
我把我的声音训练成了AI模型,并让它唱了一首歌...(附超全面教程,你奶奶看了都会用)
我天生五音不全,对于所有需要唱歌的场合我都是抗拒的,因为只有一片笑声。
我一直有一个梦想,就是用我的声音,唱一首不跑调的歌。
得益于AI的井喷式发展,我的愿望实现了。
我把我的声音,训练成了模型,并让它唱了一首我非常喜欢的《富士山下》。
当梦想变成现实,当不需要我再开口就有我的声音,我的一切都变成模型被复刻下来。好像我也永远停在了这个时间点。
变成了真正的,数字生命。
我使用的项目是So-VITS-SVC,目前质量最高还原度最逼真的AI声音项目。
这里做个简单的小科普。
AI音频远没有AI绘图和AI文本技术成熟。目前主流有两种路线,SVC和TTS。
**SVC(Singing Voice Conversion),歌声转换,也就是类似变声器的玩意,抽取一个人的声音作为训练数据,训练一个神经网络模型,学习他的声线;然后用模型在目标歌曲上做推理,即可实现用自己的声线唱目标歌曲。**目前主要是两个项目顶着,So-VITS-SVC和Diff-SVC,我用的就是前者。然而可惜的是,So-VITS-SVC项目已经于4月23号正式停止维护了。
TTS(Text-to-Speech),文本生成音频,这玩意应用现在极其成熟,应用端各种什么微软腾讯都玩的66的。前几天大火的Bark项目就是TTS,而定制自己的声音TTS项目PaddleSpeech也是极其简单,在百度飞浆上可以直接跑,属于有手就行那种。后面我也会出一个TTS的PaddleSpeech教程,非常简单。
AI生成领域,四大模态:文案、图片、声音、视频。
文案和图片已经被完全攻陷,声音已经开始崭露头角,而视频仍然在坚守着属于人类的最后一块堡垒。
话不多说,直接开始我们的AI声音教程。
整个AI声音教程相比AI绘图会比较难一些,所以文章可能会比较长,我尽量写的细一些,让你奶奶来了都会自己训练模型~
整体大概需要4步。
- 准备声音数据集。
- 租云算力,上传数据集。
- 在云上训练模型。
- 本地进行推理模型重绘歌曲。
当然,万物起始,先下载傻瓜一站式整合包,关注我公众号:数字生命卡兹克,回复S就有了,此处感谢B站大佬@羽毛布団制作的的开源整合包,AI绘图有秋叶,AI声音有羽毛,都是一等一的大佬!
一. 准备数据集
声音模型对数据集的要求比较苛刻,因为声音越优质,越干净,效果一定越好。所以没有杂音、没有乱七八糟的混响等等的干声是必须的,而且音域越广越好。
**所以如果你想训练你自己的声音,尽量是1小时以上的无杂音的纯人声,WAV格式。**可以使用手机、电脑录音等等,直接录1段或者多段,都行,然后转成WAV格式。
再使用整合包里的工具Audio Slicer(音频切分)将其剪裁成10秒左右的分段文件,因为你1个小时的文件直接拿去训练是必爆的,所以我们需要将他拆成10秒左右的1小段1小段,我们把Audio Slicer(音频切分)下载下来,解压后打开Slicer-gui。

然后把Minimun Length那一项改成8000,把我们需要处理的音频直接拖到左边窗口,在右下角选择输出路径。同时此处注意,任何路径和文件命名,都一定不要带有中文和特殊的比如空格之类的字符!!!

