
【Linux】基础IO(二)--- 理解内核级和用户级缓冲区、磁盘与ext系列文件系统、inode与软硬连接



🍎作者:阿润菜菜
📖专栏:Linux系统编程
这是目录
- 理解缓冲区
- 1.观察调用C库接口的现象
- 2.理解缓冲区存在的意义(节省进程IO数据的时间)
- 3.调用系统接口对文件进行封装 --- 模仿C库设计接口
- 4.用户级缓冲区和内核级缓冲区的联系(用户级缓冲区在struct FILE结构体,内核级缓冲区在struct file结构体。)
- 理解文件系统
- 1 了解磁盘的物理结构
- 2 磁盘的具体物理存储结构
- 3 进行逻辑抽象
- 4 磁盘文件的管理
- 5 理解ext系列文件系统(以ext2为例)
- inode
- touch一个新文件看看
- inode表中的datablock数组
- 再次理解
- 6 理解软硬理解
理解缓冲区
1.观察调用C库接口的现象
#include #include #include int main() { //C接口 printf("hello printf\n"); fprintf(stdout,"hello fprintf\n"); fputs("hello fputs\n",stdout); //系统接口 const char* msg = "hello write\n"; write(1,msg,strlen(msg));//不要把\0带上 //fork(); return 0; }结果:
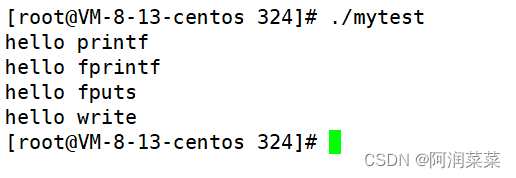
如果没有fork创建子进程的步骤,无论是运行进程还是将运行结果重定向到log.txt文件,两者输出结果都是相同的,均为4条打印信息
若具有了创建子进程的步骤,运行进程后显示到显示器上的结果是4条信息,但如果重定向到log.txt文件中,就变为7条信息,并且可以看到C函数的打印信息被重复打印了两次,而系统调用write接口打印的信息只在log.txt中打印了一次。
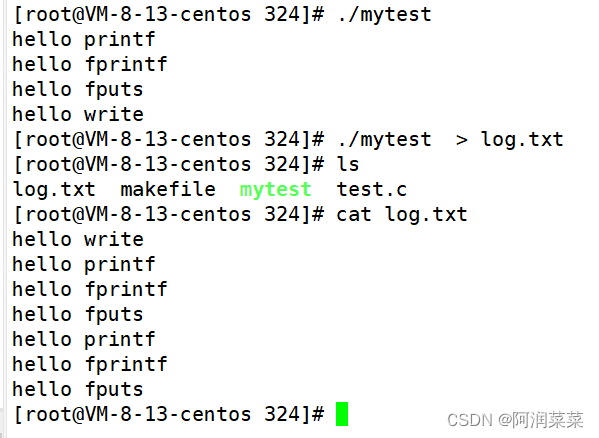
可以猜测到的是,log.txt文件中的C函数打印两次,一定和C语言函数有关,并且和创建子进程也有一定的关系,和进程有关,那是不是和写时拷贝有一些关系呢?这些都是我们的猜测,下面来系统的学习一下缓冲区的相关知识。
2.理解缓冲区存在的意义(节省进程IO数据的时间)
缓冲区是一种用来暂时存储输入或输出数据的内存空间,它可以减少对磁盘或其他低速设备的读写次数,提高计算机的运行效率。缓冲区有三种类型:全缓冲、行缓冲和无缓冲,它们分别在不同的条件下进行实际的I/O操作。缓冲区也可以通过一些函数来设置或刷新。
我们知道,如果直接将内存中的数据写到磁盘文件中,非常的消耗时间,因为磁盘是外设,外设和内存的速度相比差距非常大,一旦开始访问外设,读取数据的效率就会非常低,这个时候在内存中就会开辟一段空间,这段空间就是缓冲区,进程会将内存中的数据拷贝到缓冲区里,最后再从缓冲区中将数据输入到磁盘外设里。所以缓冲区的意义实际上就是为了节省进程进行数据IO的时间。
进程将内存中的数据拷贝到缓冲区,这句话可能有些晦涩难懂,但实际上这个工作就是fwrite做的,与其说fwrite函数是写入到文件的函数,倒不如理解成是拷贝函数,将数据从进程拷贝到“缓冲区”或者“外设”中!!!
