
YOLOv5改进 | 主干网络 | 用EfficientNet卷积替换backbone【教程+代码 】



| 💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 |
在YOLOv5的GFLOPs计算量中,卷积占了其中大多数的比列,为了减少计算量,研究人员提出了用EfficientNet代替backbone。本文给大家带来的教程是将原来的主干网络替换为EfficientNet。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址: YOLOv5改进+入门——持续更新各种有效涨点方法 点击即可跳转
文章目录
- 1. 原理
- 2.代码实现
- 2.1 将EfficientNet添加到YOLOv5中
- 2.2 新增yaml文件
- 2.3 注册模块
- 2.4 执行程序
- 3. 完整代码分享
- 4.GFLOPs对比
- 5. 总结
1. 原理

论文地址:EfficientNet论文点击即可跳转
官方代码:https://github.com/tensorflow/tpu/tree/ master/models/official/efficientnet
EfficientNet 是一个卷积神经网络架构,旨在通过同时调整深度、宽度和分辨率来实现更好的准确性和效率。它由谷歌的Mingxing Tan和Quoc V. Le在题为《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》的论文中提出。
EfficientNet主要的关键组件和概念:
-
复合缩放:EfficientNet引入了一种新的缩放方法,该方法使用复合系数均匀地缩放网络宽度、深度和分辨率。传统上,模型是通过简单增加这些维度中的一个来进行缩放的,这可能导致性能不佳。EfficientNet使用复合系数 φ 来统一地缩放这些维度。
-
架构设计:EfficientNet从基线网络架构开始,然后使用复合缩放方法进行扩展。基线架构类似于移动反向瓶颈卷积(MBConv)架构,它由带有深度可分离卷积的反向残差块组成。
-
深度可分离卷积:EfficientNet广泛使用深度可分离卷积。它将标准卷积操作分解为深度卷积(分别在每个输入通道上操作)后跟点卷积(用于组合输出的1x1卷积)。这样做既减少了计算成本,又保留了表示能力。
-
高效缩放:EfficientNet通过高效地缩放网络宽度、深度和分辨率来实现最先进的性能。通过同时缩放所有这些维度,它有效地平衡了模型容量和计算成本。
-
模型变种:EfficientNet有几个变种,如EfficientNet-B0到B7,代表不同的缩放级别。B0是最小且计算成本最低的变种,而B7是最大且计算成本最高的变种。
-
迁移学习:EfficientNet模型通常在大规模图像数据集(如ImageNet)上预先训练,然后使用较小的数据集进行特定任务的微调。使用EfficientNet的迁移学习在各种计算机视觉任务上都被证明是非常有效的,尤其是在有限的计算资源下达到最先进的性能。
由于其优越的性能和效率平衡,EfficientNet已成为计算机视觉任务的热门选择。其可扩展性使其适用于从手机到云服务器的各种设备,并且仍然能够实现出色的准确性。

2.代码实现
2.1 将EfficientNet添加到YOLOv5中
关键步骤一: 将下面代码粘贴到/projects/yolov5-6.1/models/common.py文件中
*注:代码冗长,这里只放置了部分代码,完整代码请查看文章末尾的完整代码分享
class stem(nn.Module): def __init__(self, c1, c2, act='ReLU6'): super().__init__() self.conv = nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False) self.bn = nn.BatchNorm2d(num_features=c2) if act == 'ReLU6': self.act = nn.ReLU6(inplace=True) def forward(self, x): return self.act(self.bn(self.conv(x))) class MBConvBlock(nn.Module): def __init__(self, inp, final_oup, k, s, expand_ratio, drop_connect_rate, has_se=False): super(MBConvBlock, self).