
论文阅读《Addressing Confounding Feature Issue for Causal Recommendation》
温馨提示:这篇文章已超过379天没有更新,请注意相关的内容是否还可用!
目录
- Addressing Confounding Feature Issue for Causal Recommendation
- 1. Abstract
- 2. Method
- 2.1 Causal View of Confounding Feature
- 2.2 Deconfounding Causal Recommendation(DCR)
- 2.2.1 Causal Intervention
- 2.2.2 Estimating P ( Y ∣ U , d o ( X ) ) P(Y|U,do(X)) P(Y∣U,do(X))
- 2.3 Mixture-of-Experts Model Architecture(MoE)
- 2.4 Generality of DCR
- Experiments
Addressing Confounding Feature Issue for Causal Recommendation
该文章由中科大的何向南教授发表在TOIS 2022(ccf A类)上。是我目前读过的因果推断推荐相关的文章中细节描述最为详细并且原理介绍详略得当、解释的最合理的一篇文章。如果大家有兴趣的话非常推荐大家进行研读。
1. Abstract
在推荐系统中,有一些特性会直接影响交互是否发生,这也会导致交互行为并不一定能代表用户的喜好。本文主要针对的是”在视频推荐中,短视频是更容易被完成(代表了一次交互),但实际可能用户并不喜欢这个视频“ 这样的问题。作者认为视频的长度就是视频推荐中的一个混淆因素,而现有的推荐模型都是在用户的交互数据进行模型训练,这会导致最终的模型更加偏向短视频,偏离了用户的实际需求。
为此,作者从因果关系的角度出发,阐述并解决了这个问题。提出了Deconfounding Causal Recommendation(DCR)框架。采用do算子切断虚假关联,并通过后面调整计算实际的因果关系。同时设计了混合专家(MoE)模型架构,用一个单独的专家模块对每个混淆特征的值进行建模,解决了效率问题。并最后在NFM主干模型上应用DCR框架进行了一系列实验。
2. Method
2.1 Causal View of Confounding Feature
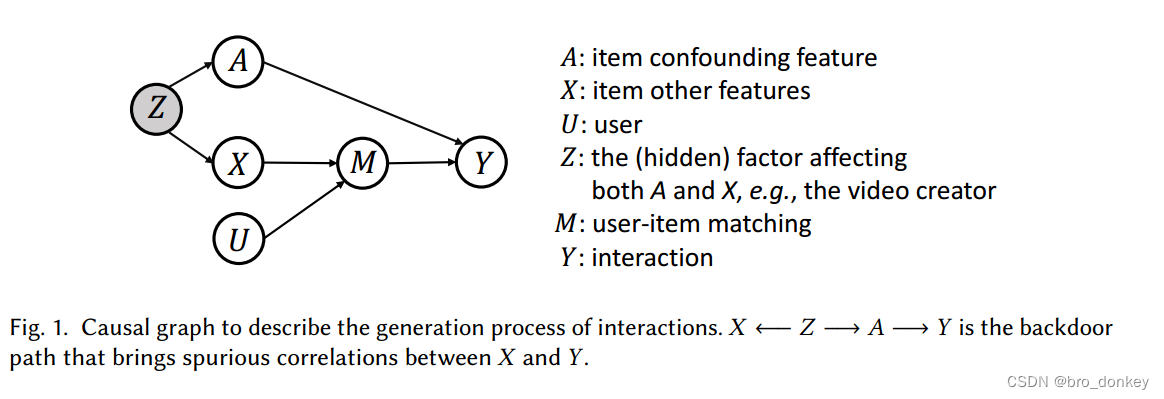
- U:用户特征,例如userID
- A:已知的物品的混淆特征,例如视频长度
- X:物品的其他特征(内容特征),主要指的是能够反映用户偏好的特征,例如itemID
- Z:同时影响A和X的隐藏因素,这部分因素是由物品的生产引起的,但是不能观察到。例如视频创作者的意图
- M:user-item匹配对,这个主要是用来反映物品特征和用户偏好的匹配程度
