spark dynamicAllocation详解及使用
温馨提示:这篇文章已超过367天没有更新,请注意相关的内容是否还可用!
我们在提交Spark应用时,一般都会指定executor数量,但我们的任务中有大的任务、也会有小的任务。这时候,我们在处理ETL的时候,会有几种选择,例如:分配一个比较大的资源,例如:请求较多的executor,然后在这之上运行作业。另外一种,为了让ETL运行彼此隔离,每个应用都会分配资源。
Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark 应用的 Executor 的数量。在运行过程中,无论 Executor上是否有 task 在执行,都会被一直占有直到此 Spark 应用结束。
在 Spark 集群中的一个常见场景是,随着业务的不断发展,需要运行的 Spark 应用数和数据量越来越大,靠资源堆砌的优化方式也越来越显得捉襟见肘。当一个长期运行的 Spark 应用,若分配给它多个 Executor,可是却没有任何 task 分配到这些 Executor 上,而此时有其他的 Spark 应用却资源紧张,这就造成了资源浪费和调度不合理。
动态资源分配(Dynamic Resource Allocation)就是为了解决这种场景而产生。Spark 2.4 版本中 on Kubernetes 的动态资源并不完善,在 Spark 3.0 版本完善了 Spark on Kubernetes 的功能,其中就包括更灵敏的动态分配。
但大家考虑,一般大一点的数据处理,都会有成千上万个应用需要执行。针对第一种,固定的资源会让集群的资源利用率下降。尽管,我们可以利用YARN的队列来进行资源的管理,同时使用Spark中的Fair公平调度,但YARN也好、FAIR公平调度也好,在task粒度上能做的弹性资源控制是有限的。所以,很多场景,我们非常有必要使用Spark的Dynamic Resource Allcation,也就是动态资源分配。特别是,如果我们需要使用thrift server的时候。
Spark动态资源分配策略
从High Level角度来看,Spark应该在executor不再被使用时释放资源,而在需要executor执行计算时再申请资源。但Spark是没有确定的策略预测是否为接下来要运行的任务保留资源,所以,Spark中提供了一组启发式的方法来确定什么时候释放或者请求executor。
一个 Spark 应用中如果有些 Stage 稍微数据倾斜,那就有大量的 Executor 是空闲状态,造成集群资源的极大浪费。通过动态资源分配策略,已经空闲的 Executor 如果超过了一定时间,就会被集群回收,并在之后的 Stage 需要时可再次请求 Executor。
如下图所示,固定 Executor 个数情况,Job1 End 和 Job2 Start 之间,Executor 处于空闲状态,此时就造成集群资源的浪费。
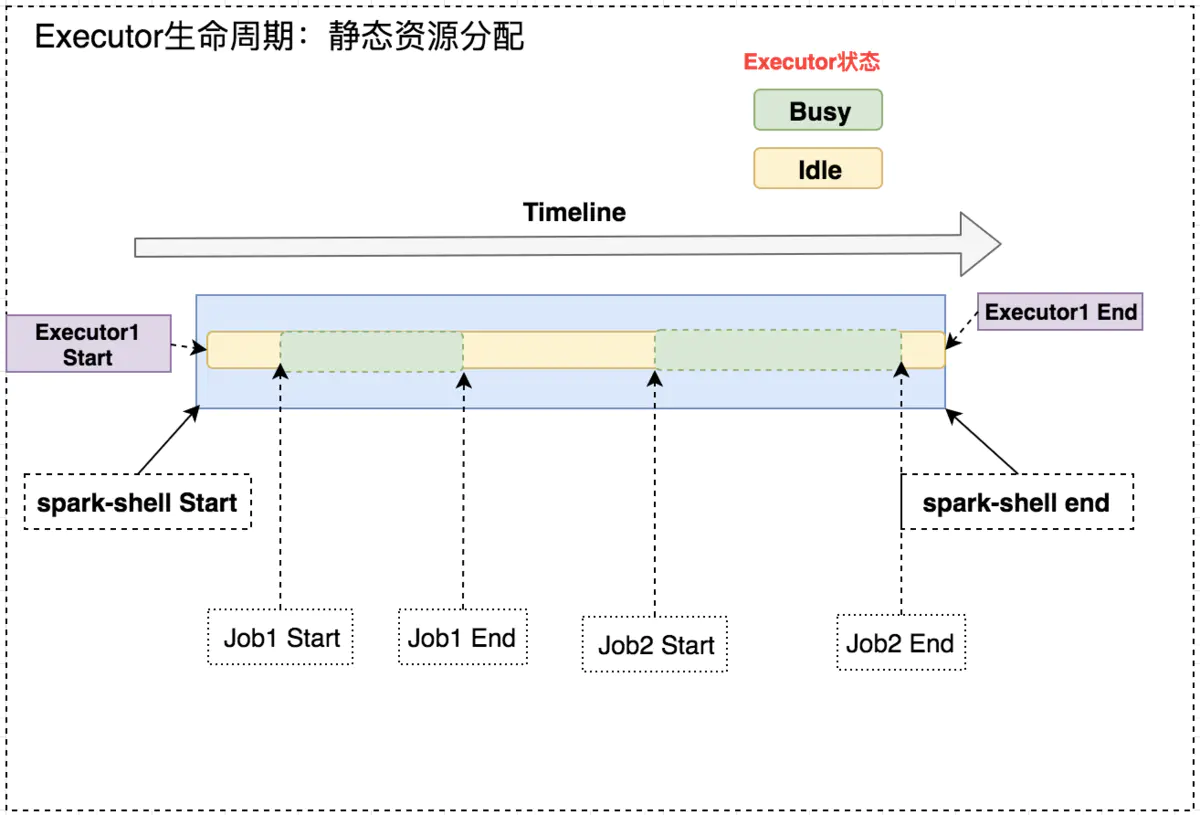
开启动态资源分配后,在 Job1 结束后,Executor1 空闲一段时间便被回收;在 Job2 需要资源时再申Executor2,实现集群资源的动态管理。
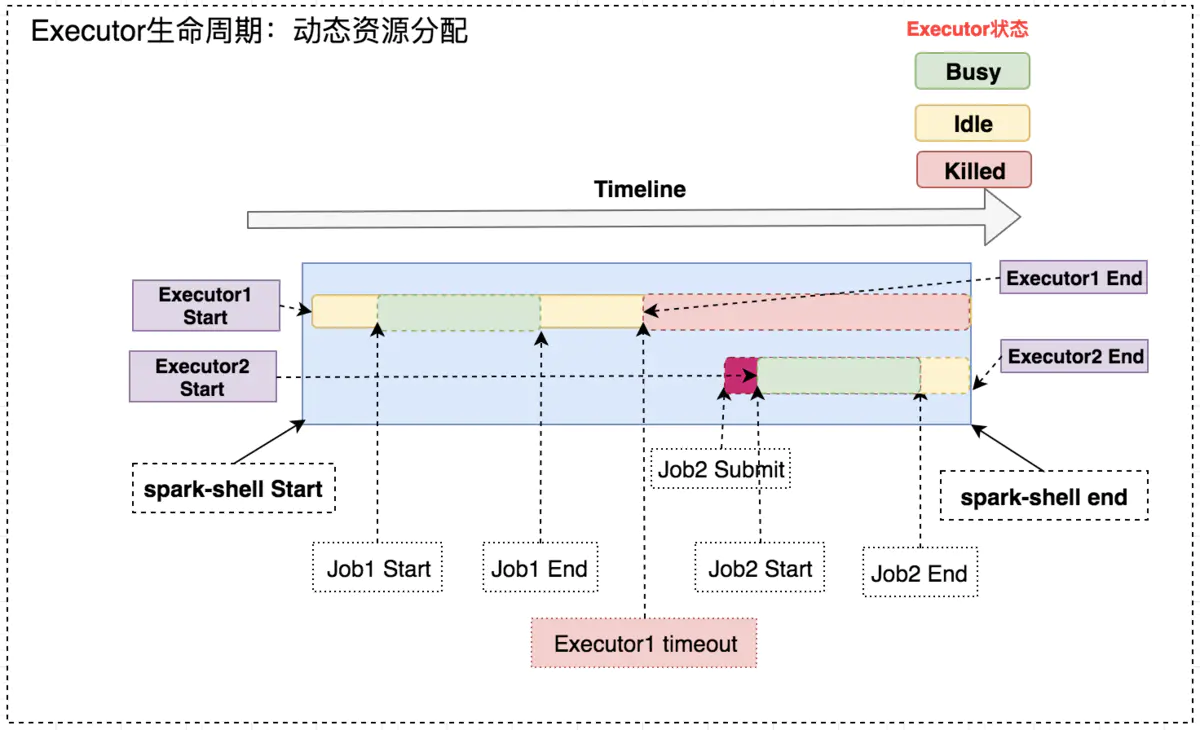
动态分配的原理很容易理解:“按需使用”。当然,一些细节还是需要考虑到:
- 何时新增/移除 Executor
- Executor 数量的动态调整范围
- Executor 的增减频率
- Spark on Kubernetes 场景下,Executor 的 Pod 销毁后,它存储的中间计算数据如何访问
这些注意点在下面的参数列表中都有相应的说明。
参数一览