__init__() self._momentum = 0.01 self._epsilon = 1e-3 self.input_filters = inp self.output_filters = final_oup self.stride = s self.expand_ratio = expand_ratio self.has_se = has_se self.id_skip = True # skip connection and drop connect se_ratio = 0.25 # Expansion phase oup = inp * expand_ratio # number of output channels if expand_ratio != 1: self._expand_conv = nn.Conv2d(in_channels=inp, out_channels=oup, kernel_size=1, bias=False) self._bn0 = nn.BatchNorm2d(num_features=oup, momentum=self._momentum, eps=self._epsilon) # Depthwise convolution phase self._depthwise_conv = nn.Conv2d( in_channels=oup, out_channels=oup, groups=oup, # groups makes it depthwise kernel_size=k, padding=(k - 1) // 2, stride=s, bias=False) self._bn1 = nn.BatchNorm2d(num_features=oup, momentum=self._momentum, eps=self._epsilon) # Squeeze and Excitation layer, if desired if self.has_se: num_squeezed_channels = max(1, int(inp * se_ratio)) self.se = SeBlock(oup, 4) # Output phase self._project_conv = nn.Conv2d(in_channels=oup, out_channels=final_oup, kernel_size=1, bias=False) self._bn2 = nn.BatchNorm2d(num_features=final_oup, momentum=self._momentum, eps=self._epsilon) self._relu = nn.ReLU6(inplace=True) self.drop_connect = drop_connect(drop_connect_rate) def forward(self, x, drop_connect_rate=None): """ :param x: input tensor :param drop_connect_rate: drop connect rate (float, between 0 and 1) :return: output of block """ # Expansion and Depthwise Convolution identity = x if self.expand_ratio != 1: x = self._relu(self._bn0(self._expand_conv(x))) x = self._relu(self._bn1(self._depthwise_conv(x))) # Squeeze and Excitation if self.has_se: x = self.se(x) x = self._bn2(self._project_conv(x)) # Skip connection and drop connect if self.id_skip and self.stride == 1 and self.input_filters == self.output_filters: if drop_connect_rate: x = self.drop_connect(x, training=self.training) x += identity # skip connection return xEfficientNet模型的主要流程如下:
-