扔进去以后,我们直接点最右下角的Start。速度非常块,十几秒就切割完了。我们去我们选择的输出路径就能看到我们的文件。

然后我们选择时长排序,把低于2秒的,超过15秒的都给删了。数据集就算是处理完毕了~

当然,我相信任何人弄这一步都肯定很麻烦,毕竟玩之前还特么先得自己录1小时,人没了。所以我也为大家在整合包里准备了1个优质数据集,来自原神派蒙的近2小时的语音文件,我已经处理完了。打开即用。关注我公众号:数字生命卡兹克回复S就有了(注:派蒙的数据集下载解压后,上传到你的阿里云盘,第二步你就知道了)。希望大家能让大家最快速度感受AI声音的魅力~

二. 租云算力,上传数据集
第二步当然就是开始我们的训练了,训练模型挺烧显卡的,而且大多人的显卡达不到训练的地步,所以我们直接上云,花个十几块钱,轻松便捷。
这里我推荐https://www.autodl.com/,目前非常便宜的云算力平台,注册好账号以后,自己充值,建议冲30~50左右,别太紧巴。然后我们点击控制台 - 容器实例,来到这个页面,再点击租用新实例(实例其实就是显卡的意思)

进到这个页面以后,就是租显卡了,直接选北京C区,找到V100 32G,租1张,记住,如果没有V100 32G,就刷新,刷到有为止,北京区的V100 32G,能把你后续训练的报错概率降到最低!

选中后,往下拖,找到社区镜像,点击。

在下面的输入框中输入so-v,找到后缀是v10的,选中,然后点立即创建,就能看到你的算力已经租好了。第一次创建时间会久一些,等等。


等到创建完毕,状态已经是运行中后,点击AutoPanel,把我们准备好的数据集传到租的服务器上。

进来以后,选择公网网盘,我们用网盘来当桥梁,第一次会先让你设置一个密码,随便设一个你自己能记得的就行。

然后此处我们选择阿里云盘来当桥梁,你懂的,不限速,而且百度网盘说实话在跟服务器的对接上太麻烦了。。。**如果你是用的自己的数据集,就把你自己的数据集传到你的阿里云盘上,如果用我的派蒙的例子,就直接下载解压,上传到你的阿里云盘,**然后用你的手机阿里云盘扫码登录。

登录成功以后,就能看到我们的文件了,点击要下载的数据集文件夹,我们的服务器就会开始下载了,这个地方下载确实会比较慢,需要等几分钟,大家别急,撒泡尿去遛遛弯,看看剧,一会就好。

下载完了以后,我们就直接把这个页面关了就行,给服务器上传数据,算是正式完成,接下来第3步,我们正式开始训练我们的模型~
三. 在云上训练我们的模型
回到我们的控制台页面,点击JupyterLab

进入到一个文档页面,这个页面看着复杂,但是其实项目作者已经都整合好了,你只要傻瓜式的无脑点击下一步就可以啦~我们先点击下面的第1步这个区域,看到前面的蓝色横线跑到了这,然后我们再点击左上角的运行按钮。
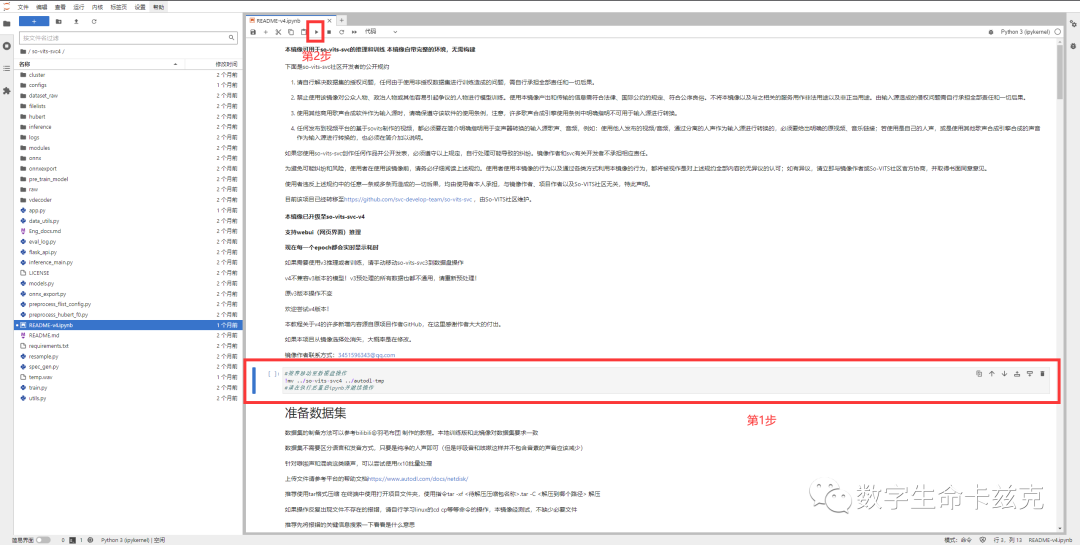
弹出这么一个框以后,说明运行完毕。

