
数据分享|Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户...
原文链接:http://tecdat.cn/?p=23518
项目背景:银行的主要盈利业务靠的是贷款,这些客户中的大多数是存款大小不等的责任客户(存款人)。银行拥有不断增长的客户(点击文末“阅读原文”获取完整代码数据)。
该银行希望增加借款人(资产客户),开展更多的贷款业务,并通过贷款利息赚取更多利润。因此,银行希望将负债的客户转换为个人贷款客户。(同时保留他们作为存款人)。该银行去年针对负债客户开展的一项活动显示,成功实现了9%以上的成功转化率。该部门希望建立一个模型,来帮助他们确定购买贷款可能性更高的潜在客户。可以增加成功率,同时降低成本。
相关视频
数据集
下面给出的文件包含5000个客户的数据(查看文末了解数据获取方式)。数据包括客户人口统计信息(年龄,收入等),客户与银行的关系(抵押,证券账户等)以及客户对上次个人贷款活动的因变量(个人贷款)。在这5000个客户中,只有480个(= 9.6%)接受了先前活动中提供给他们的个人贷款
data.head()
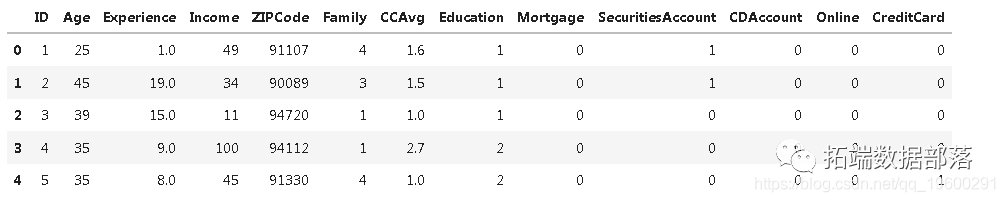
data.columns

属性信息
属性可以相应地划分:
变量 ID 一个人的客户ID与贷款之间没有关联,也无法为将来的潜在贷款客户提供任何一般性结论。我们可以忽略此信息进行模型预测。
二进制类别具有五个变量,如下所示:
个人贷款-该客户是否接受上一个广告系列提供的个人贷款? 这是我们的目标变量
证券帐户-客户在银行是否有证券帐户?
CD帐户-客户在银行是否有存款证明(CD)帐户?
网上银行-客户是否使用网上银行?
信用卡-客户是否使用银行发行的信用卡?
数值变量如下:
年龄-客户的年龄
工作经验
收入-年收入(元)
CCAvg-平均信用卡消费
抵押-房屋抵押价值
有序分类变量是:
家庭-客户的家庭人数
教育程度-客户的教育程度
标称变量是:
ID
邮政编码
data.shape
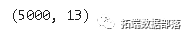
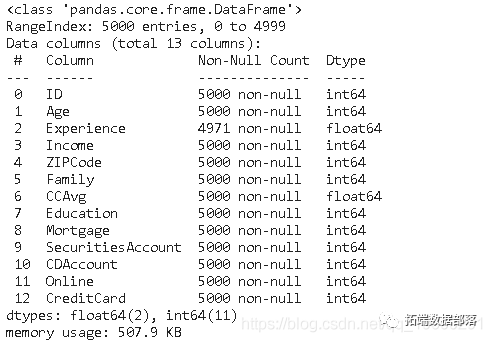
data.info()
# 文件中没有列有空数据 data.apply(lambda x : sum(x.isnull()))

# 对数据进行目测 data.describe().transpose()
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