spark.dynamicAllocation.enabled=true #总开关,是否开启动态资源配置,根据工作负载来衡量是否应该增加或减少executor,默认false spark.dynamicAllocation.shuffleTracking.enabled=true #spark3新增,之前没有官方支持的on k8s的Dynamic Resouce Allocation。启用shuffle文件跟踪,此配置不会回收保存了shuffle数据的executor spark.dynamicAllocation.shuffleTracking.timeout #启用shuffleTracking时控制保存shuffle数据的executor超时时间,默认使用GC垃圾回收控制释放。如果有时候GC不及时,配置此参数后,即使executor上存在shuffle数据,也会被回收。暂未配置 spark.dynamicAllocation.minExecutors=1 #动态分配最小executor个数,在启动时就申请好的,默认0 spark.dynamicAllocation.maxExecutors=10 #动态分配最大executor个数,默认infinity spark.dynamicAllocation.initialExecutors=2 #动态分配初始executor个数默认值=spark.dynamicAllocation.minExecutors spark.dynamicAllocation.executorIdleTimeout=60s #当某个executor空闲超过这个设定值,就会被kill,默认60s spark.dynamicAllocation.cachedExecutorIdleTimeout=240s #当某个缓存数据的executor空闲时间超过这个设定值,就会被kill,默认infinity spark.dynamicAllocation.schedulerBacklogTimeout=3s #任务队列非空,资源不够,申请executor的时间间隔,默认1s(第一次申请) spark.dynamicAllocation.sustainedSchedulerBacklogTimeout #同schedulerBacklogTimeout,是申请了新executor之后继续申请的间隔,默认=schedulerBacklogTimeout(第二次及之后) spark.specution=true #开启推测执行,对长尾task,会在其他executor上启动相同task,先运行结束的作为结果
资源请求策略
启用了动态分配的spark应用,在有待处理的任务时,会请求额外的executor以执行任务。Spark会周期性地请求资源,请求的周期由两个参数决定。
1、首发请求executor
# 默认为1s spark.dynamicAllocation.schedulerBacklogTimeout(单位为秒)
2、周期性请求executor
# 与schedulerBacklogTimeout一致(1秒) spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(单位为秒)
如果任务请求队列中仍然有Pending的任务,那么每隔一段时间会再次触发executor资源请求。并且每一轮请求的executor数量会呈指数增长(2的n次方)。例如:1、2、4、8。
资源释放策略
如果executor闲置时间超过以下参数,则spark应用将会释放该executor。
# 默认60秒 spark.dynamicAllocation.executorIdleTimeout(单位为秒)
Executor优雅退役
Shuffle输出重算问题
在没有开启Dynamic Allocation时,如果执行失败、或者与其关联的JOB退出时结束Spark应用。这两种情况下,所有与之关联的状态将会安全的被丢弃。但如果开启了Dynamic Allocation,会存在Spark应用仍在运行,但executor被显式地释放的情况。例如:某个任务执行比较慢,而其他的任务执行比较快,那么这些任务对应的executor会被释放。
此时,如果应用程序尝试访问存储在executor中的状态,就会导致之前已经SUCCESS的任务需要重新计算。所以,需要在退役executor之前,保存其状态来优雅退役executor,释放资源。这项操作对于有shuffle的应用尤其重要。在shuffle期间,Spark executor先要将map的输出写入到磁盘,然后该executor充当一个文件服务器,将这些文件共享给其他的executor访问。所以,如果开启Dynamic Allocation时,不能继续把Shuffle的状态保存在executor中,要让shuffle的输出保留,供其他的executor读取。
优雅退役
