
Hadoop搭建(完全分布式)
温馨提示:这篇文章已超过397天没有更新,请注意相关的内容是否还可用!
节点分布:
| bigdata-master | bigdata-slave1 | bigdata-salve2 |
| NameNode | NodeManager | NodeManager |
| SecondaryNameNode | DataNode | DataNode |
| ResourceManager | ||
| NodeManager | ||
| DataNode |
目录
一、jdk安装:
二、hadoop安装
一、jdk安装:
jdk-8u212链接:https://pan.baidu.com/s/1avN5VPdswFlMZQNeXReAHg
提取码:50w6
1.解压
[root@bigdata-master software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
2.环境变量
vim /etc/profile
添加如下配置 ``` export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin ```

:wq保存退出
使配置生效
source /etc/profile
3.查看版本
java -version

4.免密登录(三台都执行)一定要弄的
ssh-keygen -t rsa
其中会让输入密码等操作,直接不输入,按enter键
会在/root/.ssh产生id_rsa和id_rsa.pub文件
cd /root/.ssh
cat id_rsa.pub >>authorized_keys
将其他节点的id_rsa.pub内容添加到本节点的authorized_keys文件中(每个节点需要执行)
二、hadoop安装
hadoop-3.1.3链接:https://pan.baidu.com/s/11yFkirCiT6tdo_9i1jWwkw
提取码:stgv
1.解压
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
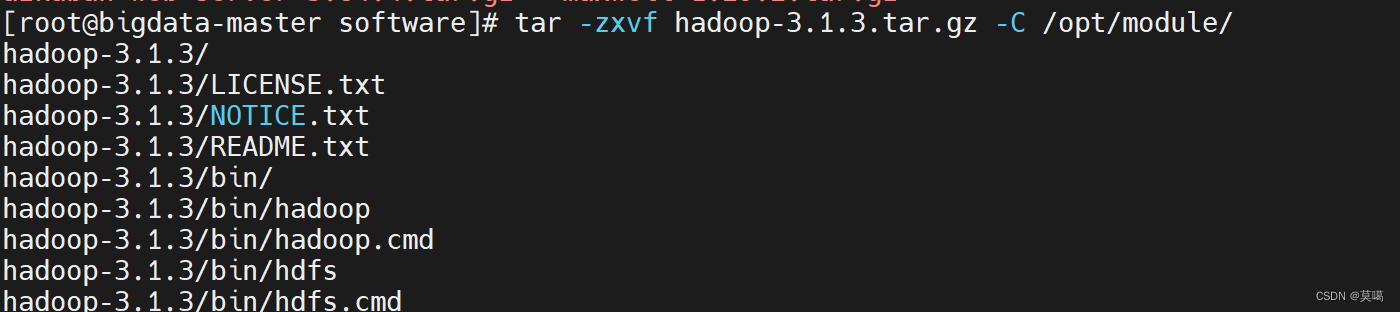
2.配置文件
cd /opt/module/hadoop-3.1.3/etc/hadoop/
(1). core-site.xml
vim core-site.xml
hadoop.tmp.dir
