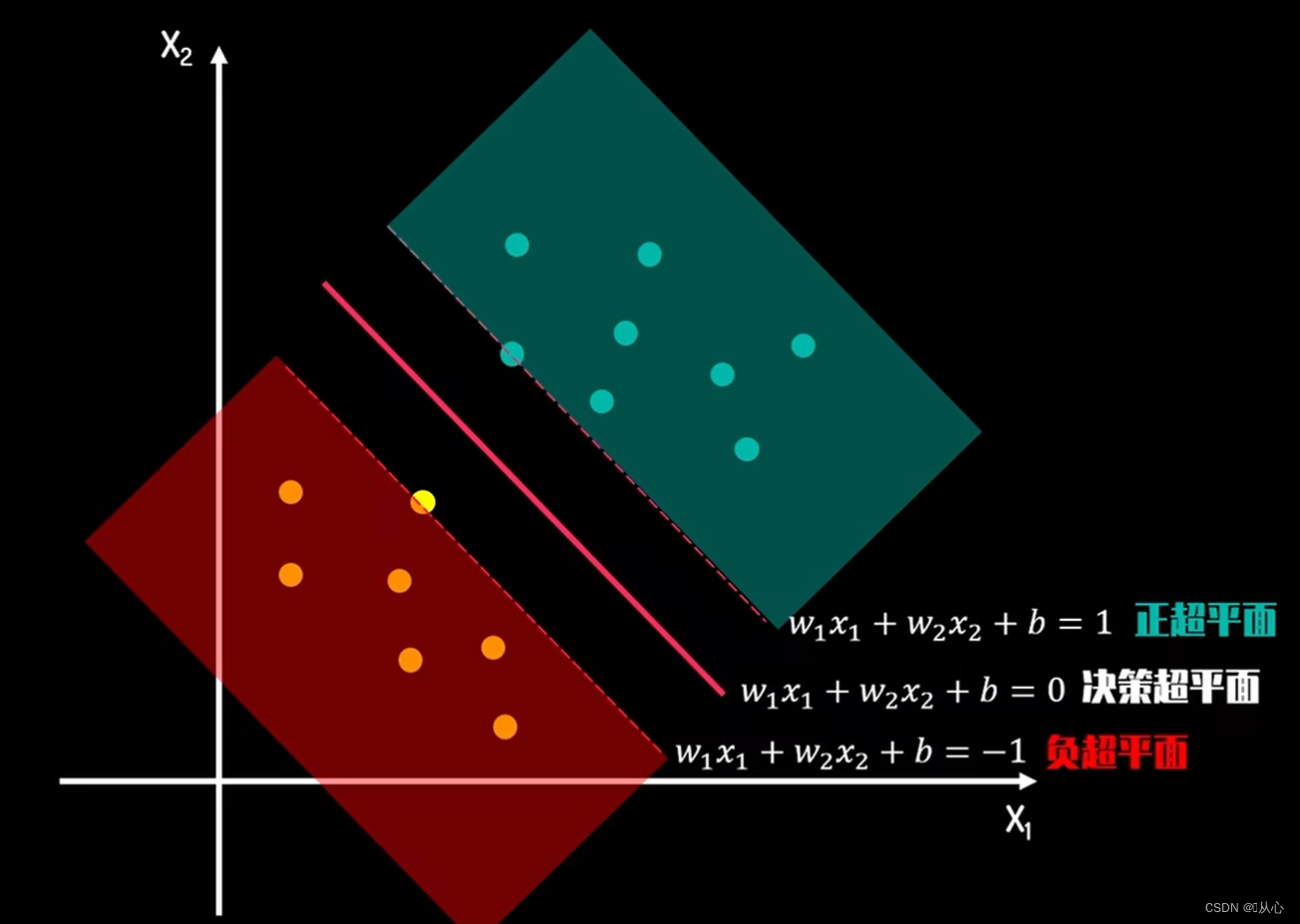
对于SVM来说,数据点若为p维向量,我们用p-1维的超平面(是决策边界,这里应该叫决策超平面)来分开这些点,
可能有许多超平面可以把数据分类。最佳超平面的一个合理选择就是以最大间隔把两个类分开的超平面。因此,SVM选择能够使离超平面最近的数据点的到超平面距离最大的超平面。
寻找最佳超平面的问题可以转化为求解两类数据的最大间隔问题。间隔正中就是我们要找的最佳超平面。
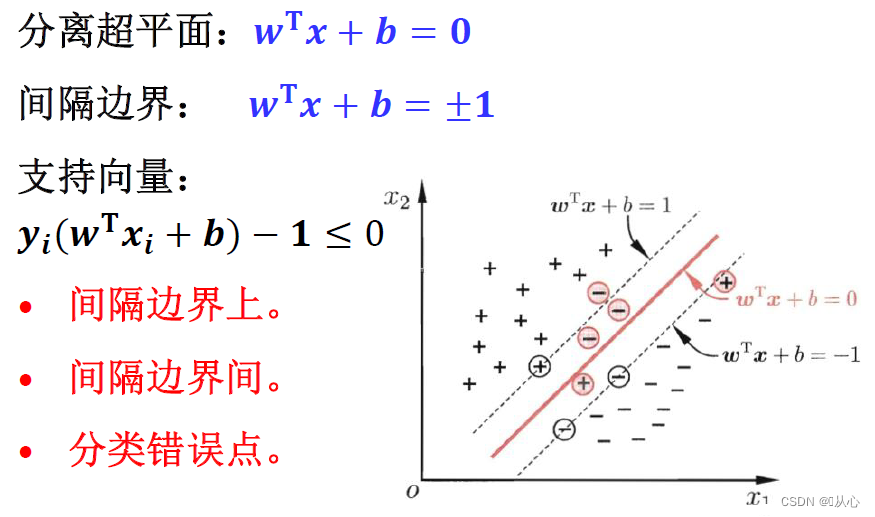
1.1、超平面
平面中的直线、空间中的平面之推广(n大于3才被称为“超”平面)。
超平面是n维欧氏空间中余维度等于一的线性子空间,也就是必须是(n-1)维度。
1.2、支持向量
在线性可分的情况下,训练数据集的样本点中与分离超平面距离最近的数据点称为支持向量。
1.3、间隔(margin)
这里的间隔就是指两类数据的支持向量形成的超平面(正、负超平面,间隔边界)之间的间隔。
间隔距离可以体现出两类数据的差异大小,间隔越大,两类数据差异越大,区分越容易。
2、支持向量机的目的(Why)
找一个使间隔最大化的超平面
由简至繁的模型包括
2.1、线性可分SVM
当训练数据线性可分时,通过硬间隔(hard margin)最大化,可以学习得到一个线性可分分类器,即硬间隔SVM,如上图的的H3。
2.2、线性SVM
当训练数据不能线性可分但是可以近似线性可分时,通过软间隔(soft margin)最大化,也可以学习到一个线性分类器,即软间隔SVM。
2.3、非线性SVM
当训练数据线性不可分时,通过使用核技巧(kernel trick)和软间隔最大化,可以学习到一个非线性SVM。
硬间隔、软间隔、核技巧具体后面讲解
3、怎么做(How)
先
二、原理理解及公式
1、数学基础
1.1、距离计算
点到点的距离
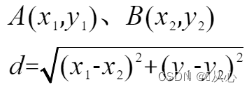
点到直线的距离
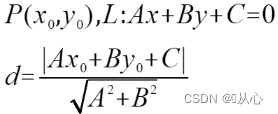
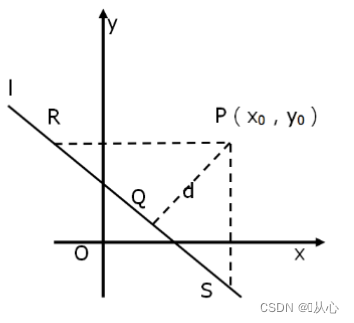
点到平面的距离

