
Hive的基本操作(查询)
1、基础查询
基本语法
select 字段列表|表达式|子查询 from 表(子查询|视图|临时表|普通表) where [not] 条件A and|or 条件B --先:面向原始行进行筛选 group by 字段A[,字段B,...] => 分组【去重处理】 having 聚合条件(非原始字段条件) --再:针对聚合后的字段进行二次筛选 order|sort|cluster by 字段A[,字段B,...] --后:全局排序(非limit的最后一句) 走mapreduce limit N(前N条记录) | M(行号偏移量),N(记录数)
1.where子句的条件格式
一:关系运算符
关系运算符:> , >= , 如果 VAL 为 null,则返回 1 。否则返回 0 --case when函数: case EXPR when V1 then VAL1 when V2 then VAL2 ... else VALN end switch ... case case when 条件1 then VAL1 when 条件2 then VAL2 ... else VALN end if ... else if ... 案例: select user_id, case when order_amount 一个任意符号 案例: select "张无极" like '张%'; => true select "张无极" like '张_'; => false
正则匹配:
基本语法:
rlike '正则表达式'
如:'^//d+$'
案例:
select "like" rlike '^[a-zA-Z]{2,4}$'; =>true
2.排序
1、order by 表达式[field|func|case...when...] ---【全局排序】:性能差 优化:在order by B 之前,可以先对数据进行 distribute by A 与 sort by B => 先部分排序,后全局排序 2、sort by FIELD_N --在【每一个reducer端】排序 解释: 当reducer 的数量为1时,等同于 order by FIELD_N 必须是select字段列表中的一员 一般和 distribute by 配合使用 3、cluster by --cluster by 字段A = distribute by 字段A + sort by 字段A
3.分组
1、group by 表达式(field|func|case...when) --为了聚合而分组,否则类似去重(代替distinct) 目的:按照某些条件对数据进行分组并进行聚合操作,使用 group by 多分组: 1.group by A,B,C grouping sets(B,(A,C),(B,C)) ✔ --指定多个【分组】为:B,(A,C),(B,C) 2.group by cube(A,B,C) --排列组合后的所有分组:A,B,C,(A,B),(A,C),(B,C),(A,B,C) 3.group by rollup(A,B,C) --最左原则的所有分组:A,(A,B),(A,B,C) 2、distribute by 表达式(field|func|case...when) 目的:为了将数据分区,仅仅将数据分发到多个节点上并行处理,使用 distribute by 解释: 1.不改变原始行数 2.类似于 hadoop job 中的 Partitioner。 【默认是采用hash算法】 3.指定按哪个字段的hashcode分区,配合【预先设置reducer数量】 注意: distribute by【决定进哪个reducer】与sort by【在reducer中排序】一般搭配使用的 distribute by通常使用在SORT BY语句之前
小型案例:
with product_total as (
select order_item_product_id product_id,sum(order_item_subtotal) total
from cb_order_items
group by order_item_product_id
)
select product_id,total
from product_total
distribute by product_id
sort by total desc;
多分组案例
1.grouping sets 案例:✔ create temporary table tmp_cb_order_ymbsc_sets as select year,month,dept_id,cate_id,prod_id grouping__id, sum(quantity) as quantity, round(sum(amount)) as amount from tmp_cb_order_ymbsc group by year,month,dept_id,cate_id,prod_id grouping sets(prod_id,(dept_id,cate_id),(year,month),(year,month,prod_id)) order by grouping__id; ------------------------------------- 寻找哪几组【去重】: select grouping__id from tmp_cb_order_ymbsc_sets group by grouping__id; ------------------------------------- -- grouping__id: 6 : year,month,prod_id 7 : year,month 25 : dept_id,cate_id 30 : prod_id 2.cube 案例:【不常用】 select year(order_date) as year, month(order_date) as month, day(order_date) as day, count(*) as count, grouping__id from cb_orders group by cube (year(order_date),month(order_date),day(order_date)) order by grouping__id; 3.rollup 案例:【不常用】 select year(order_date) as year, month(order_date) as month, day(order_date) as day, count(*) as count, grouping__id from cb_orders group by rollup (year(order_date),month(order_date),day(order_date)) order by grouping__id;
2、子查询
基本语法
select 可以出现子查询(查某个字段值,与主查询存在逻辑主外键关系) from 可以出现子查询(数据表的子集 select F1,...,FN from T where ... group by ...) where 可以出现子查询(FIELD in|=|>= (select ONLY_ONE_FIELD_IN ...)) group by FIELD|substr(FIELD,0,4),... having 可以出现子查询(FIELD in|=|>= (select ONLY_ONE_FIELD_IN ...)) order by FIELD|substr(FIELD,0,4),...
常用语法【from子查询】
select 字段列表|表达式|子查询
from(
select 字段列表|表达式|子查询 ---先进行内部的查询
from TABLE
where [not] 条件A and|or 条件B
...
