
Java:爬虫htmlunit抓取a标签
如果对htmlunit还不了解的话可以参考Java:爬虫htmlunit-CSDN博客
了解了htmlunit之后,我们再来学习如何在页面中抓取我们想要的数据,我们在学习初期可以找一些结构比较清晰的网站来做测试爬取,首先我们随意找个网站如下:

当我们打开网站F12,进入开发者模式,我们在学习之前我们需要知道我们要爬取什么数据,了解数据和页面的结构。就拿这个网站来说我们如果要爬取它的数据,首先需要获取他们的类别,在获取类别下的数据。那我们在点击类别的时候,需要分析下地址有没有变化,如果变化了,我们需要拿到指定类别的地址,然后和域名拼接成完整地址抓取其类目下的数据。
为什么要拼接呢?因为在网站类目使用的跳转,会自动加上站点地址;我们在爬取的时候是没有该网站域名的。
这个列子非常简单,我们直接要获取它的类别跳转的地址,再根据爬取的地址爬取其详情数据;
分析下来我们只要抓取该页面的a标签即可。这个在 htmlunit 中提供了 HtmlAnchor 直接可以获取所有的a标签,代码如下:
/**
* Function: todo
*
* @program: 根据页面信息获取子页面信息
* @Package: com.kingbal.king.dmp
* @author: dingcho
* @date: 2024/06/13
* @version: 1.0
* @Copyright: 2024 www.kingbal.com Inc. All rights reserved.
*/
@Slf4j
public class BaseTest {
public static void main(String[] args) throws Exception {
HtmlPage page = SpiderUtils.crawlPageWithoutAnalyseJs("https://www.yiyiwiy.com/");
//System.err.println(page);
List htmlAnchorList = page.getAnchors();
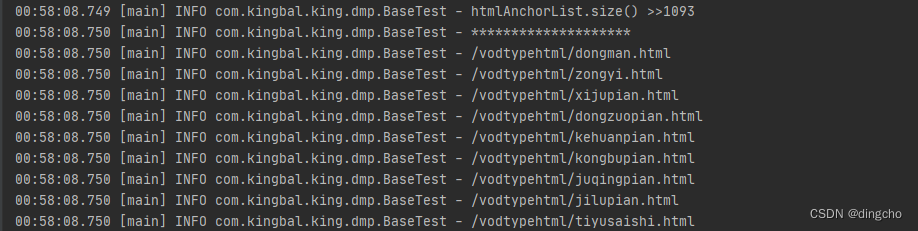
log.info("htmlAnchorList.size() >>" + htmlAnchorList.size());
log.info("********************");
htmlAnchorList.forEach(f -> {
if(f.getHrefAttribute().contains("vodtypehtml")){
log.info(f.getHrefAttribute());
}
});
log.info("********************");
}
}
我们抓取的是所有页面的a标签,所以我们需要过滤掉我们不需要的地址:
if(f.getHrefAttribute().contains("vodtypehtml")){
log.info(f.getHrefAttribute());
}
然后执行代码,就可以获取到对应数据
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



