
【人工智能】—基于K-Means算法商场顾客聚类实战教程
在这篇博文之前一直是给大家做机器学习有监督学习教程,今天来一篇无监督学习教程。
K-Means算法是一种基于中心的聚类方法,它试图找到数据点的K个簇,使得簇内的数据点尽可能相似,而簇间的数据点尽可能不同。下面是K-Means算法的详细解释和步骤:
算法原理:
K-Means算法基于最小化簇内误差平方和(Within-Cluster Sum of Squares, WCSS)来划分簇。簇内误差平方和是簇内所有点到簇中心的距离平方的总和。算法的目标是最小化所有簇的WCSS。
算法步骤:
- 初始化:选择K个数据点作为初始的簇中心。这些点可以是随机选择的,也可以通过更智能的方法选择,如K-Means++算法。
- 分配:将每个数据点分配到最近的簇中心,形成K个簇。这一步中,每个数据点根据其与簇中心的距离被分配到最近的簇。
- 更新簇中心:重新计算每个簇的中心点。簇中心是该簇内所有数据点的均值(或中位数,取决于距离度量方式)。
- 迭代:重复步骤2和3,直到满足以下任一条件:
(1)簇中心的位置变化非常小,即算法收敛。
(2)达到预设的最大迭代次数。
- 结束:当簇中心不再显著变化或达到最大迭代次数时,算法结束,此时的簇划分被认为是最终结果。
算法细节:
- 距离度量:K-Means通常使用欧几里得距离来衡量数据点之间的相似性,但也可以根据不同的应用场景使用曼哈顿距离、闵可夫斯基距离等。
- 选择K值:K值的选择通常依赖于领域知识或通过肘部法则(Elbow
Method)等方法来确定。肘部法则通过观察不同K值对应的WCSS,选择WCSS下降速率骤减的点作为K值。
- 初始簇中心选择:初始簇中心的选择对算法的收敛性和最终结果有很大影响。K-Means++是一种改进的初始化方法,它通过概率方式选择初始簇中心,以减少陷入局部最优解的风险。
- 算法变体:K-Means算法有多种变体,如K-Medoids算法,它使用实际数据点作为簇中心,而不是计算出的均值,这在处理离群点时更为稳健。
应用场景:
K-Means算法在多个领域都有应用,包括但不限于:
- 图像处理:用于图像分割,将图像划分为不同的区域。
- 文本分析:用于文本聚类,将相似的文档分到同一个簇。
- 生物信息学:用于基因表达数据的分析,识别具有相似表达模式的基因。
- 市场分析:用于客户细分,识别具有相似购买行为的客户群体。
局限性:
- 对噪声敏感:K-Means对异常值和噪声较为敏感,可能会影响簇中心的计算和最终的聚类结果。
- 对初始条件敏感:算法可能会收敛到局部最优解,而不是全局最优解。
- 不适合非球形簇:K-Means假设簇是凸形的,对于非球形或有复杂形状的簇,聚类效果可能不佳。
数据集情况
通过超市商场会员卡,获取客户的基本数据,该数据集仅用于学习客户细分概念,也称为市场篮子分析来源kaggle(数据已云游至上方王母娘娘蟠桃园,免费摘取)。
数据集概述:
- 来源:Kaggle平台
- 目的:用于商场顾客细分的数据分析,旨在帮助商场更深入地了解顾客群体,以制定更精准的营销策略和服务。
- 数据规模:包含200条数据记录,共5个字段(变量)。
数据字段:
- 客户ID(CustomerID):唯一标识每个客户的编号。
- 性别(Gender):客户的性别,分为’Male’和’Female’两类。
- 年龄(Age):客户的年龄,以整数形式表示。
- 年收入(AnnualIncome):客户的年收入,以千美元为单位(k$)。
- 支出分数(SpendingScore):商场根据客户的消费行为和购买数据分配的分数,范围为1-100。
应用场景:
- 顾客细分:通过数据分析,可以将顾客细分为不同的群体,如高收入高消费群体、年轻消费群体等。
- 营销策略制定:基于顾客细分的结果,商场可以制定有针对性的营销策略,如针对高收入群体推出高端商品或服务,针对年轻群体推出时尚或潮流商品。
- 用户画像构建:通过对数据的深入挖掘,可以构建出详细的用户画像,帮助商场更全面地了解顾客的需求和偏好。
初步分析:
导入数据:
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import plotly as py import plotly.graph_objs as go from sklearn.cluster import KMeans import warnings import os warnings.filterwarnings("ignore") plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文 plt.rcParams ['axes.unicode_minus']=False #显示负号 df = pd.read_csv('Mall_Customers.csv') df.head()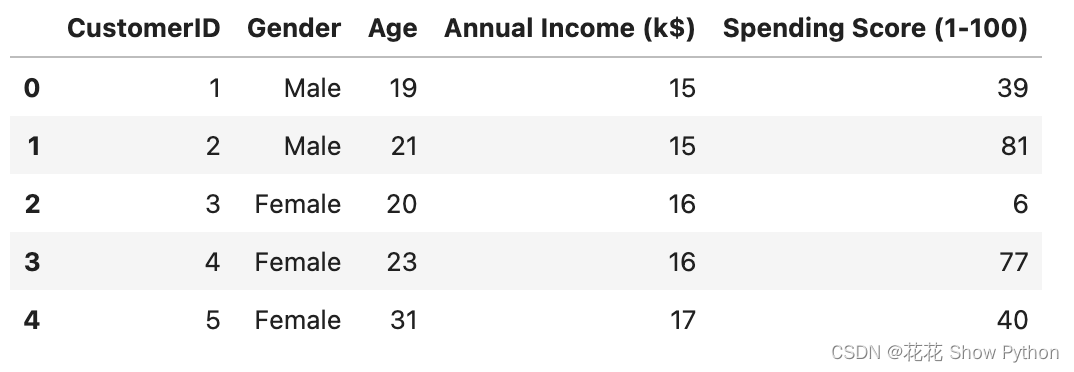 描述性统计:
描述性统计: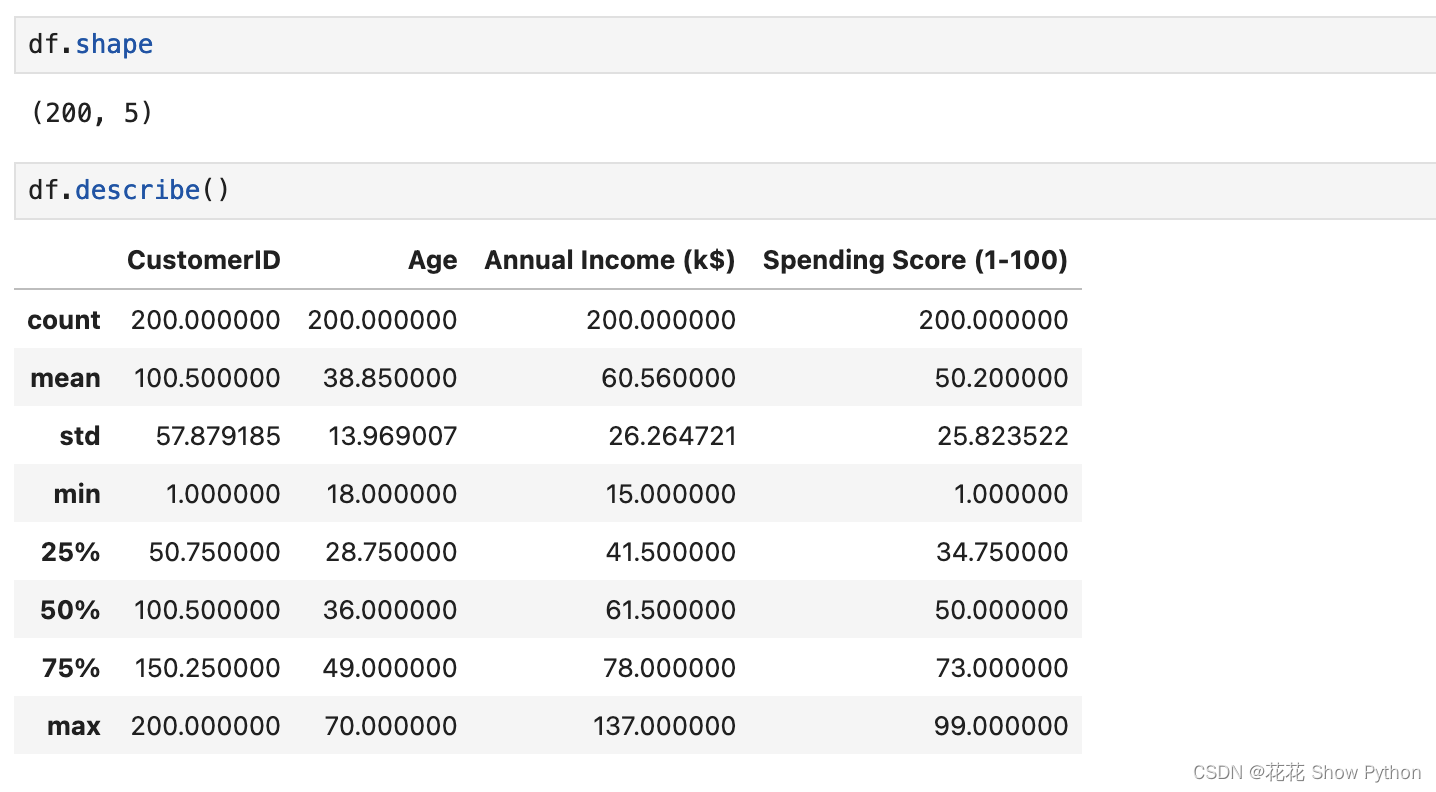
 描述性统计的意思就是我不想打字,自己看了:)
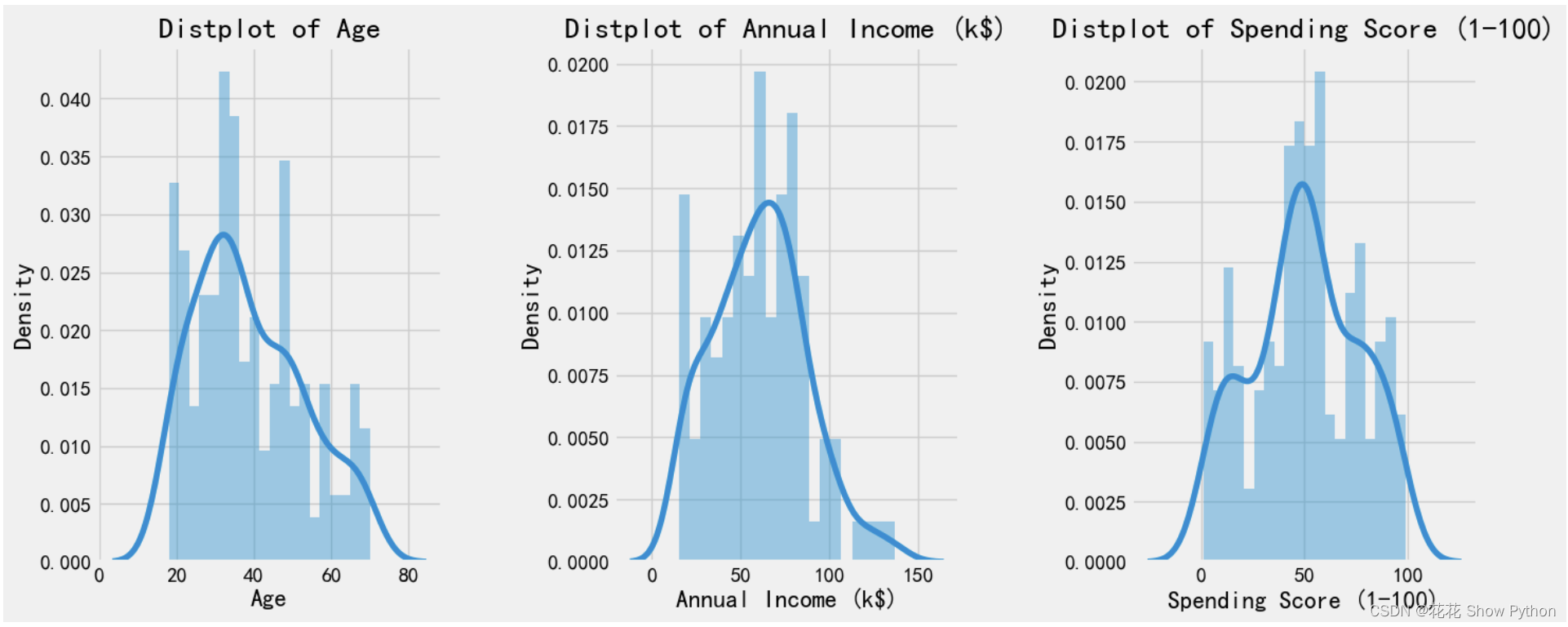