语言级缓冲区的刷新策略(三种策略,两种特殊情况)
如果有一块数据想要写入到外设中,是一次性将这么多的数据写到外设中效率高,还是将这么多的数据多次少批量的写入到外设中效率高呢?答案显而易见,当然是前者,因为相较于CPU和内存的访问速度,外设的访问速度非常的慢的,假设数据output到显示器外设的时间是1s,那么可能990ms的时间都在等待显示器就绪,10ms的时间就已经完成数据的准备工作了,所以访问一个外设是非常辛苦的。
缓冲区一定会结合具体的设备,定制自己的刷新策略:
语言级缓冲区的刷新策略是指在使用C语言等高级语言进行输入输出操作时,缓冲区何时将数据真正地传送到目标设备或文件的规则¹。根据不同的设备或文件类型,语言级缓冲区有以下三种刷新策略:
- 全缓冲:只有当缓冲区被填满时才进行实际的I/O操作,这种策略一般用于对磁盘文件的读写,可以减少磁盘的访问次数,提高效率。
- 行缓冲:只有当在输入或输出中遇到换行符时才进行实际的I/O操作,这种策略一般用于标准输入流(stdin)和标准输出流(stdout),可以保证每行数据都及时地显示或读取,提高用户体验。
- 无缓冲:不使用缓冲区,每次输入或输出都直接进行实际的I/O操作,这种策略一般用于标准错误输出流(stderr),可以使得出错信息尽快地反馈给用户,方便调试。
除了以上三种刷新策略外,还有两种特殊情况会导致缓冲区的刷新:
- 用户强制刷新:使用fflush函数或类似的操作来显式地清空缓冲区,不管缓冲区是否已满或遇到换行符。
- 进程退出时:作为main函数return操作的一部分,缓冲区会被自动刷新,以保证所有数据都被正确地传送到目标设备或文件。
无缓冲:一般情况下,立即刷新这样的场景非常少,比如显示错误信息的时候,例如发生标准错误的时候,编译器会立即将错误信息输出到显示器文件上,也就是外设当中,而不是将信息先存放到缓冲区当中,应当是立即刷新到显示器文件中。
行缓冲:我们知道带\n时数据就会立马显示到显示器上,而不带\n时,就只能通过fflush的方法来刷新数据。上面我们所说的缓冲区数据积累满之后在刷新,本身就是效率很高的刷新策略,那为什么显示器的刷新策略是行缓冲而不是全缓冲呢?是因为显示器设备太特殊了,显示器不是给其他设备或机器看的,而是给人看的,而人的阅读习惯就是从左向右按照行来读取,所以为了保证显示器的刷新效率和提升用户体验,那么显示器最好就是按照行缓冲策略来刷新数据。
如果我们写入数据没有带 \n 会发生什么 — 不发生刷新 — 不进行写入 不进行IO 不进行系统调用 —所以此时my_write()函数成本很低,函数调用会非常快,数据暂存在缓冲区里。所以可以在缓冲区积压多份数据,统一进行刷新写入 — 本质:一次IO可以IO更多的数据,提高IO的效率
全缓冲:全缓冲的效率毫无疑问是最高的,因为只需要等待一次设备就绪即可,其他刷新策略等待的次数可就不止一次了,在磁盘文件读写的时候,采用的策略就是全缓冲。
3.调用系统接口对文件进行封装 — 模仿C库设计接口
我们将自主封装fopen_,fwrite_,fclose_,fflush_四个C语言库接口,可以更加清楚的了解到,C语言的IO函数在被调用时,对数据操作的细节和流程,以及当满足刷新策略时,fwite函数是怎么做的,fclose实际内部隐式的包含了fflush,清空缓冲区时利用了惰性释放的方式,这些代码让我们真正从原理上理解了C语言的缓冲区在数据IO时,具体是怎么做的,以及FILE结构体是如何封装的。同时也让我们看到了系统调用write可以直接将数据写到内核缓冲区。
#pragma once #include #include #include #include #include #include #include #include #include #define SIZE 1024 #define SYNC_NOW (1 int flags;//刷新策略 int fileno;//文件描述符 int capacity;//buffer总容量 int size;//buffer当前使用量 char buffer[SIZE]; }FILE_; FILE_ *fopen_(const char *path_name, const char *mode); void fwrite_(const void *ptr, int num, FILE_ *fp); void fflush_(FILE_ *fp); void fclose_(FILE_ *fp); int flags = 0; int default_mode = 0666; if(strcmp(mode,"r") == 0) { flags |= O_RDONLY; } else if(strcmp(mode,"w") == 0) { flags |= (O_WRONLY | O_CREAT | O_TRUNC); } else if(strcmp(mode,"a") == 0) { flags |= (O_WRONLY | O_CREAT | O_APPEND); } umask(0000); int fd = 0; if(flags & O_RDONLY) fd = open(path_name ,flags); else fd = open(path_name, flags,default_mode); if(fd怎么刷新 ---- fflush() 刷新文件流信息 — 自己实现
实现 my_fflush()
最基本的刷新策略 — 简单调用系统接口
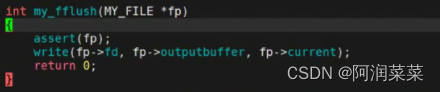
void fflush_(FILE_ *fp) { //fflush做两件事情,1.用户缓冲区数据->内核 2.内核数据->外设 //系统调用write可以直接将数据写到内核缓冲区里。 if( fp->size > 0 ) write(fp->fileno, fp->buffer,fp->size); //实际上write可以将任何数据直接写到内核缓冲区中。 fsync(fp->fileno); //将内核缓冲区数据强制性刷新到外设里 fp->size = 0;//清空缓冲区 }fwrite()— 内含缓冲区
void fwrite_(const void *ptr, int num, FILE_ *fp) { //1.将数据写入到语言级缓冲区里 memcpy(fp->buffer + fp->size, ptr, num); //加fp->size的原因是因为打开文件的方式有可能是追加。 //这里不考虑缓冲区溢出的问题,如果你想考虑可以通过realloc的方式来解决, fp->size += num;//更新FILE_中的buffer当前使用量 //2.判断是否满足刷新策略,如果满足那就刷新,不满足就不刷新 if(fp->flags & SYNC_NOW) { write(fp->fileno, fp->buffer, num); fp->size = 0;//相当于清空缓冲区,下次写入时直接覆盖原有缓冲区内容 //惰性释放 } else if(fp->flags & SYNC_LINE) { //暂时不考虑abc\ndef这种情况,处理这种情况可以利用for循环遍历,记录\n位置并将\n之前的数据刷新到磁盘外设文件中。 if(fp->buffer[fp->size-1] == '\n') { write(fp->fileno,fp->buffer,fp->size); fp->size = 0;//清空缓冲区 } } else if(fp->flags & SYNC_FULL) { if(fp->size == fp->capacity) { write(fp->fileno, fp->buffer, num); fp->size = 0;//清空缓冲区 } } }1.你以为的是写入文件流里吗?— 实际是写入了文件FILE结构体的缓冲区buffer里
2. 判断缓冲区剩余大小与需要写入大小的比较情况 ---- 1.足以容纳 ,直接内存级拷贝,memcpy()到buffer的current位置 ,最后记得更新计数器字段 2.不能一次性容纳,剩余空间多大,拷贝多少 my_size大小,然后更新数据字段 — 计数器字段
4.用户级缓冲区和内核级缓冲区的联系(用户级缓冲区在struct FILE结构体,内核级缓冲区在struct file结构体。)
历史上我们指的缓冲区指的是:用户级缓冲区,这是语言库提供的
那么一个完整的缓冲区理解是什么呢?
