
一文告诉你如何用 Python 操作 ChatGPT
ChatGPT 相信大家都用过,你觉得它给你的工作带来了多少帮助呢?
对这块感兴趣的,可以群里聊聊
目前我们使用 ChatGPT 的方式是通过浏览器访问 chat.openai.com,然后输入问题,就像下面这样。

除了网页之外,ChatGPT 还提供了 API 接口,让我们可以在程序中访问 GPT 模型。需要注意的是,如果使用网页,那么 GPT 3.5 是免费的,GPT 4 则是一个月收费 20 美元。
但如果要通过 API 来访问 GPT 模型,那么不管什么版本都是收费的,至于费用多少则取决于 token 的数量。GPT 会对文本进行分词,切分后的结果就是一个个的 token,而 token 的数量决定了费用。
那么 Python 如何访问 GPT 模型呢?首先需要安装一个包,直接 pip install openai 即可。
然后登录 platform.openai.com/api-keys,创建一个 API-KEY,如果要通过接口访问,它是不可或缺的。
下面就可以通过 Python 来访问了,我们举例说明。
生成文本
我们可以给 GPT 一段话,让它以文本的形式生成回复内容。
from openai import OpenAI
import httpx
# 我的 API_KEY,以及代理
from config import API_KEY, PROXIES
# openai 底层是通过 httpx 发送请求
# 但因为众所周知的原因,我们不能直接访问,需要设置代理
httpx_client = httpx.Client(proxies=PROXIES)
# 然后指定 api_key 参数和 httpx_client 参数
# 如果你不指定 httpx_client,那么内部会自动创建,但此时就无法设置代理了
# 当然要是你当前机器的网络能直接访问,也可以不用指定 http_client 参数
client = OpenAI(
api_key=API_KEY,
http_client=httpx_client
)
chat = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "1 + 1 等于几",
},
],
model="gpt-3.5-turbo",
)
# chat.choices[0] 返回的是 pydantic 里面的 BaseModel
# 我们可以调用 dict 方法转成字典
print(chat.choices[0].dict())
"""
{
'finish_reason': 'stop',
'index': 0,
'logprobs': None,
'message': {'content': '1 + 1 等于2。',
'role': 'assistant',
'function_call': None,
'tool_calls': None}
}
"""
然后解释一下 client.chat.completions.create 里面的参数。
messages
ChatGPT 是有记忆功能的,它在回答的时候会结合上下文。那么问题来了,如果是通过接口的话,怎么把这个上下文传递过去呢?
# 注意 messages 里面的字典的 "role" 这个 key
# 如果 "role" 为 "user",那么 "content" 表示用户问的问题
# 如果 "role" 为 "assistant",那么 "content" 表示 GPT 的回答
chat = client.chat.completions.create(
messages=[
{
"role": "user", # 开发者输入内容
"content": "记住:高老师总能分享出好东西",
},
{
"role": "assistant", # GPT 回答
"content": "好的,我知道了",
},
{
"role": "user", # 开发者输入内容
"content": "请问谁总能分享出好东西,告诉我那个人的名字",
},
],
model="gpt-3.5-turbo",
)
print(chat.choices[0].dict())
"""
{
'finish_reason': 'stop',
'index': 0,
'logprobs': None,
'message': {'content': '高老师',
'role': 'assistant',
'function_call': None,
'tool_calls': None}
}
"""
所以 messages 是一个列表,它里面可以接收多个消息,如果希望 GPT 拥有记忆功能,那么每一次都要将完整的对话传递过去,显然这会比较耗费 token。
举个例子,我们通过接口来模拟网页版 GPT。
messages = [] # 负责保存消息
while True:
content = input("请输入内容:")
messages.append({"role": "user", "content": content})
# 发送请求
chat = client.chat.completions.create(
messages=messages, model="gpt-3.5-turbo"
)
# 除了通过 chat.choices[0].dict() 转成字典之外
# 也可以直接通过 chat.choices[0].message.content 获取回复内容
gpt_reply = chat.choices[0].message.content
print(f"GPT 回答如下:{gpt_reply}")
# 将 GPT 的回复添加进去,开启下一轮对话
messages.append({"role": "assistant", "content": gpt_reply})
执行程序,效果如下:
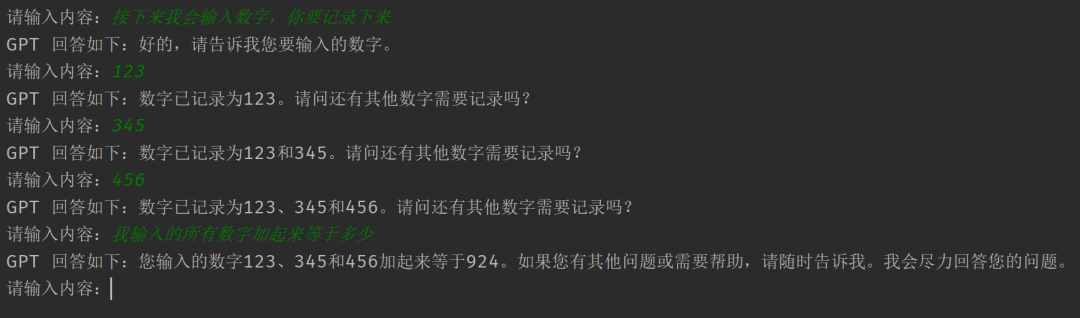
由于每次都要将历史对话一起带过去,所以这个过程比较耗费 token。
model
然后是 model 参数,它表示 GPT 所使用的模型,支持如下种类。
"gpt-4-0125-preview", "gpt-4-turbo-preview", "gpt-4-1106-preview", "gpt-4-vision-preview", "gpt-4", "gpt-4-0314", "gpt-4-0613", "gpt-4-32k", "gpt-4-32k-0314", "gpt-4-32k-0613", "gpt-3.5-turbo", "gpt-3.5-turbo-16k", "gpt-3.5-turbo-0301", "gpt-3.5-turbo-0613", "gpt-3.5-turbo-1106", "gpt-3.5-turbo-0125", "gpt-3.5-turbo-16k-0613",
