
Elasticsearch 索引、类型、文档、分片与副本等核心概念介绍
温馨提示:这篇文章已超过368天没有更新,请注意相关的内容是否还可用!

🐇明明跟你说过:个人主页
🏅个人专栏:《洞察之眼:ELK监控与可视化》🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、Elasticsearch简介
2、分布式搜索引擎的工作原理
二、Elasticsearch核心组件
1、索引(Index)
2、类型(Type,注:自Elasticsearch 7.x开始已弃用)
3、文档(Document)
4、节点(Node)
5、集群(Cluster)
6、分片(Shard)与副本(Replica)
7、Elasticsearch与MySQL的对应关系
一、引言
1、Elasticsearch简介
Elasticsearch 是一个开源的分布式搜索和分析引擎,最初由 Elasticsearch N.V. 公司开发,并于 2010 年首次发布。它建立在 Apache Lucene 基础之上,提供了分布式的实时搜索和分析功能,被广泛应用于各种场景,包括日志分析、全文搜索、监控和可视化等。
以下是 Elasticsearch 的一些重要特点和功能:
1. 分布式架构:
- Elasticsearch 是一个分布式系统,数据可以水平扩展到多个节点上存储和处理。
- 数据被分割成多个分片(Shard),每个分片可以被复制到多个副本(Replica),以提高数据的可用性和容错性。
2. 实时搜索:
- Elasticsearch 提供了快速的实时搜索功能,可以在大规模数据集上快速地进行搜索、过滤和排序。
- 支持复杂的搜索查询语法和全文搜索功能,可以满足各种搜索需求。
3. 多种数据类型:
- Elasticsearch 支持多种数据类型的存储和索引,包括文本、数字、日期、地理位置等。
- 支持结构化数据和非结构化数据的索引和查询。
4. 强大的聚合和分析:
- Elasticsearch 提供了丰富的聚合(Aggregation)功能,可以对数据进行统计、分组、计算等操作。
- 支持各种聚合函数和桶(Bucket)操作,可以生成复杂的数据分析报表和可视化。
5. RESTful API:
- Elasticsearch 提供了基于 RESTful API 的接口,支持各种 HTTP 请求和 CRUD 操作。
- 开发者可以使用各种编程语言和工具与 Elasticsearch 进行交互,实现数据的索引、搜索和分析。
6. 可扩展性和灵活性:
- Elasticsearch 提供了丰富的插件和扩展机制,可以根据需求定制和扩展功能。
- 支持与其他开源工具和系统集成,如 Logstash、Kibana、Beats 等,构建完整的日志分析和监控解决方案。

2、分布式搜索引擎的工作原理
- 数据采集:分布式搜索引擎从多个来源采集数据,这些数据可以是网页、文档、日志、数据库等。数据采集可以通过网络爬虫、日志收集器等方式进行。
- 数据处理和索引构建:采集到的数据需要进行处理和索引构建,以便后续的快速搜索。在这个阶段,文本数据会被分词、分析,并构建索引结构。索引结构通常包括倒排索引等,用于加快搜索速度和提高搜索精度。
- 索引分片和分布式存储:索引构建完成后,索引数据会被分片存储在多个节点上,以确保数据的高可用性和可扩展性。分布式存储系统通常使用分布式文件系统(如HDFS)、分布式数据库(如Elasticsearch、Apache Solr)、NoSQL数据库(如MongoDB、Cassandra)等。
- 搜索请求处理:当用户提交搜索请求时,搜索引擎会接收到请求并进行处理。搜索请求处理包括解析用户查询、检索相关文档、计算文档相关度等步骤。通常情况下,搜索请求会被路由到多个索引分片上并行处理,以提高搜索速度。
- 结果聚合和排序:搜索引擎会将检索到的文档按照相关度排序,并返回给用户。搜索结果可能还包括分页、高亮显示、聚合等功能,以提高用户体验。
- 搜索结果缓存:为了提高搜索性能,搜索引擎通常会使用缓存来存储热门搜索结果。这样,对于相同的查询请求,可以直接从缓存中获取结果,而不需要重新计算。
- 系统监控和优化:搜索引擎会持续监控系统性能、用户行为等指标,并根据监控结果进行系统优化和调整,以提高搜索效率和用户满意度。

二、Elasticsearch核心组件
1、索引(Index)
Elasticsearch 的核心组件之一是索引(Index)。索引是 Elasticsearch 中存储和组织数据的基本单位,类似于关系型数据库(MySQL)中的表。
1. 定义:
- 索引在 Elasticsearch 中是一个逻辑存储单元,类似于关系型数据库中的“数据库”概念。