认识强制刷新系统调用 — fsyns() 直接刷新打印到显示器
fsync ()是一个系统调用函数,它的作用是将内核级缓冲区中的数据同步到磁盘或其他持久化设备上,以保证数据的完整性和一致性¹²。fsync ()的原型是:
#include int fsync (int fd);
其中,fd是一个文件描述符,它指向要同步的文件。fsync ()会等待设备报告同步完成后才返回。如果成功,fsync ()返回0,如果失败,返回-1,并设置errno来表示错误原因。
注意,fsync ()不仅同步文件数据,还同步文件元数据,如文件大小,修改时间等。如果只想同步文件数据,可以使用fdatasync ()函数。另外,fsync ()不一定保证目录项中包含该文件的条目也同步到磁盘上,为了确保这一点,还需要对目录文件进行显式的fsync ()。
write写入接口,实际上并不是直接将数据写到磁盘中,而是将数据写到内核缓冲区里面,而且fflush也不是将数据刷新到磁盘里,而是将数据从语言级缓冲区刷新到内核缓冲区里,这个内核缓冲区就在OS中的struct file结构体里面,最后由操作系统自主决定将内核缓冲区的数据刷新到磁盘上。我们上面所谈到的刷新策略都是FILE结构体里面的刷新策略,而内核缓冲区的刷新策略是非常复杂的,不像我们上面所说的那样简单,因为操作系统需要兼顾整个内存的使用情况,来决定是否进行内核缓冲区的刷新,然而这却是非常复杂的。
所以C函数打印的一个字符串,首先需要被拷贝到FILE中的用户级缓冲区里,然后通过系统调用write再将数据从FILE缓冲区中刷新到file结构体中的内核级缓冲区,最后再由操作系统自主决定将内核级缓冲区的数据刷新到外设物理媒介上。
内核缓冲区刷新数据到磁盘上,这个过程和用户毫无关系。
系统调用接口fsync可以用来同步文件内核状态到存储设备中,说白了就是强制刷新内核缓冲区的数据到磁盘(物理媒介)上。
fwrite将数据拷贝到用户级缓冲区,write将数据拷贝到内核级缓冲区,本质上fwrite和write函数都是拷贝函数,fsync将数据从内核缓冲区写入到磁盘外设中。
真正意义上的fflush不仅要将数据从用户缓冲区依靠write拷贝到内核缓冲区,还要将数据从内核缓冲区依靠fsync刷新到外设中
fsync ()和fflush ()有以下几点区别:
- fsync ()是一个系统调用函数,它的作用是将内核级缓冲区中的数据同步到磁盘或其他持久化设备上,它接受一个文件描述符作为参数。
- fflush ()是一个标准库函数,它的作用是将用户级缓冲区中的数据刷新到内核级缓冲区中,它接受一个FILE*指针作为参数 。
- fsync ()和fflush ()的功能不同,fsync ()保证数据已经写入到物理设备上,而fflush ()只保证数据已经传递给操作系统³。
- fsync ()和fflush ()的使用场景不同,fsync ()一般用于需要确保数据完整性和一致性的情况,如数据库事务,日志记录等,而fflush ()一般用于需要及时显示或读取数据的情况,如标准输入输出流等。
- fsync ()和fflush ()的返回值不同,fsync ()返回0表示成功,返回-1表示失败,并设置errno来表示错误原因,而fflush ()返回0表示成功,返回EOF表示失败,并设置errno来表示错误原因。
用户级缓冲区和内核级缓冲区的联系是:
- 用户级缓冲区是用户进程为了减少系统调用次数而设置的一块内存空间,它可以暂时存储用户进程和操作系统之间交换的数据。
- 内核级缓冲区是操作系统为了提高设备I/O效率而设置的一块内存空间,它可以暂时存储操作系统和设备之间交换的数据。
- 用户级缓冲区和内核级缓冲区之间的数据传输需要用户进程主动调用read或write等函数来完成,这些函数会调用操作系统提供的系统调用接口,从而触发内核态和用户态的切换。
- 用户级缓冲区在struct FILE结构体中,它是一个typedef定义的类型,通常是一个结构体,它包含了一些与文件相关的信息,如文件指针,缓冲区指针,缓冲区大小,文件标志等 。
- 内核级缓冲区在struct file结构体中,它是一个内核定义的类型,它包含了一些与文件相关的信息,如文件引用计数,文件操作函数指针,文件位置,文件状态标志等 。
理解文件系统
之前讲的都是一个文件被打开的相关知识点,那不打开的文件呢?反正一定不在内存中,根据冯诺依曼体系,这些文件只能在磁盘等外设中静静的等待着,只有被打开时才会被加载到内存
那么如何理解磁盘文件这些没有被打开的文件呢?没有被打开的文件有什么问题呢?
