
技能
温馨提示:这篇文章已超过496天没有更新,请注意相关的内容是否还可用!
VMProtect是新一代软件保护系统,它将受保护的代码运行在虚拟机中,这将使分析反编译代码并破解变得极其困难。因此,为了实现一条x86指令的相同功能,Vmp的CPU需要执行多条指令。这就需要代码的读者阅读大量的代码才能理解程序逻辑。但是,授权功能的系统要求至少为 Windows 2000。该版本完全支持脚本、水印、序列号和 VMProtect 的所有其他功能。人工智能的大规模应用在加速传统数据安全问题的同时,进一步加剧了数据过度采集的安全问题,甚至催生了“数据中毒”等新的数据安全问题。武器化模型的存在引起了人们对人工智能和机器学习技术的适当使用的担忧。
VMProtect是新一代软件保护系统,它将受保护的代码运行在虚拟机中,这将使分析反编译代码并破解变得极其困难。
软件基础知识简介
Vmprotect使用不同于x86的虚拟CPU来执行转换后的程序。 该CPU只支持简单的运算和最简单的无条件跳转指令。 因此,为了实现一条x86指令的相同功能,Vmp的CPU需要执行多条指令。 这就需要代码的读者阅读大量的代码才能理解程序逻辑。
VMProtect是一款软件保护软件。 该软件保护的代码部分是在虚拟机上执行的,这使得受保护的程序难以分析和破解。 使用反汇编程序和MAP文件可以让您快速选择需要保护免遭破解的代码。
VMProtect Ultimate是一款专业的限制软件更新的工具软件。 用户可以使用软件来限制可执行文件、动态加载的库、驱动程序和其他文件的频繁更新。 软件支持限制和修改序列号以及序列号的有效期。 总体来说这是一个非常好的软件。
软件特点

支持的文件和格式
VMProtect 支持 32 位和 64 位可执行文件、动态加载的库和驱动程序。 这包括屏幕保护程序、Active-X 组件、BPL 库和其他 PE 格式文件。 受保护的文件基本上可以在任何版本的 Windows 上运行,甚至是较旧的 Windows 95! 但是,授权功能的系统要求至少为 Windows 2000。VMProtect 不支持 .NET 可执行文件,并且对 VB 可执行文件的支持有限。
序列号
VMProtect 的终极版本允许用户轻松地将序列号添加到受保护的应用程序中。 PayPro Global 电子商务提供商支持此功能,因此您甚至不需要设置自己的序列号生成器(当然,如果您确实需要,也可以这样做)。 许可功能可帮助用户限制免费更新周期、设置序列号的有效期限、防止在未输入序列号的情况下执行代码,并提供许多其他功能。 您还可以阻止新的受保护文件不接受的任何序列号。
用户界面
VMProtect 提供两种用户界面模式:简单模式和专家模式。 简单模式可帮助用户轻松选择保护功能、调整选项,只需点击几下鼠标即可获取受保护的文件。 专家模式适用于高级用户,它显示汇编代码,允许编写脚本、绑定 DLL 等。此外,“选项”选项卡中提供了更多设置。

主机版
VMProtect 的专业版和旗舰版有一个控制台版本,支持命令行参数,可以在自动构建期间使用。 该版本完全支持脚本、水印、序列号和 VMProtect 的所有其他功能。
安装步骤
下载安装包并打开
按照安装指南进行安装
安装完成后即可打开并使用。