从Spark 1.2开始,引入了外部shuffle服务。该服务是一个长期运行的守护进程,shuffle service独立于运行在各节点的Spark应用、以及executor。如果启用了该服务,Spark executor将从shuffle service拉取shuffle输出文件,而不再从executor中拉取shuffle输出。这就意味着,executor的shuffle输出都可以在executor生命周期结束后,继续提供shuffle数据。
executor cache重算问题
除了shuffle,executor中还有可能将数据缓存在磁盘或者内存中,而executor一旦退出,这些cache将不再能够访问。这些cache存储的时长由以下参数决定:
# 默认为infinity,永远不删除 spark.dynamicAllocation.cachedExecutorIdleTimeout(单位为秒)
Spark任务调度策略
FAIR调度
在SparkContext中,如果多个并行的JOB,任务是可以同时运行的。默认情况下,Spark调度程序是以FIFO方式运行JOB的,每个作业分为多个Stage,第一个作业可以在所有可用资源上申请资源,而第二个作业继续申请资源,以此类推。这种情况,如果前面的作业比较大,就可能导致后面的JOB有较大的延迟。
从Spark 0.8开始,可以配置作业调度策略为Fair,及公平调度。Spark会以循环的方式在作业间调度,以便所有的作业获得大致相等的集群资源。所以,即使在运行长作业时,短作业也可以迅速执行。无需等待长作业执行。这种模式比较适合于多用户提交作业情况。
# 默认为FIFO,可以配置为:FAIR spark.scheduler.mode
FAIR Scheduler Pool
FAIR调度支持将作业进行分组,分组到不同的POOL中,并且为每个POOL设置不同的选项、参数。例如:权重。类似于YARN的Fair scheduler。默认,所有新提交的作业都会提交到default pool,可以通过:
sc.setLocalProperty("spark.scheduler.pool", "pool1")来设置作业池。并对资源池进行配置:
conf.set("spark.scheduler.allocation.file", "/path/to/file")配置文件如下:
FAIR 1 2 FIFO 2 3Spark的安装目录中有一个fairscheduler.xml.template配置供参考。
JDBC client使用以下方式设置:
SET spark.sql.thriftserver.scheduler.pool=accounting;
配置
Shuffle service配置
找到spark shuffle service jar包
[root@hadoop1 ~]# su yarn [yarn@hadoop1 root]$ ll /opt/spark/yarn total 10704 -rw-r--r-- 1 spark hadoop 10959536 Mar 11 11:02 spark-3.1.1-yarn-shuffle.jar
每个NodeManager节点将jar包添加到Hadoop
ssh hadoop1 "ln -s /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar /opt/hadoop/share/hadoop/yarn/lib/" ; \ ssh hadoop2 "ln -s /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar /opt/hadoop/share/hadoop/yarn/lib/" ; \ ssh hadoop3 "ln -s /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar /opt/hadoop/share/hadoop/yarn/lib/" ; \ ssh hadoop4 "ln -s /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar /opt/hadoop/share/hadoop/yarn/lib/" ; \ ssh hadoop5 "ln -s /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar /opt/hadoop/share/hadoop/yarn/lib/" ; \ ssh hadoop6 "ln -s /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar /opt/hadoop/share/hadoop/yarn/lib/" ; \ ssh hadoop7 "ln -s /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar /opt/hadoop/share/hadoop/yarn/lib/" ; \ ssh hadoop8 "ln -s /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar /opt/hadoop/share/hadoop/yarn/lib/" ; \ ssh hadoop9 "ln -s /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar /opt/hadoop/share/hadoop/yarn/lib/" # [yarn@hadoop1 root]$ ll /opt/hadoop/share/hadoop/yarn/lib/ | grep spark # lrwxrwxrwx 1 yarn hadoop 44 Apr 8 09:26 spark-3.1.1-yarn-shuffle.jar -> /opt/spark/yarn/spark-3.1.1-yarn-shuffle.jar
修改yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle,spark_shuffle yarn.nodemanager.aux-services.spark_shuffle.class org.apache.spark.network.yarn.YarnShuffleService分发yarn-site.xml
scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop2:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop3:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop4:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop5:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop6:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop7:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop8:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop9:/opt/hadoop/etc/hadoop/
重新启动所有NodeManager
stop-yarn.sh start-yarn.sh netstat -nltp | grep 7337 # spark.shuffle.service.port=7337 # [yarn@hadoop1 root]$ netstat -nltp | grep 7337 # (Not all processes could be identified, non-owned process info # will not be shown, you would have to be root to see it all.) # tcp 0 0 0.0.0.0:7337 0.0.0.0:* LISTEN 13929/java
Dynamic Allocation配置
