
【Python文本数据系列】使用LSTM模型进行文本情感分析(案例+源码)
这是我的第257篇原创文章。
一、引言
当使用深度学习处理文本分类任务时,遵循的流程如下:
-
首先,准备数据,而且数据量要大,才能发挥神经网络的优势;
-
再者,进行文本预处理,将文本数据转化成向量化数据,划分训练集、验证集和测试集;
-
其次,依据分析目标选择合适的神经网络模型,搭建网络、进行参数设置;
-
最后,训练模型,通过评估指标确定模型效果。
本文基于具体具体的实例采用LSTM模型进行文本情感分析。
二、实现过程
2.1 准备数据
读取数据:
reviews = pd.read_csv('dataset.csv') print(reviews.head())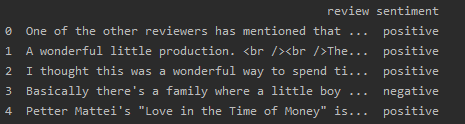
2.2 文本预处理
将影评情感转为0和1的数值,并将影评和情感转化为numpy数组:
reviews['sentiment'] = np.where(reviews['sentiment'] == 'positive', 1, 0) sentences = reviews['review'].to_numpy() labels = reviews['sentiment'].to_numpy()
划分训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(sentences, labels, test_size=0.25) print("Training Data Input Shape: ", X_train.shape) print("Training Data Output Shape: ", y_train.shape) print("Testing Data Input Shape: ", X_test.shape) print("Testing Data Output Shape: ", y_test.shape)构建分词器,构建单词索引,将字符串转化成整数索引组成的列表:
vocab_size = 10000 oov_tok = "" tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok) tokenizer.fit_on_texts(X_train) train_sequences = tokenizer.texts_to_sequences(X_train)
将整数列表转化为二维数值张量,相同的操作对测试集再执行一遍:
sequence_length = 200 train_padded = pad_sequences(train_sequences, maxlen=sequence_length, padding='post', truncating='post') test_sequences = tokenizer.texts_to_sequences(X_test) test_padded = pad_sequences(test_sequences, maxlen=sequence_length, padding='post', truncating='post')
2.3 模型搭建
使用Sequential类定义模型,首先定义Embedding词嵌入层。这是因为深度学习模型只能处理数值张量类型的数据。16表示的是词向量维度。接着定义一个双向LSTM层,定义一个relu激活的全连接层,定义一个使用sigmoid激活的输出层。因为是二分类任务,所以最后输出值为“积极”情感的概率。最后定义损失函数、优化器和评估指标。
embedding_dim = 16 lstm_out = 32 model = Sequential() model.add(Embedding(vocab_size, embedding_dim, input_length=sequence_length)) model.add(Bidirectional(LSTM(lstm_out))) model.add(Dense(10, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
2.4 模型训练及评估
模型自动判断迭代次数,防止过拟合,然后开始模型训练和测试:
checkpoint_filepath = os.getcwd() model_checkpoint_callback = ModelCheckpoint(filepath=checkpoint_filepath, save_weights_only=False, monitor='val_loss', mode='min', save_best_only=True) callbacks = [EarlyStopping(patience=2), model_checkpoint_callback] history = model.fit(train_padded, y_train, epochs=10, validation_data=(test_padded, y_test), callbacks=callbacks) metrics_df = pd.DataFrame(history.history) print(metrics_df)
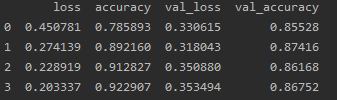
打印模型结果,可以看到我们定义的是迭代10次,实际上4次之后就过拟合了。所以,在没有进行网络参数调优的情况下,获得了87%的准确率,深度学习的能力确实是非常惊艳。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