描述性统计的意思就是我不想打字,自己看了:)# 使用'fivethirtyeight'样式来设置绘图的主题和样式,这个样式常用于《五三八》(FiveThirtyEight)网站的图表风格 plt.style.use('fivethirtyeight') # 创建一个图形窗口,并设置其编号(虽然在这里编号并不关键,因为只有一个窗口)和大小(宽度为15英寸,高度为6英寸) plt.figure(1, figsize=(15, 6)) # 初始化一个计数器,用于后面的subplot布局 n = 0 # 对数据集中的'Age'、'Annual Income (k$)'和'Spending Score (1-100)'这三个字段进行迭代 for x in ['Age', 'Annual Income (k$)', 'Spending Score (1-100)']: # 每次迭代,计数器n加1 n += 1 # 创建一个子图(subplot),在1行3列的布局中,这是第n个子图 # 第一个参数是子图的行数,第二个参数是列数,第三个参数是当前子图的编号(从1开始) plt.subplot(1, 3, n) # 调整子图之间的水平和垂直间距,使得子图之间不会过于拥挤或过于疏远 plt.subplots_adjust(hspace=0.5, wspace=0.5) # 使用seaborn库的distplot函数绘制df[x]列的分布图,bins参数指定了分布的条形数量 # 这里假设df是一个pandas DataFrame,且包含了'Age'、'Annual Income (k$)'和'Spending Score (1-100)'这三个字段 sns.distplot(df[x], bins=20) # 设置当前子图的标题,格式为"Distplot of 字段名" plt.title('Distplot of {}'.format(x)) # 显示所有子图 plt.show()绘制年龄、年收入、支出分数直方图:
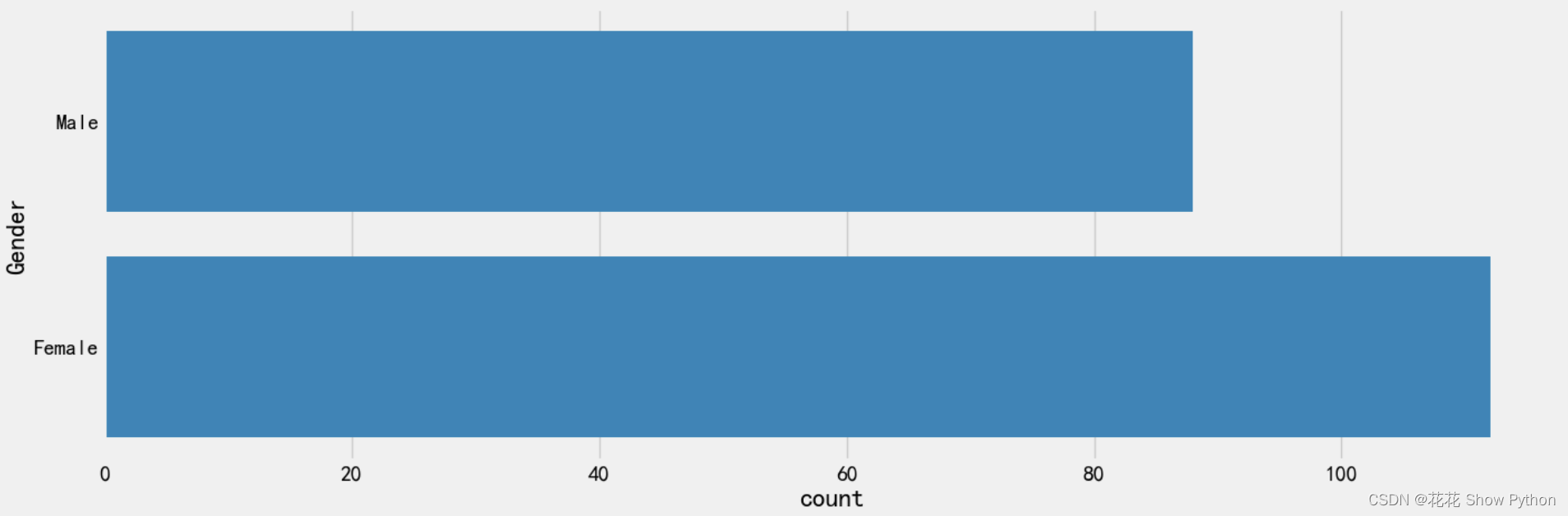
# 创建一个新的图形窗口,编号为1,并设置其大小为宽度15英寸,高度5英寸 plt.figure(1, figsize=(15, 5)) # 使用seaborn库中的countplot函数绘制一个条形图 # 其中,y参数指定了用于分类的列名(在这里是'Gender'),即条形图的分类标签 # data参数指定了数据源,即包含数据的pandas DataFrame(在这里是df) sns.countplot(y='Gender', data=df) # 显示图形窗口中的所有图形 plt.show()
绘制性别计数图:
# 创建一个新的图形窗口,编号为1,并设置其大小为宽度15英寸,高度7英寸 plt.figure(1, figsize=(15, 7)) # 初始化一个计数器,用于后面的subplot布局 n = 0 # 遍历'Age'、'Annual Income (k$)'和'Spending Score (1-100)'这三个字段,作为x轴和y轴的可能选择 for x in ['Age' , 'Annual Income (k$)' , 'Spending Score (1-100)']: for y in ['Age' , 'Annual Income (k$)' , 'Spending Score (1-100)']: # 每次循环,计数器n加1 n += 1 # 创建一个子图(subplot),在3行3列的布局中,这是第n个子图 # 注意:这里会生成9个子图(3x3),但其中很多可能是重复的或没有意义的(例如x和y都是'Age') plt.subplot(3, 3, n) # 调整子图之间的水平和垂直间距 plt.subplots_adjust(hspace=0.5, wspace=0.5) # 使用seaborn的regplot函数绘制x和y之间的回归线及其置信区间 # data参数指定了数据源,即包含数据的pandas DataFrame(在这里是df) sns.regplot(x=x, y=y, data=df) # 设置y轴的标签 # 如果y是一个包含空格的字符串(例如'Annual Income (k$)'),则使用split()方法将其分割为两部分,并重新组合以作为标签 # 如果y只包含一个词(例如'Age'),则直接使用y作为标签 plt.ylabel(y.split()[0]+' '+y.split()[1] if len(y.split()) > 1 else y) # 显示所有子图 plt.show()绘制年龄、年收入和支出得分之间的关系图:
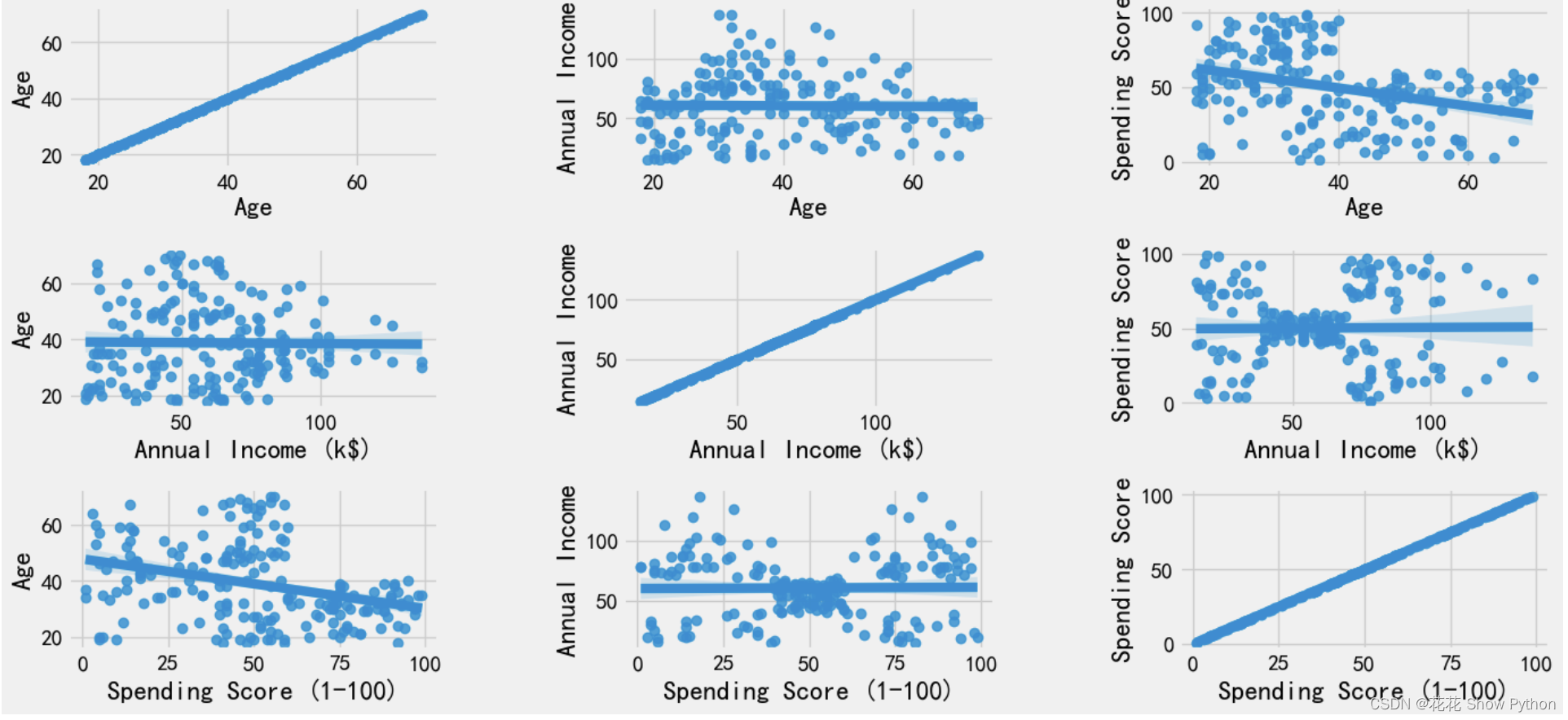
# 创建一个新的图形窗口,编号为1,并设置其大小为宽度15英寸,高度6英寸 plt.figure(1, figsize=(15, 6)) # 遍历'Male'和'Female'两个性别 for gender in ['Male', 'Female']: # 使用scatter函数绘制散点图 # x参数指定了x轴的数据列名,这里是'Age' # y参数指定了y轴的数据列名,这里是'Annual Income (k$)' # data参数指定了数据源,这里是从df中筛选出'Gender'列等于当前循环中gender的数据子集 # s参数指定了散点的大小,这里是200 # alpha参数指定了散点的透明度,这里是0.5,意味着散点会有一定的重叠效果 # label参数为散点设置了标签,用于在图例中显示 plt.scatter(x='Age', y='Annual Income (k$)', data=df[df['Gender'] == gender], s=200, alpha=0.5, label=gender) # 设置x轴的标签为'Age' plt.xlabel('Age') # 设置y轴的标签为'Annual Income (k$)' plt.ylabel('Annual Income (k$)') # 设置图形的标题为'Age vs Annual Income w.r.t Gender' plt.title('Age vs Annual Income w.r.t Gender') # 显示图例,图例中的标签来源于前面scatter函数中设置的label参数 plt.legend() # 显示图形窗口中的所有图形 plt.show()绘制年龄与性别(男和女)的散点关系图:

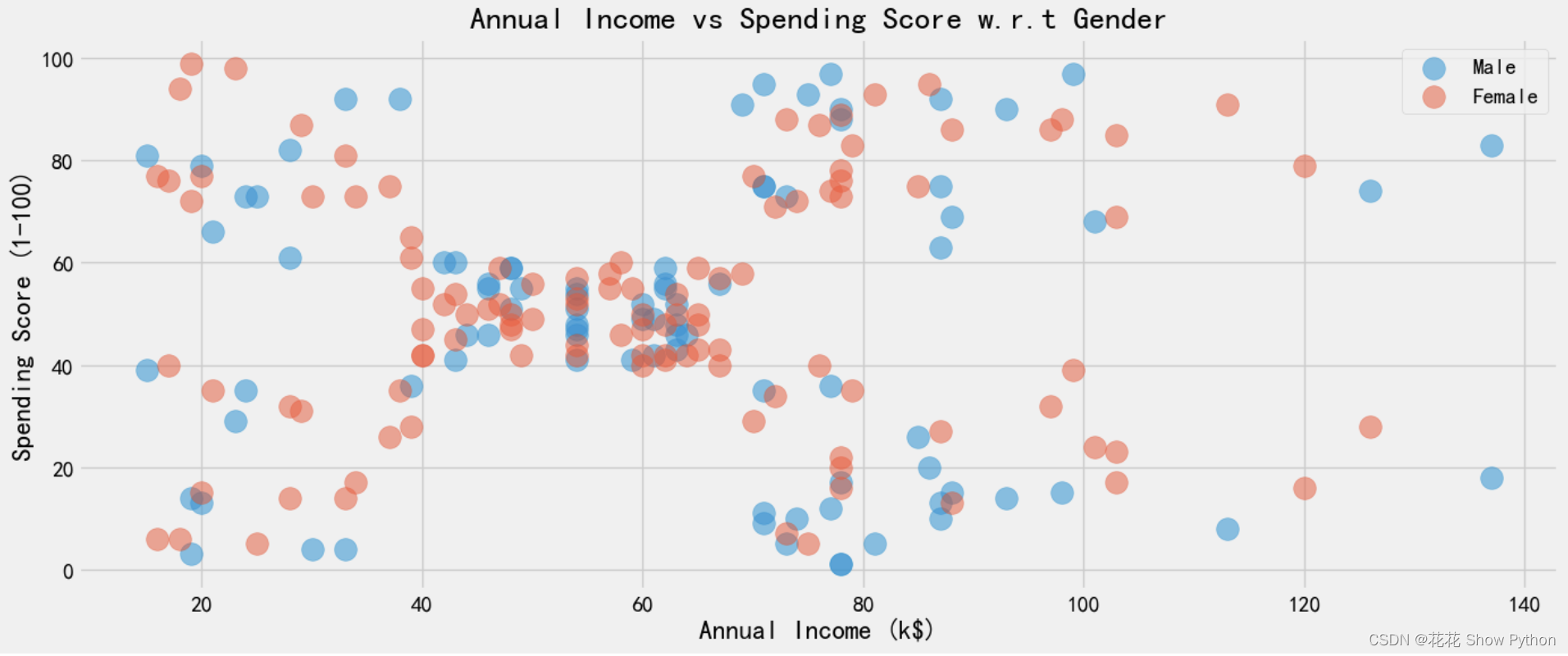