- Y:交互标签。表示是否发生交互行为(播放完毕或者点击)
- { X , U } → M \{X,U\} \to M {X,U}→M:表示user-item匹配对是由用户特征X和物品的内容特征U决定的。
- { A , M } → Y \{A,M\} \to Y {A,M}→Y:表示交互行为是由user-item匹配程度以及混淆特征共同决定的。 A → Y A \to Y A→Y对应的是混淆特征影响交互概率,但是不能够反映用户的真实偏好。
- A ← Z → X A \gets Z \to X A←Z→X:表示隐藏因素Z同时影响混淆特征A和物品内容特征X。例如婚礼视频制作者会制作相对较长(A)的视频同时选择感人的背景音乐(X)
-
X
←
Z
→
A
→
Y
X \gets Z \to A \to Y
X←Z→A→Y:这是一个后门路径,为X和Y带来了虚假的关联。
现有的方法通常通过在历史交互中计算 P ( Y ∣ U , X , A ) P(Y|U,X,A) P(Y∣U,X,A) 或 P ( Y ∣ U , X ) P(Y|U,X) P(Y∣U,X)的值来学习排序函数,得到最终的排序结果。但是这两个的值都存在着弊端。
- P ( Y ∣ U , X , A ) P(Y|U,X,A) P(Y∣U,X,A) :该值计算包含了 A → Y A \to Y A→Y,A对Y的直接影响,这会导致预测更加偏向于混淆变量。
-
P
(
Y
∣
U
,
X
)
P(Y|U,X)
P(Y∣U,X):由于存在着后门路径,这样的方法计算会忽视A对Y的影响,这导致模型会学习到X和Y之间虚假关联。
2.2 Deconfounding Causal Recommendation(DCR)
该框架主要是为了学习到X对Y的因果效应
2.2.1 Causal Intervention
X对Y的因果效应定义:将X的参考值改变为目标值后,Y的变化。
在现实生活中通常是进行随机对照实验来计算因果效应(比如说经典的吃药还是不吃药试例),然而这样的实验在推荐中是代价特别昂贵的,并且对于混淆特征问题的应用并不实际。因此通常都是进行因果干预来计算X对Y的因果效应,具体的来说,通常都是经过do算子来切断后门路径中的虚假关联,并使用后门调整来计算。公式如下:
P ( Y ∣ U , d o ( X ) ) = ∑ a ∈ A P ( Y ∣ U , X , A = a ) P ( A = a ) (1) P(Y|U,do(X)) = \sum_{a \in \mathcal{A}}{P(Y|U,X,A=a)P(A=a)}\tag{1} P(Y∣U,do(X))=a∈A∑P(Y∣U,X,A=a)P(A=a)(1)
我们直接认为 P ( Y ∣ U , d o ( X = x ) ) P(Y|U,do(X = x)) P(Y∣U,do(X=x))作为X对Y的因果效应。(参考值 P ( Y ∣ U , d o ( X = x ∗ ) ) P(Y|U,do(X = x^*)) P(Y∣U,do(X=x∗))对于所有item是相同的,且P(A)是不变的)
