
前端使用pdf.js进行pdf文件预览的第二种方式:Viewer.html
温馨提示:这篇文章已超过399天没有更新,请注意相关的内容是否还可用!
背景
最近需要实现一个PDF文档预览的功能,按理说,如果只是简单的预览,使用、等就可以实现。
但是,我们的需求要实现搜索!而且,文档还都超大,均300页以上。那、就难以实现了!所以使用pdf.js库。
摘要
上一篇文章 前端 使用pdf.js加载PDF文件 中讲的是使用canvas绘图的方式,将PDF文件渲染在页面中。但其实PDF.js也提供了通过viewer.html来加载预览PDF文件,而且使用非常方便。
viewer.html很好用,但是我查遍了很多文档,真的都好难看懂是怎么使用的啊!那下面,我们把使用viewer.html的方法直接贴出来。
使用Viewer.html的好处
- 与我上一篇文章中提到的canvas绘图相比,性能肯定是比较好的;
- 自带了搜索、页面跳转、高亮等等工具栏,不需要手动实现了,这是莫大的便利。
viewer.html使用
第一步:pdf.js文档和文件包下载
- pdf.js文档: https://github.com/mozilla/pdf.js?tab=readme-ov-file,这个是pdf.js的readme.md地址,所有的使用指导在这里都可以找到。
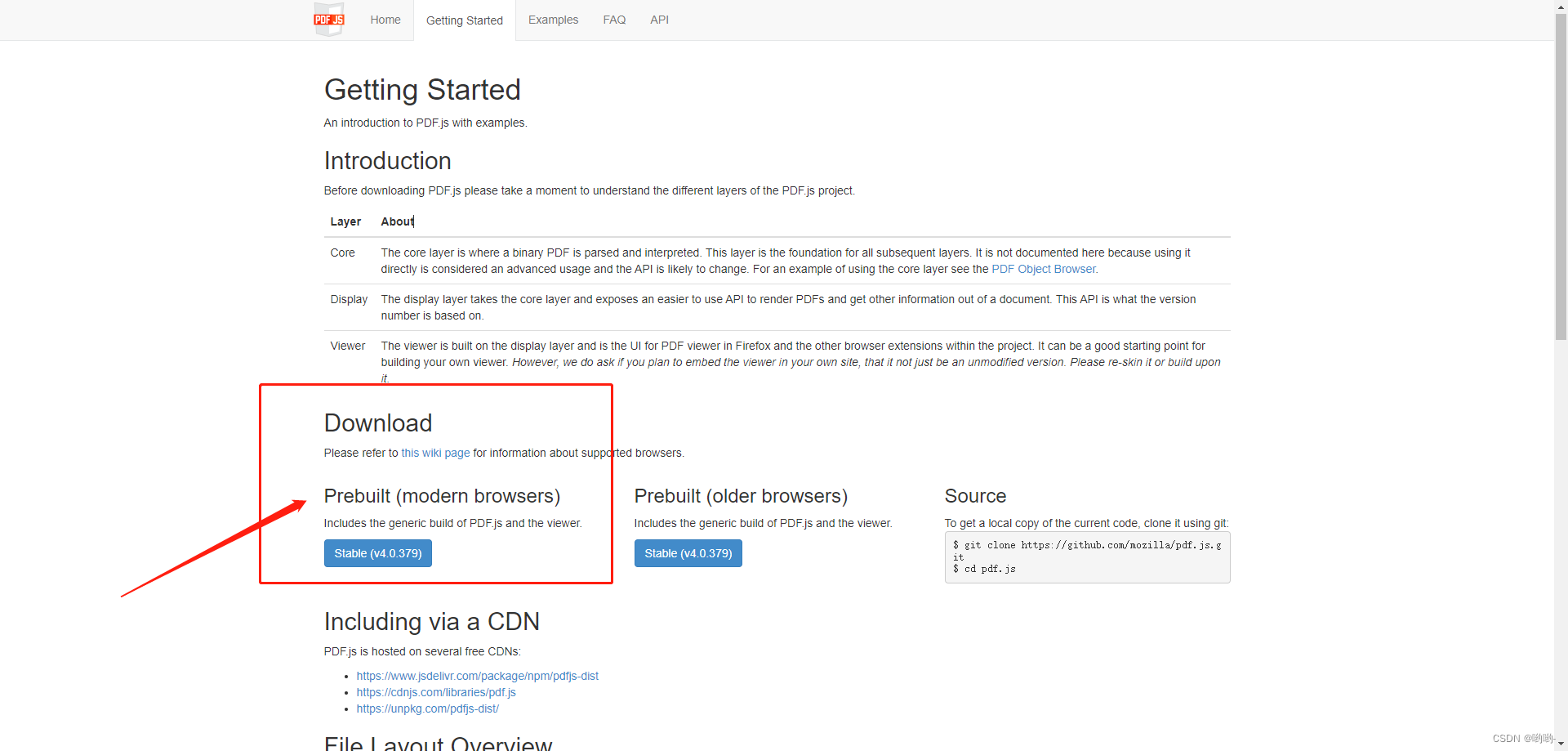
- 文件包下载:你可以在上面的这个页面中找到。当然也可以在这个地址中:https://mozilla.github.io/pdf.js/getting_started/#download,选择stable下载。下载页面截图如下:
第二步:下载到pdf.js按照包后,怎么使用呢?放在哪里
有两种方式:
1. 第一种方式:放在你当前项目的路径下,像下面这样:
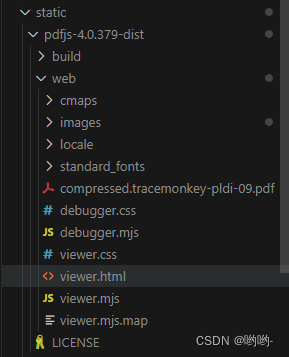
说明:
- pdfjs-4.0.379-dist是下载的pdf文件的夹,里面的viewer.html文件,就是它的入口文件。
2. 第二种方式:将它部署成为一个静态服务(这是本示例中我所使用的方式)
这样做的好处是:
- 对于当前项目,项目体量减小;
- 部署一个静态服务,多个项目可调用。便利性更好
题外话:将pdfjs部署在亚马逊
创建一个部署静态服务的存储桶,上传下载下来的文件包,如下所示:
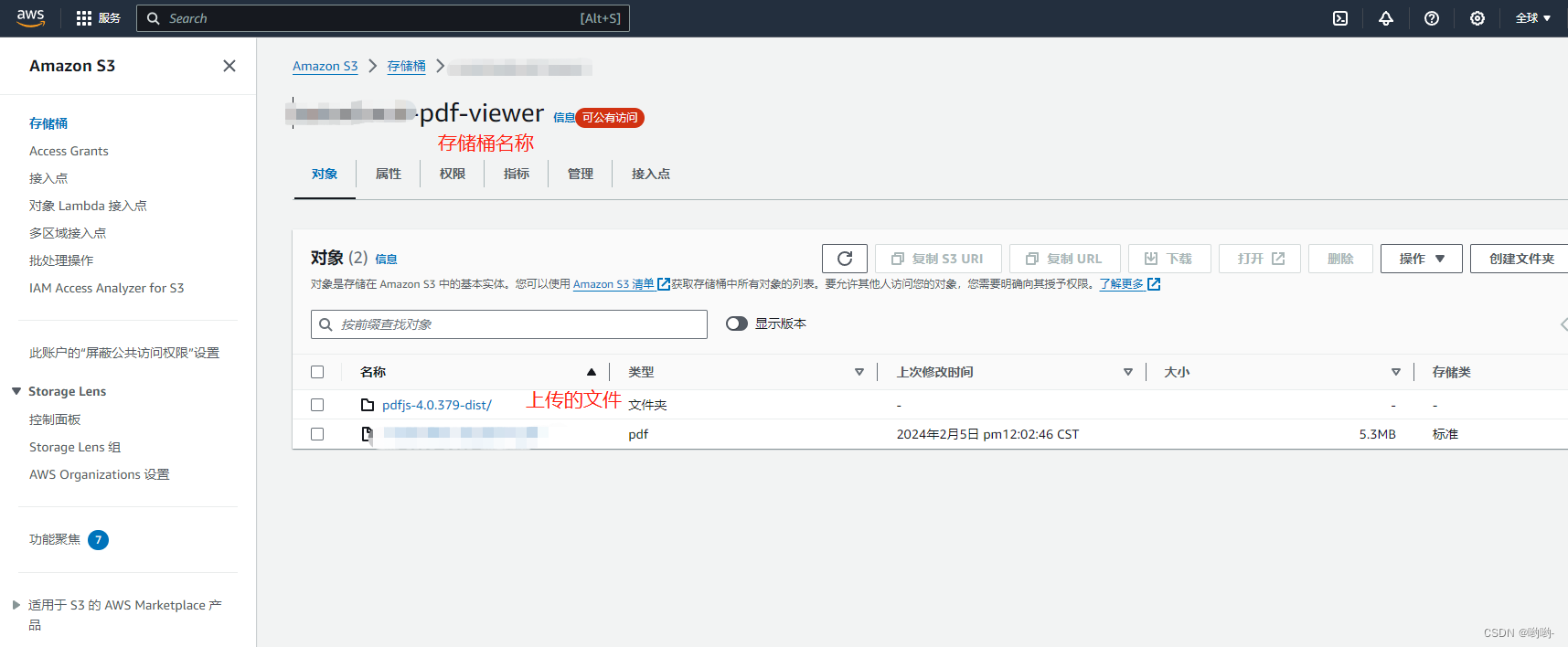
这样一来,存放在该静态服务内的pdf文件都可以访问了。假设部署的服务地址是:http://xxx-pdf-viewer.s3-website-xx-xxx-xx.amazonaws.com/pdfjs-4.0.379-dist/web/viewer.html?file=docs/xxx.pdf
在这个路径中,docs文件夹位于web文件夹内,专门用来存放pdf文件。
第三步:使用viewer.html
通过iframe嵌入来使用viewer.html,使用方法很简单:
html:
JavaScript:计算url
const url = computed(() => { // 部署pdfjs的服务地址 const aws_server = 'http://xxx-pdf-viewer.s3-website-xx-xxx-xx.amazonaws.com/pdfjs-4.0.379-dist/web/viewer.html' // pdf文件名称 const pdf_name = 'x-trail-0601-20220911.pdf' return `${aws_server}?file=${encodeURIComponent(`docs/${pdf_name}`)}` })这样,就可以访问到docs文件夹下的所有pdf啦。简单吧!
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