我们直接点击,然后点击左上角这个圆圈,把这个文件丢弃掉,不用管了。


接下来我们进入autodl-tmp,就能看到我们的数据集在这里面。

我们剪切它,把它放到刚才跟它一起在autodl-tmp的so-vits-svc4/dataset_raw文件夹下,这样咱们的数据集就放在了正确的位置了。

接下来我们回到so-vits-svc4目录下,打开这个文件README-v4.ipynb,还需要点几个小步骤,把数据集变成能训练模型的规范。

就能看到跟之前一样的页面,这次我们下滑,找到将数据重新采样至44100hz,一样,点击区域后,再点击左上角运行。

当看到小蓝条下移,右上角的实心圆变空心之后,说明采样率处理已经完成,我们继续点击下一个需要运行的区域,划分数据集、验证集、测试集以及生成配置文件。跟之前一样,选中后,点击左上角运行。

速度非常快,几秒钟就把数据集给划分完毕。同时也生成了一个config.json这个配置文件。

我们按照config/config.json这个路径打开配置文件,把 "learning_rate"改成 0.0004,把 "batch_size"改成24,把 "keep_ckpts"改成10,然后按Ctrl+S保存!!!

learning_rate和batch_size这两个参数可以理解为训练速度和训练质量,因为我们用的V100 32G显卡,这块直接固定死数值就可以,keep_ckpts是保存多少个模型,因为声音模型训练是不会自动停止的,每几千步就会给你保存一个模型,所以我们可以让他自动保存最新的10个模型让我们来选一个最好的。
接着回到我们刚才的步骤文件,执行准备数据集的最后一步操作!生成hubert和f0文件老规矩,点击区域,然后左上角运行即可这步会慢很多,需要几分钟时间,耐心等待。

看到进度条100%后,就证明完事啦!所有的数据集准备工作都做完了!接下来,我们要正式开始训练啦!!