同时因为Z是一个无法观察到的隐藏混淆因素,计算 P ( Y ∣ U , d o ( X ) ) = ∑ z ∈ Z P ( Y ∣ U , X , Z = z ) P ( Z = z ) P(Y|U,do(X)) = \sum_{z \in \mathcal{Z}}{P(Y|U,X,Z=z)P(Z=z)} P(Y∣U,do(X))=∑z∈ZP(Y∣U,X,Z=z)P(Z=z)是不切实际的。
2.2.2 Estimating P ( Y ∣ U , d o ( X ) ) P(Y|U,do(X)) P(Y∣U,do(X))
- 计算
P
(
A
)
P(A)
P(A):在本文中涉及到的混合特征A只有一个,但是它的值是K个。并且K远小于数据集
D
\mathcal{D}
D的大小。
P ( A = a ) = ∣ { U , X , A , Y } ∣ A = a ∣ ∣ D ∣ (2) P(A=a) = \frac{|\{U,X,A,Y\}| A = a|}{|\mathcal{D}|}\tag{2} P(A=a)=∣D∣∣{U,X,A,Y}∣A=a∣(2)
- 计算
P
(
Y
∣
U
,
X
,
A
)
P(Y|U,X,A)
P(Y∣U,X,A):由于推荐中的数据稀疏性,从D中直接观察到所有概率是不可行的,因此采用机器学习的方法来学习该分布。可以通过任何的特征感知推荐模型(如FM或者NFM)来实现映射函数f(u,x,a)。
对于给定的 U = u , X = x , A = a U=u,X=x,A=a U=u,X=x,A=a,通过以下公式3来进行计算最小化负对数似然来计算 f ( u , x , a ) f(u,x,a) f(u,x,a),即交互概率(Y=1)。 min ∑ ( u , x , a , y ) ∈ D − y log ( f ( u , x , a ) ) − ( 1 − y ) log ( 1 − f ( u , x , a ) ) (3) \min{\sum_{(u,x,a,y) \in \mathcal{D}} -y\log{(f(u,x,a))} - (1-y)\log{(1-f(u,x,a))}} \tag{3} min(u,x,a,y)∈D∑−ylog(f(u,x,a))−(1−y)log(1−f(u,x,a))(3)
当 f ( u , x , a ) f(u,x,a) f(u,x,a)和 P ( A ) P(A) P(A)计算完毕之后,就可以通过下式4来计算推荐得分。 P ( y = 1 ∣ U , d o ( X ) ) = ∑ a ∈ A P ( a ) ⋅ f ( u , x , a ) (4) P(y = 1|U,do(X)) = \sum_{a \in \mathcal{A}}{P(a) \cdot f(u,x,a)} \tag{4} P(y=1∣U,do(X))=a∈A∑P(a)⋅f(u,x,a)(4)