spark.dynamicAllocation.enabled=true spark.shuffle.service.enabled=true spark.dynamicAllocation.minExecutors=2 spark.dynamicAllocation.maxExecutors=200 spark.dynamicAllocation.initialExecutors=2 spark.dynamicAllocation.executorAllocationRatio=1 spark.dynamicAllocation.executorIdleTimeout=60s spark.dynamicAllocation.schedulerBacklogTimeout=1s spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=1s spark.dynamicAllocation.shuffleTracking.enabled=false
scheduler配置
spark.scheduler.mode=FAIR
spark sql优化
# 最大分区为256M spark.sql.files.maxPartitionBytes=268435456 # 广播阈值(100MB) spark.sql.autoBroadcastJoinThreshold=104857600
CBO(基于成本优化)配置
针对大的JOIN操作,可以开启CBO来优化Spark。
spark.sql.cbo.enabled=true # 从catalog中获取行列统计信息 spark.sql.cbo.planStats.enabled=true
动态分区
spark.sql.adaptive.coalescePartitions.enabled=true spark.sql.adaptive.coalescePartitions.initialPartitionNum=50 spark.sql.adaptive.advisoryPartitionSizeInBytes=268435456
数据倾斜优化
spark.sql.adaptive.skewJoin.enabled=true spark.sql.adaptive.skewJoin.skewedPartitionFactor=5 # 256M spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes=268435456
测试集群配置
yarn-site.xml
yarn.scheduler.maximum-allocation-mb 10240 yarn.scheduler.maximum-allocation-vcores 8分发到所有节点:
scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop2:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop3:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop4:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop5:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop6:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop7:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop8:/opt/hadoop/etc/hadoop/; \ scp /opt/hadoop/etc/hadoop/yarn-site.xml hadoop9:/opt/hadoop/etc/hadoop/
spark-defaults.conf
# vim /opt/spark/conf/spark-defaults.conf spark.driver.cores 1 spark.driver.memory 4096m spark.executor.memory 8192m spark.executor.cores 4 spark.task.cpus 1 spark.default.parallelism 50 # Dynamic allocation spark.dynamicAllocation.enabled true spark.shuffle.service.enabled true