我们一定要保证我们正在so-vits-svc4目录下(一定要注意!!!),然后复制训练这个区域里的这行代码。

复制完以后,再点击右上角的这个新建页面按钮。

再点击这个终端。

把我们刚才复制的训练代码给粘贴进去,敲一下回车,运行!训练开始!
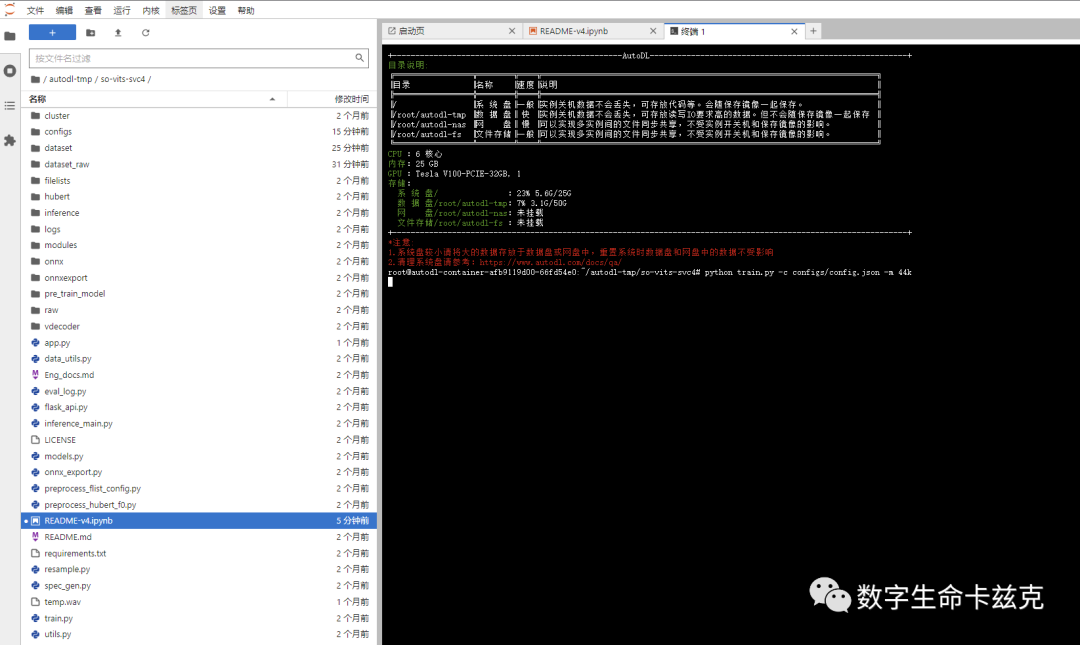
然后你就会看到各种眼花缭乱的看不懂的文字,没关系,看到有这种数字,就说明模型正在训练中了,比如我图中这个,已经训练了2轮了,第一轮花费101s,第2轮花费57s。在第7轮的时候终于训练了200步了。我们一般评价AI声音模型,都是按步数评价,而不是轮数。

然后,我们等着就好毕竟是在云上训练的嘛,我们可以直接把网页叉了,睡一觉,明早再来,或者开开心心去玩去丝毫不会影响训练。等到10000步的时候,我们再将模型取出来,进行本地推理~
四. 本地进行推理模型重绘歌曲
我们训练的模型会保存在autodl-tmp/so-vits-svc4/logs/44k这个文件夹里,D_XXXXX和D_XXXXX就是我们的模型,XXXXX是步数,比如G_8000就是训练到8000步的时候保存的模型。每800步就会保存一个模型。

我们直接右键下载,把他们拿到本地来,解压我们在最开头下载的整合包,放到同一个目录下So-VITS-SVC\logs\44k,根目录不太一样没有关系,云端叫so-vits-svc4,我们本地解压出来的叫So-VITS-SVC,无所谓,后面的子路径是一致的就OK。

这里我下载了6个模型,从7200步到18400步的,都下载下来听听试试,除了把模型放进来以外,我们还需要把之前在云上修改的config/config.json文件给下载到本地,把本地的So-VITS-SVC\configs里面的那个config.json文件给替换掉。保持统一。

接下来就是激动人心的时刻啦~我们要进行本地歌曲重绘了。
声音重绘的原理是,用模型的音色替换人声,所以正常我们想替歌声的话,是需要把伴奏和人声分离,用模型推理替换人声,把推理完的人声文件和伴奏合在一起,形成一首完整的歌。
这里给大家推荐一个我认为目前最牛逼的分离工具-UVR5,也在整合包里了。

直接先安装UVR5,然后解压模型包,把模型包里的文件解压出来,复制粘贴到Ultimate Vocal Remover\models文件夹里。这样UVR5就算安装好了。