点到超平面的距离

1.2、凸优化
1.2.1、直线、线段

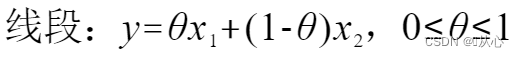
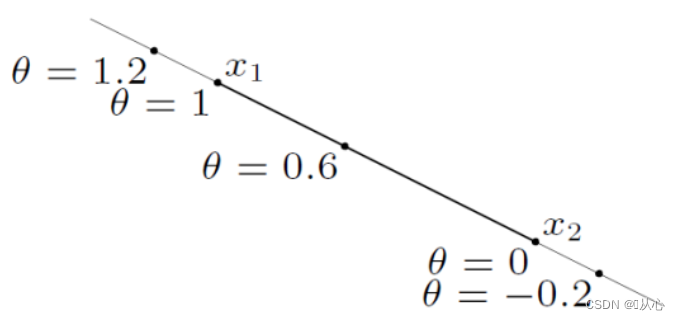
1.2.1、仿射集(Affine Set)、凸集(Convex Set)和锥(Cones)
1.2.1.1、仿射集

仿射集的推广:一个仿射集包含其中任意点的仿射组合。
仿射集的例子:
直线
平面
超平面
1.2.1.2、凸集

凸集的推广:一个凸集等价于集合包含其中所有点的凸组合。
凸集的例子:

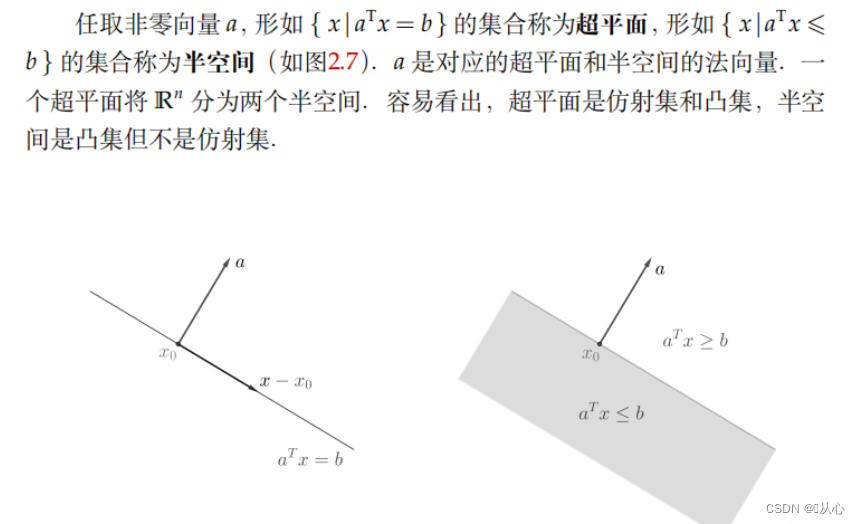
超平面和半空间:
1.2.1.3、锥

锥的例子:
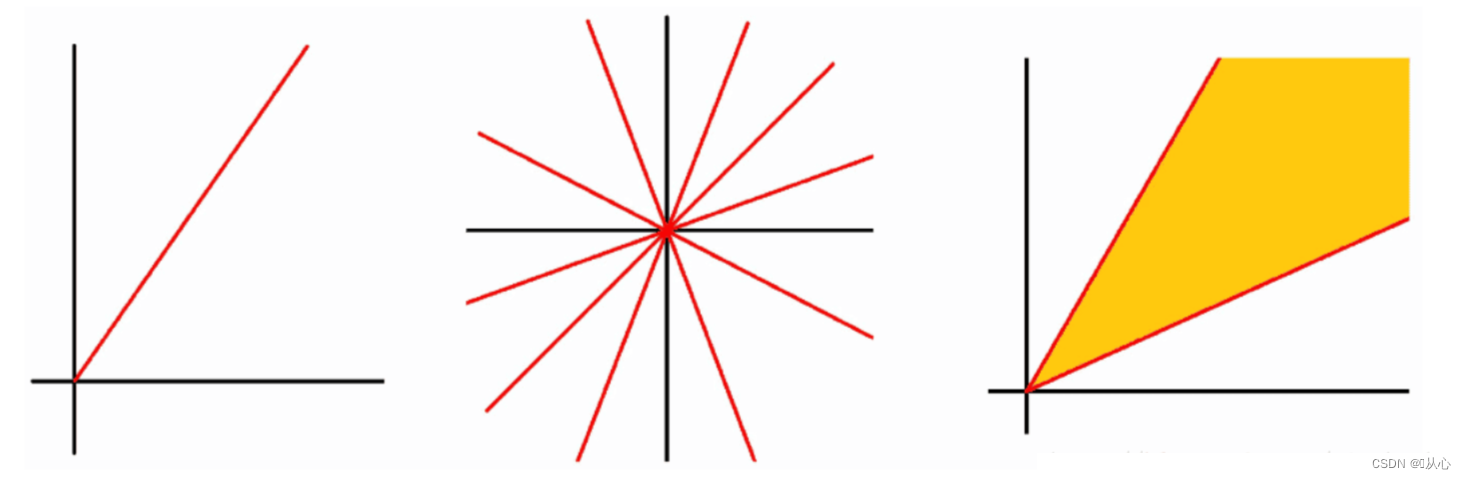
平面中过原点的射线,射线族,角
1.2.2、仿射包、凸包和锥包
1.2.2.1、仿射包
仿射包:集合C中的点的所有仿射组合组成的集合为C的仿射包,记为aff C:
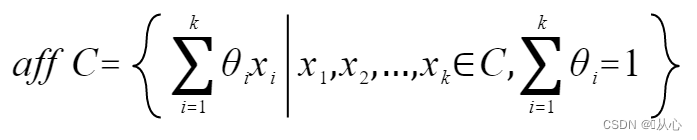
集合C的仿射包是包含C的最小的仿射集合
仿射维数:集合C的仿射维数为其仿射包的维数。
三角形的仿射维数为2
线段的仿射维数为1
球的仿射维数为3
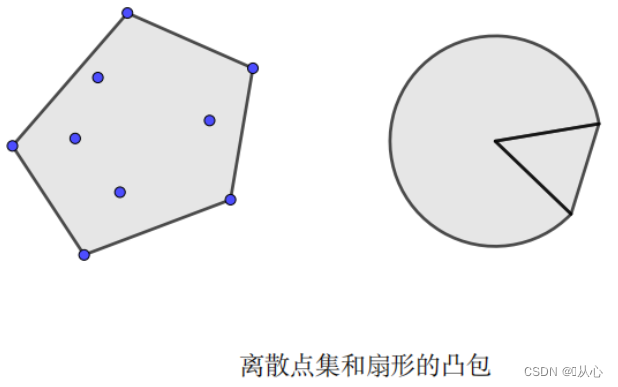
1.2.2.2、凸包
凸包:集合C中所有点的凸组合的集合称为凸包,记为conv C:
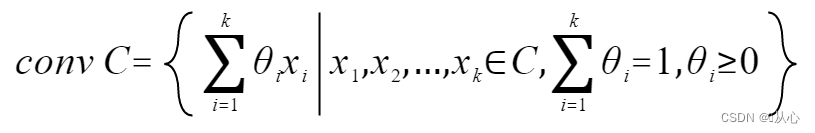
集合C的凸包是包含C的最小凸集。
1.2.2.3、锥包
锥包:集合C中元素的所有锥组合的集合称为锥包,记为cone C:
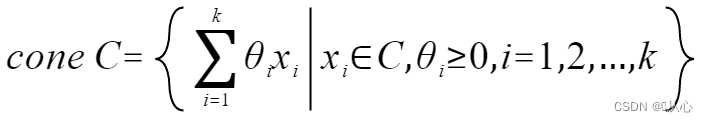
集合C的锥包是包含C的最小凸锥
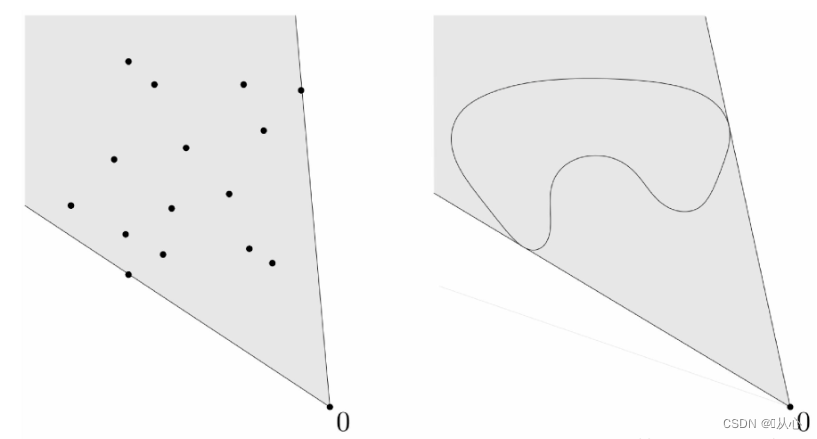
1.2.3、凸函数
通俗:两点之间的函数值小于两点连线的函数值
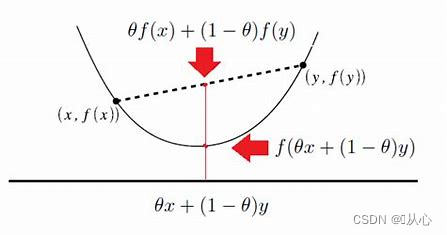
定义:

1.2.4、凸优化
凸优化,或叫做凸最优化,凸最小化,是数学最优化的一个子领域,研究定义于凸集中的凸函数最小化的问题。
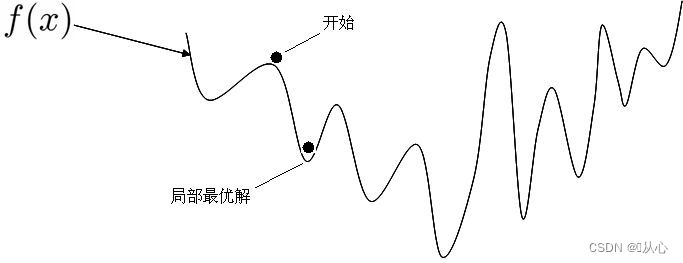
1、为什么要求是凸函数?
如果不是凸函数无法获得全局最优。
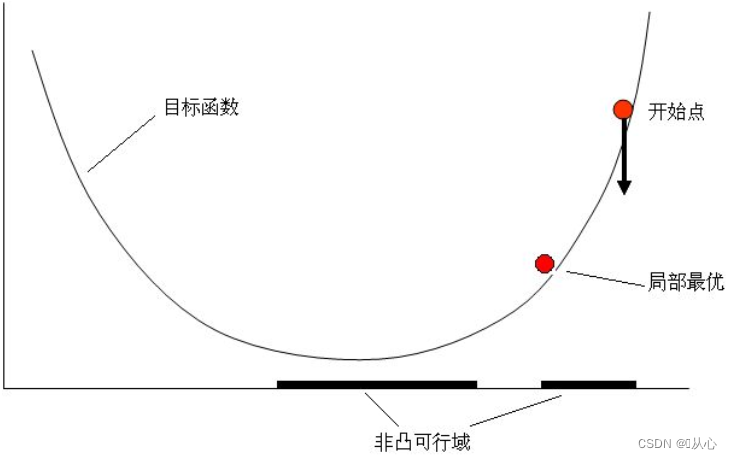
2、为什么是凸集?
如果不是凸集,也会导致局部最优。
通常将一个优化问题写成如下标准形式:

1.2.4.1常见凸优化问题
线性规划(Linear Programming,LP)
二次规划(Quadratic Programming,QP)
二次约束的二次规划(Quadratically Constrained Quadratic Programming,QCQP)
半定规划(Semidefinite Programming,SDP)
1.3、仿射函数
仿射函数(affine function)即由 1 阶多项式构成的函数,一般形式为 f(x)=Ax+b,这里A 是一个 m × k 矩阵,x 是一个k向量,b是一个 m 向量,实际上反映了一种从 k 维到 m 维的空间映射关系。
仿射函数的作用是维度改变或者形状、方向改变,这个过程叫做仿射变换。
特别的,当m = 1 时,向量转化为一个实数,维度由k降低到1(m)。
此外,当仿射函数的常数项b为零时,称为线性函数。
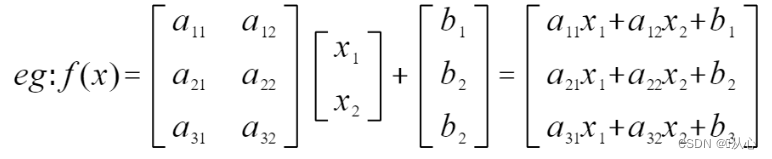
1.4、最优化问题
一般情况下,最优化问题会碰到下面三种:s.t.(约束条件)
无约束条件;
min f(x);
等式约束条件;
min f(x),
s.t. h_i(x)=0,i=1,2,…,n
(s.t. subject to 约束于)
不等式约束条件;
min f(x),
s.t. h_i(x)=0,i=1,2,…,n
g_j(x)=1
约束条件是不等式需要加入一个非负变量pi^2(简单理解:左边为0时,pi^2=0,左边为2时,pi^2=2)将不等式转化为等式约束,然后运用 拉格朗日乘子法,得到拉格朗日方程。