2.3 Mixture-of-Experts Model Architecture(MoE)
上述的方法是通过枚举A的值进行累加和计算最终得分,总共进行了K次 f ( u , x , a ) f(u,x,a) f(u,x,a)的计算。显然这会大大增加干预的时间成本。
通常大家都会进行NWGM近似(Normalized Weighted Geometric Mean 归一化加权几何平均)来计算最终得分,但是这样会牺牲精度,尤其是当 f ( ⋅ ) f(\cdot) f(⋅)是非线性的时候。近似公式如下:
P ( y = 1 ∣ u , d o ( x ) ) ≈ f ( u , x , ∑ a ∈ A a ∗ P ( a ) ) (5) P(y=1|u,do(x)) \approx f(u,x,\sum_{a \in \mathcal{A}}{a*P(a)})\tag{5} P(y=1∣u,do(x))≈f(u,x,a∈A∑a∗P(a))(5)
以往的研究都陷入了精度和效率的二择问题中,本文设计了混合专家框架来解决这个问题。该框架只需要计算一次因果效应,同时保留了足够的精度。
实现的关键就在于在一次模型推理中计算出所有的A的值对应的f(u,x,a)。具体地,MoE框架包含了两个部分,如下图所示:
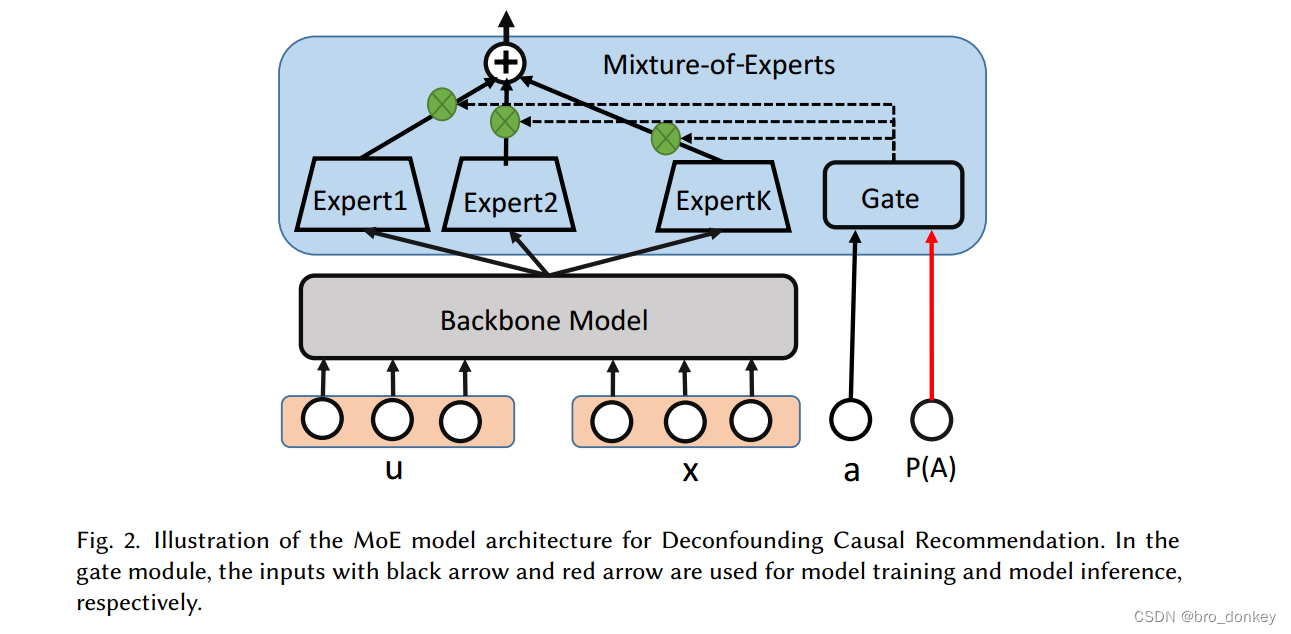
- Backbone Model:目标是学习x和u的匹配对的一个表示。公式如下,其中m是匹配对的潜在表示,
Θ
\Theta
Θ是模型的参数
m = f Θ ( u , x ) (6) m = f_{\Theta}(u,x) \tag{6} m=fΘ(u,x)(6)
- K Experts:每个专家对应混淆变量A的一个值a,将匹配表示m和a映射成交互概率。每个专家模块都是具有两个隐藏层的多层感知机。在形式上如下所示。
其中 ϕ a \phi_a ϕa是a专家对应的参数。在训练阶段是通过a的one-hot编码来为每个训练样本选择专家。而在因果推断阶段,使用P(A)来个每个专家系统分配权重,计算最终的因果效应。
f ( u , x , a ) = f ϕ a ( m ∣ a ) (7) f(u,x,a) = f_{\phi_a}(m|a)\tag{7} f(u,x,a)=fϕa(m∣a)(7)
带有MoE框架的DCR就称之为DCR-MoE,其实现算法可以如下所示。 主要分为训练和推理两个阶段。
在训练阶段是通过a的one-hot编码来为每个训练样本选择专家,并通过最小化公式3的损失函数来进行参数更新。