file:/opt/module/hadoop-3.1.3/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://bigdata-master:9000
hadoop.proxyuser.root.hosts
对root用户不进行限制
*
hadoop.proxyuser.root.groups
*
对root群组不限制
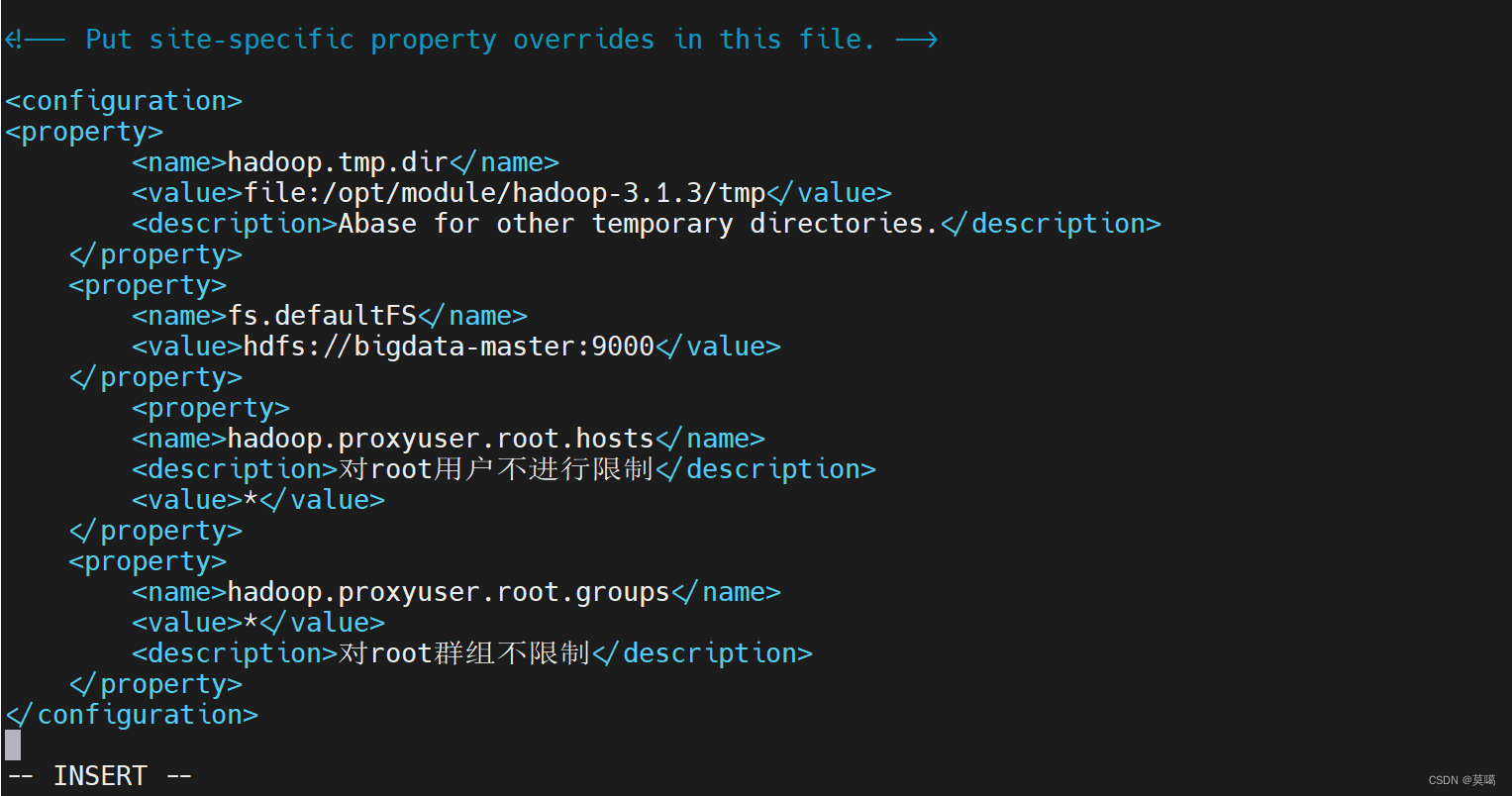 保存退出(:wq)
保存退出(:wq)
(2). hdfs-site.xml
vim hdfs-site.xml
dfs.replication
2
dfs.namenode.name.dir
file:/opt/module/hadoop-3.1.3/tmp/dfs/name
dfs.datanode.data.dir
file:/opt/module/hadoop-3.1.3/tmp/dfs/data
 保存退出(:wq)
保存退出(:wq)
(3). mapred-site.xml
vim mapred-site.xml
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
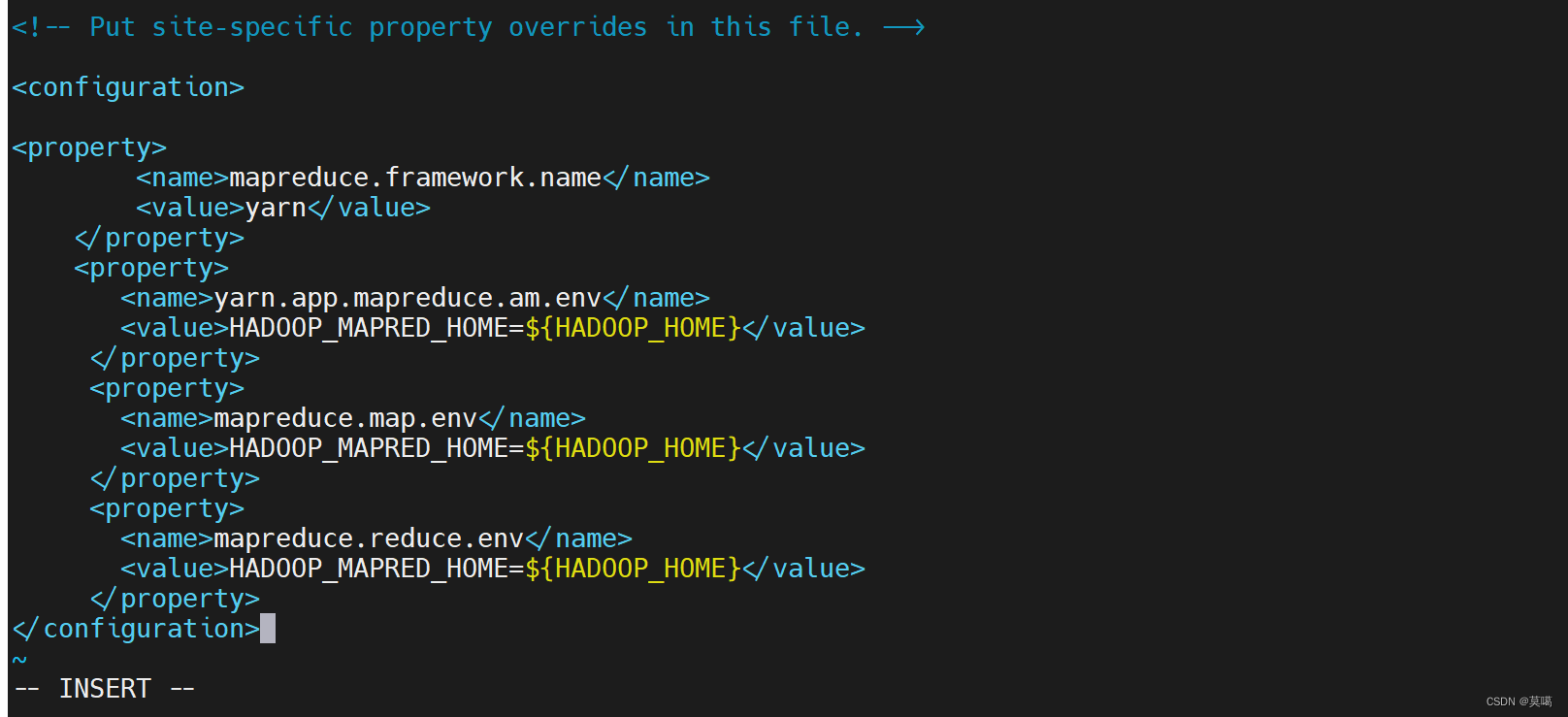