- 它是一个文档的集合,这些文档具有相似的特性或属于同一逻辑分类。
2. 分片与副本:
- 索引可以包含一个或多个分片(Shards),每个分片都是一个 Lucene 实例,可以独立地进行搜索和存储操作。分片允许 Elasticsearch 在多个服务器上水平扩展,从而处理更多的数据和查询。
- 每个分片可以有零个或多个副本(Replicas),副本是分片的完整拷贝,用于提供数据的冗余和容错性。当某个分片所在的服务器出现故障时,可以从其副本中恢复数据。
3. 数据存储:
- 索引中的文档被存储为 JSON 格式,这使得 Elasticsearch 能够存储结构化和非结构化数据。
- Elasticsearch 使用倒排索引(Inverted Index)技术来实现高效的全文搜索。倒排索引将文档中的单词与其在文档中的位置信息关联起来,从而可以快速定位包含特定单词的文档。
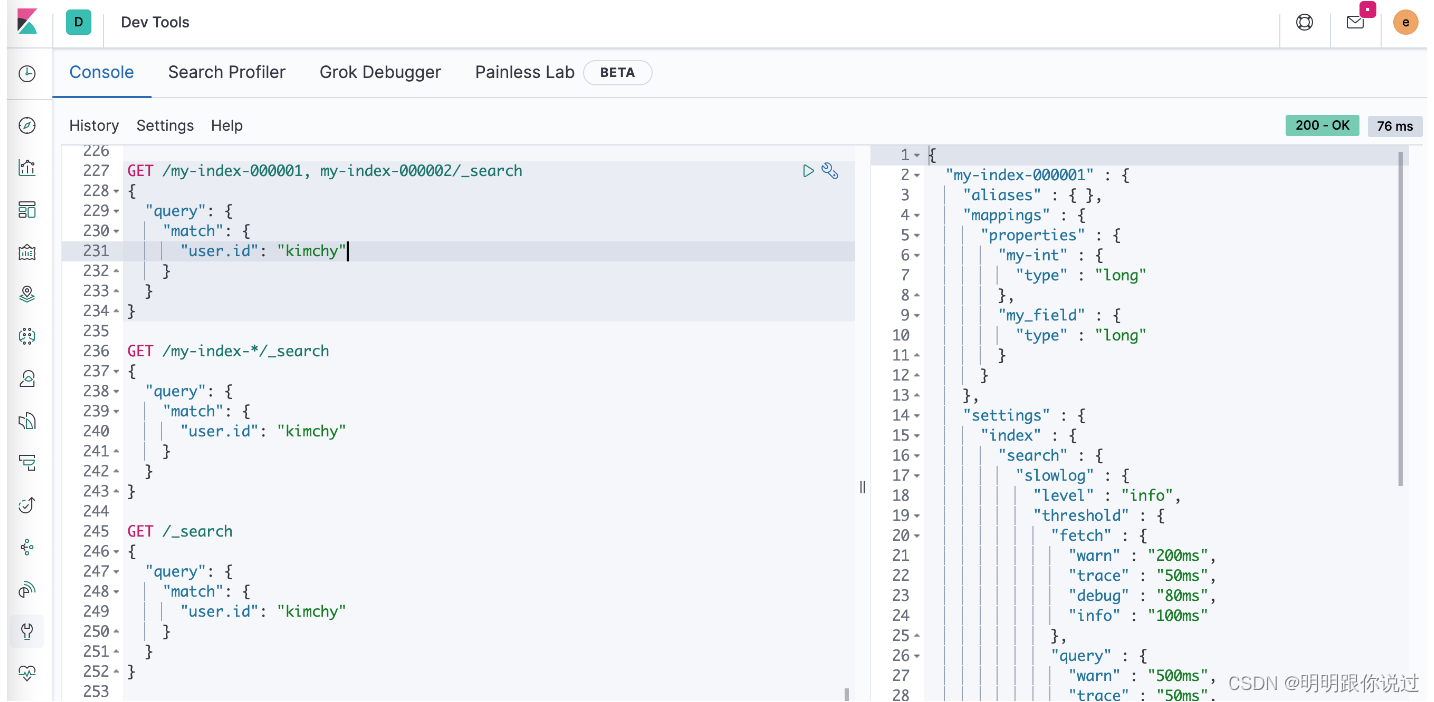
2、类型(Type,注:自Elasticsearch 7.x开始已弃用)
在Elasticsearch的早期版本中,类型(Type)是一个重要的概念,它用于在一个索引中定义不同的文档类型。从Elasticsearch 7.x版本开始,类型(Type)的概念已经被弃用,并在8.x版本中完全移除。这是为了简化索引和搜索操作,并提高数据的一致性和可靠性。
在早期的Elasticsearch版本中,类型允许用户在一个索引中存储多种类型的文档。每个类型都有自己的映射(Mapping),定义了文档的结构和属性。这种灵活性使得用户可以在一个索引中存储具有不同结构的数据,但也可能导致数据管理和查询的复杂性增加。
随着Elasticsearch的发展,官方团队发现类型的存在带来了许多问题。首先,它增加了索引的复杂性,使得管理和优化变得更加困难。其次,类型在某些情况下可能导致数据不一致和查询错误。因此,官方决定逐步弃用类型,并在8.x版本中完全移除它。
在没有类型的Elasticsearch中,每个索引都只能包含一种类型的文档。这意味着用户需要为每个不同的数据类型创建一个单独的索引。虽然这可能会增加索引的数量,但它可以提高数据的一致性和可靠性,并简化索引和搜索操作。

3、文档(Document)