min ∑ ( u , x , a , y ) ∈ D − y log ( f ( u , x , a ) ) − ( 1 − y ) log ( 1 − f ( u , x , a ) ) (3) \min{\sum_{(u,x,a,y) \in \mathcal{D}} -y\log{(f(u,x,a))} - (1-y)\log{(1-f(u,x,a))}} \tag{3} min(u,x,a,y)∈D∑−ylog(f(u,x,a))−(1−y)log(1−f(u,x,a))(3)
而在因果推断阶段,使用P(A)来个每个专家系统分配权重,计算最终的因果效应。

2.4 Generality of DCR
以上已经介绍了DCR的实现细节,值得一提的是,DCR不仅仅只适用于存在潜在的混淆因素Z的情况,它是解决混淆特性问题
的通用解决方案。作者论证了以下三种情况DCR的可行性。
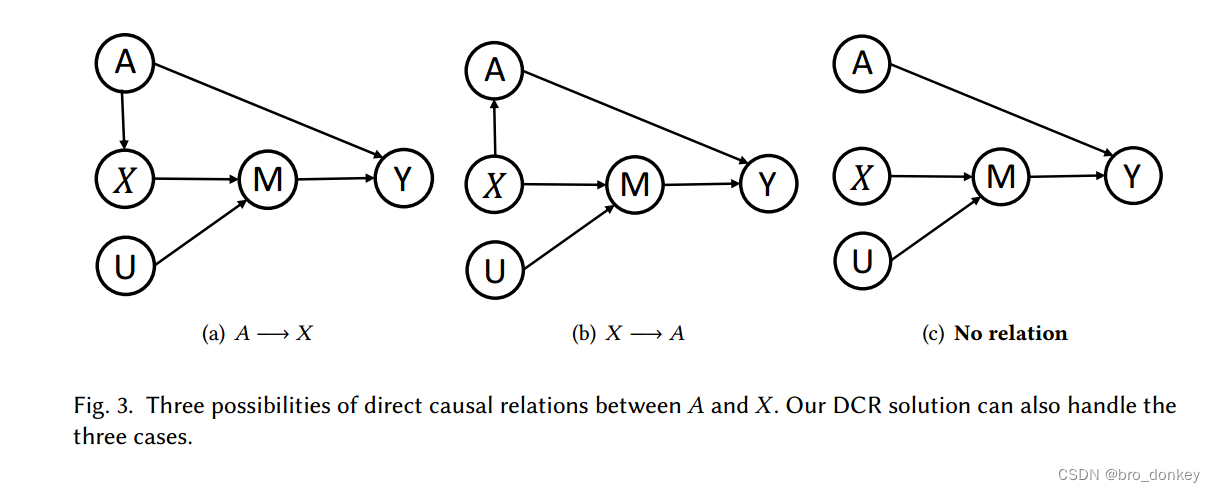
- 情况a:没有潜在混淆变量Z,混淆变量A直接作用与物品内容特征X。这种情况下,与之前讨论的情况其实是一致的。
对于变量x进行的do算子操作之后进行的后门调整计算X对Y的因果效应依然可以用公式1来计算。
P ( Y ∣ U , d o ( X ) ) = ∑ a ∈ A P ( Y ∣ U , X , A = a ) P ( A = a ) (1) P(Y|U,do(X)) = \sum_{a \in \mathcal{A}}{P(Y|U,X,A=a)P(A=a)}\tag{1} P(Y∣U,do(X))=a∈A∑P(Y∣U,X,A=a)P(A=a)(1)
- 情况b:没有潜在混淆变量Z,物品内容特征X作用于混淆变量A。在这种情况下,混淆变量A依然是X对Y的因果效应的中介之一。
此时求X对Y的因果效应,包含了 X → A → Y X \to A \to Y X→A→Y路径和 { X , U } → M → Y \{X,U\} \to M \to Y {X,U}→M→Y两条路径。我们所需要的只是第二条路径上的因果效应。
进行做差计算。 P ( Y ∣ U , X = x , A x ∗ ) − P ( Y ∣ U , X = x ∗ , A x ∗ ) = ∑ a ∈ A ( P ( Y ∣ U , x , a ) − P ( Y ∣ U , x ∗ , a ) ) P ( a ∣ x ∗ ) , (8) \begin{aligned} & P\left(Y | U, X=x, A_{x^{*}}\right)-P\left(Y | U, X=x^{*}, A_{x^{*}}\right) \\ = & \sum_{a \in \mathcal{A}}\left(P(Y | U, x, a)-P\left(Y | U, x^{*}, a\right)\right) P\left(a | x^{*}\right), \end{aligned} \tag{8} =P(Y∣U,X=x,Ax∗)−P(Y∣U,X=x∗,Ax∗)a∈A∑(P(Y∣U,x,a)−P(Y∣U,x∗,a))P(a∣x∗),(8)