保存退出(:wq)
(4). yarn-site.xml
vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
bigdata-master
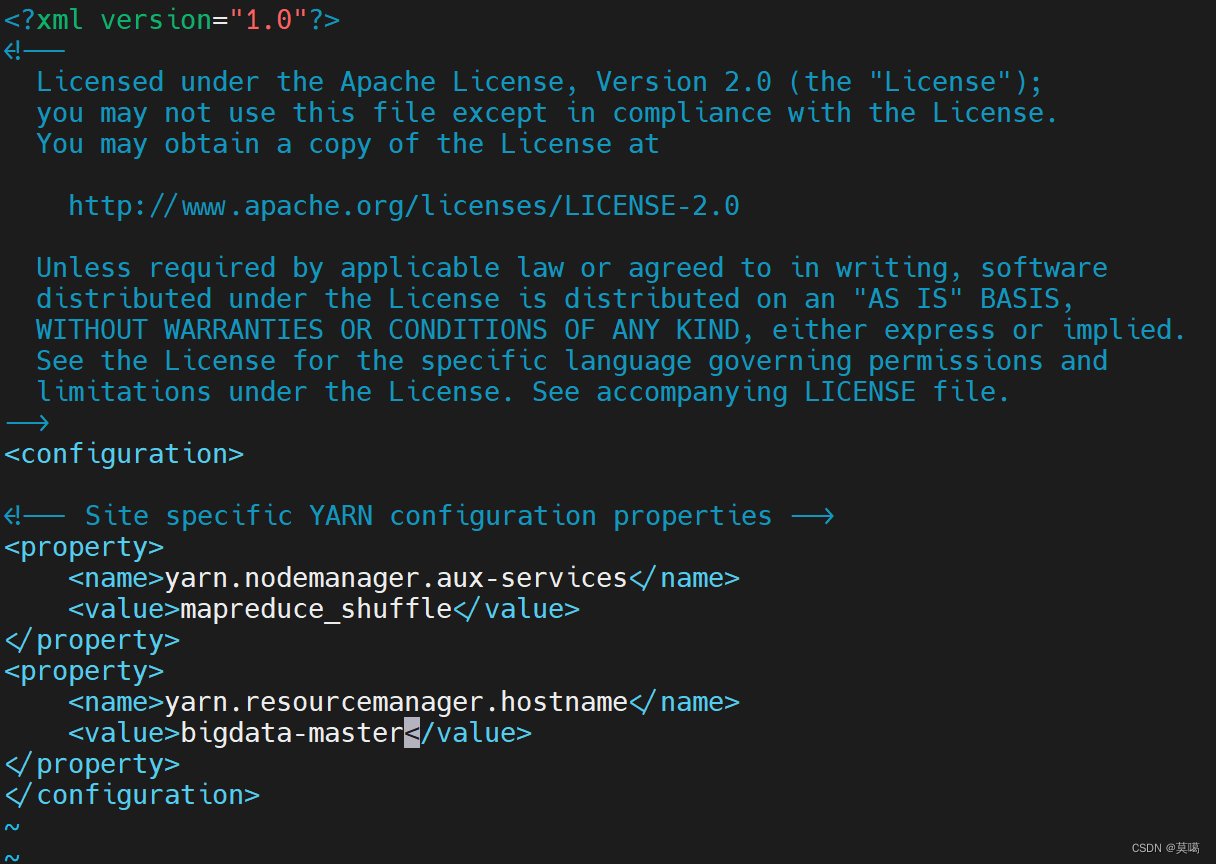
保存退出(:wq)
(5).yarn-env,sh
vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212

(6).workers
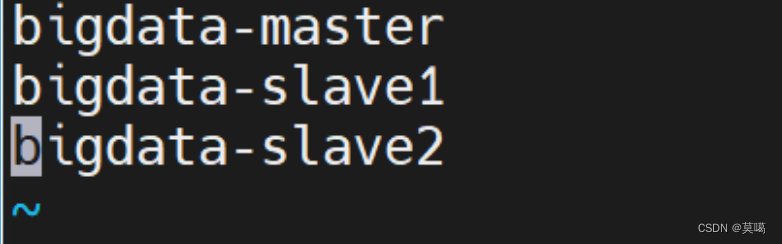
vim workers
bigdata-master bigdata-slave1 bigdata-slave2
(7).
修改 /opt/module/hadoop-3.1.3/sbin/start-dfs.sh和 /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
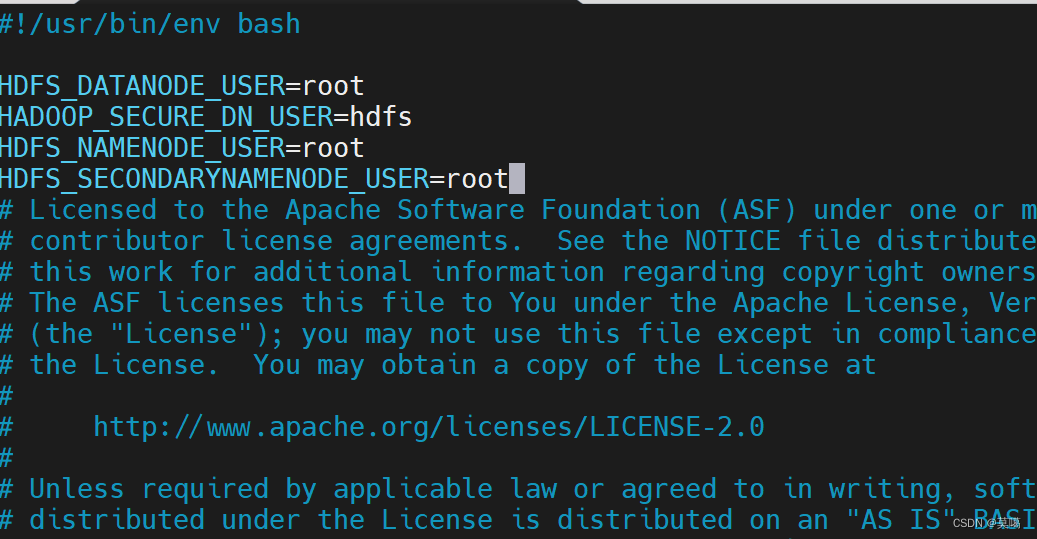
vim /opt/module/hadoop-3.1.3/sbin/start-dfs.sh