如今,人工智能技术的快速发展给各个领域带来了前所未有的变化和进步。 其中包括2023年上半年的“顶尖玩家”——生成式AI和ChatGPT。
ChatGPT的火爆让人们看到了AI惊人表现的光辉一面,但与此同时,阴暗面也在暗中发力、疯狂生长。
AI技术不仅可以用来维护网络安全,有兴趣的人还可以利用AI技术进行网络攻击。 人工智能网络攻击引发了人们对隐私、安全和道德问题日益增长的担忧。 AI攻击不仅仅是黑客利用AI技术进行犯罪活动,还包括其他潜在威胁,例如误导性信息、社会工程等。
让我们来看看十大最热门的新型AI网络攻击方式。
AI中毒攻击
人工智能的大规模应用在加速传统数据安全问题的同时,进一步加剧了数据过度采集的安全问题,甚至催生了“数据中毒”等新的数据安全问题。
一般来说,AI中毒是指攻击者通过在训练数据中添加精心构造的异常数据来破坏原始训练数据的概率分布,导致模型在一定条件下产生分类或聚类错误,从而破坏其训练数据集和准确性。
其中,最常见的中毒形式是后门中毒,即使只有极小部分训练数据受到影响。 人工智能模型可以在很长一段时间内持续提供高度准确的结果,直到它被“激活”并在暴露于特定触发器时出现故障。
适应场景
由于数据中毒攻击需要攻击者访问训练数据,因此通常针对在线学习场景或需要定期重新训练模型更新的系统。 这种类型的攻击更为有效。 典型场景包括推荐系统、自适应生物识别系统和垃圾邮件检测系统。 数据中毒攻击过程可分为三个阶段:
1. 根据被攻击模型的输出特征,选择替代训练集,在相同输入下训练出具有相同输出的模型。 比如猫和狗的分类。
2、初始化恶意样本集(无论来源如何),利用梯度更新(根据需要构造损失函数,如梯度上升策略)恶意样本,直至达到预期效果。
3、将恶意样本集放入被攻击模型的训练集中
“AI模型中毒”将严重威胁AI应用的完整性和安全性。 因此,大型语言模型 (LLM) 需要接受风险和安全研究人员的严格审查,以探索反馈循环和人工智能偏差等问题如何导致人工智能输出不可靠。
AI生成的恶意软件
在网络安全领域,威胁行为者手中的人工智能潜在威胁不断敲响警钟。 尤其是现在,使用人工智能工具创建恶意软件已成为现实。
研究人员发现,利用生成式人工智能可以帮助黑客制作恶意软件并快速发现目标系统中的漏洞,从而比使用其他自动化技术更快地加速和扩展攻击。
这也是SANS列出的“2023年最危险的5大网络攻击”中的又一重大威胁。 在RSAC 2023会议上,SANS漏洞研究员Steven Sims表示,即使是非专业犯罪分子也开始尝试使用ChatGPT生成勒索软件代码,并在特定代码段中发现了ChatGPT自动生成的零日漏洞。
AI数据隐私攻击
在人工智能应用中,数据隐私和信息安全是首要关注的问题之一。 随着大规模数据的收集和存储,个人信息泄露和黑客攻击的风险也越来越大。 数据偏见和算法不公平可能会导致不公平的决策和影响,因此人工智能算法中的偏见和歧视问题引起了广泛关注。
与此同时,社会工程和欺诈也成为人工智能应用的挑战,虚假信息和网络欺诈的增加给社会带来了负面影响。