由于最终是对计算得到的概率进行排序,公式8中的第二部分相当于是公有部分,不会影响item的排名。相当于我们的目标是计算第一部分,如公式9所示: ∑ a ∈ A P ( Y ∣ U , x , a ) P ( a ∣ x ∗ ) (9) \sum_{a \in \mathcal{A}}{P(Y|U,x,a)P(a|x^*)}\tag{9} a∈A∑P(Y∣U,x,a)P(a∣x∗)(9)
因为我们可以取X的任意值为参考值 x ∗ x^* x∗,因此只要存在一个 x ∗ x^* x∗满足 P ( a ∣ x ∗ ) = P ( a ) P(a|x^*) = P(a) P(a∣x∗)=P(a),就有下式成立: ∑ a ∈ A P ( Y ∣ U , x , a ) P ( a ∣ x ∗ ) ∝ ∑ a ∈ A P ( Y ∣ U , x , a ) P ( a ) (10) \sum_{a \in \mathcal{A}}{P(Y|U,x,a)P(a|x^*)} \propto \sum_{a \in \mathcal{A}}{P(Y|U,x,a)P(a)} \tag{10} a∈A∑P(Y∣U,x,a)P(a∣x∗)∝a∈A∑P(Y∣U,x,a)P(a)(10)
这意味着我们之前的计算方式在某种程度上可以近似这种情况下的特定路径的因果效应。
- 情况c:当A和X之间没有任何关系时,意味着A和X是物品独立的两个特征。在这种情况下进行因果干预相当于直接计算X和Y的因果关系。
P ( Y ∣ U , d o ( X ) ) = ∑ a ∈ A P ( Y ∣ U , x , a ) P ( a ) = P ( Y ∣ U , X ) (11) P(Y|U,do(X)) = \sum_{a \in \mathcal{A}}{P(Y|U,x,a)P(a)} = P(Y|U,X)\tag{11} P(Y∣U,do(X))=a∈A∑P(Y∣U,x,a)P(a)=P(Y∣U,X)(11)
Experiments
快手和微信的两个视频数据集,详细信息如下所示,最后两个参数 ρ 1 , ρ 2 \rho_1 , \rho_2 ρ1,ρ2分别是是训练集标签和测试集标签对混淆因素A(视频长度)的皮尔逊相关系数
满足条件是测试集与训练集相比,更加不受混淆因素的影响。

进行大量实验主要是回答下面三个问题
-
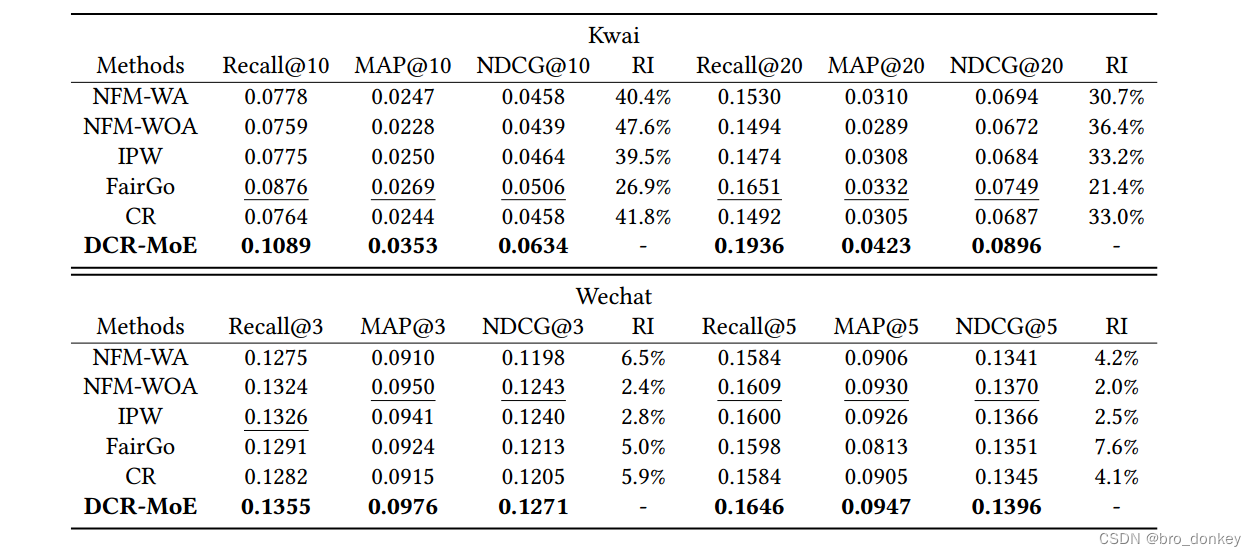
RQ1 How is the performance of the proposed framework DCR implemented with MoE (denoted as DCR-MoE) compared with existing methods?
这个问题主要是DCR-MoE和其他模型相比的性能问题,实验结果如下所示。
-
RQ2 How do the design choices affect the effectiveness and efficiency of DCR-MoE?