为求方程式极值,我们对w,b,λ_i,p_i求偏导,将得到的等式③代入等式④,得到新的等式

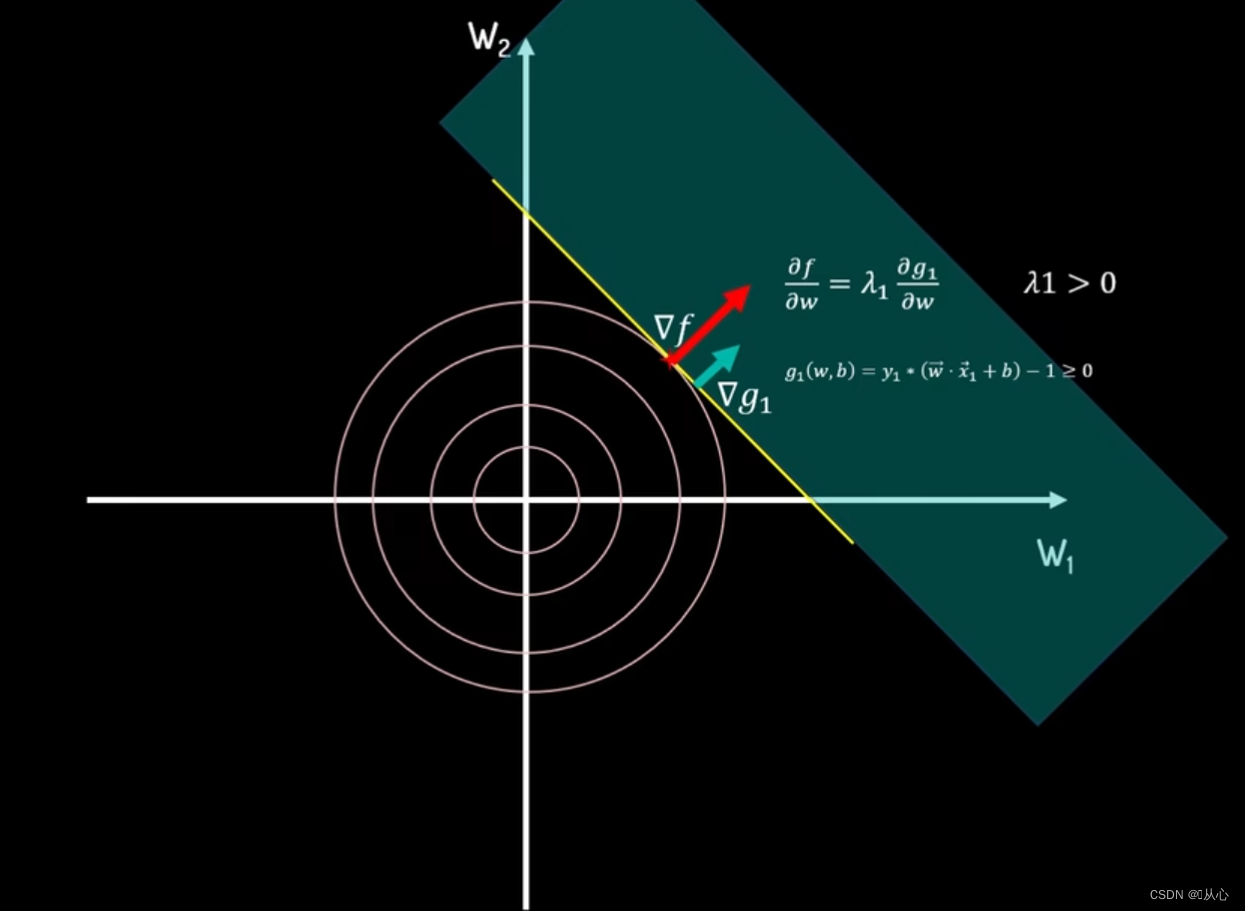
把λ_i看作违背约束条件的惩罚系数,当不满足约束条件时,即y_i*(wx+b)-1=0时,可行区域为绿色部分,最小值在等高线圆与约束边界相切处得到。此时f(w)的梯度grad f与g_1的梯度grad g_1的方向一致,大小可以通过λ_1进行调整。
当第二个约束条件g_2>=0加入,两约束边界的相交点为最优解,此时f(w)的梯度grad f可以由g_1的梯度grad g_1和g_2的梯度grad g_2分别乘以大于0的调整系数λ_1、λ_2相加组合而成。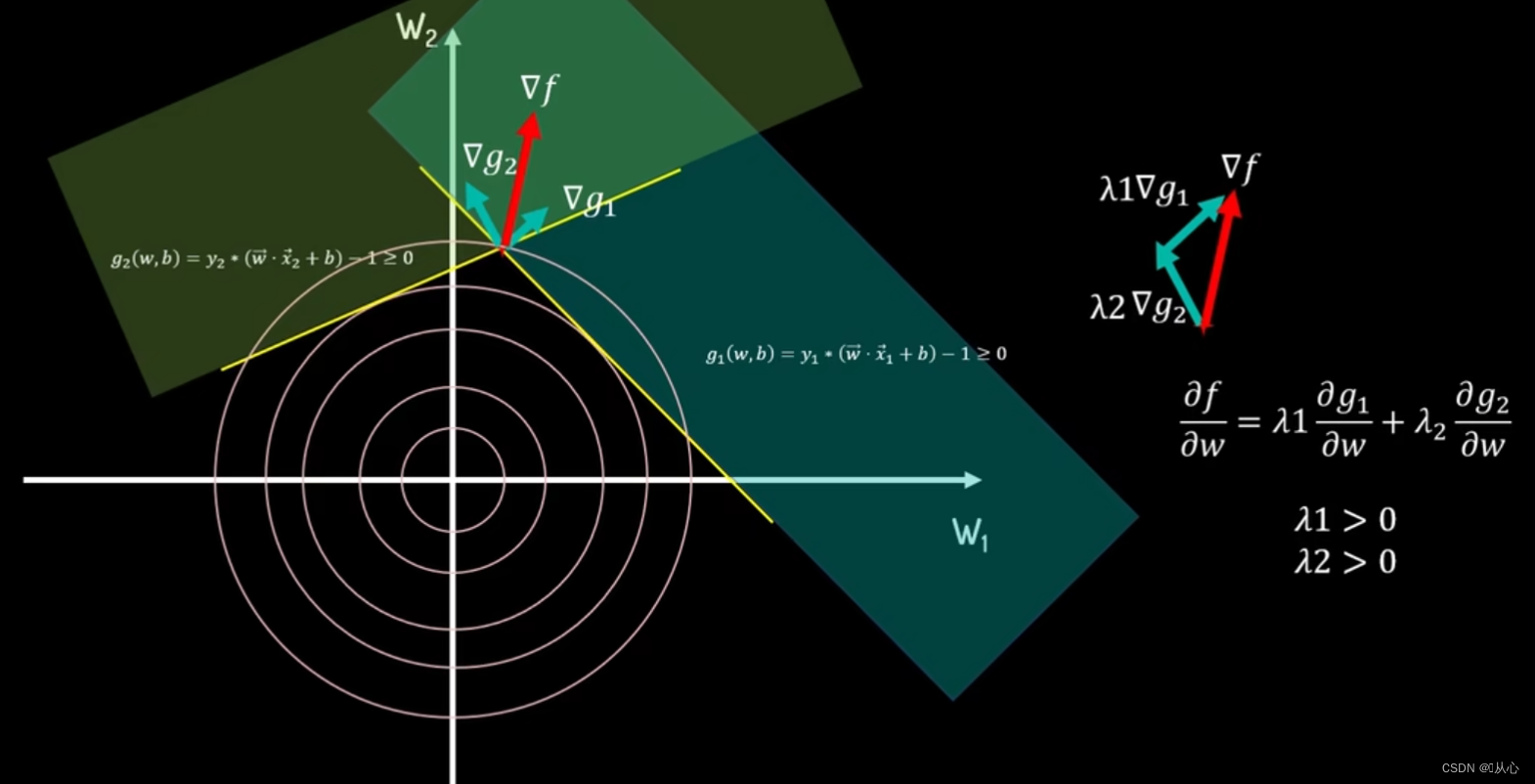
当第三个约束条件g_3>=0加入,最优解已经由前两个约束边界决定,此时最优解不在g_3的约束边界上,此时g_3>0,不起作用,λ_3=0。
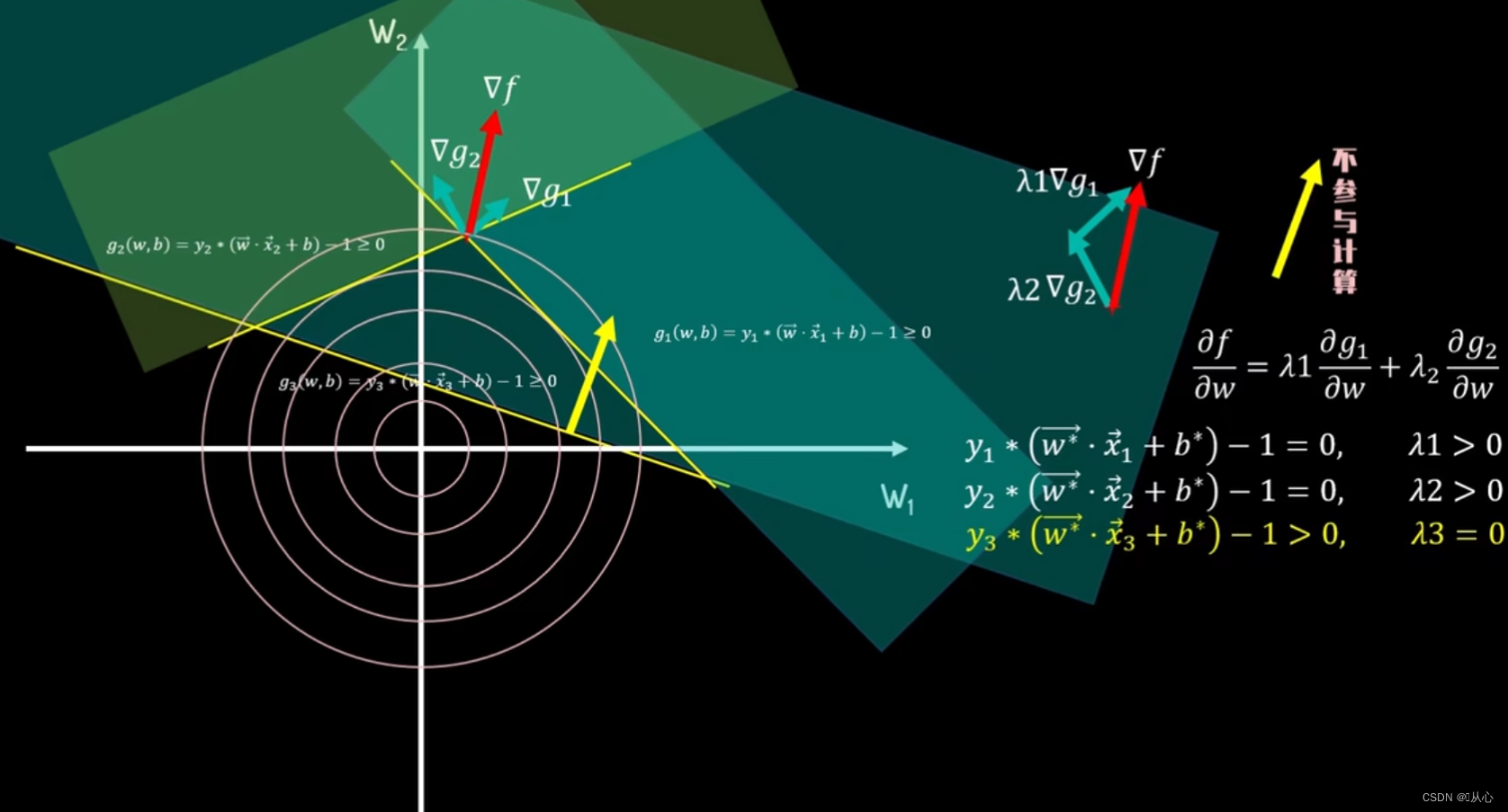
KKT条件
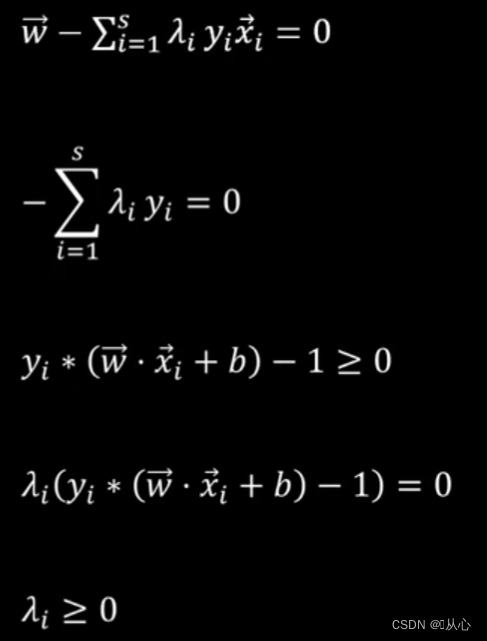
3.3、SVM对偶性
由于原有目标,以及约束条件可以列出拉格朗日方程q(λ_i)=min(L(w,b,λ_i)),因为是最小化所以必定有q(λ_i)=0,所以f(w)必定>=f(w)-λ_i*g(w,b),即有如下不等式
其中q(λ_i)有一个最大的q(λ_i*)存在,让f(w*)与其尽可能接近,这里求解最大q(λ_i*)等于求解如下问题,这就是原问题的对偶问题。当q(λ_i*)=f(w*)成立时就叫强对偶,当强对偶成立时,我们就可以通过求解对偶问题同时得到原问题的解;如当满足某些条件(slater条件),在仿射函数约束下求解凸优化问题时,强对偶成立,两者同时得到最优解