# 创建一个新的图形窗口,编号为1,并设置其大小为宽度15英寸,高度6英寸 plt.figure(1, figsize=(15, 6)) # 遍历'Male'和'Female'两个性别 for gender in ['Male', 'Female']: # 使用scatter函数绘制散点图 # x参数指定了x轴的数据列名,这里是'Annual Income (k$)' # y参数指定了y轴的数据列名,这里是'Spending Score (1-100)' # data参数指定了数据源,这里是从df中筛选出'Gender'列等于当前循环中gender的数据子集 # s参数指定了散点的大小,这里是200 # alpha参数指定了散点的透明度,这里是0.5,意味着散点会有一定的重叠效果 # label参数为散点设置了标签,用于在图例中显示 plt.scatter(x='Annual Income (k$)', y='Spending Score (1-100)', data=df[df['Gender'] == gender], s=200, alpha=0.5, label=gender) # 设置x轴的标签为'Annual Income (k$)' plt.xlabel('Annual Income (k$)') # 注意:这里使用了逗号来将两个函数调用分隔开,但这不是必要的。可以单独调用plt.ylabel # 设置y轴的标签为'Spending Score (1-100)' plt.ylabel('Spending Score (1-100)') # 设置图形的标题为'Annual Income vs Spending Score w.r.t Gender' plt.title('Annual Income vs Spending Score w.r.t Gender') # 显示图例,图例中的标签来源于前面scatter函数中设置的label参数 plt.legend() # 显示图形窗口中的所有图形 plt.show()绘制年收入、支出分数的性别(男和女)散点关系图:
# 创建一个新的图形窗口,编号为1,并设置其大小为15x7英寸 plt.figure(1 , figsize = (15 , 7)) # 初始化一个计数器n,用于跟踪子图的编号 n = 0 # 遍历列名列表,这些列是我们希望根据性别来绘制小提琴图和蜂群图的特征 for cols in ['Age' , 'Annual Income (k$)' , 'Spending Score (1-100)']: # 每次循环,n增加1,以便在子图中定位 n += 1 # 使用subplot创建一个子图,1行3列,当前是第n个子图 plt.subplot(1 , 3 , n) # 调整子图之间的水平和垂直间距,使图形之间有足够的空间 plt.subplots_adjust(hspace = 0.5 , wspace = 0.5) # 使用seaborn的violinplot函数绘制小提琴图,小提琴图展示了数据的分布 # x轴是列名cols对应的值,y轴是'Gender'列的值,数据来自df # palette参数设置了小提琴图的颜色方案 sns.violinplot(x = cols , y = 'Gender' , data = df , palette = 'vlag') # 使用seaborn的swarmplot函数绘制蜂群图,蜂群图展示了每个数据点的位置 # x轴和y轴与小提琴图相同,数据也来自df sns.swarmplot(x = cols , y = 'Gender' , data = df) # 如果这是第一个子图,则设置y轴的标签为'Gender',否则不设置 plt.ylabel('Gender' if n == 1 else '') # 如果这是第二个子图,则设置标题为'Boxplots & Swarmplots',否则不设置 # 注意:虽然标题中提到了Boxplots,但实际上并没有绘制箱线图 plt.title('Boxplots & Swarmplots' if n == 2 else '') # 显示图形 plt.show()绘制年龄、年收入、支出分数的性别(男和女)小提琴图:

**小提琴图(Violin Plot)**是一种用于展示数据分布的图形,它结合了箱线图(Box Plot)和密度图(Density Plot)的特点。小提琴图提供了数据的多种统计信息,包括数据的分布、密度、中位数、四分位数以及异常值等。以下是小提琴图的一些关键特点和组成部分:
- 形状:小提琴图的主体部分是曲线,形状像小提琴的侧面,因此得名。曲线的宽度表示数据点的密度,即在该范围内数据点的数量。
- 箱线图部分:在小提琴图的中心,通常会有一个箱线图,显示数据的中位数、四分位数和异常值。这与标准的箱线图相同。
- 数据分布:小提琴图的曲线部分显示了数据的密度分布。曲线越宽,表示在该区间内数据点越密集。
- 颜色:小提琴图可以使用颜色来表示数据的密度,颜色越深表示密度越高。
- 多组数据对比:小提琴图非常适合用于展示和比较多组数据的分布情况。例如,可以在同一张图上展示不同条件下的数据分布,通过比较小提琴图的形状和大小来直观地看出不同组数据的差异。
- 适用场景:小提琴图适用于展示连续数据的分布情况,尤其是当数据集较大,需要同时展示多个维度的数据时。
- 局限性:由于小提琴图包含了大量的信息,对于初学者来说可能不太容易解读。此外,当数据集中包含多个峰值或多个模式时,小提琴图可能不如其他图形(如直方图)直观。
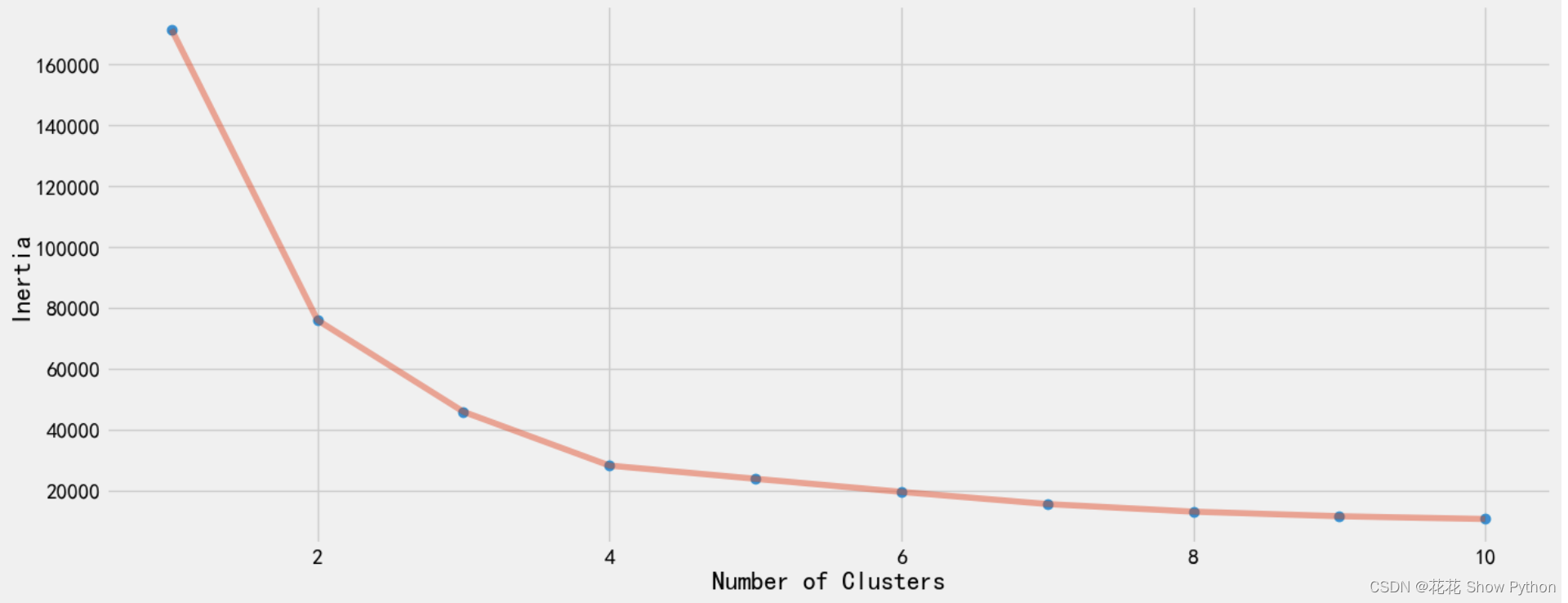