这个问题主要针对的是自身各个模块的有效性和效率问题,进行消融实验,结果如下:
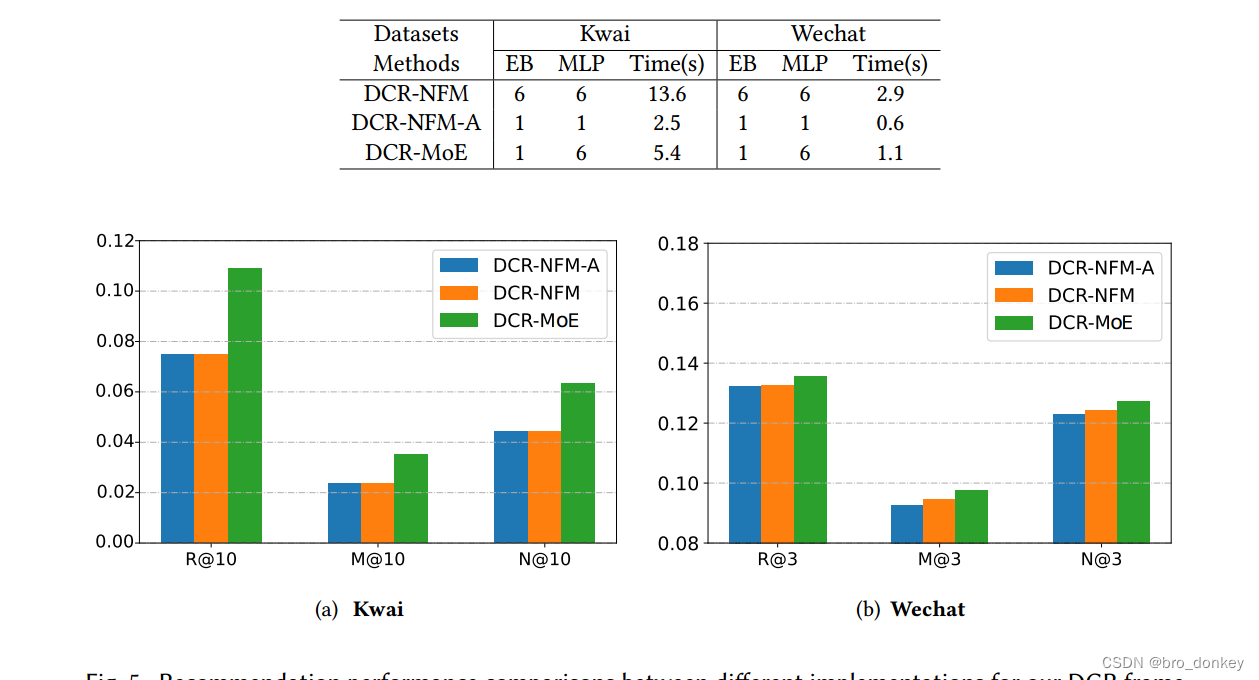
-
RQ3 Has the proposed method effectively eliminated the impact of the confounding feature?
论证DCR框架是否消除了混淆因素的影响,为此,混淆特征相同值的为一组,组与组之间进行对比实验,观察是否更加的公平。
结果如下:
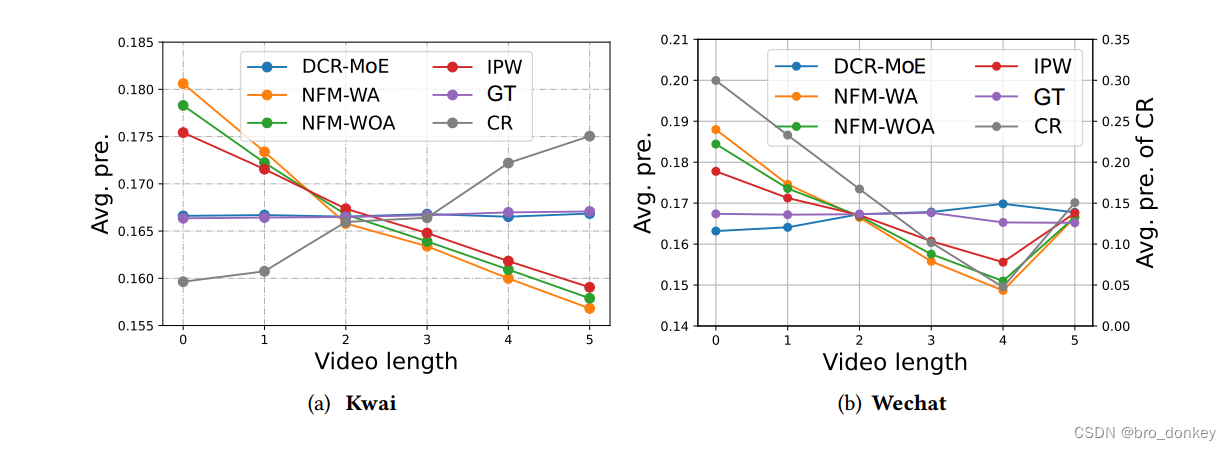
-
- 计算
P
(
A
)
P(A)
P(A):在本文中涉及到的混合特征A只有一个,但是它的值是K个。并且K远小于数据集
D
\mathcal{D}
D的大小。