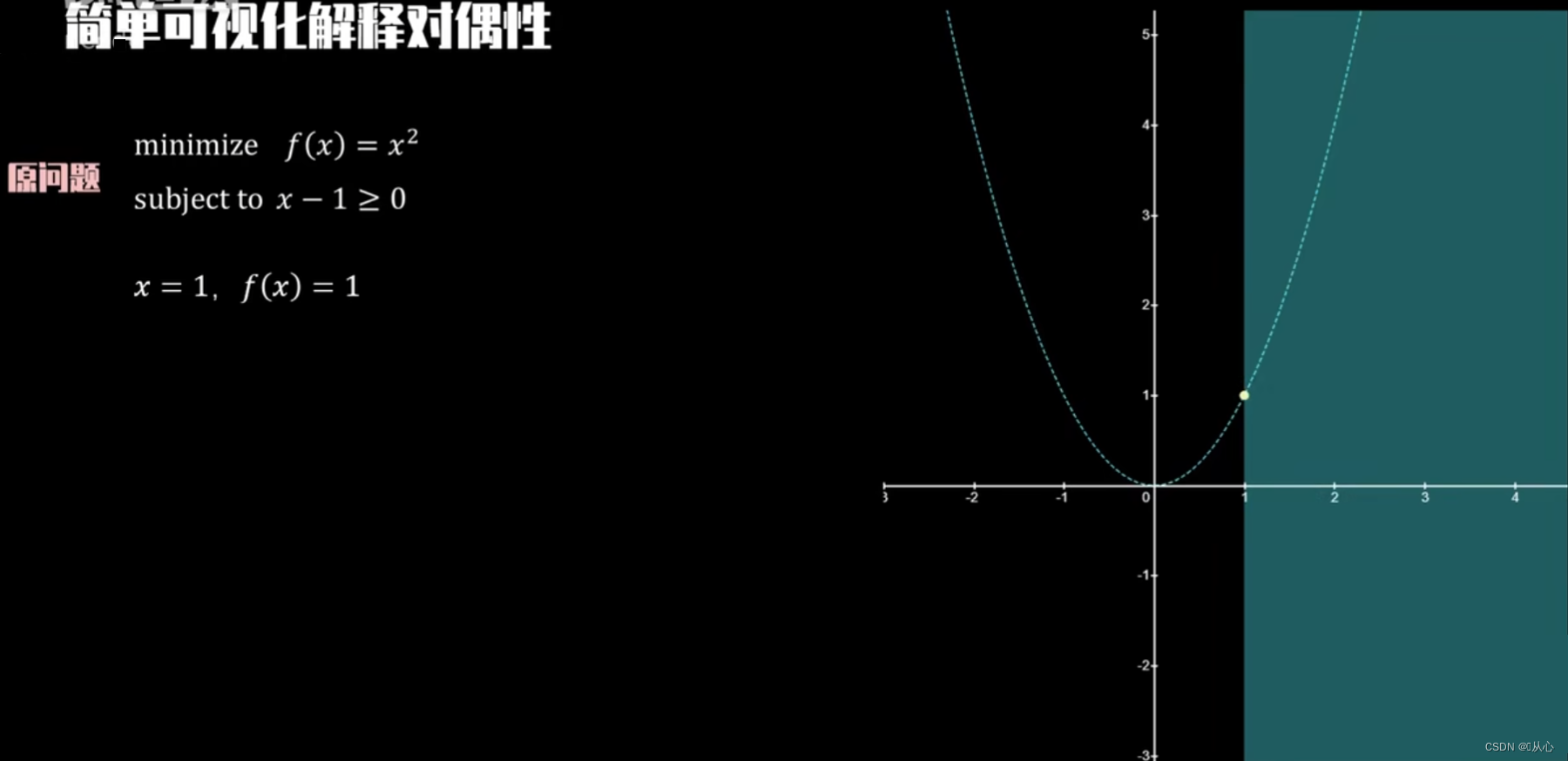
简单可视化理解对偶性
如下目标与约束条件,在(1,1)处取得最小值
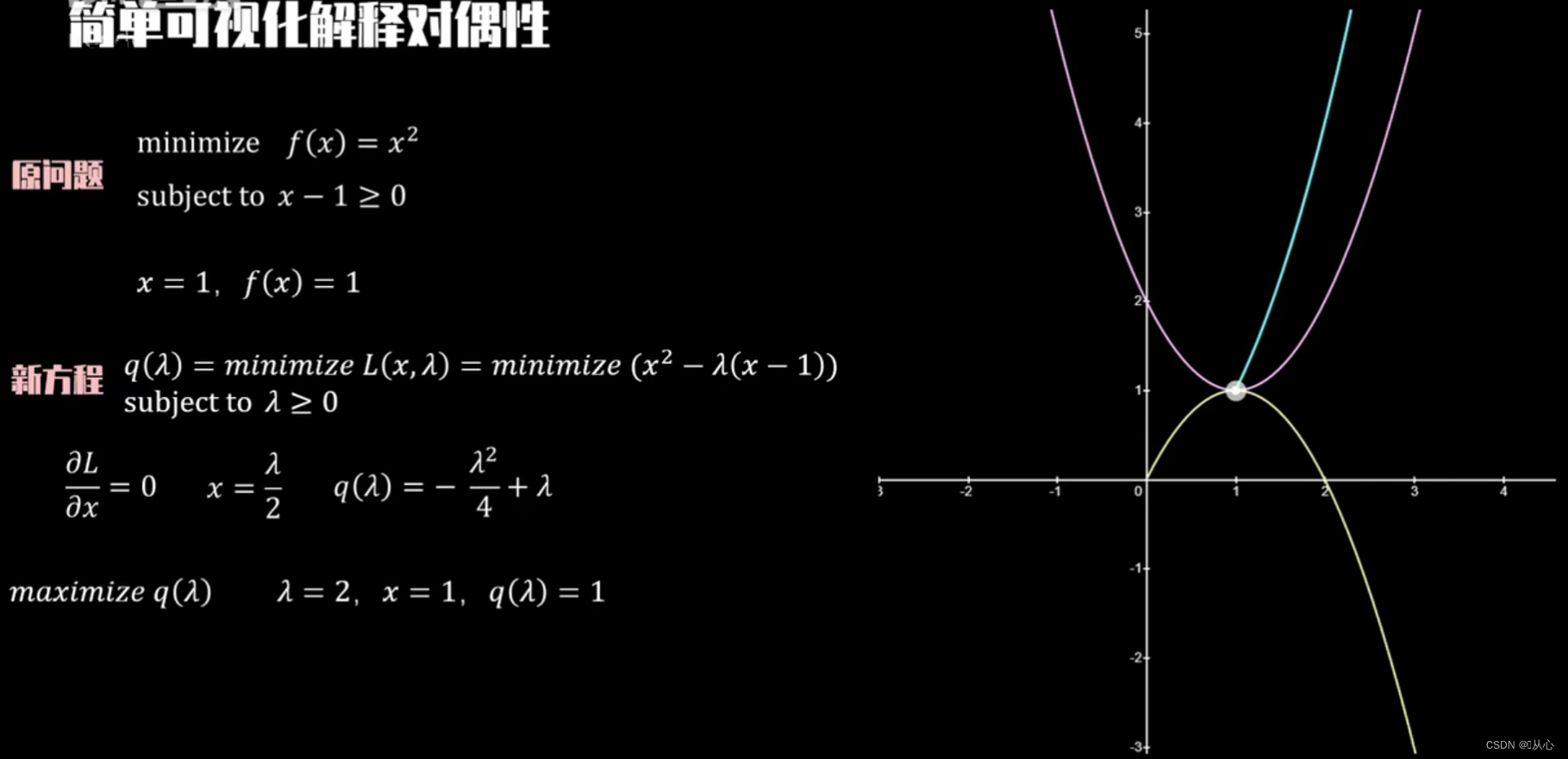
构建方程 ,根据KKT条件,q(λ_i)对x求偏导=0,得到x=λ/2,带回原方程得到q(λ)为如下结果,粉色为拉格朗日方程,黄色为不同λ下的拉格朗日方程的最小值轨迹,可以看出最小值轨迹的最大值为原方程最小值
回原问题
运用对偶问题求解如下:
先对最小化部分求解,可以直接套入之前的KKT条件结果,得到更精简的优化方程
求解λ_i后就可以求解w向量 ,根据KKT条件,只有正负超平面上的支持向量λ_i>0,其余值λ_i=0,所以我们计算w的过程中,只需要用到支持向量,其他不影响结果,计算量显著减小,完成w的计算后,再将w和支持向量x_i套回正负超平面上的方程,就可以求得b了