输入图像预处理:
- 输入图像首先会经过预处理步骤,包括归一化、缩放等,以使其适应网络的输入要求。
-
特征提取:
- 输入图像通过一系列卷积层和池化层,逐步提取特征。这些卷积层通常采用深度可分离卷积(depthwise separable convolution),这种卷积操作可以显著减少参数数量和计算量,从而提高模型的效率。
-
特征放缩(Feature Scaling):
- 在EfficientNet中,为了适应不同分辨率的输入图像,引入了特征放缩模块。这个模块使用全局平均池化将提取的特征向量转换为固定长度的向量,并通过一个可学习的线性变换(通常是一个1x1卷积层)将其映射到固定维度,以确保网络对于不同分辨率的图像具有一致的性能。
-
特征组合:
- 将不同尺度的特征图进行组合,通常采用特征级联或者特征融合的方式,以丰富特征表示能力。
-
分类或回归:
- 最后一层是用于分类或回归任务的全连接层或者卷积层。对于分类任务,通常使用softmax激活函数输出类别概率分布;对于回归任务,可以输出边界框的位置或者其他相关信息。
-
损失计算和反向传播:
- 使用损失函数计算模型预测值与真实标签之间的差异,常见的损失函数包括交叉熵损失(对于分类任务)和均方误差损失(对于回归任务)等。然后通过反向传播算法更新网络参数,使得损失函数最小化。
整个流程的关键点在于使用了深度可分离卷积来减少计算量,同时通过宽度/深度/分辨率缩放来平衡模型的复杂度和性能。EfficientNet在保持模型轻量级的同时,能够取得很好的性能表现,因此被广泛应用于计算资源受限的设备和场景中。
- 使用损失函数计算模型预测值与真实标签之间的差异,常见的损失函数包括交叉熵损失(对于分类任务)和均方误差损失(对于回归任务)等。然后通过反向传播算法更新网络参数,使得损失函数最小化。
2.2 新增yaml文件
关键步骤二:在下/projects/yolov5-6.1/models下新建文件 yolov5_efficientNet.yaml并将下面代码复制进去

# YOLOv5 🚀 by Ultralytics, GPL-3.0 license # Parameters nc: 80 # number of classes depth_multiple: 1.0 # model depth multiple width_multiple: 1.0 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # EfficientNetLite backbone backbone: # [from, number, module, args] [[-1, 1, stem, [32, 'ReLU6']], # 0-P1/2 ch_out, act [-1, 1, MBConvBlock, [16, 3, 1, 1, 0]], # 1 ch_out, k_size, s, expand [-1, 1, MBConvBlock, [24, 3, 2, 6, 0.028, True]], # 2-P2/4 ch_out, k_size, s, expand, drop_connect_rate, se [-1, 1, MBConvBlock, [24, 3, 1, 6, 0.057]], [-1, 1, MBConvBlock, [40, 5, 2, 6, 0.085]], # 4-P3/8 ch_out, k_size, s, expand, drop_connect_rate, se [-1, 1, MBConvBlock, [40, 5, 1, 6, 0.114]], [-1, 1, MBConvBlock, [80, 3, 2, 6, 0.142]], # 6-P4/16 ch_out, k_size, s, expand, drop_connect_rate, se [-1, 1, MBConvBlock, [80, 3, 1, 6, 0.171]], [-1, 1, MBConvBlock, [80, 3, 1, 6, 0.2]], [-1, 1, MBConvBlock, [112, 5, 1, 6, 0.228]], # 9 [-1, 1, MBConvBlock, [112, 5, 1, 6, 0.257]], [-1, 1, MBConvBlock, [112, 5, 1, 6, 0.285]], [-1, 1, MBConvBlock, [192, 5, 2, 6, 0.314]], # 12-P5/32 ch_out, k_size, s, expand, drop_connect_rate, se [-1, 1, MBConvBlock, [192, 5, 1, 6, 0.342]], [-1, 1, MBConvBlock, [192, 5, 1, 6, 0.371]], [-1, 1, MBConvBlock, [192, 5, 1, 6, 0.4]], [-1, 1, MBConvBlock, [320, 3, 1, 6, 0.428]], # 16 [-1, 1, SPPF, [1024, 5]], # 17 ] # YOLOv5 v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 11], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 21 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 5], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 25 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 22], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 28 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 18], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 31 (P5/32-large) [[25, 28, 31], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
温馨提示:本文只是对yolov5l基础上添加swin模块,如果要对yolov8n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n depth_multiple: 0.33 # model depth multiple width_multiple: 0.25 # layer channel multiple # YOLOv5s depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple # YOLOv5l depth_multiple: 1.0 # model depth multiple width_multiple: 1.0 # layer channel multiple # YOLOv5m depth_multiple: 0.67 # model depth multiple width_multiple: 0.75 # layer channel multiple # YOLOv5x depth_multiple: 1.33 # model depth multiple width_multiple: 1.25 # layer channel multiple
2.3 注册模块
关键步骤:在yolo.py中注册, 大概在260行左右添加 ‘MBConvBlock’和‘stem’

2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_efficient.yaml的路径
建议大家写绝对路径,确保一定能找到
🚀运行程序,如果出现下面的内容则说明添加成功🚀

3. 完整代码分享
https://pan.baidu.com/s/1lnKpoDnfCpVpKf9jQTG4xw?pwd=ga2h
提取码: ga2h
下面的代码是调用官方仓库实现的特征提取
https://pan.baidu.com/s/1Eo5nDN7kA34750L9fBO8YA?pwd=5geh
提取码: 5geh
4.GFLOPs对比
未改进的YOLOv5l的GFLOPs
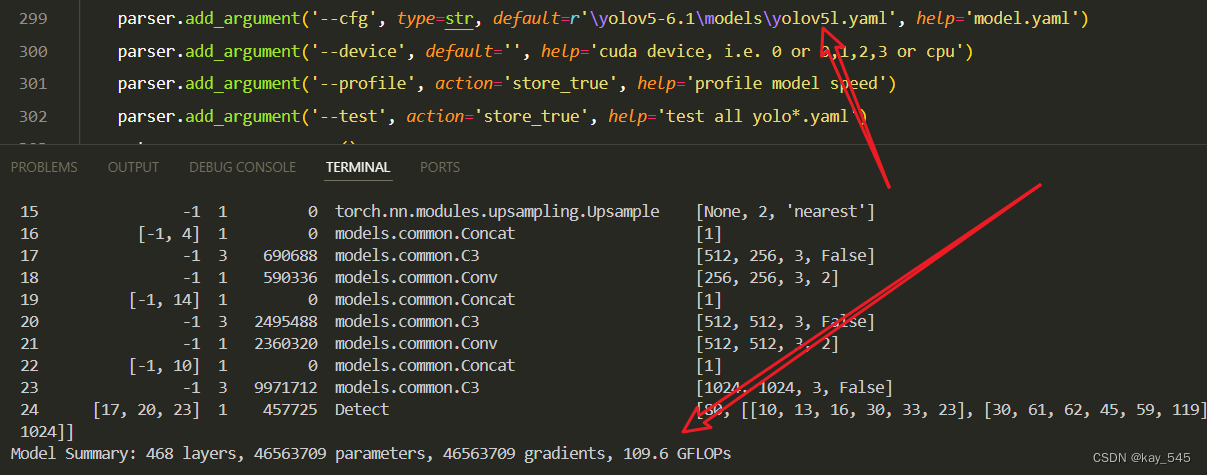
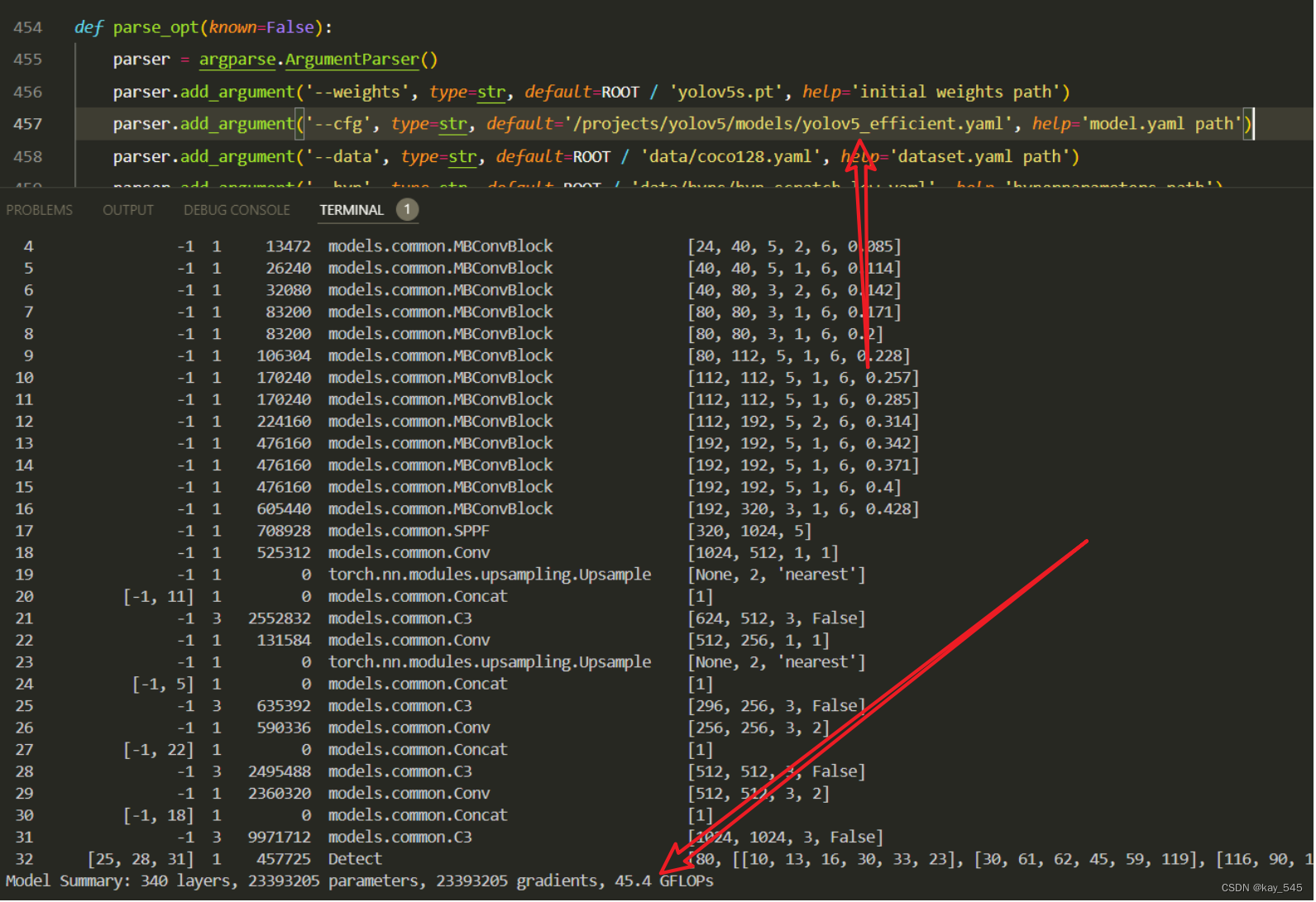
GFLOPs减少一半以上
5. 总结
EfficientNet是一种卓越的卷积神经网络架构,通过复合缩放和深度可分离卷积等技术,以及特征放缩模块的引入,实现了在保持高准确性的同时显著提升了模型的效率和性能。其提供的多个预定义模型变种,以及在各种计算机视觉任务中广泛的应用领域,使其成为了业界的热门选择,为图像分类、目标检测和其他相关任务提供了可靠且高效的解决方案。
-