如果人工智能模型在构建时没有采取足够的隐私措施,攻击者就有可能破坏用于训练这些模型的数据的机密性。 对于个人来说,了解企业如何使用人工智能及其对数据的影响将非常重要。 攻击者还可能尝试使用恶意软件窃取包含信用卡号或社会保障号等个人信息的敏感数据集。 隐私风险可能发生在数据生命周期的任何阶段,因此为所有利益相关者制定统一的隐私安全策略非常重要。
武器化模型
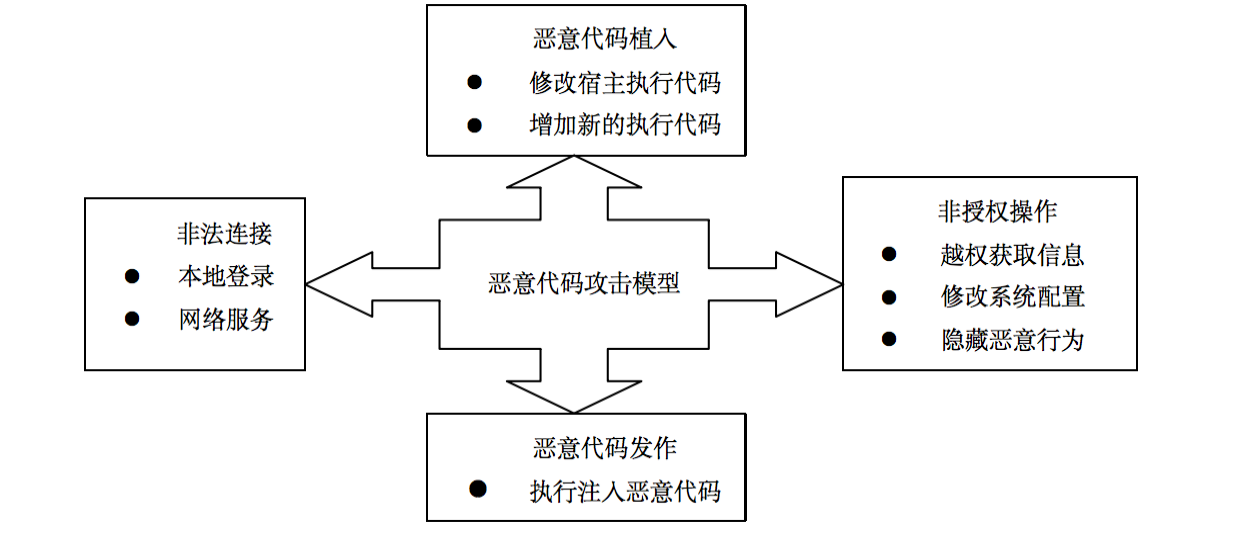
武器化模型是指将人工智能或机器学习模型应用于恶意目的或攻击行为的过程。 通常,这种行为是非法的和破坏性的,旨在侵犯隐私、破坏系统、欺骗用户或其他恶意活动。
武器化模型可用于各种攻击场景,例如网络攻击、隐私侵犯、社会工程等。
在网络钓鱼攻击中,自然语言处理模型可用于生成欺骗性电子邮件或社交媒体消息,以诱骗用户提供个人信息或执行恶意操作。
使用机器学习模型来对抗其他系统中的欺诈检测机制,例如规避金融交易中的反欺诈系统。 以及使用机器学习模型来分类和识别恶意软件以闯入系统、窃取信息或造成损害。
另外,这种方法也多用于自动化的网络攻击,比如利用机器学习和自适应算法自动发现和利用系统或应用程序的漏洞来进行攻击,比如自动化的漏洞扫描和利用。
武器化模型也常用于假新闻和虚假信息的传播,通过利用自然语言处理模型生成假新闻文章、社交媒体帖子或评论来操纵舆论或造成混乱。
武器化模型的存在引起了人们对人工智能和机器学习技术的适当使用的担忧。 为了应对这一威胁,研究人员和业界应加强安全分析、加强监管控制、提高用户意识,以减少武器化模型的风险和滥用。
海绵攻击
2023 年 RSAC 会议设有一个小组,讨论 CISO 在未来几年将面临的人工智能风险和弹性问题。 讨论中最引人注目的主题之一是一种称为海绵攻击的新兴攻击。