) ---后进行外部的查询
where [not] 条件A and|or 条件B --后=>先:面向原始行进行筛选
group by 字段A[,字段B,...]
order by 字段A[,字段B,...] --后=>再:针对聚合后的字段进行二次筛选
limit N(前N条记录) | M(行号偏移量),N(记录数) --后=>后:全局排序(非limit的最后一句)
3、CTE
基本语法
with SUB_ALIA as(...), SUB_ALTER as(select...from SUB_ALIA...) select...
小型案例
with
total_amount as(
select sum(order_amount) total
from hive_internal_par_regex_test1w
where year>=2016
group by user_gender, user_id
having total>=20000
),
level_amount as(
select round(total/10000) as level
from total_amount
)
select level,count(*) as level_count
from level_amount
group by level;
结果展示:
level level_count
2,162
3,125
4,26
5,5
4、联合查询
数据准备
Class表: +-------+---------+ |classId|className| +-------+---------+ | 1| yb12211| | 2| yb12309| | 3| yb12401| +-------+---------+ Student表: +-----+-------+ | name|classId| +-----+-------+ |henry| 1| |ariel| 2| | jack| 1| | rose| 4| |jerry| 2| | mary| 1| +-----+-------+
三种主要形式
一:内连接【inner join】
两集合取交集:
select A.内容,....,B.内容,... =>字段别名:提高筛选的性能 from TABLE_A as A inner join TABLE_B as B on A.主键=B.外键 (and A.fa = VALUE...) 多表√ 两表√ =>表进行合并时进行【连接条件】 where A.fa = VALUE; 两表√ =>合并后进行【条件筛选】 group by ... having ... order by ... limit ...
小型案例:
select * from Student S
inner join Class C
on S.classId = C.classId
结果展示:
+-----+-------+-------+---------+
| name|classId|classId|className|
+-----+-------+-------+---------+
|henry| 1| 1| yb12211|
|ariel| 2| 2| yb12309|
| jack| 1| 1| yb12211|
|jerry| 2| 2| yb12309|
| mary| 1| 1| yb12211|
+-----+-------+-------+---------+
二:外连接
左外连接【left join】
两个集合取左全集,右交集
select A.内容,....,B.内容,... =>字段别名:提高筛选的性能 from TABLE_A as A 【A为主表】 left [outer] join TABLE_B as B 【B为从表】 on A.主键|外键=B.外键|主键 (and A.fa = VALUE...) 多表√ 两表√ =>表进行合并时进行【连接条件】 where A.fa = VALUE; 两表√ =>合并后进行【条件筛选】 group by ... having ... order by ... limit ...
小型案例:
select * from Student S
left join Class C
on S.classId = C.classId
结果展示:
+-----+-------+-------+---------+
| name|classId|classId|className|
+-----+-------+-------+---------+
|henry| 1| 1| yb12211|
|ariel| 2| 2| yb12309|
| jack| 1| 1| yb12211|
| rose| 4| null| null|
|jerry| 2| 2| yb12309|
| mary| 1| 1| yb12211|
+-----+-------+-------+---------+
右外连接【right join】
两集合取右全集,左交集
select A.内容,....,B.内容,... =>字段别名:提高筛选的性能 from TABLE_A as A 【A为主表】 right [outer] join TABLE_B as B 【B为从表】 on A.主键|外键=B.外键|主键 (and A.fa = VALUE;) 多表√ 两表√ =>表进行合并时进行【连接条件】 where A.fa = VALUE; 两表√ =>合并后进行【条件筛选】 group by ... having ... order by ... limit ...
小型案例:
select * from Student S
right join Class C
on S.classId = C.classId
结果展示:
+-----+-------+-------+---------+
| name|classId|classId|className|
+-----+-------+-------+---------+
| mary| 1| 1| yb12211|
| jack| 1| 1| yb12211|
|henry| 1| 1| yb12211|
|jerry| 2| 2| yb12309|
|ariel| 2| 2| yb12309|
| null| null| 3| yb12401|
+-----+-------+-------+---------+
全外连接【full join】
两集合取左右全集
select A.内容,....,B.内容,... =>字段别名:提高筛选的性能 from TABLE_A as A 【A为主表】 full [outer] join TABLE_B as B 【B为从表】 on A.主键|外键=B.外键|主键 (and A.fa = VALUE;) 多表√ 两表√ =>表进行合并时进行【连接条件】 where A.fa = VALUE; 两表√ =>合并后进行【条件筛选】 group by ... having ... order by ... limit ...
小型案例:
select * from Student S
full join Class C
on S.classId = C.classId
结果展示:
+-----+-------+-------+---------+
| name|classId|classId|className|
+-----+-------+-------+---------+
|henry| 1| 1| yb12211|
| jack| 1| 1| yb12211|
| mary| 1| 1| yb12211|
| null| null| 3| yb12401|
| rose| 4| null| null|
|ariel| 2| 2| yb12309|
|jerry| 2| 2| yb12309|
+-----+-------+-------+---------+
三:交叉连接【cross join】
两集合取笛卡尔积
select A.内容,....,B.内容,... =>字段别名:提高筛选的性能 from TABLE_A as A 【A为主表】 cross join TABLE_B as B 【B为从表】 on A.主键|外键=B.外键|主键 (and A.fa = VALUE;) 多表√ 两表√ =>表进行合并时进行【连接条件】 where A.fa = VALUE; 两表√ =>合并后进行【条件筛选】 group by ... having ... order by ... limit ...