- 如何被合理存储问题 ---- 如学校菜鸟驿站案例
- 主要是为了解决:快速定位 快速读取和快速写入
1 了解磁盘的物理结构
磁盘是我们计算机中唯一一个机械设备,同时它还是外设!当然现在我们基本上都是固态硬盘,而且我们知道磁盘的访问速度相当于内存或者CPU是非常慢的

- 磁盘是指利用磁记录技术存储数据的存储器。磁盘是计算机主要的存储介质,可以存储大量的二进制数据,并且断电后也能保持数据不丢失。
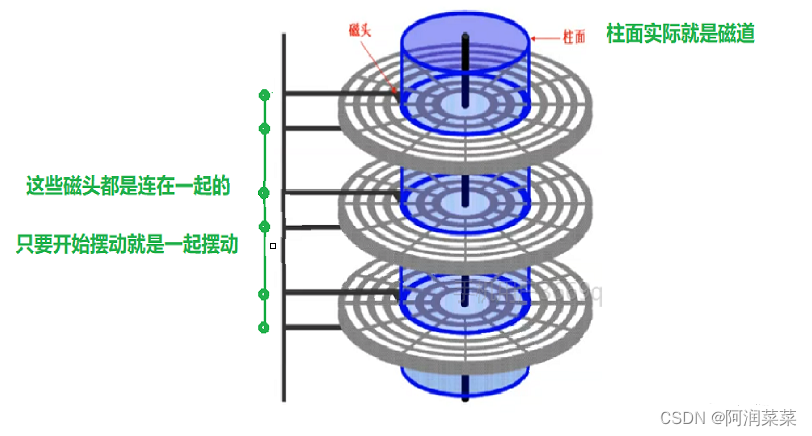
- 磁盘主要由磁盘盘片、磁头、主轴与传动轴等组成,数据就存放在磁盘盘片中。磁盘盘片上划分为磁道、扇区、柱面等逻辑结构,用来定位和存取数据。
- 磁盘不能直接使用,必须对硬盘进行分割,分割成的一块一块的硬盘区域就是磁盘分区。磁盘分区可以提高数据的安全性和管理效率。
- 本地磁盘是指安装于同一台计算机主板上,不可随意插拔、移动的磁盘,一般包括计算机操作系统所在分区及其他分区。
磁盘的物理结构 — 硬件层面理解

- 磁盘是指利用磁记录技术存储数据的存储器,磁盘主要由磁盘盘片、磁头、主轴与传动轴等组成,数据就存放在磁盘盘片中。
- 磁盘盘片上划分为磁道、扇区、柱面等逻辑结构,用来定位和存取数据。磁道是单个盘面上的同心圆,扇区是磁道被等分为若干个弧段,柱面是由不同盘片的面,但处于同一半径圆的多个磁道组成的一个圆柱面。
- 磁头是硬盘中对盘片进行读写工作的工具,是硬盘中最精密的部位之一。磁头是用线圈缠绕在磁芯上制成的,工作原理则是利用特殊材料的电阻值会随着磁场变化的原理来读写盘片上的数据³。
- 磁头的移动是靠磁头驱动组件实现的,硬盘寻道时间的长短与磁头驱动组件关系非常密切。磁头驱动组件由电磁线圈电机、磁头驱动小车、防震动装置构成,高精度的轻型磁头驱动机构能够对磁头进行正确的驱动和定位,并能在很短时间内精确定位系统指令指定的磁道,保证数据读写的可靠性³。
- 主轴组件包括主轴部件轴瓦和驱动电机等。随着硬盘容量的扩大和速度的提高,主轴电机的速度也在不断提升,有厂商开始采用精密机械工业的液态轴承机电技术,这种技术的应用有效地降低了硬盘工作噪音³。
- 前置放大电路控制磁头感应的信号、主轴电机调速、磁头驱动和伺服定位等,由于磁头读取的信号微弱,将放大电路密封在腔体内可减少外来信号的干扰, 提高操作指令的准确性³。
为什么磁头和盘面不能挨着? 防止盘面被刮花数据丢失
为什么机械磁盘被淘汰? — 物理结构导致的 比如磁头和盘片经常碰撞导致数据丢失操作系统无法启动
磁盘的伺服电路
向磁盘写入的本质:磁化 — 改变磁极 — 达成微观的一个比特位的读写(0 1)
怎么消磁:加热 — 所以不能摩擦
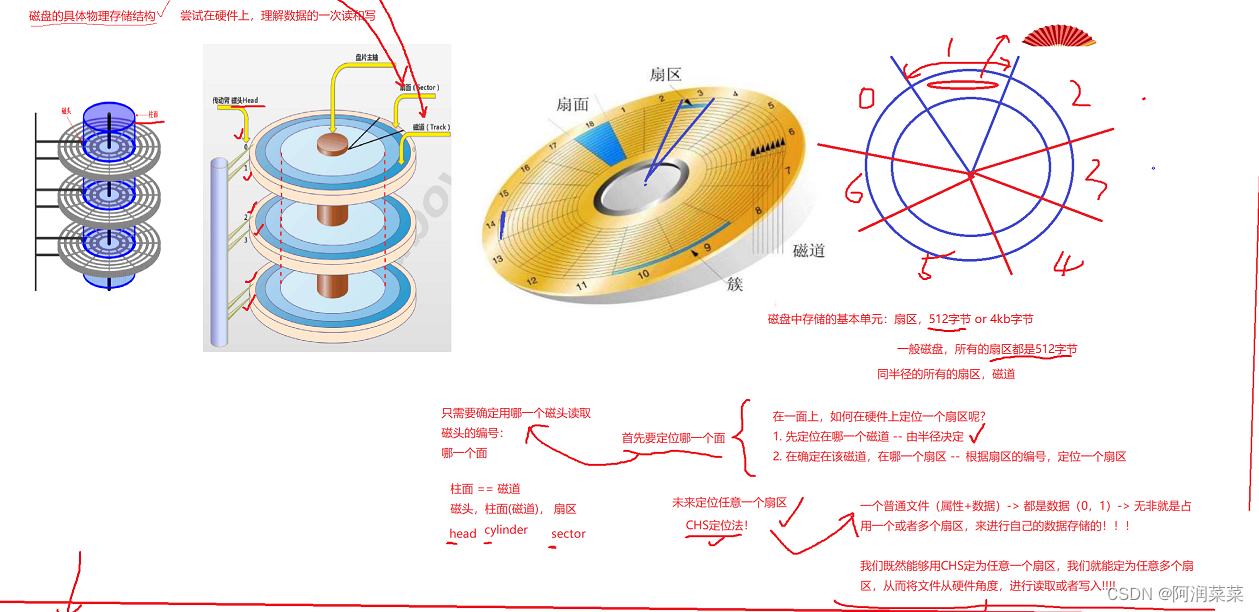
2 磁盘的具体物理存储结构
存储的基本单元:扇区 ---- 一般磁盘,所有的扇区都是512字节
同半径的所有扇区 — 称为 : 磁道
如何定位一个扇区?