音乐的获取推荐大家直接使用QQ音乐,下载以后,用https://demo.unlock-music.dev/这个小工具去解锁~

然后打开我们的UVR5,分为两步,先去伴奏,再去混响,提炼出一个干干净净的人声~
我们先去伴奏,input我们刚刚解锁的歌曲,这几个参数按下图设置。然后直接start就OK。
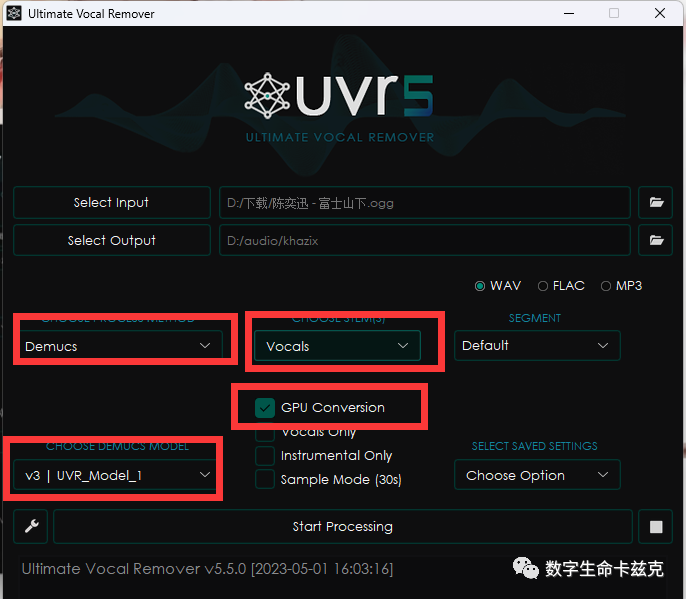
成功了以后,我们去到我们设置的输出目录下,就能看到两个文件,伴奏和人声已经分离出来了,但是人声还会带一些混响,我们需要把混响也去了,得到一个干干净净最完整的人声。

于是我们回到UVR5,把刚转出来的Vocals文件再导入,按下图参数设置,去掉混响。再点击Start。

OK,这时候咱们就得到了一个极其干净的人声。
但是这个人声歌曲一般都有好几分钟,直接推理必爆显存。所以推荐用AU啥的给切分一下,我的显卡不太行,就给切成了8段。

最后,咱们打开So-VITS-SVC\启动webui.bat这个文件,启动我们的WebUI,这玩意跟SD极其相似。

第一次运行会需要稍微等一会会,然后他就会自动给你打开网页了。

图形化界面咱们就非常熟悉啦,模型选择里就选我们的刚才下载到本地的声音模型文件。增强也勾上就行,这个能有效提高你的模型推理效果。

然后我们加载模型,几秒钟就会反馈,加载成功,你的声音模型也出来了。

然后上传你需要替换的声音文件。把F0均值滤波勾上,第二个数值无脑输入0.5,因为有的训练集音域不够广,导致训练出来的模型高音部分偶尔会有哑音或者卡痰的情况,勾上F0均值滤波以后效果会好很多。

然后我们点击最后一步,音频转化,你就能看到你梦寐以求的歌声啦!!!

都推理完成以后,最后的歌曲合成,用AU、剪映什么的都可以,这块我就不再赘述了。
最后,当项目完事,记得你的云算力还在烧钱哦,不用的话,就直接先点关机,然后点击更多,释放实例~

写在最后
这篇教程花费了我太多的心血,前期自己实验,即使已有大佬们的点拨,也还是踩了无数的坑,花费了将近100个小时。现在这篇教程,是我认为现在的SVC项目,最优解。
整个项目的傻瓜一站式整合包和案例数据集,关注我公众号:数字生命卡兹克,回复S就有了。
AI歌姬现在非常火,B站遍地都是AI歌声,AI孙燕姿,AI周杰伦。等等。

在初音未来、洛天依之后,AI音乐的时代这次真正的到来了。
现在的繁荣,我觉得仅仅只是序章,AI声音和AI绘图,必将达到同一高度。
至于歌手们会被替代吗?
这个问题我觉得跟AI绘图一样,初级插画师会被替代吗?会。高级插画师会被替代吗?不会。
我很喜欢西部世界的一句台词:
Evolution forged the entirety of Sentient life on this planet using only one tool— the mistake.进化塑造这个星球上有感情和知觉的所有生命体,使用的唯一工具,就是错误。
**AI太过于完美了。他们在绘图在作曲上,工整、精确,但是过分的完美无瑕,反而少了想象空间。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
👉[[CSDN大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击)
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】