spark.dynamicAllocation.minExecutors 1 spark.dynamicAllocation.maxExecutors 200 spark.dynamicAllocation.initialExecutors 1 # spark.dynamicAllocation.executorAllocationRatio 1 # spark.dynamicAllocation.executorIdleTimeout 60s # spark.dynamicAllocation.schedulerBacklogTimeout 1s # spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 1s # spark.dynamicAllocation.shuffleTracking.enabled false # scheduler spark.scheduler.mode FAIR spark.scheduler.allocation.file /opt/spark/conf/fairscheduler.xml # spark sql spark.sql.shuffle.partitions 50 spark.sql.files.maxPartitionBytes 268435456 spark.sql.autoBroadcastJoinThreshold 104857600 # cbo spark.sql.cbo.enabled true spark.sql.cbo.planStats.enabled true # adaptive partition # spark.sql.adaptive.coalescePartitions.enabled true spark.sql.adaptive.coalescePartitions.initialPartitionNum 50 spark.sql.adaptive.advisoryPartitionSizeInBytes 268435456 # skew data # spark.sql.adaptive.skewJoin.enabled true # spark.sql.adaptive.skewJoin.skewedPartitionFactor 5 # spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 268435456
配置fairscheduler.xml
cp /opt/spark/conf/fairscheduler.xml.template /opt/spark/conf/fairscheduler.xml vim /opt/spark/conf/fairscheduler.xml FAIR 1 0分发:
scp /opt/spark/conf/spark-defaults.conf /opt/spark/conf/fairscheduler.xml hadoop2:/opt/spark/conf/; \ scp /opt/spark/conf/spark-defaults.conf /opt/spark/conf/fairscheduler.xml hadoop3:/opt/spark/conf/; \ scp /opt/spark/conf/spark-defaults.conf /opt/spark/conf/fairscheduler.xml hadoop4:/opt/spark/conf/; \ scp /opt/spark/conf/spark-defaults.conf /opt/spark/conf/fairscheduler.xml hadoop5:/opt/spark/conf/; \ scp /opt/spark/conf/spark-defaults.conf /opt/spark/conf/fairscheduler.xml hadoop6:/opt/spark/conf/; \ scp /opt/spark/conf/spark-defaults.conf /opt/spark/conf/fairscheduler.xml hadoop7:/opt/spark/conf/; \ scp /opt/spark/conf/spark-defaults.conf /opt/spark/conf/fairscheduler.xml hadoop8:/opt/spark/conf/; \ scp /opt/spark/conf/spark-defaults.conf /opt/spark/conf/fairscheduler.xml hadoop9:/opt/spark/conf/