- 磁盘中定位一个扇区需要知道它所在的柱面号、磁头号和扇区号,这三个参数构成了磁盘的物理地址。
- 磁盘中定位一个扇区的过程分为两步:第一步是寻道,即将磁头移动到目标柱面上;第二步是旋转延迟,即等待目标扇区旋转到磁头下方。
- 磁盘中定位一个扇区的时间取决于寻道时间和旋转延迟时间,寻道时间与磁头移动的距离有关,旋转延迟时间与磁盘的转速有关。
- 磁盘中定位一个扇区的方法有多种,常见的有CHS(柱面-磁头-扇区)方法、LBA(逻辑块地址)方法和GPT(全局唯一标识分区表)方法。
3 进行逻辑抽象
谈到过物理层面定位某个扇区运用的算法是CHS定位法,那么LBA如何转到CHS定位呢?其实很简单,只需通过一些计算方式就可以进行转换,下面图片中的计算方法是捏出来的数据,方便大家理解LBA转到CHS定位的过程。
H磁头用来判断是哪个扇面,C柱面用来判断是哪个磁道,S就是确定在具体扇面的具体磁道中的具体某个扇区,这些工作在软件层面都可以解决,解决的过程其实就是LBA转到CHS的过程。
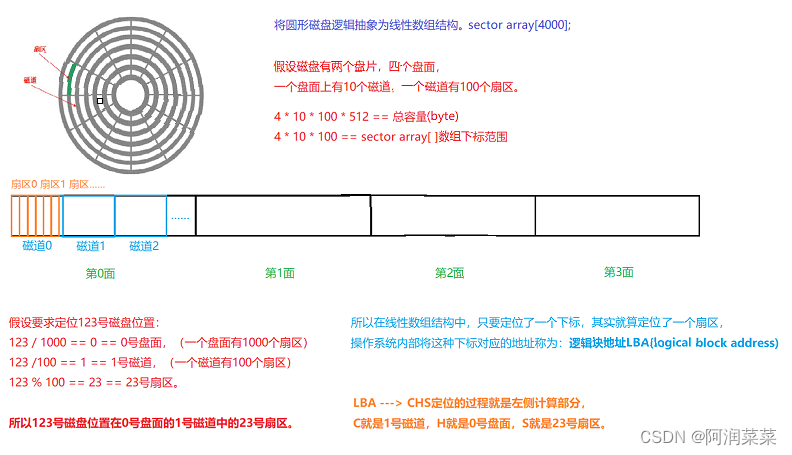
为什么OS要进行磁盘的逻辑抽象呢?直接用CHS定位不行吗?
其实有两个原因,第一点是便于管理:在软件层面OS只要管理一个线性数组就可以了,而在物理层面管理一个三维立体结构可不是轻松的。最重要的第二点是:不想让OS的代码和硬件强耦合,因为如果强耦合,底层换了存储设备由SSD换成HHD,OS的代码就失效了,而如果进行逻辑抽象的话,底层无论更换任何存储设备,在操作系统看来都不过只是一个线性数组结构罢了,适应性很强。
4 磁盘文件的管理
磁盘文件的管理思想 — 分而治之
操作系统对磁盘空间的抽象 — 数据块 一般是4kb大小
至于为什么选择4KB为基本单位,之前的计算机科学家做过测试,发现以4KB作为IO的基本单位,性能是最好的,所以文件系统就采用了4KB了,这背后都是有论文作为依据的。
早些年诞生一项理论,叫做局部性原理,这项理论证明,当计算机访问某些数据时,极大可能访问到它周围的数据,所以在进程IO数据时,多加载一些数据是有助于提高操作系统的效率的,并且在一定程度上减缓了数据多次IO的过程。顺序表相比链表优势便在于数据更加集中,缓存时数据的命中率更高。
所以多加载数据的原因就是,达到预加载数据和以空间换时间的目的!!!