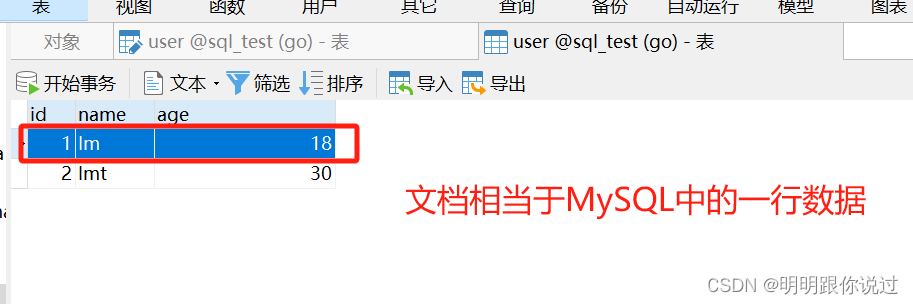
在 Elasticsearch 中,文档(Document)是存储在索引(Index)中的基本数据单位。每个文档都是一个 JSON 格式的数据对象,它包含了一系列字段(Field)和对应的值。文档可以被索引、检索、更新和删除。
文档(Document)在 Elasticsearch 中相当于 MySQL 中的行(Row)。就像 MySQL 中的每一行代表一个数据记录,而 Elasticsearch 中的每个文档也代表着一个数据实体。因此,文档和行都是存储在数据库中的基本数据单位,它们都包含了一系列的字段和对应的值。
以下是关于 Elasticsearch 文档的一些重要概念和特点:
- 结构化数据:文档是结构化的数据对象,由多个字段组成。每个字段都有一个名称和对应的值,可以是简单的数据类型(如文本、数字、日期等)或复杂的数据结构(如嵌套对象、数组等)。
- 唯一标识:每个文档都有一个唯一标识符(ID),用于在索引中唯一标识该文档。ID 可以由 Elasticsearch 自动生成,也可以由用户指定。
- 索引存储:文档被存储在索引中,每个索引可以包含多个文档。索引是文档的集合,类似于关系型数据库中的表。
- 字段映射:文档的字段映射定义了每个字段的数据类型、分析器等属性。字段映射可以手动指定,也可以由 Elasticsearch 根据插入的文档自动推断生成。
- 全文搜索:Elasticsearch 支持全文搜索,可以对文档中的文本字段进行全文检索。全文搜索可以根据关键词、词语匹配度等条件快速定位到符合条件的文档。
- CRUD 操作:文档支持 CRUD 操作,即创建(Create)、读取(Retrieve)、更新(Update)和删除(Delete)。通过 Elasticsearch 的 API 可以对文档进行增删改查操作。
- 版本控制:Elasticsearch 支持文档的版本控制,每个文档可以有多个版本。当对文档进行更新操作时,Elasticsearch 会自动创建新版本,并保存历史版本的数据。
文档是 Elasticsearch 中存储和组织数据的基本单位,具有灵活的数据模型、强大的全文搜索和分析功能,是构建分布式搜索引擎和分布式数据存储系统的核心组件之一。
4、节点(Node)