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
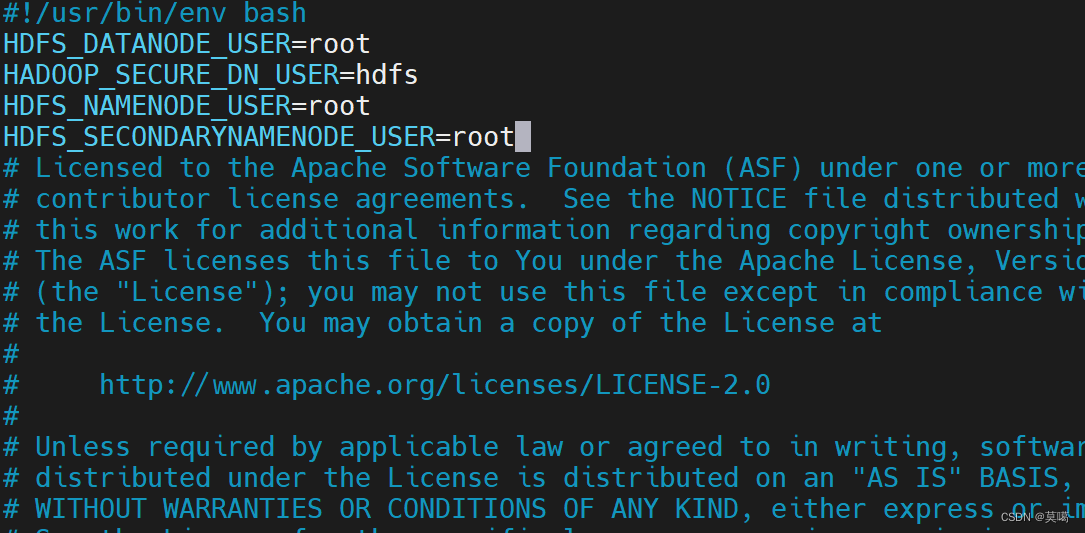
/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
(8).
修改 /opt/module/hadoop-3.1.3/sbin/start-yarn.sh和 /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
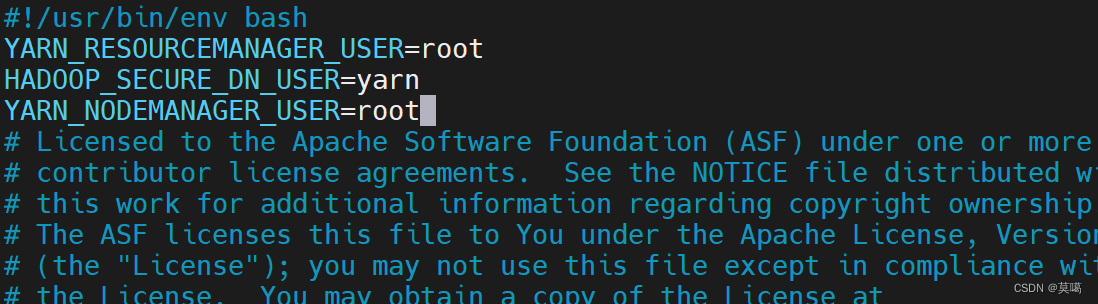
vim /opt/module/hadoop-3.1.3/sbin/start-yarn.sh
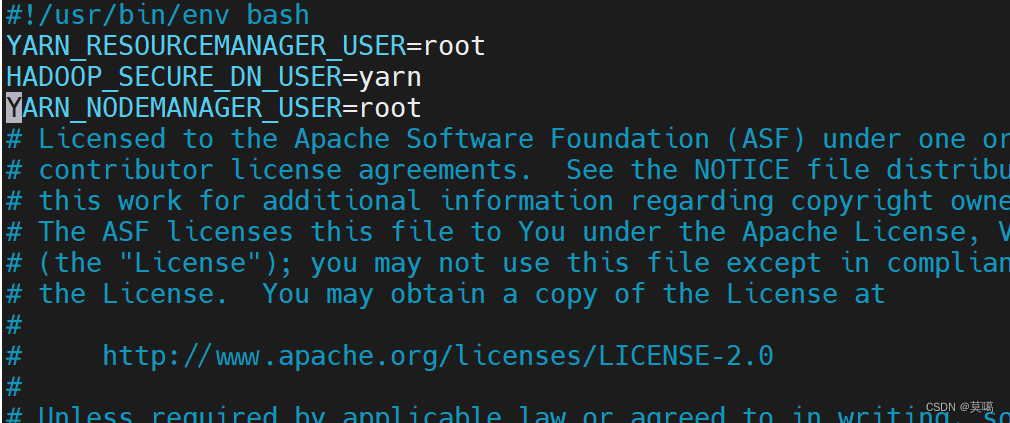
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
vim /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
3.环境变量
vim /etc/profile
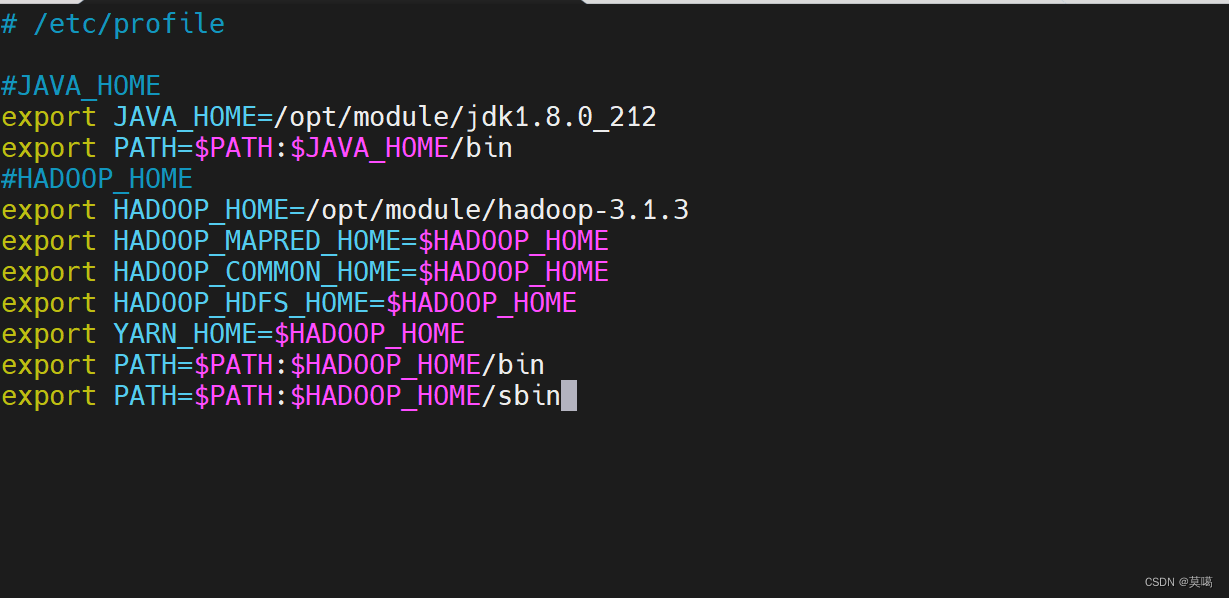