在海绵攻击中,攻击者通过针对海绵结构中的弱点来损害海绵的安全性。 攻击的目标是根据给定的输入生成具有特定属性的输出。 攻击者通过选择适当的输入数据并进行特定的修改,并通过观察输出数据的反馈来指导修改过程来实现这一目标。
在这种攻击类型中,对手可以通过特制的输入消耗模型的硬件资源,从而对AI模型进行拒绝服务攻击。
CalypsoAI首席执行官Neil Serebryany表示,此次攻击试图让神经网络使用更多的计算量,以至于可能超出系统的可用计算资源,导致系统崩溃。
AI大模型窃取攻击
AI大模型盗窃攻击是针对人工智能领域的安全威胁。 攻击者试图通过获取经过训练的大型人工智能模型的权重和参数来获取模型的知识和能力,而无需从头开始训练自己的模型。
这种攻击主要基于两种主要方法:

攻击者不仅可以从人工智能技术的应用部署中窃取数据,还可以通过各类攻击手段破解人工智能模型的运行原理。 AI大模型窃取攻击可以让攻击者获得模型的知识和能力,包括模型学习到的数据特征和模式。 这可能会导致原有车型商业秘密的泄露,也可能导致在竞争中失去技术优势。
此外,如果攻击者能够获取公司或组织的核心AI模型,他们就可以利用该模型在竞争市场中获得不公平的优势,或者滥用该模型引发恶意行为,从而削弱组织的竞争优势。
为了防止大型AI模型盗窃攻击,开发者和研究人员可以采取一些安全措施,包括但不限于对训练数据和模型权重进行加密、限制对模型接口的访问、使用模型水印技术等。此外,研究人员还探索更安全的AI模型设计和训练方法,降低模型被盗的风险。
AI技术的研究和创新需要高度的团队协作和迭代开发,因此涉及大量的共享,包括数据共享和模型共享,这可能会给AI供应链带来重大风险。 研究人员最近发现了一种新的人工智能攻击模型。 攻击者首先劫持公共代码库上的合法AI模型,然后将恶意代码嵌入到这些预先训练的AI模型中,使其具有恶意。 一旦用户重新加载这些修改后的AI模型,攻击者就可以进行勒索软件攻击等非法活动。
Tip注入攻击:

提示注入(Pi)攻击是AIGC大语言模型引发内容安全、数据安全等风险的重要原因之一。
提示注入是一种影响某些 AI/ML 模型的新型漏洞。 本质上,它训练一个机器学习模型,听从人类指令来遵循恶意用户提供的指令,从而突破模型本身实现的内容生产规则的限制,这就是劫持模型输出的过程。
当开发者将ChatGPT和其他大型语言模型(LLM)集成到他们的应用程序中时,这些恶意提示会被AI模型处理并触发一些不安全行为,例如向网站发布欺诈内容,或者制作可能包含非法或非法内容的电子邮件。煽动性信息。