所以真实的内存被划分是以4KB作为基本数据大小的空间,16G内存的笔记本中大约有4194304个基本数据大小的空间,这些空间叫做页框,就是内存中一个个的块。
磁盘中的文件,尤其是可执行文件,实际上也是按照4KB大小划分为一个个的块,可执行文件中的一个个块叫做页帧。
所以从磁盘中加载数据到内存时,就是分为一个个的块进行加载,将页帧的数据加载到页框里,这就是文件系统和内存管理之间的耦合,他们都是以4KB为大小进行划分的。
磁盘分区的各个区的管理策略都是相同的,只要把管理方法ctrl+c,ctrl+v就可以解决其他区的管理问题了,区域中细分的组之间的管理策略也是如此,所以在管理时,我们只要管理好细分的组便可以管理好磁盘这一大块空间了。
从磁盘文件管理角度为什么有类型?操作系统的访问方式就是起始地址加上偏移地址这么访问的。所以只需要知道数据块的起始地址即可访问对应数据内容
所以块的地址本质就是:数组的一个下标,N,我们采用线性下标N的方式,就能定位任何一个块了
介绍下位图:
文件系统中的位图是一种数据结构,用来表示有限域中的稠集,即每个元素至少出现一次,没有其他的数据和元素相关联。文件系统中的位图通常用来标记磁盘空间的分配情况,每个比特位对应一个磁盘块,0表示空闲,1表示占用。
5 理解ext系列文件系统(以ext2为例)
我们可以通过ls -l读取存储在磁盘上的文件信息,然后显示出来
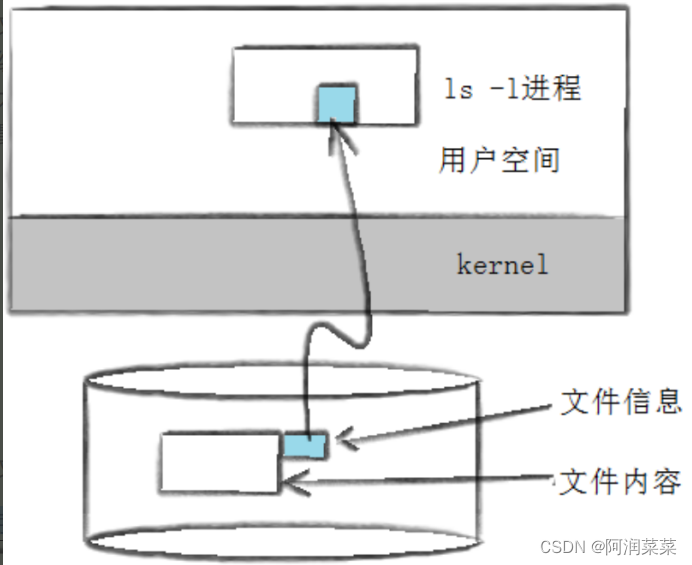
其实这个信息除了通过这种方式来读取,还有一个stat命令能够看到更多信息:
[root@localhost linux]# stat test.c File: "test.c" Size: 654 Blocks: 8 IO Block: 4096 普通文件 Device: 802h/2050d Inode: 263715 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2017-09-13 14:56:57.059012947 +0800 Modify: 2017-09-13 14:56:40.067012944 +0800 Change: 2017-09-13 14:56:40.069012948 +0800
inode
inode表是文件系统中的一种数据结构,它存放了文件的元数据信息,如inode号、大小、属性、时间等。 inode表中的每个条目叫做inode,它是文件或目录在一个文件系统中的唯一标识。
inode表的内容可以用·stat命令或ls -i命令来查看。 例如,如果你有一个文件叫file.txt,你可以用stat file.txt来查看它的inode信息,如下:
$ stat file.txt File: file.txt Size: 13 Blocks: 8 IO Block: 4096 regular file Device: fd02h/64770d Inode: 123456 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2022-10-05 10:00:00.000000000 +0800 Modify: 2022-10-05 10:00:00.000000000 +0800 Change: 2022-10-05 10:00:00.000000000 +0800 Birth: -
从上面的输出可以看出,file.txt的inode号是123456,它的大小是13字节,它的权限是0644,它的所有者是root,它的修改时间是2022-10-05 10:00:00等等。
你也可以用ls -i file.txt来查看它的inode号,如下:
$ ls -i file.txt 123456 file.txt
从上面的输出可以看出,file.txt的inode号是123456。
为了能解释清楚inode我们先简单了解一下文件系统
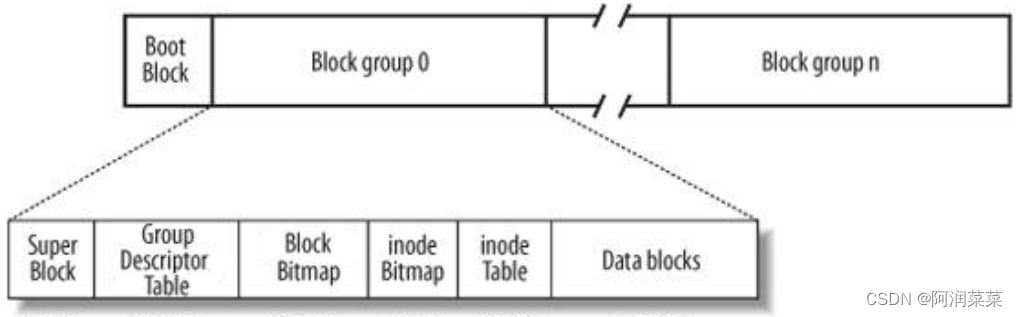
Linux ext2文件系统,上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的block。一个block的大小是由格式化的时候确定的,并且不可以更改。例如mke2fs的-b选项可以设定block大小为1024、2048或4096字节。而上图中启动块(Boot Block)的大小是确定的.