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
使变量生效
source /etc/profile
4.分发(或者自己手配以上步骤给另外两台)

分发hadoop和jdk
[root@bigdata-master hadoop]# scp -r /opt/module/ root@bigdata-slave1:/opt/module [root@bigdata-master hadoop]# scp -r /opt/module/ root@bigdata-slave2:/opt/module
配置另外两台的环境变量 并使变量生效
source /etc/profile
5.Hdfs格式化(bigdata-master)
不要多次格式化
hdfs namenode -format

6.启动hadoop
start-all.sh
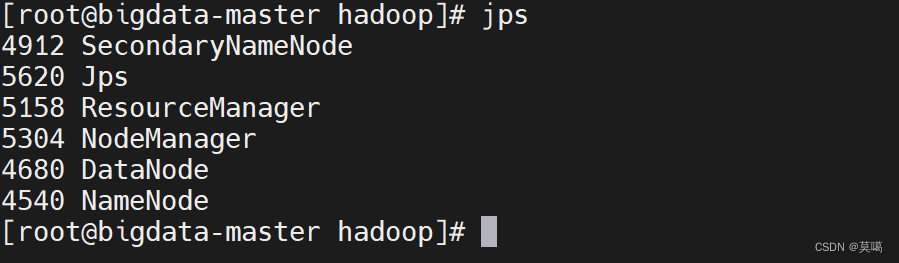
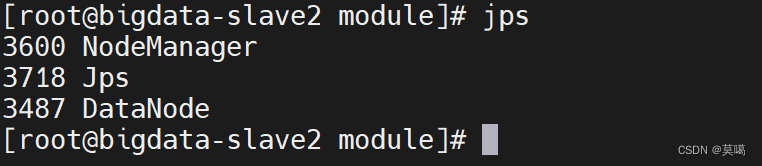
jps查看进程:

免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