逃脱攻击
逃避攻击是目前最典型的对抗性人工智能攻击之一。 攻击者试图逃离受限环境并获得提升的权限或更广泛的访问权限以获取敏感信息或执行未经授权的操作。
攻击者专门构建的用于进行规避攻击的样本通常被称为“对抗性样本”。只要AI模型在判别机制上存在缺陷,攻击者就有可能构建对抗性样本来欺骗AI模型。
研究人员一直试图在计算机上模仿人类视觉功能,但由于人类视觉机制过于复杂,两个系统在区分物体时所依赖的规则存在一定的差异。
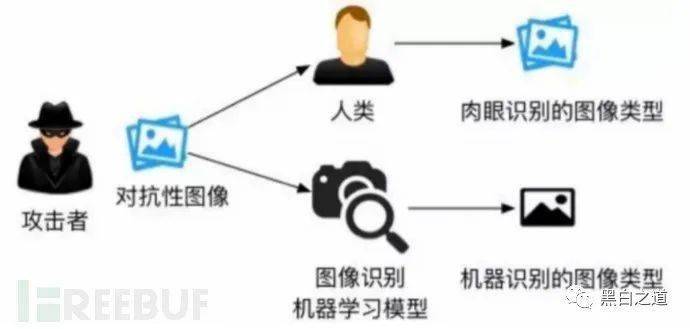
此类规避攻击可能发生在各种系统和应用程序中,包括操作系统、虚拟化平台、容器、浏览器和移动设备。 攻击者利用系统中的漏洞、错误配置或有缺陷的控制机制,成功地“逃离”受限环境,并通过注入恶意代码、提升权限和绕过安全限制来访问系统或其他资源。 完全控制权限。
逃逸攻击的危害性很大,因为攻击者获得了更高的权限,可以绕过各种安全机制和访问限制。 一旦攻击者成功逃脱,他们可能能够执行恶意操作,例如访问敏感数据、篡改系统配置、拦截通信、安装恶意软件等,从而对系统和用户造成严重损害。
AI 生成的网络钓鱼和 BEC 诱饵
人工智能生成的网络钓鱼和 BEC(商业电子邮件欺诈)诱饵是使用人工智能技术生成的虚假电子邮件、消息或其他通信,然后伪装成信誉良好的机构、公司、服务提供商或个人。 引诱用户相信其真实性,通过点击链接、下载附件、提供敏感信息、填写表格等方式欺骗员工,获取机密商业信息、敏感财务数据,进行非法转账。
由于冒充者采用高度真实的欺骗手段,员工很难察觉欺骗行为,从而误认为这些要求合法合理。
人工智能技术的应用使得网络钓鱼和BEC诱饵攻击变得更加扑朔迷离和隐蔽,让用户更难辨别真伪。
此类AI生成的网络钓鱼和BEC诱饵往往具有以下“优点”:
针对这种攻击方式,企业需要加强员工教育、实施有效的安全控制和监控、建立内部报告机制作为防范BEC诱饵攻击的关键措施。
Deepfake深度假冒骗局
Deepfake是一种人工智能技术,可以将人的声音、面部表情和身体动作拼接成虚假内容。 它主要利用生成对抗网络的机器学习模型,将图片或视频融合叠加到源图片或视频上,利用神经网络技术进行大样本学习,达到伪造的目的。

深度伪造最常见的手段是AI换脸技术,其中还包括语音模拟、人脸合成、视频生成等,它的出现使得篡改或生成高度真实且难以区分的音视频内容成为可能,最终导致观察者无法用肉眼辨别真伪。
如今,ChatGPT 已将深度造假攻击从理论转变为真正的威胁。
如果不法分子利用这种深度伪造技术攻击企业或个人,不仅会威胁国家安全和公共安全,还可能利用其传播虚假视频、激化社会矛盾、煽动暴力恐怖行为,还可能被用来干扰竞争。 该国情报机构甚至设定了限制其行动范围的条件。
同时,该技术也降低了视频换脸技术的门槛。 别有用心的人可以利用深度伪造技术轻松绑架或窃取他人的身份。 甚至可以说,深度伪造技术可能被用来实施色情报复、商业诽谤、敲诈勒索、网络攻击等犯罪等非法活动的新工具。
结论
如今,人工智能带来的威胁已经逼近。 随着人工智能应用范围不断扩大,新的攻击技术不断涌现。 新的人工智能攻击给个人、企业和整个社会带来巨大的风险和危害。
一方面,人工智能可以成为网络可见性、异常检测和威胁自动化的强大工具。 另一方面,人工智能也可能成为黑客侵入系统、窃取数据的邪恶力量。
对于网络安全的攻防博弈来说,人工智能既是“天使”,又是“恶魔”。 如何轻松、适度地掌控AI至关重要。
人工智能和网络安全是密切相关、相互影响的两个领域。 利用人工智能技术,提高网络安全水平,保护数据和设备免受攻击或破坏; 但同时,我们也必须关注人工智能本身带来的一些挑战和风险,并采取相应措施应对。
人工智能的发展给我们带来了前所未有的可能性,但也需要人们保持警惕,认识到技术本身的局限性。 只有综合运用技术、法律、教育等手段,才能构建安全可靠的网络环境。 。