- 块组 Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。如政府管理各区的例子
-
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个 文件系统结构就被破坏了
-
GDT,Group Descriptor Table:块组描述符,描述块组属性信息,有兴趣的同学可以在了解一下 块位图(BlockBitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没 有被占用
-
inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。
-
i节点表:存放文件属性 如 文件大小,所有者,最近修改时间等
-
数据区:存放文件内容
-
可以说super block时文件系统的控制块 — 代表整个分区(或者说整个文件系统)的情况 保存文件系统的所有属性信息 (很重要!)---- 多份super block 就是为了防止故障发生,整个分区都不可以使用,起备份的作用!同时每个分区又分为不同的块组(block group),每个块组中都存在超级块,块组描述符— 记录块组宏各个部分的位置和大小,如位图、inode表等;数据块位图 — 记录块组中哪些数据块已经被使用,哪些没被使用;inode位图 – 记录了哪些inode已经被使用,哪些没有; inode表 — 存放了文件的元数据信息,如inode号、大小、属性、时间等;以及数据块 —存放了文件的实际内容或者指向其他数据块的指针(当然数据块data blocks 占据块组的百分之九十九的内存)
-
inode bit map 和block bit map的关系是什么 ?并行关系 一个管理inode的属性 一个管理数据
-
查看inode ---- ls -il
-
怎么理解inode?

touch一个新文件看看
将属性和数据分开存放的想法看起来很简单,但实际上是如何工作的呢?我们通过touch一个新文件来看看如何工作
[root@localhost linux]# touch abc [root@localhost linux]# ls -i abc 263466 abc
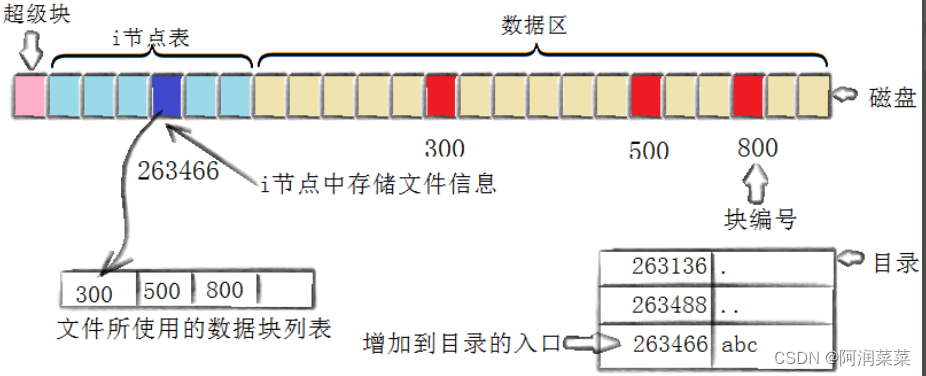 创建一个新文件主要有一下4个操作:
创建一个新文件主要有一下4个操作:- 存储属性
内核先找到一个空闲的i节点(这里是263466)。内核把文件信息记录到其中。
- 存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:300,500,800。将内核缓冲区的第一块数据复制到300,下一块复制到500,以此类推。
- 记录分配情况
文件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。
- 添加文件名到目录
新的文件名abc。linux如何在当前的目录中记录这个文件?内核将入口(263466,abc)添加到目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
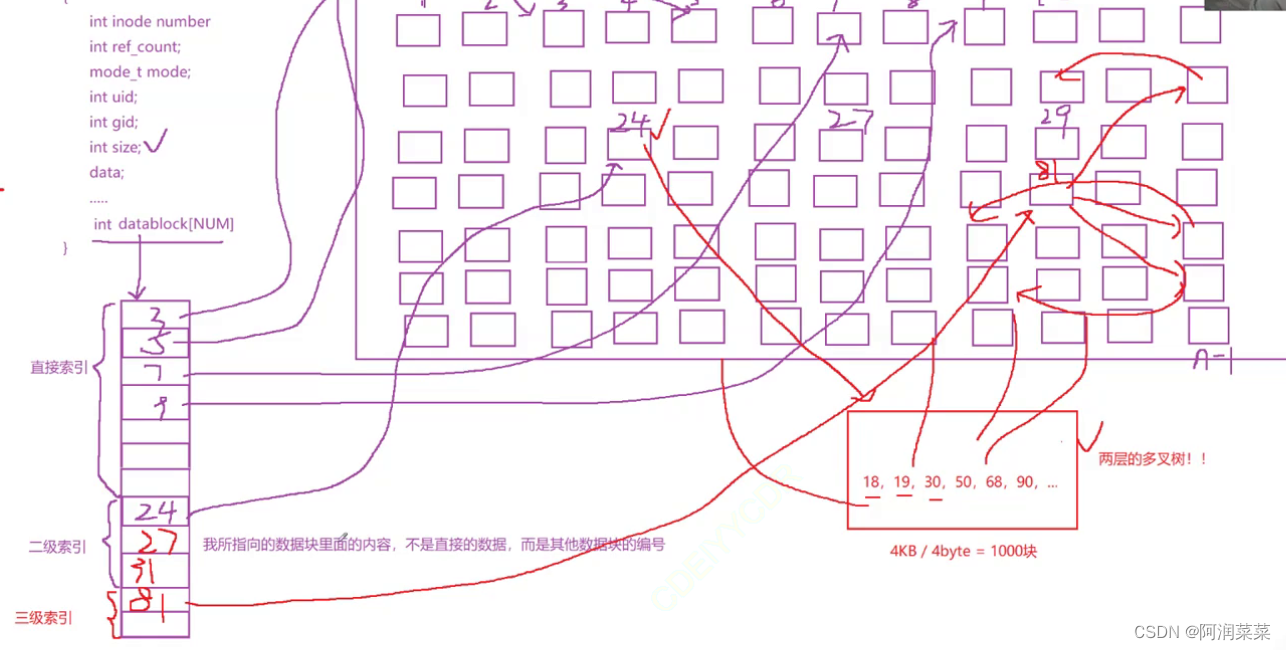
inode表中的datablock数组
inode表中的datablock数组是一个指针数组,它用来存储文件的数据块的地址。datablock数组的长度和文件系统的类型有关,一般有12个或15个指针。