# 注释:从df中选取'Age'和'Spending Score (1-100)'两列, # 并将其转换为numpy数组(因为KMeans需要数值型数组作为输入) # .iloc[: , :] 是一个冗余的索引,因为这里它选择了所有的行和列(但在这个上下文中,它仍然是有效的) X1 = df[['Age' , 'Spending Score (1-100)']].iloc[: , :].values # 注释:初始化一个空列表,用于存储不同聚类数量下KMeans算法的惯性(inertia)值 # 惯性是KMeans算法的一个指标,表示所有样本到其最近质心的距离的平方和 inertia = [] # 注释:开始一个循环,从1到10(包含1但不包含11),用于测试不同的聚类数量 for n in range(1 , 11): # 注释:在每次循环中,创建一个KMeans对象,设置n_clusters为当前循环的n值 # init='k-means++' 表示使用k-means++初始化质心 # n_init=10 表示算法将运行10次,并返回最佳结果(基于惯性) # max_iter=300 表示算法的最大迭代次数 # tol=0.0001 是收敛的容忍度,即当质心变化小于这个值时,算法将停止 # random_state=111 确保了每次运行的结果都是可重复的 # algorithm='elkan' 是一个加速KMeans算法的选项 algorithm = (KMeans(n_clusters = n ,init='k-means++', n_init = 10 ,max_iter=300, tol=0.0001, random_state= 111 , algorithm='elkan') ) # 注释:使用当前KMeans对象对X1数据进行拟合,即进行聚类 algorithm.fit(X1) # 注释:将KMeans算法拟合后的惯性值添加到inertia列表中 # 惯性值越小,通常表示聚类效果越好(但需要注意过拟合的可能性) inertia.append(algorithm.inertia_)这段代码的目的是通过计算不同聚类数量下的KMeans惯性值,来评估并找出最佳的聚类数量,从而优化KMeans聚类的效果。通常,惯性值越小表示聚类效果越好,但需避免过拟合。
# 创建一个新的图形窗口,编号为1,并设置其大小为15x6英寸 plt.figure(1, figsize=(15, 6)) # 绘制点图,横坐标是聚类数量的范围(从1到10),纵坐标是对应的惯性值 # 'o' 表示数据点将被绘制为圆圈 plt.plot(np.arange(1, 11), inertia, 'o') # 绘制线图,与点图使用相同的横纵坐标数据 # '-' 表示线将被绘制为实线 # alpha=0.5 设置线的透明度为0.5,使其半透明,以便与点图区分 plt.plot(np.arange(1, 11), inertia, '-', alpha=0.5) # 设置x轴的标签为'Number of Clusters',表示聚类数量 # 设置y轴的标签为'Inertia',表示惯性值 # plt.xlabel() 和 plt.ylabel() 函数返回None,但在这里我们使用逗号将它们组合在一行,这是一种常见的Python编程风格,用于在一行中执行多个操作 plt.xlabel('Number of Clusters'), plt.ylabel('Inertia') # 显示图形 plt.show()这段代码可视化KMeans聚类算法中不同聚类数量对应的惯性值,展示了KMeans聚类中聚类数量与惯性值之间的关系,帮助用户确定最佳的聚类数量。
KMeans聚类中聚类数量与惯性值之间的关系图:
# 创建一个KMeans算法对象 # 参数说明: # n_clusters=4: 指定要形成的簇的数量为4 # init='k-means++': 使用k-means++算法来初始化质心 # n_init=10: 算法将使用不同的质心初始化运行10次,并选择最佳结果(基于惯性) # max_iter=300: 算法的最大迭代次数 # tol=0.0001: 收敛的容忍度,即当质心变化小于这个值时,算法将停止 # random_state=111: 随机数生成器的种子,确保结果的可重复性 # algorithm='elkan': 使用Elkan的K-Means算法,它使用三角形不等式来加速计算 algorithm = (KMeans(n_clusters=4, init='k-means++', n_init=10, max_iter=300, tol=0.0001, random_state=111, algorithm='elkan')) # 使用KMeans算法对象对X1数据进行拟合,即进行聚类 # X1是一个包含'Age'和'Spending Score (1-100)'的二维numpy数组 algorithm.fit(X1) # 获取每个数据点的聚类标签 # labels1是一个与X1数据点数量相同的数组,其中每个元素表示对应数据点所属的簇的编号(从0到n_clusters-1) labels1 = algorithm.labels_ # 获取每个簇的质心 # centroids1是一个形状为(n_clusters, n_features)的二维数组 # 在这个例子中,由于n_clusters=4且n_features=2('Age'和'Spending Score'两列),所以centroids1的形状为(4, 2) # 每一行代表一个簇的质心,包含两个值:该簇的平均'Age'和平均'Spending Score' centroids1 = algorithm.cluster_centers_以上代码创建了一个KMeans聚类算法对象,并设置了多个参数来指导聚类过程。其中,指定了簇的数量为4,并使用k-means++算法进行质心初始化,以增加聚类的稳定性和效率。算法将尝试10种不同的质心初始化,并选择其中惯性最小的结果作为最佳聚类。此外,还设置了最大迭代次数和收敛容忍度来控制算法的停止条件。使用指定的随机数种子确保了结果的可重复性。算法被应用于一个二维数据集X1,该数据集包含’Age’和’Spending Score’两个特征。聚类完成后,代码获取了每个数据点的聚类标签以及每个簇的质心。这些质心表示了每个簇中数据点的平均值,可以帮助理解各个簇的特征。