小型案例:
select * from Student S
cross join Class C
on S.classId = C.classId
结果展示:
+-----+-------+-------+---------+
| name|classId|classId|className|
+-----+-------+-------+---------+
|henry| 1| 1| yb12211|
|henry| 1| 2| yb12309|
|henry| 1| 3| yb12401|
|ariel| 2| 1| yb12211|
|ariel| 2| 2| yb12309|
|ariel| 2| 3| yb12401|
| jack| 1| 1| yb12211|
| jack| 1| 2| yb12309|
| jack| 1| 3| yb12401|
| rose| 4| 1| yb12211|
| rose| 4| 2| yb12309|
| rose| 4| 3| yb12401|
|jerry| 2| 1| yb12211|
|jerry| 2| 2| yb12309|
|jerry| 2| 3| yb12401|
| mary| 1| 1| yb12211|
| mary| 1| 2| yb12309|
| mary| 1| 3| yb12401|
+-----+-------+-------+---------+
5、联合查询
何为联合查询?
-
纵向拼接表,高变大
-
查询字段的【数量】与【类型】必须相同,字段名是以【第一张表为准】。
union与union all的区分
-
union:合并后删除重复项(去重)
-
union all:合并后保留重复项 ✔
小型案例
数据准备:
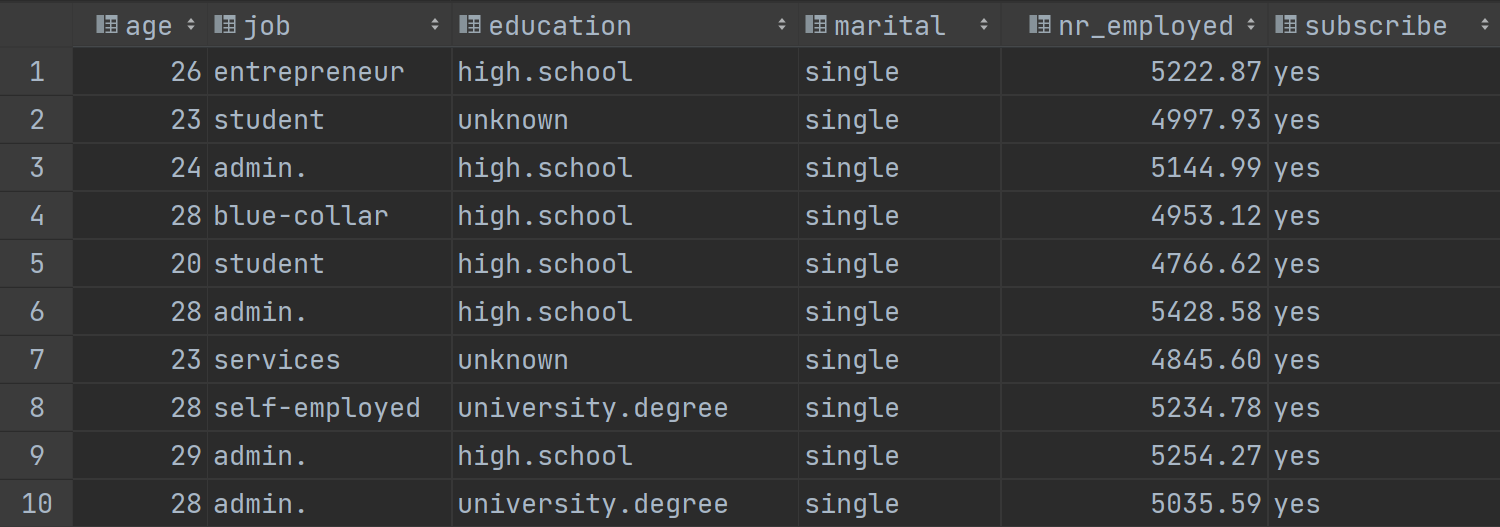
语句:
select age,job from bank_client_info_3 union all select age,job from bank_client_info_3;
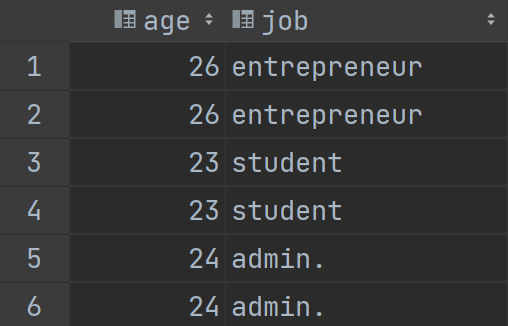
-
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