Elasticsearch中的节点(Node)指的是Elasticsearch实例的运行实例,即一个独立的Elasticsearch服务进程。每个节点都是一个独立的工作单元,负责存储数据、参与数据处理(如索引、搜索、聚合等)以及参与集群的协调工作。
通过多个节点(Node),可以组成Elasticsearch高可用集群
节点可以承担多种角色,包括但不限于:
- 主节点(Master Node):负责集群范围内的元数据管理和变更,如索引创建、删除、分片分配等。
- 数据节点(Data Node):存储实际数据和相关的索引文件,参与数据的索引、搜索和恢复过程。
- 协调节点(Coordinating Node):接收客户端请求,将请求路由至适当的节点,并将结果汇总返回给客户端。每个节点都可以充当协调节点,也可以专门设置某些节点仅作为协调节点。
节点可以在物理或虚拟机上单独部署,也可以在同一台机器上运行多个节点(但需注意资源分配)。节点通过HTTP协议进行通信,共同管理集群的状态和数据。在Elasticsearch集群中,多个节点协同工作,共同提供高效、可靠的数据存储和搜索服务。
5、集群(Cluster)
在 Elasticsearch 中,集群(Cluster)是由一个或多个节点(Node)组成的分布式系统。这些节点协同工作,共同存储、索引和搜索数据,提供高可用性、可伸缩性和容错性。
- 节点的集合:集群是由多个节点组成的集合。每个节点都是一个独立的 Elasticsearch 实例,可以独立运行,也可以加入到一个集群中。
- 数据分片和副本:集群中的数据被分成多个分片(Shard),每个分片可以在集群的不同节点上进行存储和复制。分片的复制称为副本(Replica),用于提高数据的可用性和容错性。
- 负载均衡:集群可以自动进行负载均衡,将搜索请求和索引请求分配到各个节点上,以实现数据的均衡存储和处理。
- 故障检测和容错:集群可以检测到节点的故障并进行处理,例如自动将丢失的分片复制到其他节点上,以确保数据的完整性和可用性。
- 主节点:集群中的主节点(Master Node)负责集群的管理和协调工作,例如分配分片、故障检测、节点加入和退出等。
- 集群状态:集群的状态可以是健康的(Green)、部分健康的(Yellow)或者不健康的(Red),根据集群中分片的分布和副本的状态来判断。
- 动态扩展:集群可以根据需要动态扩展,可以增加节点、增加分片副本或者增加集群中的分片数量。