# 设置网格步长,这个值决定了网格的粒度或精细程度 h = 0.02 # 找到X1中第一列(即'Age'列)的最小值和最大值,并分别减去和加上1,以扩展网格的范围 # 这样做是为了确保所有的数据点都包含在网格内,尤其是在绘制边界时 x_min, x_max = X1[:, 0].min() - 1, X1[:, 0].max() + 1 # 找到X1中第二列(即'Spending Score (1-100)'列)的最小值和最大值,并分别减去和加上1 # 同样是为了扩展网格的范围 y_min, y_max = X1[:, 1].min() - 1, X1[:, 1].max() + 1 # 使用numpy的meshgrid函数在(x_min, x_max)和(y_min, y_max)之间创建一个二维网格 # np.arange(x_min, x_max, h) 和 np.arange(y_min, y_max, h) 分别生成x和y轴上的值 # meshgrid函数将这些一维数组转换为两个二维数组xx和yy,它们分别表示网格的x和y坐标 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 将xx和yy的二维数组平铺(ravel)为一维数组,并将它们沿着列方向(使用np.c_)合并成一个二维数组 # 这个二维数组的每一行代表网格上的一个点的坐标(x, y) # 这是为了将网格上的点作为输入数据传递给KMeans算法的predict方法 Z = algorithm.predict(np.c_[xx.ravel(), yy.ravel()]) # 经过predict方法处理后,Z是一个一维数组,包含了网格上每个点所属的簇的编号 # 接下来,通常会将Z重新整形为与xx和yy相同的二维形状,以便在绘制图形时能够正确对应每个网格点所属的簇 # 这通常是通过Z = Z.reshape(xx.shape)来实现的,但您提供的代码段中没有这一步
以上代码的主要目的是在包含’Age’和’Spending Score (1-100)'特征的数据集X1的范围内创建一个二维网格,并使用先前训练的KMeans算法(algorithm)来预测这个网格上每个点所属的簇。首先,通过扩展数据集中这两个特征的最小值和最大值来定义网格的边界。然后,使用numpy的meshgrid函数创建了一个二维网格,该网格覆盖了由x_min到x_max和y_min到y_max定义的区域,网格的粒度由步长h控制。接着,将网格的x和y坐标合并成一个二维数组,作为输入数据传递给KMeans算法的predict方法,以获取每个网格点所属的簇的编号。最后,通常会将预测的簇编号重新整形为与网格相同的二维形状,以便在可视化时能够正确对应每个网格点所属的簇。
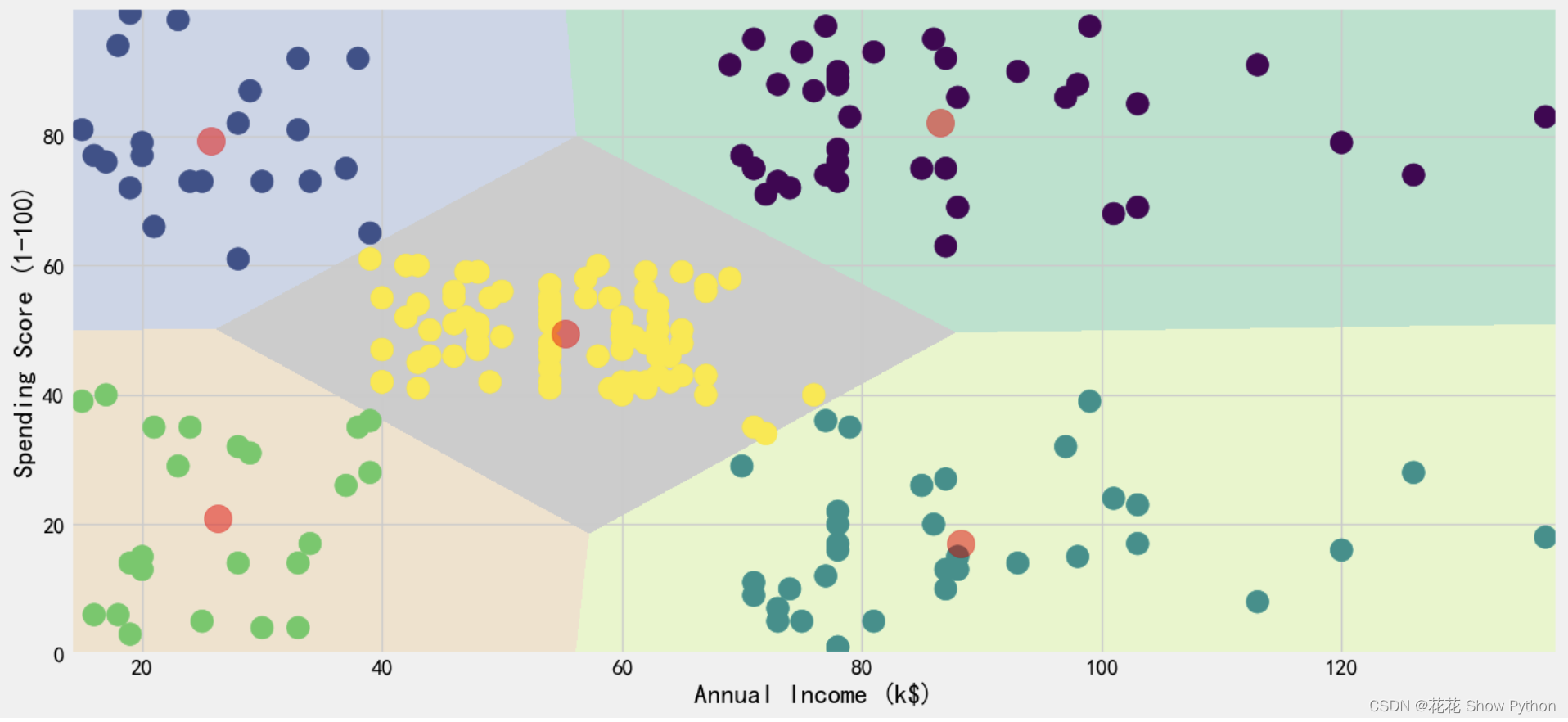
# 创建一个新的图形窗口,编号为1,并设置其大小为15x7英寸 plt.figure(1 , figsize = (15 , 7) ) # 清除当前图形窗口中的所有内容(如果存在的话),这确保我们从一个干净的画布开始 plt.clf() # 将之前预测得到的Z数组(包含网格上每个点所属的簇编号)重新整形为与xx(网格的x坐标)相同的二维形状 Z = Z.reshape(xx.shape) # 使用imshow函数绘制Z数组,即绘制出聚类结果 # interpolation='nearest':表示使用最近邻插值法来绘制图像 # extent=(xx.min(), xx.max(), yy.min(), yy.max()):定义图像的范围 # cmap=plt.cm.Pastel2:选择颜色映射(这里选择了Pastel2颜色映射) # aspect='auto':自动调整x和y轴的缩放比例 # origin='lower':设置坐标原点在图像的左下角 plt.imshow(Z , interpolation='nearest', extent=(xx.min(), xx.max(), yy.min(), yy.max()), cmap = plt.cm.Pastel2, aspect = 'auto', origin='lower') # 绘制原始数据点,这里使用scatter函数 # x 和 y 参数通常应该是具体的数值,但这里使用了字符串'Age'和'Spending Score (1-100)' # 这意味着我们要从DataFrame df中引用这些列。但是,为了保持一致性,我们最好直接使用列名对应的数值数组 # c=labels1:设置数据点的颜色,根据labels1中的簇编号进行着色 # s=200:设置数据点的大小为200 plt.scatter( x = 'Age' ,y = 'Spending Score (1-100)' , data = df , c = labels1 , s = 200 ) # 绘制聚类中心(质心) # x 和 y 分别是质心的x和y坐标 # s=300:设置质心点的大小为300 # c='red':设置质心点的颜色为红色 # alpha=0.5:设置质心点的透明度为0.5 plt.scatter(x = centroids1[: , 0] , y = centroids1[: , 1] , s = 300 , c = 'red' , alpha = 0.5) # 设置y轴的标签为'Spending Score (1-100)' # 设置x轴的标签为'Age' # 使用逗号操作符将两个设置标签的操作放在一行中,这是一种常见的Python编程风格 plt.ylabel('Spending Score (1-100)') , plt.xlabel('Age') plt.show()年龄和支出分数的可视化KMeans聚类的结果:

后面会重复不同变量的聚类结果,由于时间有限,我就直接上代码和聚类的结果。
# 从df数据集中选择'Annual Income (k$)'和'Spending Score (1-100)'两列,并将其作为numpy数组赋值给X2 # iloc[: , :]表示选择所有的行和所有的列(这里其实是冗余的,但明确表明了意图) X2 = df[['Annual Income (k$)' , 'Spending Score (1-100)']].iloc[: , :].values # 初始化一个空列表inertia,用于存储不同聚类数量下的惯性值 inertia = [] # 遍历从1到10的整数,作为KMeans算法中可能的聚类数量n for n in range(1 , 11): # 创建一个KMeans对象,设置n_clusters为当前的n值,使用'k-means++'作为初始化方法 # 设置n_init为10,意味着会进行10次不同的初始化并选择最优结果 # max_iter设置为300,即算法的最大迭代次数 # tol设置为0.0001,即算法收敛的容忍度 # random_state设置为111,以确保结果的可复现性 # 使用'elkan'作为KMeans的加速算法 algorithm = (KMeans(n_clusters = n ,init='k-means++', n_init = 10 ,max_iter=300, tol=0.0001, random_state= 111 , algorithm='elkan') ) # 使用KMeans对象对X2进行拟合(即进行聚类) algorithm.fit(X2) # 将当前KMeans对象的惯性值(即聚类内部点到其质心的距离的平方和)添加到inertia列表中 inertia.append(algorithm.inertia_)# 创建一个新的图形窗口,编号为1,并设置其大小为15x6英寸 plt.figure(1, figsize=(15, 6)) # 绘制散点图,其中x轴是np.arange(1, 11)(即从1到10的整数数组),y轴是之前计算得到的inertia(惯性值列表) # 'o'表示使用圆圈作为数据点的标记 plt.plot(np.arange(1, 11), inertia, 'o') # 在同一图形上再次绘制线条图,使用相同的x和y数据 # '-'表示使用实线连接数据点 # alpha=0.5设置线条的透明度为0.5,使其半透明 plt.plot(np.arange(1, 11), inertia, '-', alpha=0.5) # 设置x轴的标签为'Number of Clusters'(簇的数量) # 使用逗号操作符将两个操作放在同一行上,这是一种常见的Python编程风格 plt.xlabel('Number of Clusters'), plt.ylabel('Inertia') # 显示图形 plt.show()KMeans聚类中聚类数量与惯性值之间的关系图:

# 创建一个KMeans对象,设置其参数: # n_clusters=5:表示要形成的簇的数量为5 # init='k-means++':使用'k-means++'作为初始化质心的方法 # n_init=10:在给定n_clusters的情况下,进行10次KMeans算法的运行,并选择最佳结果(即惯性最小的结果) # max_iter=300:KMeans算法的最大迭代次数为300 # tol=0.0001:KMeans算法收敛的容忍度,即当质心变化小于这个值时,算法停止迭代 # random_state=111:设置随机种子为111,以确保结果的可复现性 # algorithm='elkan':使用'elkan'算法,这是KMeans算法的一种优化版本,尤其在稀疏数据上表现更好 algorithm = (KMeans(n_clusters = 5 ,init='k-means++', n_init = 10 ,max_iter=300, tol=0.0001, random_state= 111 , algorithm='elkan') ) # 使用前面定义的KMeans对象(algorithm)对X2(包含'Annual Income (k$)'和'Spending Score (1-100)'的数据)进行拟合,即进行聚类 algorithm.fit(X2) # 从KMeans对象中获取每个数据点的簇标签,即每个数据点所属的簇的编号 # 这些标签是整数,从0开始,对应于簇的索引 labels2 = algorithm.labels_ # 从KMeans对象中获取每个簇的质心(即中心点)的坐标 # 这是一个二维数组,其中每一行代表一个簇的质心,列对应于数据集中的特征(这里是'Annual Income (k$)'和'Spending Score (1-100)') centroids2 = algorithm.cluster_centers_# 设置网格步长,即网格中相邻两个点之间的间隔。这里设置为0.02,表示网格的精细度。 h = 0.02 # 找出数据集X2中第一列(即'Annual Income (k$)')的最小值和最大值,并分别减1和加1来扩展网格的边界,以确保所有数据点都被包含在内。 x_min, x_max = X2[:, 0].min() - 1, X2[:, 0].max() + 1 # 同理,找出数据集X2中第二列(即'Spending Score (1-100)')的最小值和最大值,并分别减1和加1来扩展网格的边界。 y_min, y_max = X2[:, 1].min() - 1, X2[:, 1].max() + 1 # 使用numpy的meshgrid函数生成一个二维网格。其中,np.arange(x_min, x_max, h)和np.arange(y_min, y_max, h)分别生成x和y轴上的点。 # meshgrid函数将这两个一维数组转换为两个二维数组xx和yy,它们表示网格上的所有点的坐标。 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 将xx和yy的二维数组展平(ravel)成一维数组,并使用np.c_将它们组合成一个二维数组,其中每一行代表网格上的一个点('Annual Income (k$)'和'Spending Score (1-100)'的坐标)。 # 然后,使用KMeans对象(algorithm)的predict方法预测这些点所属的簇。 # Z2将是一个一维数组,其中包含了网格上每个点所属的簇的标签。 Z2 = algorithm.predict(np.c_[xx.ravel(), yy.ravel()])
# 创建一个新的图形窗口,编号为1,并设置其大小为15x7英寸 plt.figure(1 , figsize = (15 , 7) ) # 清除当前图形窗口的内容(如果有的话),确保在干净的画布上绘图 plt.clf() # 由于Z2原本是一维数组,它包含了每个网格点所属的簇的标签。我们需要将其重新整形为与xx相同的形状, # 以便可以使用imshow来绘制聚类结果。 Z2 = Z2.reshape(xx.shape) # 使用imshow函数绘制Z2数组,即聚类结果。interpolation='nearest'表示使用最近邻插值法。 # extent参数定义了图像在x和y轴上的扩展范围,与xx和yy的边界对应。 # cmap=plt.cm.Pastel2设置了颜色映射,这里使用了Pastel2配色方案。 # aspect='auto'允许自动调整x和y轴的比例,以保持数据的真实比例。 # origin='lower'表示图像的原点在左下角。 plt.imshow(Z2 , interpolation='nearest', extent=(xx.min(), xx.max(), yy.min(), yy.max()), cmap = plt.cm.Pastel2, aspect = 'auto', origin='lower') # 绘制原始数据点。这里不能直接使用字符串'Annual Income (k$)'和'Spending Score (1-100)'作为x和y的值, # 而是应该从数据框df中提取这些列的实际值。c=labels2表示使用labels2数组中的值来为数据点着色, # s=200设置了数据点的大小。 plt.scatter( x = 'Annual Income (k$)' ,y = 'Spending Score (1-100)' , data = df , c = labels2 , s = 200 ) # 绘制聚类中心(质心)。x和y分别使用centroids2数组的第一列和第二列的值。 # s=300设置了质心点的大小,c='red'表示质心点用红色绘制,alpha=0.5设置了点的透明度。 plt.scatter(x = centroids2[: , 0] , y = centroids2[: , 1] , s = 300 , c = 'red' , alpha = 0.5) # 设置y轴的标签为'Spending Score (1-100)',设置x轴的标签为'Annual Income (k$)'。 # 注意这里使用逗号分隔了两个函数调用,是Python中一种常见的在一行内写多个语句的方式。 plt.ylabel('Spending Score (1-100)') , plt.xlabel('Annual Income (k$)') plt.show()年收入和支出分数的可视化KMeans聚类的结果:
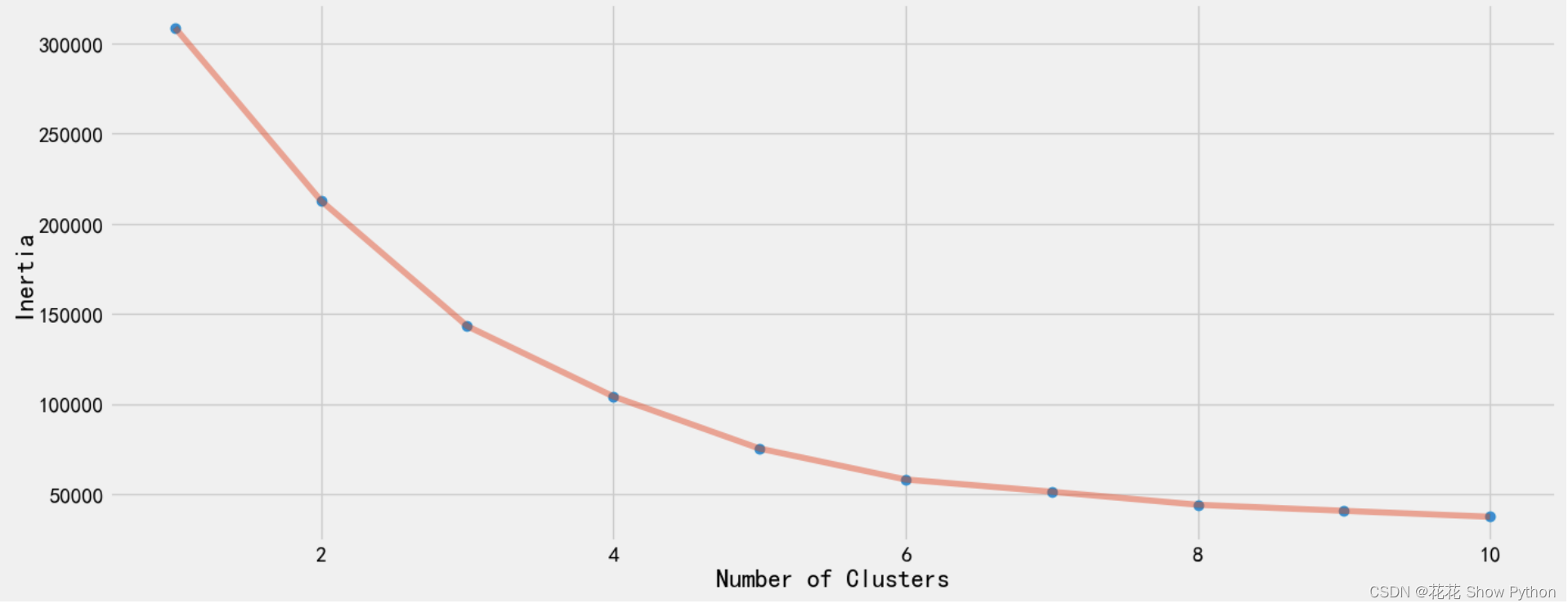
# 注意:iloc[: , :]在这里是多余的,因为它实际上选择了所有的行和列,但在这里它不会造成错误。 X3 = df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']].iloc[:, :].values # 创建一个空列表,用于存储每次KMeans聚类后的惯性(即簇内距离的平方和) inertia = [] # 循环遍历从1到10的整数(包括1但不包括11),代表要形成的簇的数量 for n in range(1, 11): # 创建一个KMeans对象,设置n_clusters为当前的n值(即簇的数量),以及其他一些参数 algorithm = (KMeans(n_clusters=n, init='k-means++', n_init=10, max_iter=300, tol=0.0001, random_state=111, algorithm='elkan')) # 使用KMeans对象对X3数据进行拟合(即进行聚类) algorithm.fit(X3) # 获取这次聚类的惯性,并将其添加到inertia列表中 inertia.append(algorithm.inertia_) # 现在inertia列表包含了从1到10个簇时的惯性值,可以用于后续的图形化显示或选择最佳簇数(即“肘部方法”)# 创建一个新的图形窗口,编号为1,并设置其大小为15x6英寸 plt.figure(1, figsize=(15, 6)) # 使用plot函数绘制散点图,表示簇的数量与对应的惯性值。 # np.arange(1, 11)生成了一个从1到10的整数数组,代表簇的数量。 # inertia是之前计算得到的惯性值列表。 # 'o'指定了点的样式为圆圈。 plt.plot(np.arange(1, 11), inertia, 'o') # 再次使用plot函数绘制线图,以连接上述散点,这样可以更清晰地看到惯性值随簇数量增加的变化趋势。 # '-'指定了线的样式为实线。 # alpha=0.5设置了线的透明度,使散点图更加突出。 plt.plot(np.arange(1, 11), inertia, '-', alpha=0.5) # 设置x轴的标签为'Number of Clusters',表示簇的数量。 # 注意这里使用了逗号分隔了两个函数调用,是Python中一种常见的在一行内写多个语句的方式。 