对偶问题从表达式和约束条件上更简洁外,还有一个非常好的特征,也就是最优解仅根据支持向量的点积结果所决定,也可以理解为仅由支持向量的空间相似度所决定。
更一般的理解

1.不等式约束一直是优化问题中的难题,求解对偶问题可以将支持向量机原问题约束中的不等式约束转化为等式约束;
2.支持向量机中用到了高维映射,但是映射函数的具体形式几乎完全不可确定,而求解对偶问题之后,可以使用核函数来解决这个问题。
3.并不一定要用拉格朗日对偶。要注意用拉格朗日对偶并没有改变最优解,而是改变了算法复杂度:1)在原问题下,求解算法的复杂度与样本维度(等于权值w的维度)有关;2)而在对偶问题下,求解算法的复杂度与样本数量(等于拉格朗日算子的数量)有关。




解出λ后,求出w和b得到模型
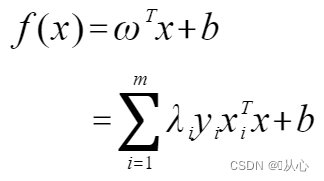

3.4、核函数
前面我们假设样本是线性可分的,即存在一个超平面能将样本正确分类,然而实际任务中,原始样本空间内不存在一个超平面能将两类样本正确划分,对于这样的问题,可以将样本从原始空间映射到一个更高维的特征空间,使其在这个空间中线性可分。