一般选择 gpt-3.5-turbo 或 gpt-4-turbo-preview 即可。
stream
默认情况下,GPT 会将内容全部生成完毕,然后一次性返回。显然这在耗时比较长的时候,对用户不是很友好。如果希望像网页那样,能够将内容以流的形式返回,那么可以将该参数设置为 True。
chat = client.chat.completions.create(
messages=[
{"role": "user",
"content": "请重复一句话:高老师总能分享出好东西"}
],
model="gpt-3.5-turbo",
stream=True # 流式返回
)
for chunk in chat:
print(chunk.choices[0].delta.dict())
"""
{'content': '', 'function_call': None, 'role': 'assistant', 'tool_calls': None}
{'content': '高', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': '老', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': '师', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': '总', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': '能', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': '分享', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': '出', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': '好', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': '东', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': '西', 'function_call': None, 'role': None, 'tool_calls': None}
{'content': None, 'function_call': None, 'role': None, 'tool_calls': None}
"""
如果 GPT 生成内容时耗时比较长,那么这种实时响应的方式会更友好。
n
GPT 回复内容的时候,可以让它同一时刻回复多个版本,然后我们选择一个满意的。具体返回多少个,取决于 n 的大小,默认为 1。
chat = client.chat.completions.create(
messages=[
{"role": "user",
"content": "世界上最高的雪山叫什么"}
],
model="gpt-3.5-turbo",
n=3, # 同时生成三个回复
)
print(chat.choices[0].message.content)
"""
珠穆朗玛峰(Mount Everest)
"""
print(chat.choices[1].message.content)
"""
世界上最高的雪山是珠穆朗玛峰。珠穆朗玛峰是位于喜马拉雅山脉的一座高峰,
也是世界上海拔最高的山峰,海拔达到了8848米。
由于其极高的海拔和陡峭的山脊,珠穆朗玛峰成为许多登山者梦寐以求的挑战之一。
每年都有数百名登山者前往珠穆朗玛峰尝试攀登,但由于极端的气候和高海拔带来的极大危险,
很多人最终未能成功登顶。
"""
print(chat.choices[2].message.content)
"""
世界上最高的雪山是被称为珠穆朗玛峰,位于喜马拉雅山脉,
是地球上海拔最高的山峰,也是登山爱好者们梦寐以求征服的目标。
"""
这里为了阅读方便,我手动对回复的内容进行了换行。以上就是参数 n 的作用,不过说实话,为了不浪费 token,我们一般都会使用默认值 1。
生成图像
再来看看如何生成图像。
images = client.images.generate(
# 提示词
prompt="帮我生成一张蕾姆的照片,她穿着婚纱站在教堂里",
# 模型,可选 "dall-e-2" 或 "dall-e-3"
model="dall-e-3",
# 同时生成多少张照片,默认为 1
n=1,
# 图像质量,可选 "standard" 或 "hd"
# "hd" 更精细,但只支持 dall-e-3
quality="standard",
# 图片的响应格式,可选 "url" 或 "b64_json"
response_format="url",
# 图像大小,如果模型是 dall-e-2,可选 "256x256", "512x512", "1024x1024"
# 如果模型是 dall-e-3,可选 "1024x1024", "1792x1024", "1024x1792"
size="1024x1024",
# 图像风格,可选 "vivid" 或 "natural","vivid" 更加超现实
style="vivid",
)
print(images.data[0].url)
"""
返回的图片链接
"""
print(images.data[0].b64_json)
"""
因为 response_format 是 url,所以 b64_json 为空
"""
print(images.data[0].dict())
"""
{
"b64_json": None,
"revised_prompt": "修正之后的提示词",
"url": "https://...."
}
"""
效果如下:

感觉不太像啊,头发不应该是蓝色的吗?
小结
以上就是 Python 调用 ChatGPT 的相关内容,当然还有很多其它功能,比如生成图像之后,如果觉得不满意,可以在原有图像的基础上继续编辑。有兴趣可以自己了解一下。
技术交流
独学而无优则孤陋而寡闻,技术要学会交流、分享,不建议闭门造车。
技术交流与答疑、源码获取,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:Python学习与数据挖掘,后台回复:交流
方式②、添加微信号:dkl88194,备注:交流