plt.xlabel('Number of Clusters'), plt.ylabel('Inertia') # 显示图形窗口 plt.show()KMeans聚类中聚类数量与惯性值之间的关系图:
# 创建一个KMeans对象,设置其参数来初始化KMeans聚类算法。 # 参数说明如下: # n_clusters: 指定的簇数量,这里设置为6,表示数据将被分为6个簇。 # init: 初始化方法,'k-means++' 是一种用于选择初始质心集合的算法,它通常可以产生比随机初始化更好的结果。 # n_init: 使用不同的初始质心设置运行KMeans算法的次数,选择最佳结果(即最小惯性)的那次。这里设置为10,意味着算法会运行10次,每次使用不同的初始质心。 # max_iter: 单次运行的迭代最大次数,即算法会尝试优化簇质心的最大次数。这里设置为300。 # tol: 容忍的最小优化值,当(惯性)改进低于这个值时,算法将停止迭代。这里设置为0.0001。 # random_state: 随机数生成器的种子,用于初始化质心。设置随机种子可以确保结果的可重复性。这里设置为111。 # algorithm: KMeans算法的实现,'elkan'是一种更高效的实现,尤其是在大数据集上。 algorithm = (KMeans(n_clusters=6, init='k-means++', n_init=10, max_iter=300, tol=0.0001, random_state=111, algorithm='elkan')) # 使用KMeans对象对X3数据进行拟合(即进行聚类),将数据划分为n_clusters指定的簇数(在这里是6个簇)。 # 这个过程会找到每个簇的质心,并将每个数据点分配给最近的质心所代表的簇。 algorithm.fit(X3) # labels3变量用于存储每个数据点所属的簇的标签。 # 这些标签是整数,范围从0到n_clusters-1(在这里是从0到5)。 labels3 = algorithm.labels_ # centroids3变量用于存储每个簇的质心(即簇的中心点)。 # 它是一个二维数组,其中每一行代表一个簇的质心,每一列代表一个特征(在这里是Age、Annual Income (k$)和Spending Score (1-100))。 centroids3 = algorithm.cluster_centers_# 将KMeans算法生成的簇标签(labels3)添加到原始数据框df中作为一个新的列'label3'。 df['label3'] = labels3 # 创建一个3D散点图的trace对象,使用plotly的go.Scatter3d类。 trace1 = go.Scatter3d( # 设置x轴的数据为df中的'Age'列。 x= df['Age'], # 设置y轴的数据为df中的'Spending Score (1-100)'列。 y= df['Spending Score (1-100)'], # 设置z轴的数据为df中的'Annual Income (k$)'列。 z= df['Annual Income (k$)'], # 设置模式为'markers',即只显示标记点,不显示连线。 mode='markers', # 设置标记点的属性。 marker=dict( # 设置标记点的颜色为df中的'label3'列,即每个簇使用不同的颜色。 color = df['label3'], # 设置标记点的大小为20。 size= 20, # 设置标记点的边界线属性。 line=dict( # 设置边界线的颜色与标记点颜色相同(即与簇标签对应)。 color= df['label3'], # 设置边界线的宽度为12。 width= 12 ), # 设置标记点的透明度为0.8。 opacity=0.8 ) ) # 创建一个包含trace1的数据列表。 data = [trace1] # 创建一个布局对象,用于设置图表的整体布局。 layout = go.Layout( # (注释掉的代码)设置图表的边距,但这里被注释掉了,所以图表将使用默认边距。 # title= 'Clusters', # 标题设置为'Clusters' # 设置图表的标题为'Clusters'。 title= 'Clusters', # 设置3D场景的属性。 scene = dict( # 设置x轴的属性,标题为'Age'。 xaxis = dict(title = 'Age'), # 设置y轴的属性,标题为'Spending Score'。 yaxis = dict(title = 'Spending Score'), # 设置z轴的属性,标题为'Annual Income'。 zaxis = dict(title = 'Annual Income') ) ) # 创建一个Figure对象,并传入数据和布局。 fig = go.Figure(data=data, layout=layout) # 使用plotly的offline模块来在本地显示图表。注意:py.offline.iplot是一个较旧的plotly API调用, # 在新版本的plotly中,可能需要使用其他方法(如plotly.offline.plot或直接在Jupyter Notebook中使用fig.show())。 # 这里假设您已经正确地设置了plotly的offline模式或者在一个支持的环境下运行此代码。 py.offline.iplot(fig)年龄、年收入和支出分数的可视化KMeans聚类的结果:

最后我以最后一次可视化的结果为例,将分类数值映射到原数据,直观的反映聚类结果。

最后一列就是我们的聚类结果了,从最后一次聚类可视化结果可以看出,有5个红色的质心,共有5个簇(也就是按超市会员的不同特征分成5类人)。K-Means算法在商场顾客细分领域的应用是一个典型的案例,它可以帮助商场管理者更好地理解顾客群体的特征和偏好,从而制定更加精准的营销策略。
创作不易,点赞、收藏、评论、转发,评论区留邮箱免费拿数据集。