 更一般的理解
更一般的理解
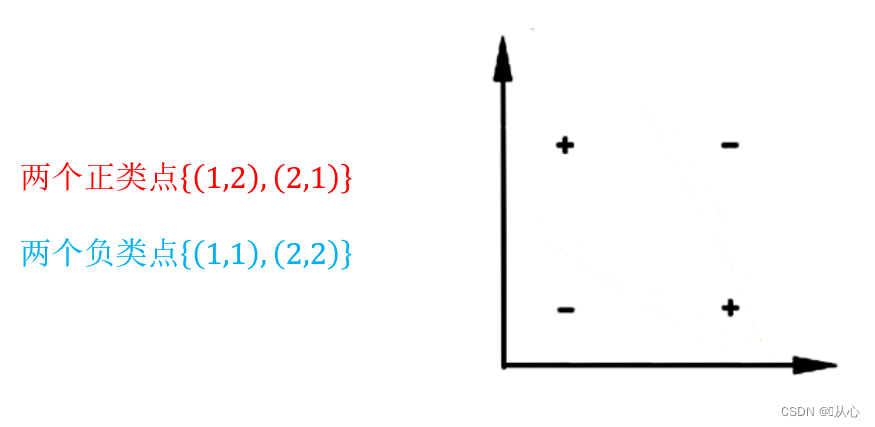
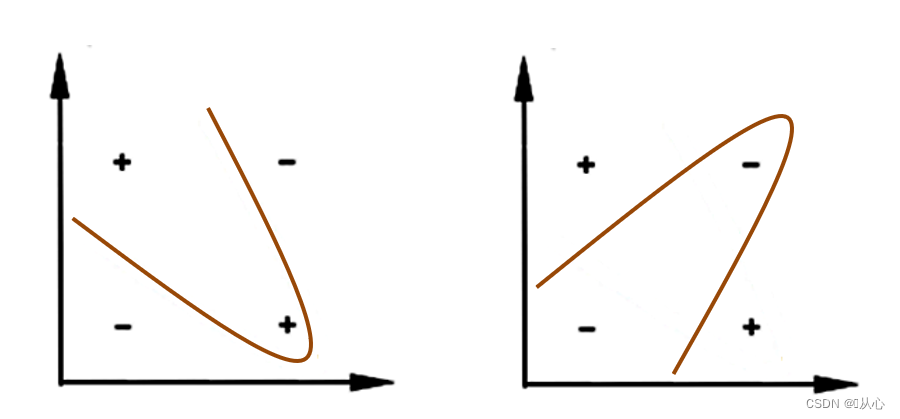
令∅(x)表示将x映射后的特征向量,于是在特征空间中划分超平面所对应的模型如下
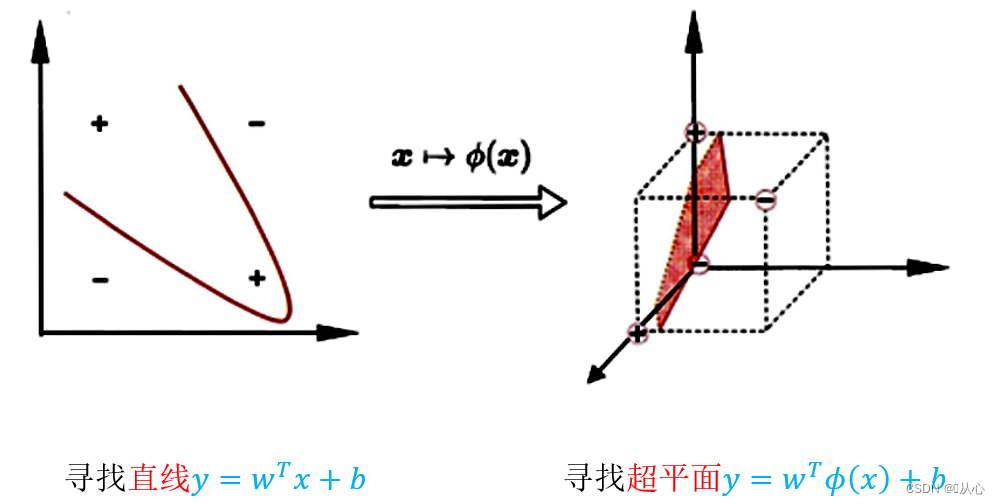
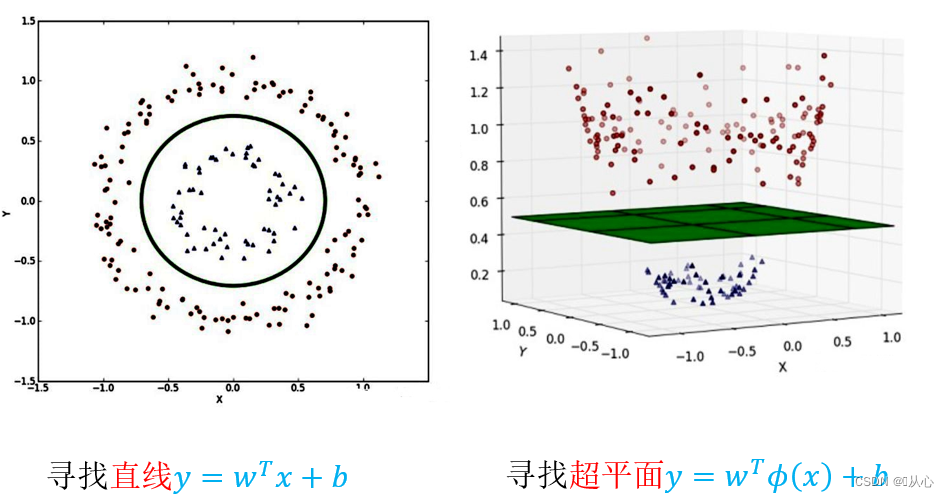