datablock数组中的指针分为以下几种类型:
- 直接指针:直接指向文件的数据块,一般有12个,可以存储48KB(假设块大小为4KB)的文件数据。
- 间接指针:指向一个间接块,间接块中存放了多个直接指针,一般有一个,可以存储4MB(假设块大小为4KB,每个指针占4字节)的文件数据。
- 双重间接指针:指向一个双重间接块,双重间接块中存放了多个间接指针,一般有一个,可以存储4GB(假设块大小为4KB,每个指针占4字节)的文件数据。
- 三重间接指针:指向一个三重间接块,三重间接块中存放了多个双重间接指针,一般有一个,可以存储4TB(假设块大小为4KB,每个指针占4字节)的文件数据。
这样的结构可以让inode表中的inode占用较少的空间,同时可以支持较大的文件。
再次理解
如何理解文件名 ---- 在目录文件内,文件名和inode互为key值 即映射关系

如何理解文件访问 — 一个目录也是一个文件,也有inode

如何理解文件的增删查改
- 查就是通过目录文件的数据信息进行查找
- 怎么删除文件 — 为什么删除这么快 — 很简单,因为只是修改了inode位图

inode 不会被删 只会被覆盖 ---- bit map 置0 即删除 等待下次覆盖
格式化是什么? 其实就是对属性信息做操作,如bit map清空,描述符初始化
6 理解软硬理解
软硬链接是Linux系统中的两种文件链接方式,它们可以为一个文件创建多个有效的路径名。
软链接(也叫符号链接)类似于Windows系统中的快捷方式,它是一个特殊的文件,其中包含了另一个文件的路径名。软链接可以跨文件系统,可以对目录或不存在的文件名进行链接,但是如果原文件被删除了,软链接就会失效。
硬链接是指为一个文件创建一个或多个文件名,它们都指向同一个索引节点(inode),也就是同一个数据块。 硬链接不能跨文件系统,不能对目录进行链接,也不能对不存在的文件名进行链接,但是如果原文件被删除了,硬链接仍然有效。
在Linux系统中,可以用ln命令来创建软硬链接。
- 创建软链接:ln -s 源文件 目标文件
- 创建硬链接:ln 源文件 目标文件
-
软链接是一个独立的链接文件,有自己的inode number ,所以必有自己的inode属性和内容
-
软连接应用场景 — 本质其实就相当于快捷方式
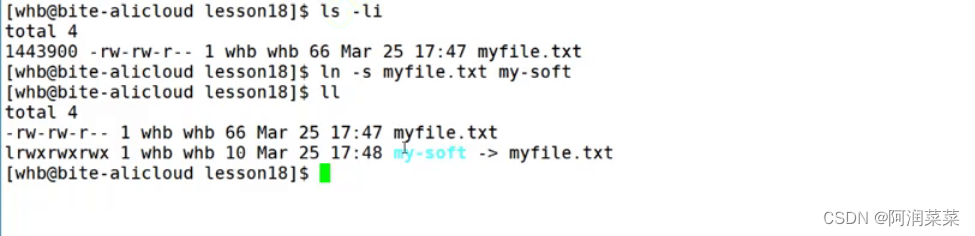
那软连接的属性我们知道了,它的内容放的是什么呢?就是指向源文件的地址字符串
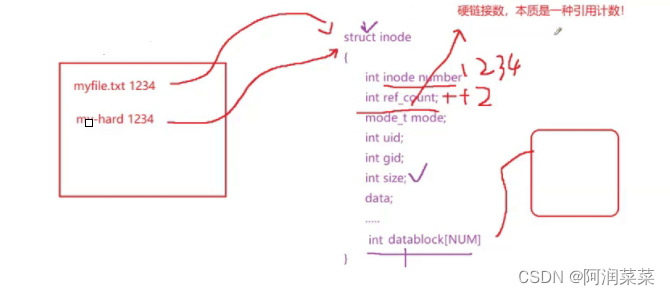
其中ref count 引用计数器 — 代表有多少文件指向我 — 当为0时就代表文件已经被删掉
软链接文件是一个独立的文件,有自己的inode节点,这个文件数据中保存的是源文件路径,通过保存的路径访问源文件,因此源文件被删除则无法再访问,通过路径将找不到源文件,这时候软链接就会失效。
-
软链接文件是一个独立的文件有自己的inode节点,文件中保存了源文件路径,通过数据中保存的源文件路径访问源文件
-
硬链接是文件的一个目录项,与源文件共用同一个inode节点,直接通过自己的inode节点访问源文件(其实本质上来说与源文件没区别)
-
硬链接被删除,则inode中的链接数-1,并不会直接删除文件数据,而是等链接数为0的时候才会实际删除对应文件的inode,将所占用数据块置为空闲

-
-
-
- 块组 Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。如政府管理各区的例子







