
【Vision Transformers-VIT】: 计算机视觉中的Transformer探索
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【车辆检测追踪与流量计数系统】 |
| 49.【行人检测追踪与双向流量计数系统】 | 50.【基于YOLOv8深度学习的反光衣检测与预警系统】 |
| 51.【危险区域人员闯入检测与报警系统】 | 52.【高压输电线绝缘子缺陷智能检测系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
介绍
Transformer 模型极大地推动了人工智能领域的发展,尤其是在自然语言处理 (NLP) 和计算机视觉领域。使 transformer 如此强大的关键特征之一是它们的注意力机制,它允许模型专注于输入数据的不同部分。
这种机制在Vision Transformers(ViT) 中尤为重要,该VIT在 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(Dosovitskiy 等人,2021 年)中介绍,它将Transformer架构应用于图像数据。
在这篇文章中,我们将深入探讨如何量化和可视化注意力,重点关注 ViT 模型,并演示如何生成和解释注意力地图。
ViT 模型:基于 Transformer 的计算机视觉架构
我们讨论的具体模型是 google/vit-large-patch32-384 ,它在 ImageNet-21k 上进行了预训练,并在 ImageNet 2012 上进行了微调。该模型具有:
- 分辨率:224x224(预训练)和 384x384(微调)
- 层数:24 层,每层有 16 个关注头
- Tokens:145(包括CLS-Tokens)
生成注意力热力图
注意力热力图有助于可视化模型聚焦的图像的哪些部分。层中的每个注意力头都学习tokens关系的不同方面。该过程包括:
- 通过模型管道推理图像
- 聚合注意力映射
- 平滑地图并将其应用于原始图像
配置 ViT 模型
为了能够从模型的推理中提取注意力数据,在加载预训练(和微调)模型时,在通过图像之前需要进行一些配置:
from transformers import ViTForImageClassification, ViTImageProcessor # Load a pre-trained ViT model and feature extractor model_name = 'google/vit-large-patch32-384' processor = ViTImageProcessor.from_pretrained(model_name, do_rescale=False) model = ViTForImageClassification.from_pretrained(model_name, attn_implementation='eager') # Run an image through the pipline inputs = processor(images=image, return_tensors="pt") outputs = model(**inputs, output_attentions=True) # Getting the attentions attentions = outputs.attentions
原始注意力
在汇总所有 24 层的总分类注意力之前,我们可以绘制单层 16 个注意力图像(作为标记的数量;145X145),让我们看一下最后一层,例如:
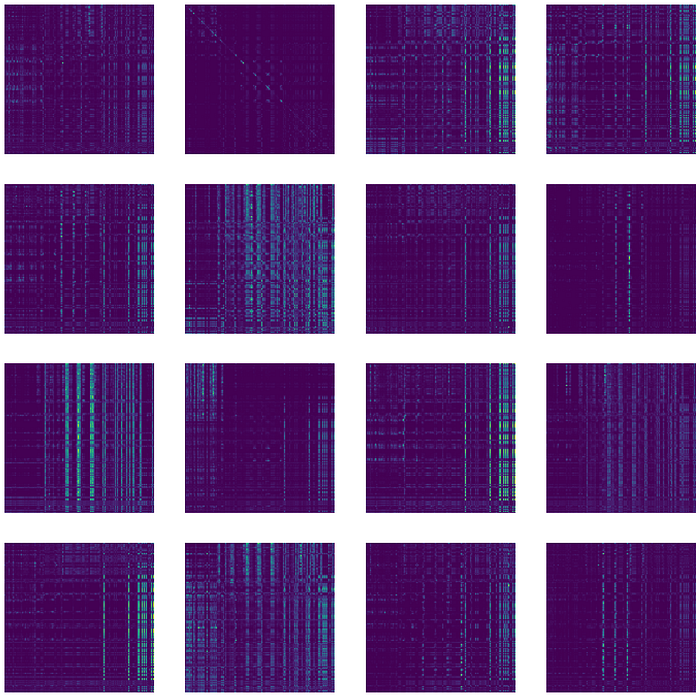
单层 16 张注意力图像 (16X145X145)
ig, axs = plt.subplots(4, 4, figsize=(20, 20)) for i, ax in enumerate(axs.flatten()): ax.imshow(attentions[-1][0, i, :, :].detach().cpu().numpy()) ax.axis('off')滚动注意力
滚动注意力聚合跨多个图层的注意力地图,提供跨所有图层的图像焦点的全面视图。该技术突出显示了最相关的区域,提供了一种视觉解释形式,并使模型的内部工作更易于解释。
根据Abnar&Zuidema(2020)的工作,transformers中的注意力流可以量化。数学过程包括以下步骤:
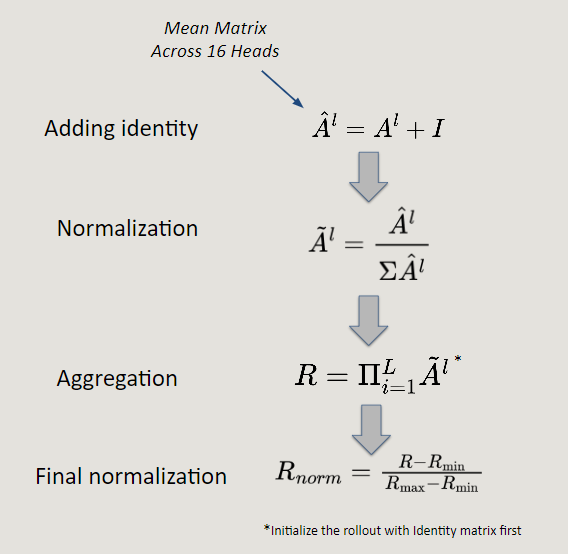
代码如下:
def attention_rollout(attentions): # Initialize rollout with identity matrix rollout = torch.eye(attentions[0].size(-1)).to(attentions[0].device) # Multiply attention maps layer by layer for attention in attentions: attention_heads_fused = attention.mean(dim=1) # Average attention across heads attention_heads_fused += torch.eye(attention_heads_fused.size(-1)).to(attention_heads_fused.device) # A + I attention_heads_fused /= attention_heads_fused.sum(dim=-1, keepdim=True) # Normalizing A rollout = torch.matmul(rollout, attention_heads_fused) # Multiplication return rollout这个简单的过程借鉴了基于Transformers的NLP任务模型评估,使我们能够聚合所有层的注意力,保留每个标记(视觉中的图像补丁)为任务传达的信息。
示例和视觉演示
以下是一些示例,展示了注意力图如何突出显示重要的图像区域,从而增强了转换器模型在视觉任务中的可解释性。
使用这个推出过程,我们能够在原始输入之上生成一个注意力布局:

输入和生成的注意力热力图,这是通过将分类标记的注意力向量扩展到 12X12 矩阵中来实现的。
cls_attention = rollout[0, 1:, 0] # Get attention values from [CLS] token to all patches cls_attention = 1 - cls_attention.reshape(int(np.sqrt(num_of_patches)), int(np.sqrt(num_of_patches)))
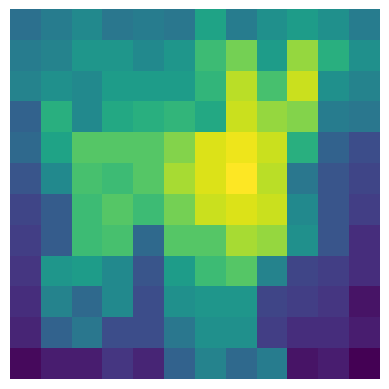
classifaciton tokens的 12X12 原始注意力热力图。
在应用Geussion Filter并重塑后,我们得到了要叠加的最终图像如下:
# Normalize the attention map for better visualization cls_attention = (cls_attention - cls_attention.min()) / (cls_attention.max() - cls_attention.min()) # Resize and blur the attention map cls_attention_resized = Image.fromarray((cls_attention * 255).astype(np.uint8)).resize((img_size, img_size), resample=Image.BICUBIC) cls_attention_resized = cls_attention_resized.filter(ImageFilter.GaussianBlur(radius=2))
操作后的注意力图
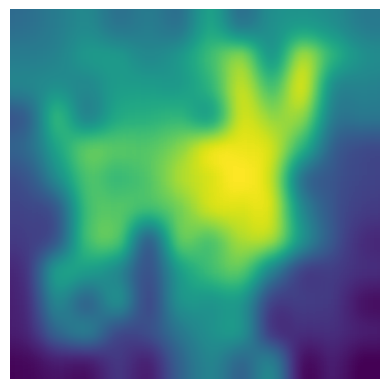
最后,应用灰度注意力叠加的变换:
# Convert the attention map to RGBA cls_attention_colored = np.array(cls_attention_resized.convert("L")) cls_attention_colored = np.stack([cls_attention_colored]*3 + [cls_attention_colored], axis=-1) # Adjust the alpha channel to control brightness cls_attention_colored_img = Image.fromarray(cls_attention_colored, mode="RGBA") cls_attention_colored_img.putalpha(100) # Adjust alpha for blending (lower value for darker overlay)生成的地图:

灰度注意力地图
总结
在图像分类任务领域,描绘注意力图像具有显着优势。
这些图像突出显示了图像中与特定任务最相关的区域,从而对影响模型决策的关键区域进行了重点分析。此功能充当视觉解释的一种形式,使模型的内部工作更易于解释。
通过揭示模型认为重要的图像部分,注意力地图增强了透明度和可信度,使用户能够更有效地理解和验证模型的预测。
在这个特定示例中,模型似乎在耳朵和脸上有更多的重点来确定这是一只狗。
好了,这篇文章就介绍到这里,感谢点赞关注,更多精彩内容持续更新中~
关注文末名片G-Z-H:【阿旭算法与机器学习】,可获取更多干货学习资源