由于特征空间维数可能很高,甚至是无穷维,因此直接计算∅(x_i)^T ∅(x_j)较为困难,所以可以设定一个函数,如下,

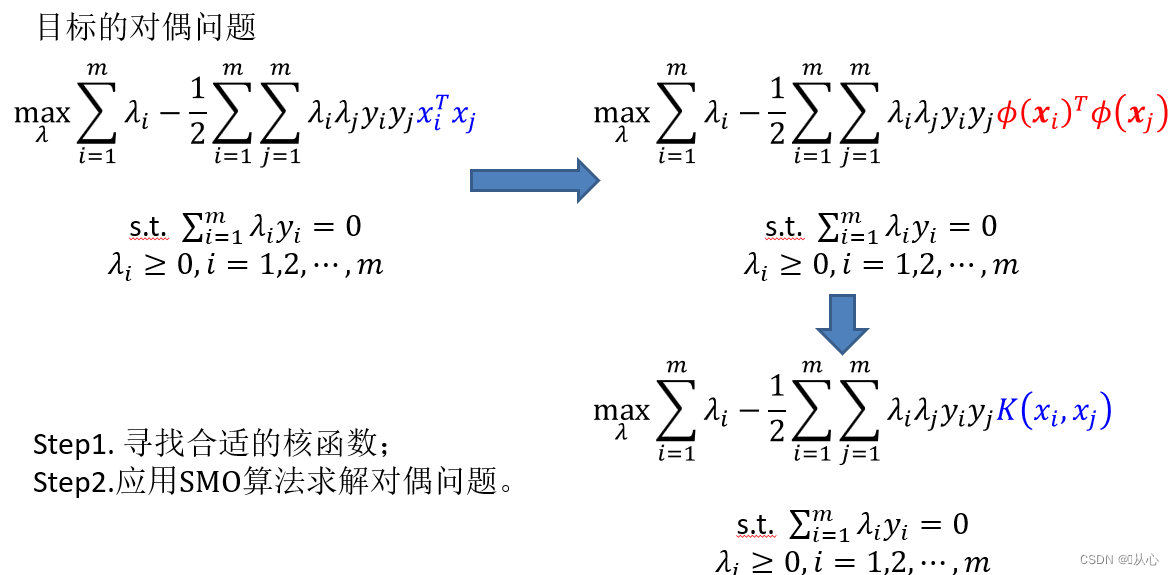


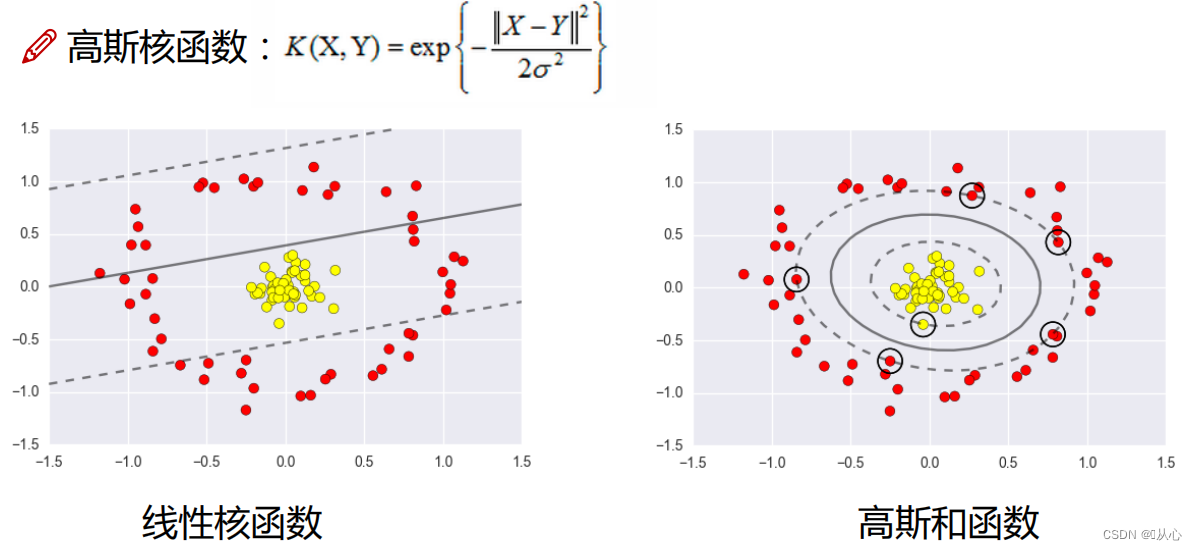
3.5、软间隔
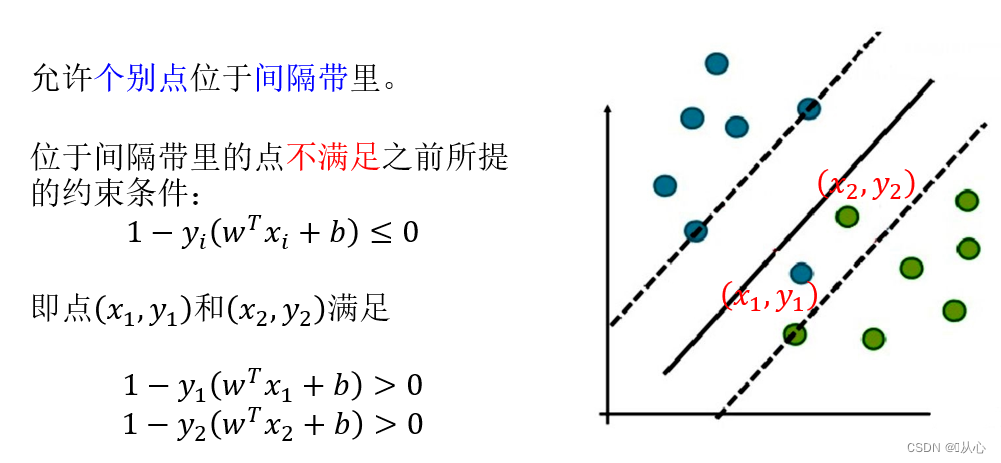
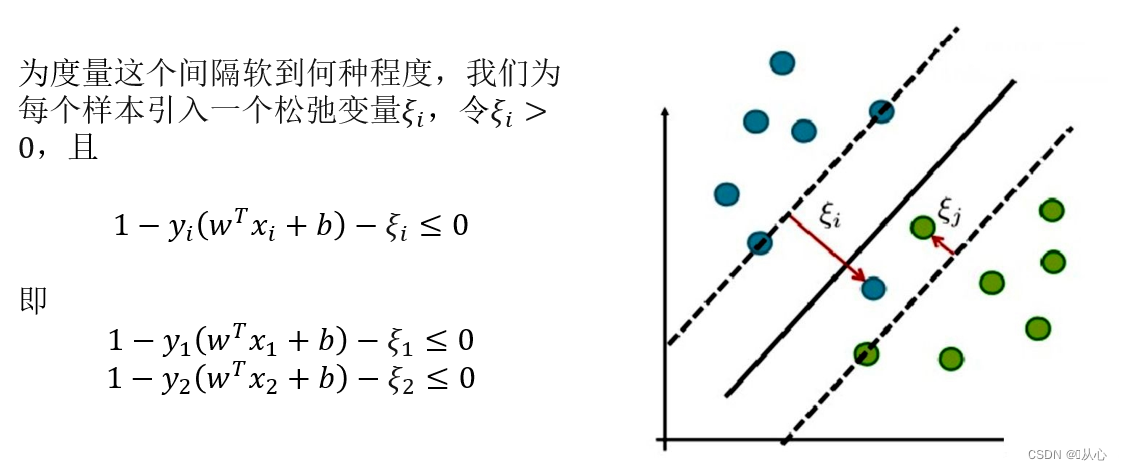






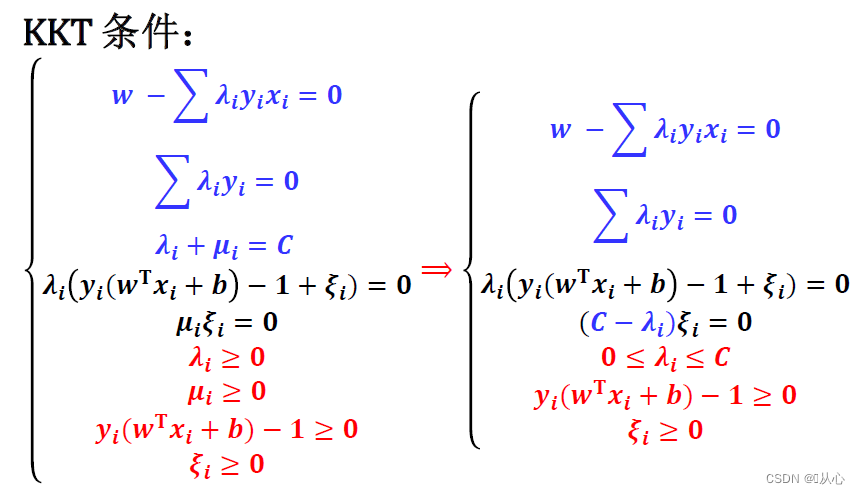

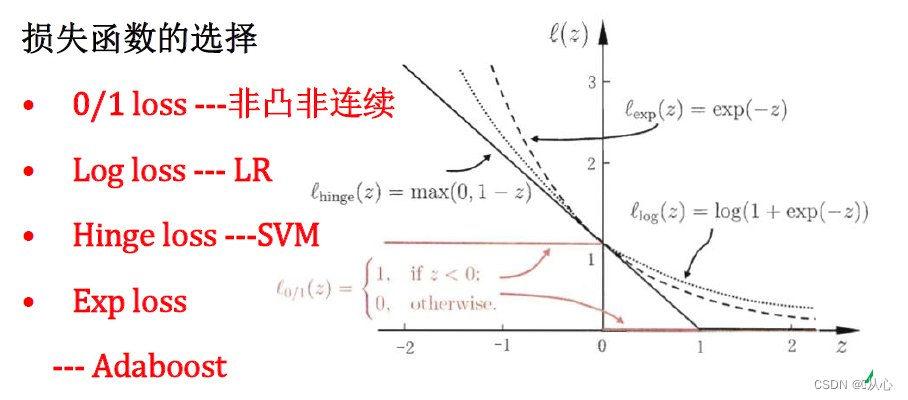
3.6、 例子






4、优缺点
4.1、优点:
SVM 适合中小型数据样本、非线性、高维的分类问题。
- 有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
- 非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;
- 采用核技巧之后,可以处理非线性分类/回归任务;
- 支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量;
- SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”;
- 少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。这种“鲁棒”性主要体现在:
- 增、删非支持向量样本对模型没有影响;
- 支持向量样本集具有一定的鲁棒性;
- 有些成功的应用中,SVM 方法对核的选取不敏感
4.2、缺点:
- SVM算法对大规模训练样本难以实施
- 用SVM解决多分类问题存在困难
旧梦可以重温,且看:机器学习(五) -- 监督学习(6) --逻辑回归
欲知后事如何,且看:



