
前端实现大文件分片并行上传、断点续传、秒传(完整解析)
一、总体流程图
二、具体步骤
简单理解:前端先将文件切割多份,在进行上传,由后端进行切片合并操作。
具体逻辑:
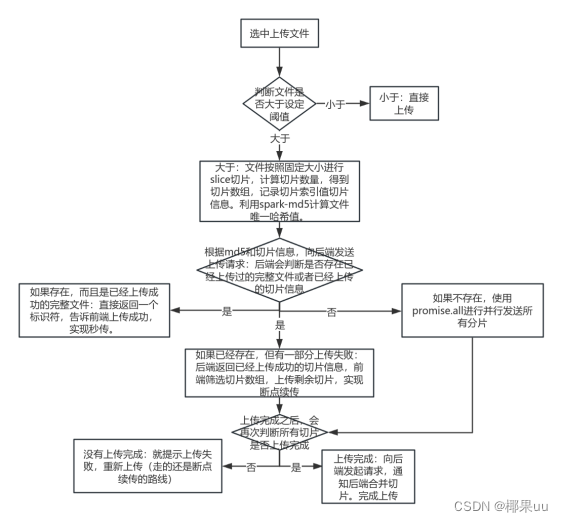
- 1. 前端选中上传文件(如果是批量上传就把选中的文件存入选中文件列表数组中,后续在遍历上传)
- 2. 判断文件大小是否大于设定的阈值(如果小于的话就不用切片上传,直接走单文件上传逻辑)
- 3. 如果大于的话就进入到大文件切片上传逻辑
- 4.按照固定大小对文件进行slice切片得到切片数组,计算切片数量,记录切片索引值,使用spark-md5计算文件的唯一哈希值
- 5.判断:根据文件的hash值和记录的切片信息,请求后端获取该文件是否已经存在当前文件或者上传的切片
- (1)如果已经存在,并且是已经上传成功的文件,则直接返回一个标识符告诉前端上传成功,实现秒传;
- (2)如果已经存在,但是有一部分上传失败,就返回给前端已经上传成功的切片信息,前端对切片数组进行筛选,排除已经上传过的切片数据,把剩余切片继续上传,实现断点续传》
- (3)如果不存在,就开始使用promise.all进行并行发送所有分片(在并发发送切片时控制并发量避免一次性上传多个切片),对接后端接口进行上传》
- 6.判断所有切片是否上传完成(根据上传成功的数组长度和失败的数组长度相加是否等于数组的长度来判断)
- (1)如果没有的话就提示上传失败,重新上传(走的还是断点续传的逻辑,记录的有index,会返回哪个切片没有上传完成,只需要重新上传这些切片就可以)
- (2)如果都上传完成的话就向后端发起请求,通知后端合并切片,最终完成整个上传流程。
三、切片上传
大文件上传-CSDN博客
- 前端将一个大文件,拆分成多个小文件(分片);
- 前端将拆分好的小文件依次发送给后端(每一个小文件对应一个请求);
- 后端每接收到一个小文件,就将小文件保存到服务器;
- 当大文件的所有分片都上传完成后,前端再发送一个“合并分片”的请求到后端;
- 后端对服务器中所有的小文件进行合并,还原完整的大文件;

四、文件秒传
文件秒传,其实指的是文件不用传。如果某一个文件,在之前已经上传成功过,再次上传时,就可以直接提示用户“上传成功”。
工作流程大致如下:
- 上传文件前,将文件名发送到后端,来判断当前文件是否有上传完成过;
- 后端接收到文件名,查询上传成功的文件中是否有该文件,并返回查询结果给前端;
- 前端接收到查询结果,如果是已上传过的文件,则直接提示用户“上传成功”;

五、断点续传
断点续传可以分为两种场景:
用户点击“暂停”按钮时,终止文件的上传;再点击“续传”按钮时,继续上传剩下部分;
用户在上传文件切片的过程中,由于外部原因(网络等)导致上传失败;后续重新上传时,可以接着上次失败的进度继续上传;
两种场景的处理方式其实和“文件秒传”是一样的,工作流程大致如下:
- 文件上传(续传)前,将文件名发送到后端,来判断当前文件是否有上传成功过的部分切片文件;
- 如果有上传过部分切片,后端将上传成功的切片文件名返回给前端;
- 前端从所有切片中,将已经上传成功的切片筛选出来,再将剩下未上传成功的切片重新发送给后端;
- 后端将所有切片合并,完成整个文件的上传

先更新到这里,后续补充代码以及面试问题
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