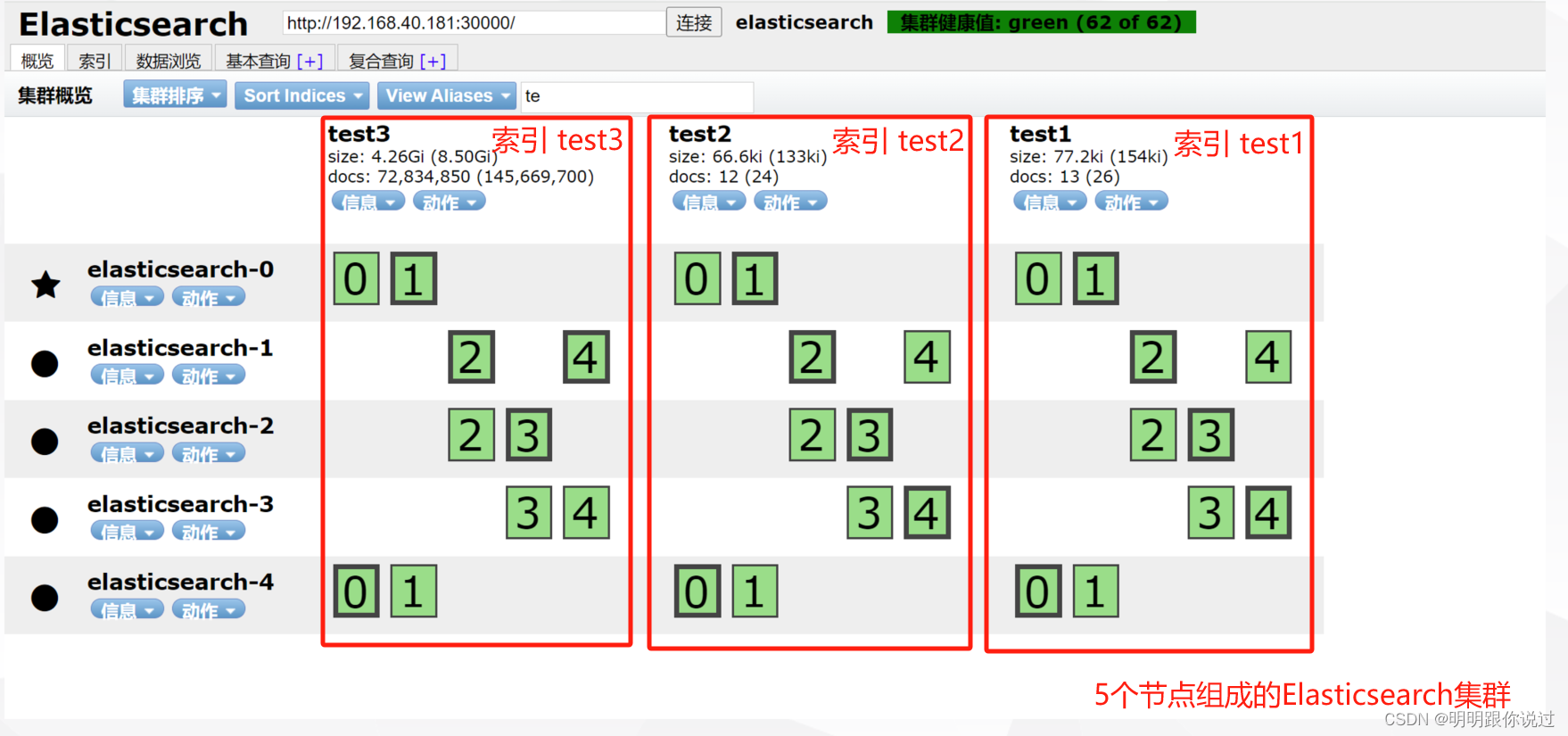
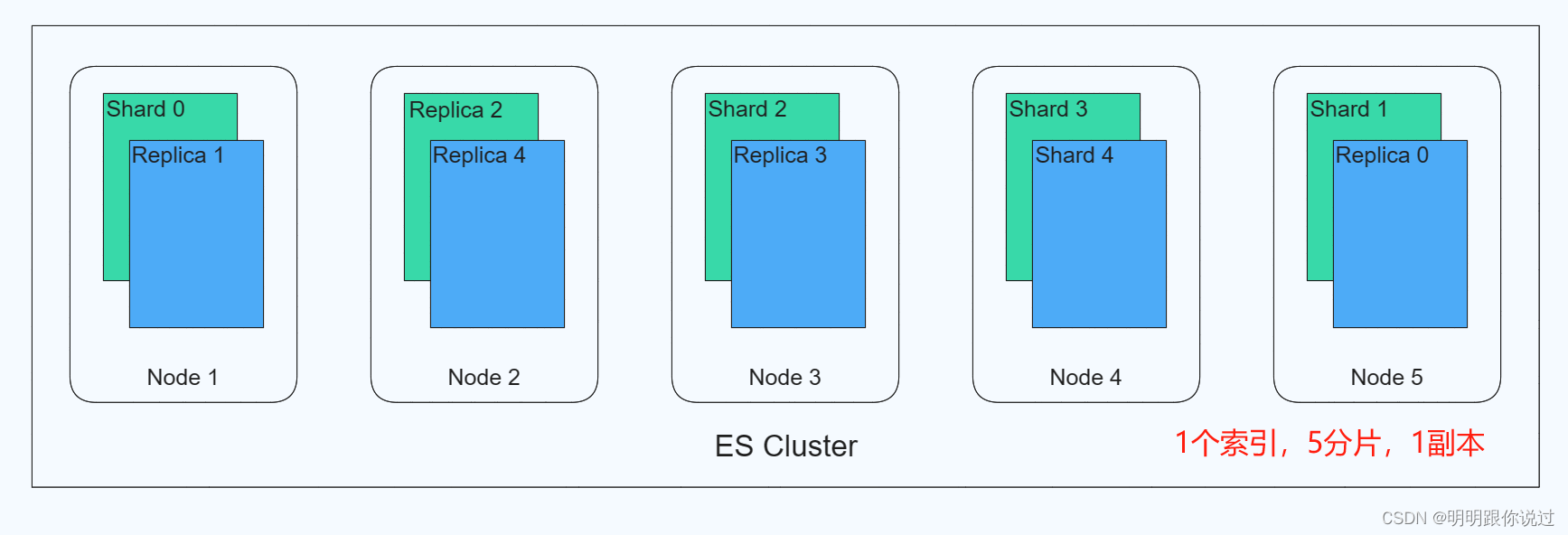
6、分片(Shard)与副本(Replica)
在 Elasticsearch 中,分片(Shard)和副本(Replica)是两个重要的概念,它们在集群中起着不同的作用。
分片(Shard):
- 分片是 Elasticsearch 中存储数据的基本单位,每个索引(Index)都被分成多个分片,每个分片是一个独立的 Lucene 索引。
- 分片的数量在索引创建时就确定了,一旦确定就不能修改。默认情况下,每个索引会被分配 5 个主分片(Primary Shard),可以通过配置来修改。
- 分片的主要作用是实现数据的分布和并行处理。通过将索引数据分成多个分片存储在不同的节点上,可以提高搜索和索引操作的并发性和吞吐量。
副本(Replica):
- 副本是分片的拷贝,每个分片可以有多个副本。副本的数量在索引创建时可以指定,也可以后续动态修改。
- 副本的主要作用是提高数据的可用性和容错性。当某个节点上的分片不可用时,集群可以从其它节点上的副本中提供服务,确保数据的完整性和可用性。
- 默认情况下,每个分片会有一个副本,可以通过配置来修改副本的数量。副本的数量可以根据集群的规模、性能需求和容错需求来灵活调整。
7、Elasticsearch与MySQL的对应关系
在 MySQL 中,表(Table)用于存储数据记录,而在 Elasticsearch 中,索引(Index)用于存储文档。一个索引可以看作是 MySQL 中的表,而文档则是表中的行。
类比关系如下:
- MySQL 中的表(Table)对应于 Elasticsearch 中的索引(Index)。
- MySQL 中的行(Row)对应于 Elasticsearch 中的文档(Document)。
- MySQL 中的字段(Field)对应于 Elasticsearch 中的字段(Field)。

💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于ELK的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!