实战演示
配置参数
动态资源分配相关参数配置如下图所示:
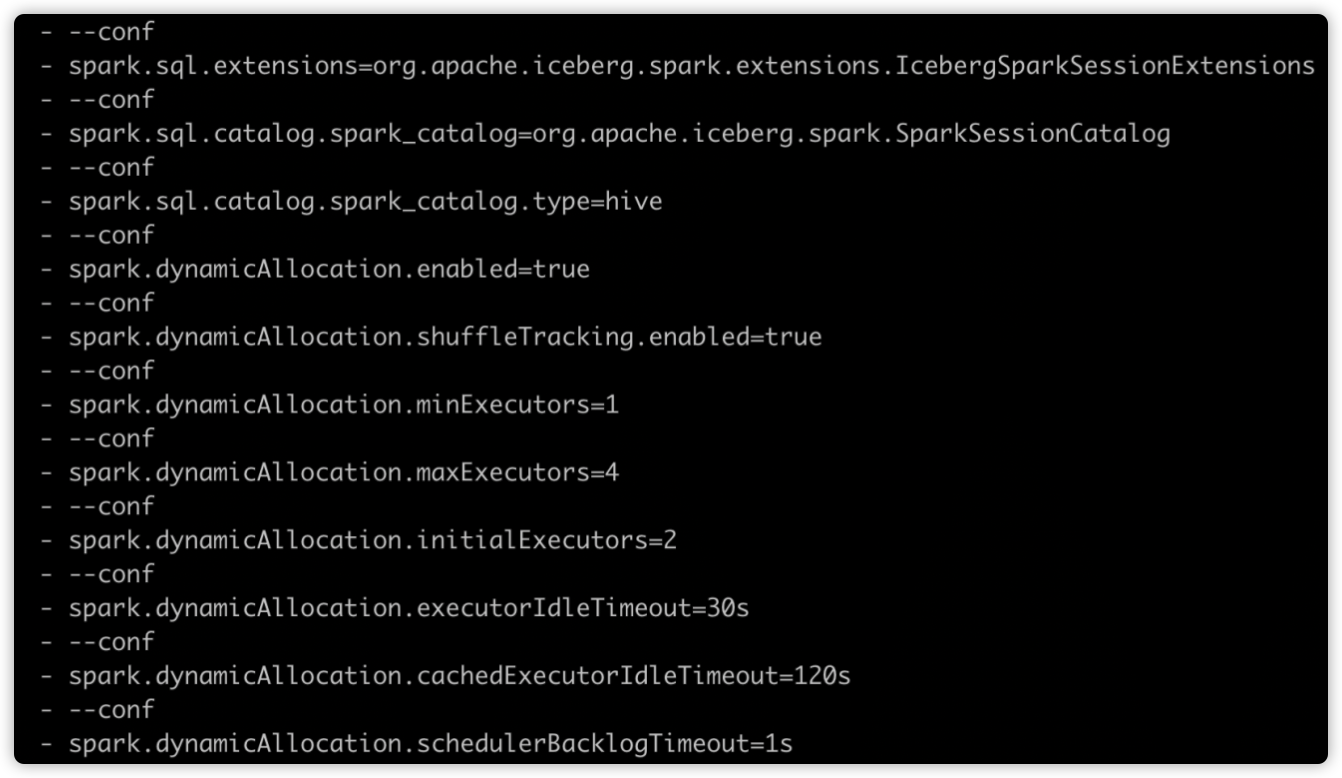
如下图所示,Spark 应用启动时的 Executor 个数为 2。因为配置了
spark.dynamicAllocation.initialExecutors=2
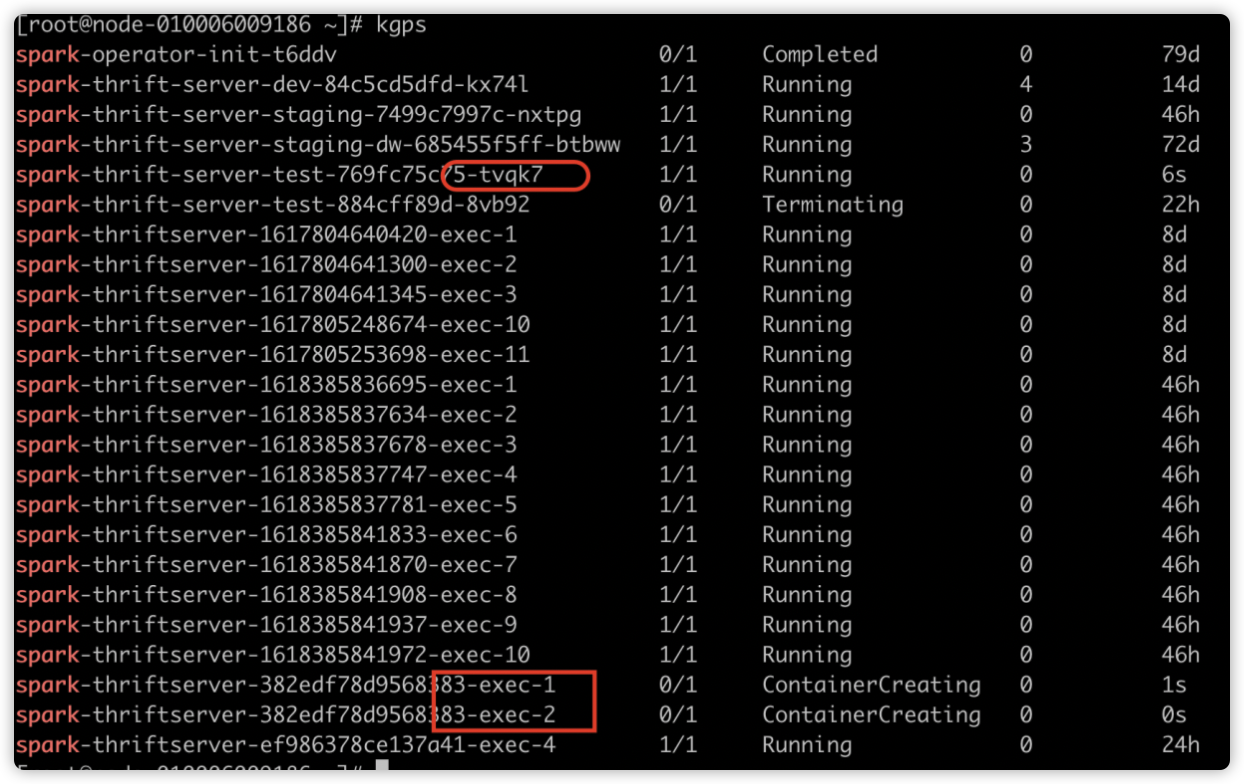
运行一段时间后效果如下,executorNum 会递增,因为空闲的 Executor 被不断回收,新的 Executor 不断申请。
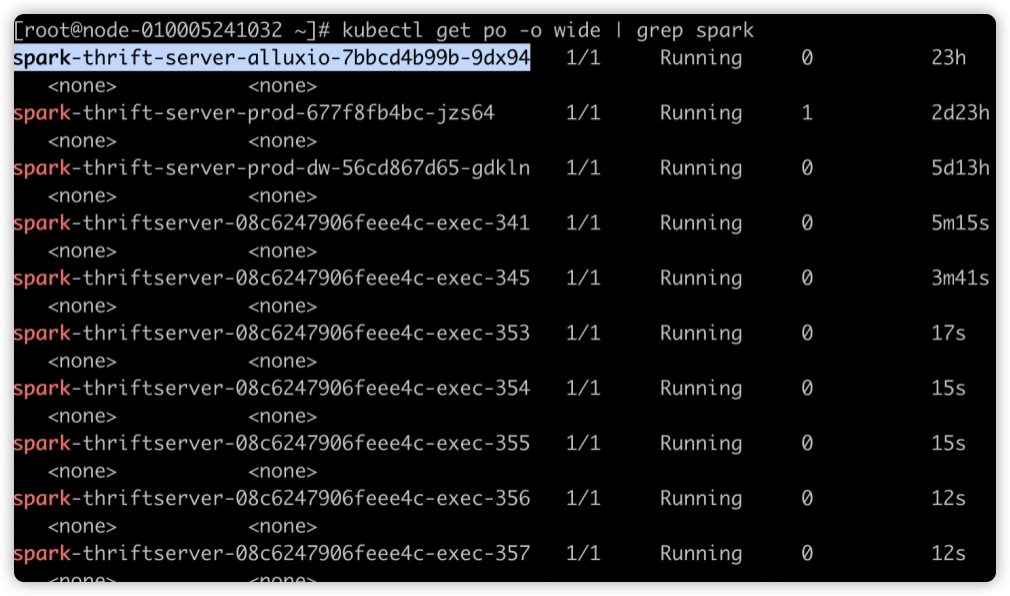
验证快慢 SQL 执行
使用 SparkThrfitServer 会遇到的问题是一个数据量很大的 SQL 把所有的资源全占了,导致后面的 SQL 都等待,即使后面的 SQL 只需要几秒就能完成。我们开启动态分配策略,再来看 SQL 执行顺序。
先提交慢 SQL:
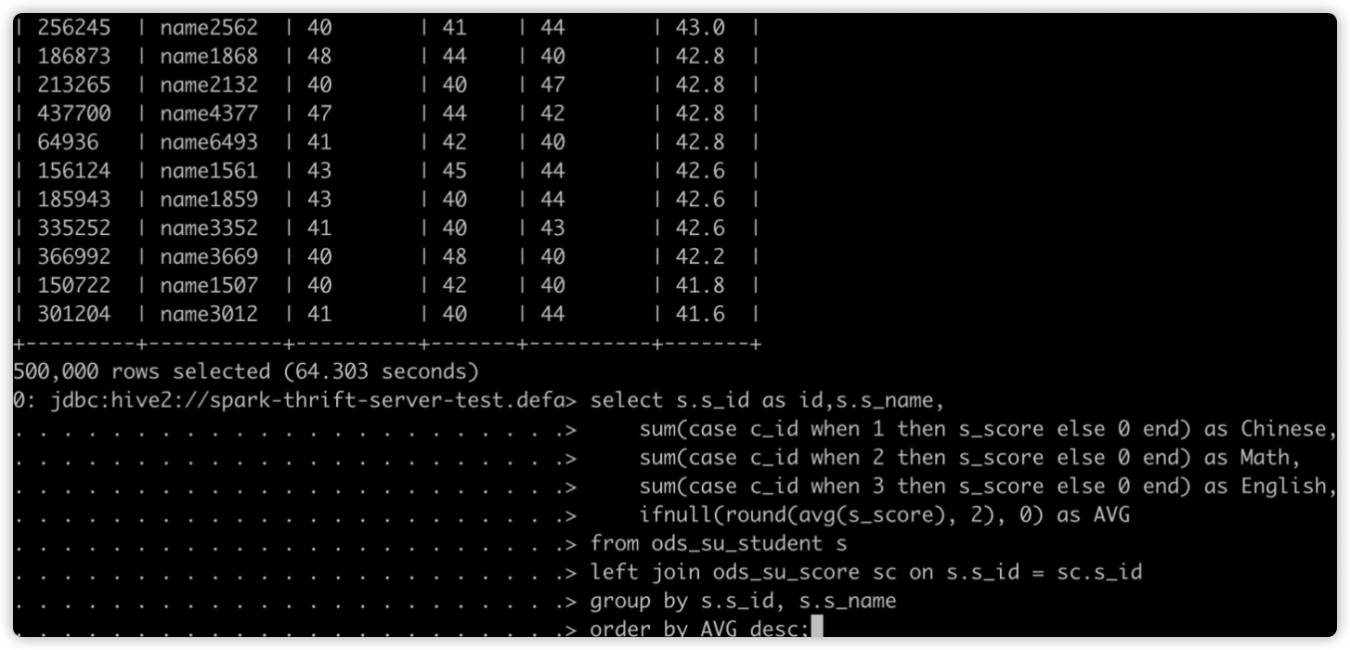
再提交快 SQL:
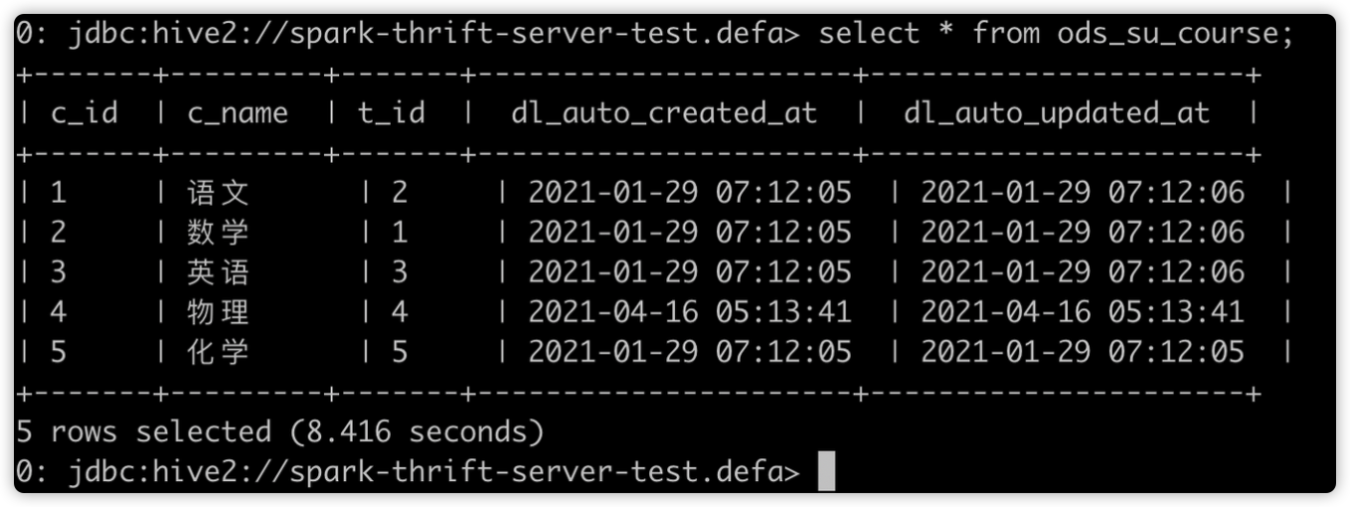
如下图所示,开启动态资源分配后,因为 SparkThrfitServer 可以申请新的 Executor,后面的 SQL 无需等待便可执行。Job7(慢 SQL)还在运行中,后提交的 Job8(快 SQL)已完成。这在一定程度上缓解了资源分配不合理的情况。
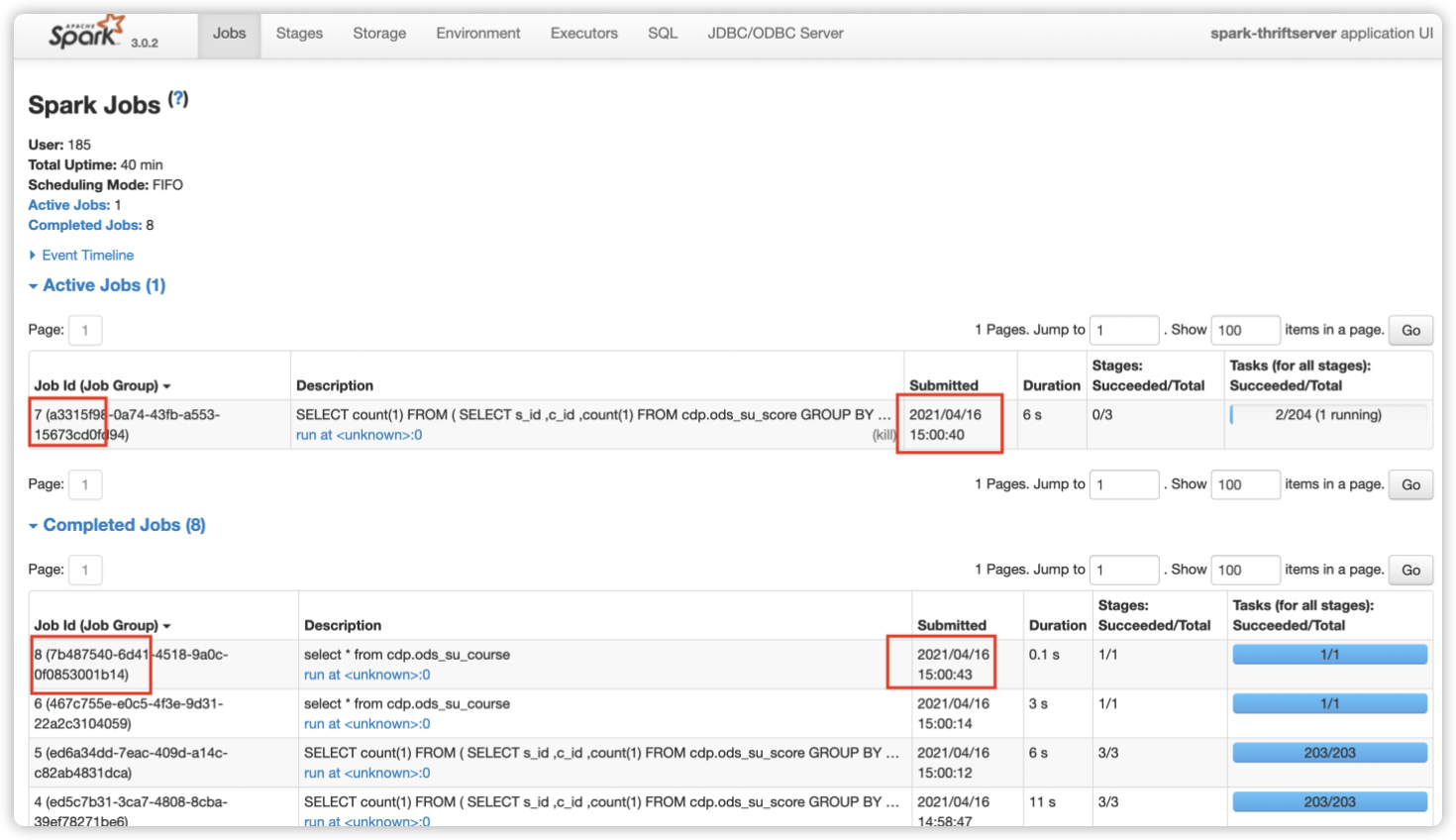
详情查看
我们在 SparkWebUI 上可以看到动态分配的整个流程。
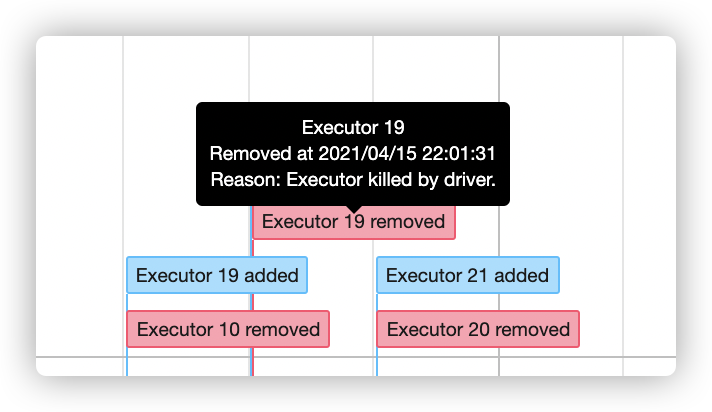
登陆 SparkWebUI 页面,Jobs -> Event Timeline,可以看到 Driver 对整个应用的 Executor 调度。如下图所示,显示了每个 Executor 的创建和回收。

同时也能看到此 Executor 的具体创建和回收时间。
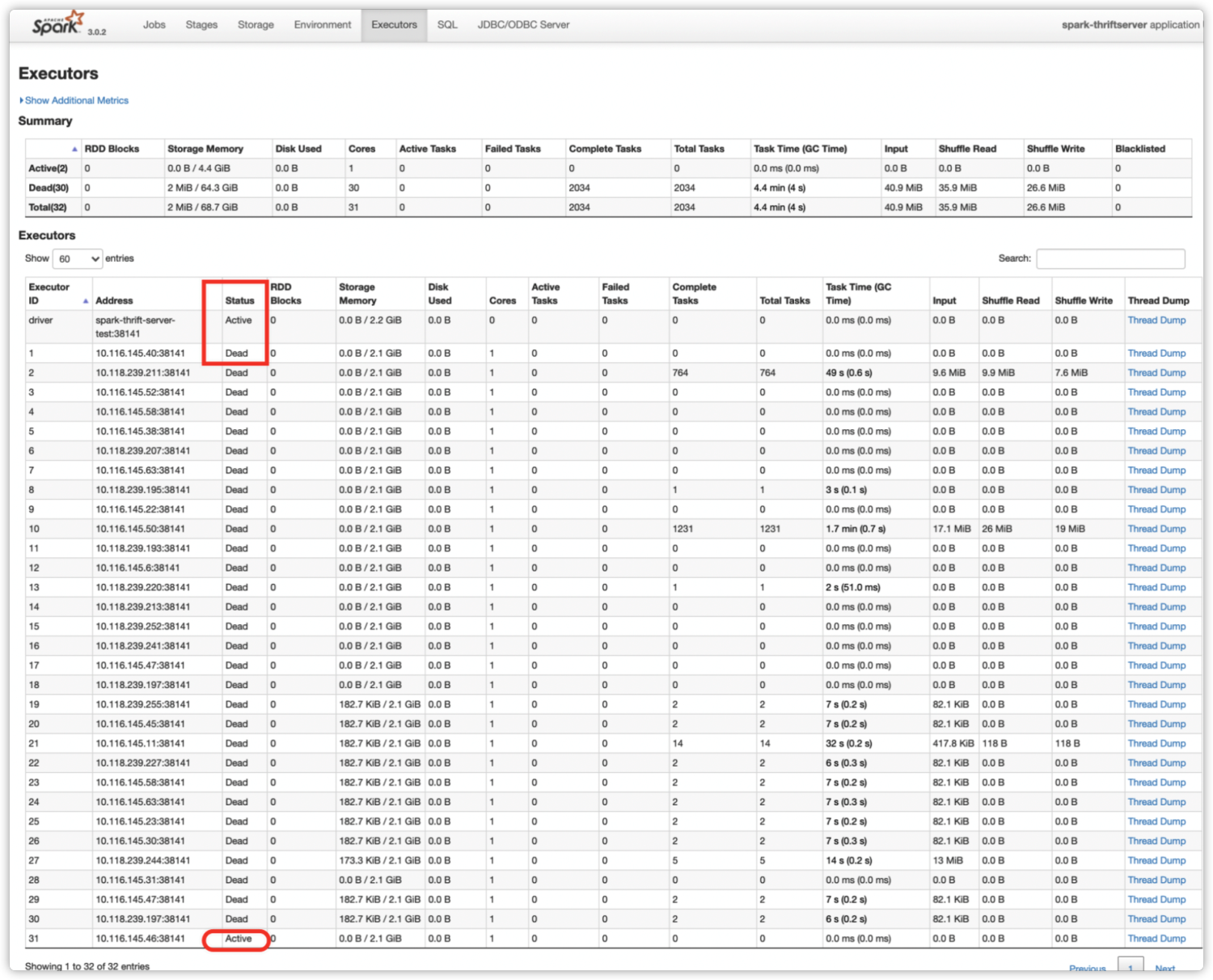
在 Executors 标签页,我们可以看到所有历史 Executor 的当前状态。如下图所示,之前的 Executor 都已被回收,只有 Executor-31 状态为 Active。
总结
动态资源分配策略在空闲时释放 Executor,繁忙时申请 Executor,虽然逻辑比较简单,但是和任务调度密切相关。它可以防止小数据申请大资源,Executor 空转的情况。在集群资源紧张,有多个 Spark 应用的场景下,可以开启动态分配达到资源按需使用的效果。
aws EMR
经调研,EMR 在 4.4.0 之后的版本就默认开启了 dynamic allocation[1],Spark shuffle service 也是由 EMR 自动配置,EMR 是通过 spark-defaults.conf 来默认开启。
参考:
[1] Amazon EMR 设置的 Spark 默认值 -https://docs.aws.amazon.com/zh_cn/emr/latest/ReleaseGuide/emr-spark-configure.html#spark-defaults
Running Spark on YARN - Spark 3.4.1 Documentation
Job Scheduling - Spark 3.4.1 Documentation
1.1. 关键配置
在 /etc/spark/conf 目录下的 spark-defaults.conf 中看到以下配置
spark.dynamicAllocation.enabled true spark.shuffle.service.enabled true
1.2. YARN 配置
当前 EMR Spark 仅支持 master 为 YARN,故 EMR 会在每个 NodeManager 中启动 shuffle service,可以在 /etc/hadoop/conf/yarn-site.xml 中观察到 EMR 默认己完成 YarnShuffleService 配置。
yarn.nodemanager.aux-services mapreduce_shuffle,spark_shuffle, yarn.nodemanager.aux-services.mapreduce_shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.nodemanager.aux-services.spark_shuffle.class org.apache.spark.network.yarn.YarnShuffleServiceYARN env 配置
/etc/hadoop/conf/yarn-env.sh
export HADOOP_CLASSPATH="$HADOOP_CLASSPATH:/usr/lib/spark/yarn/lib/spark-yarn-shuffle.jar"
动态分配功能测试
集群中执行 spark-submit 命令
spark-submit \ --master yarn \ --deploy-mode client \ --class org.apache.spark.examples.SparkPi \ /usr/lib/spark/examples/jars/spark-examples.jar 10
可以在 executor stderr 日志中观察到 Spark 使用 7337 做为 shuffle service port,并将 executor 注册进去。
23/08/16 06:36:59 INFO BlockManager: external shuffle service port = 7337
23/08/16 06:36:59 INFO BlockManager: Registering executor with local external shuffle service.
综上所述,EMR 默认开启 dynamic allocation,您只要依业务需求调整 initialExecutors、maxExecutors、minExecutors 等跟 dynamic allocation 相关的配置即可。
腾讯EMR
开启aqe执行在EMR3.4版本操作步骤如下:
1. 修改&增加yarn的配置:
- 修改配置项 yarn.nodemanager.aux-services,添加 spark_shuffle。
- 增加:yarn.nodemanager.aux-services.spark_shuffle.class = org.apache.spark.network.yarn.YarnShuffleService
- 增加:spark.yarn.shuffle.stopOnFailure = false
YARN界面化配置yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle,spark_shuffle, yarn.nodemanager.aux-services.mapreduce_shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.nodemanager.aux-services.spark_shuffle.class org.apache.spark.network.yarn.YarnShuffleService修改spark的配置:
spark.yarn.shuffle.stopOnFailure = false spark.dynamicAllocation.enabled= true spark.shuffle.service.enabled=true
可以忽略spark-*-shuffle-jar包版本的问题
可以忽略spark-*-shuffle-jar包版本的问题
参考文档:
弹性 MapReduce Spark 资源动态调度实践-EMR 开发指南-文档中心-腾讯云
shuffleTracking特性
开启shuffleTracking特性,也可以支持dynamic allocation,可以无需开启spark yarn shuffle.service 。