
Django-开发一个列表页面
需求
- 基于ListView,创建一个列表视图,用于展示"BookInfo"表的信息
- 要求提供分页
- 提供对书名,作者,描述的查询功能
示例展示:
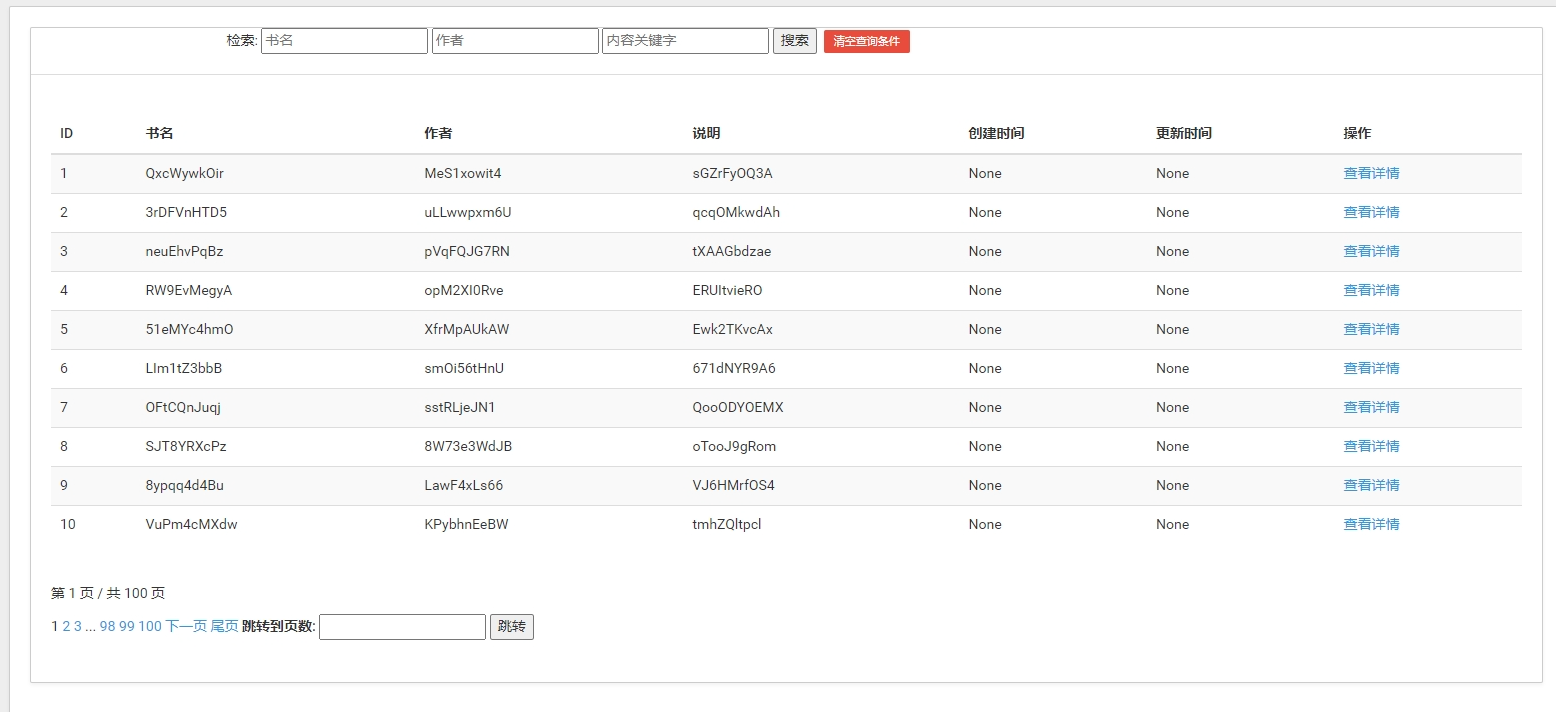
1. 数据模型
models.py
class BookInfo(models.Model):
title=models.CharField(verbose_name="书名",max_length=100)
author=models.CharField(verbose_name="作者",max_length=100)
desc=models.TextField(verbose_name="介绍")
create_at=models.DateTimeField(verbose_name="创建时间",auto_now=True)
update_at=models.DateTimeField(verbose_name="更新时间",auto_now_add=True)
2. 视图
views.py
from functools import reduce
from typing import Any
from django.shortcuts import render,redirect
from django.db.models import Q
from django.views.generic import ListView
from django.views.generic.detail import DetailView
from .models import *
from .forms import *
class BookListView(ListView):
model=BookInfo
template_name = "demo1/book_list.html"
paginate_by = 10
def get_queryset(self):
title = self.request.GET.get('title')
author = self.request.GET.get('author')
content = self.request.GET.get('content')
# 如果有任意参数不为空,则构建Q对象进行查询
queries = [Q(titile__icontains=title) if title else Q(),
Q(author__icontains=author) if author else Q(),
Q(desc__icontains=content) if content else Q()]
# 使用Q对象的&操作符组合查询条件
queryset = BookInfo.objects.filter(reduce(lambda x, y: x & y, queries)) if queries else BookInfo.objects.all()
return queryset
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
# 保留查询参数到分页链接
query_params = self.request.GET.copy()
if 'page' in query_params:
del query_params['page'] # 移除现有的页码参数以避免冲突
paginator = context['paginator']
page_numbers_range = 5 # 您可以根据需要调整显示的页码范围大小
max_index = len(paginator.page_range)
page = self.request.GET.get('page')
current_page = int(page) if page else 1
start_index = int((current_page - 1) / page_numbers_range) * page_numbers_range
end_index = start_index + page_numbers_range
if end_index >= max_index:
end_index = max_index
page_range = paginator.page_range[start_index:end_index]
context['page_range'] = page_range
context['query_params'] = query_params.urlencode() # 将查询参数编码为URL字符串
return context
def get(self, request, *args, **kwargs):
# 如果是重定向回来的,需要处理paginate_by参数
if 'paginate_by' in request.GET:
try:
paginate_by = int(request.GET['paginate_by'])
if paginate_by > 0: # 防止不合法的值
self.paginate_by = paginate_by
except ValueError:
pass # 如果转换失败,忽略错误,使用默认设置
return super().get(request, *args, **kwargs)
class BookDetailView(DetailView):
model=BookInfo
template_name = "demo1/book_detail.html"
context_object_name = "book"
注册路由(urls.py)
from django.urls import path
from .views import *
urlpatterns = [
path("book",BookListView.as_view(),name="book-list"),
path("book/detail//",BookDetailView.as_view(),name="book-detail"),
]
3. 页面代码
列表页:
{% extends 'layout.html' %}
{% block main %}
检索:
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



