
大数据ETL工具对比——SeaTunnel、DataX、Sqoop、Flume、Flink CDC、Dlinky、TIS、Chunjun等对比



文章目录
- 1、简介
- 1.1、Apache SeaTunnel
- 1.1.1、简介
- 1.1.2、官方地址
- 1.1.3、软件架构
- 1.2、Alibaba DataX
- 1.2.1、简介
- 1.2.2、官方地址
- 1.2.3、软件架构
- 1.3、Apache Sqoop
- 1.3.1、简介
- 1.3.2、官方地址
- 1.3.3、软件架构
- 1.4、Apache Flume
- 1.4.1、简介
- 1.4.2、官方地址
- 1.4.3、软件架构
- 1.5、Apache Flink CDC
- 1.5.1、简介
- 1.5.2、官网地址
- 1.5.3、软件架构
- 1.6、Dinky
- 1.6.1、简介
- 1.6.2、官网地址
- 1.6.3、软件架构
- 1.7、TIS
- 1.7.1、简介
- 1.7.2、官网地址
- 1.7.3、软件架构
- 1.8、Chunjun
- 1.8.1、简介
- 1.8.2、官网地址
- 1.8.3、软件架构
- 2、总结
1、简介
1.1、Apache SeaTunnel
1.1.1、简介
Apache SeaTunnel作为下一代数据集成平台。同时也是数据集成一站式的解决方案,有下面这么几个特点。
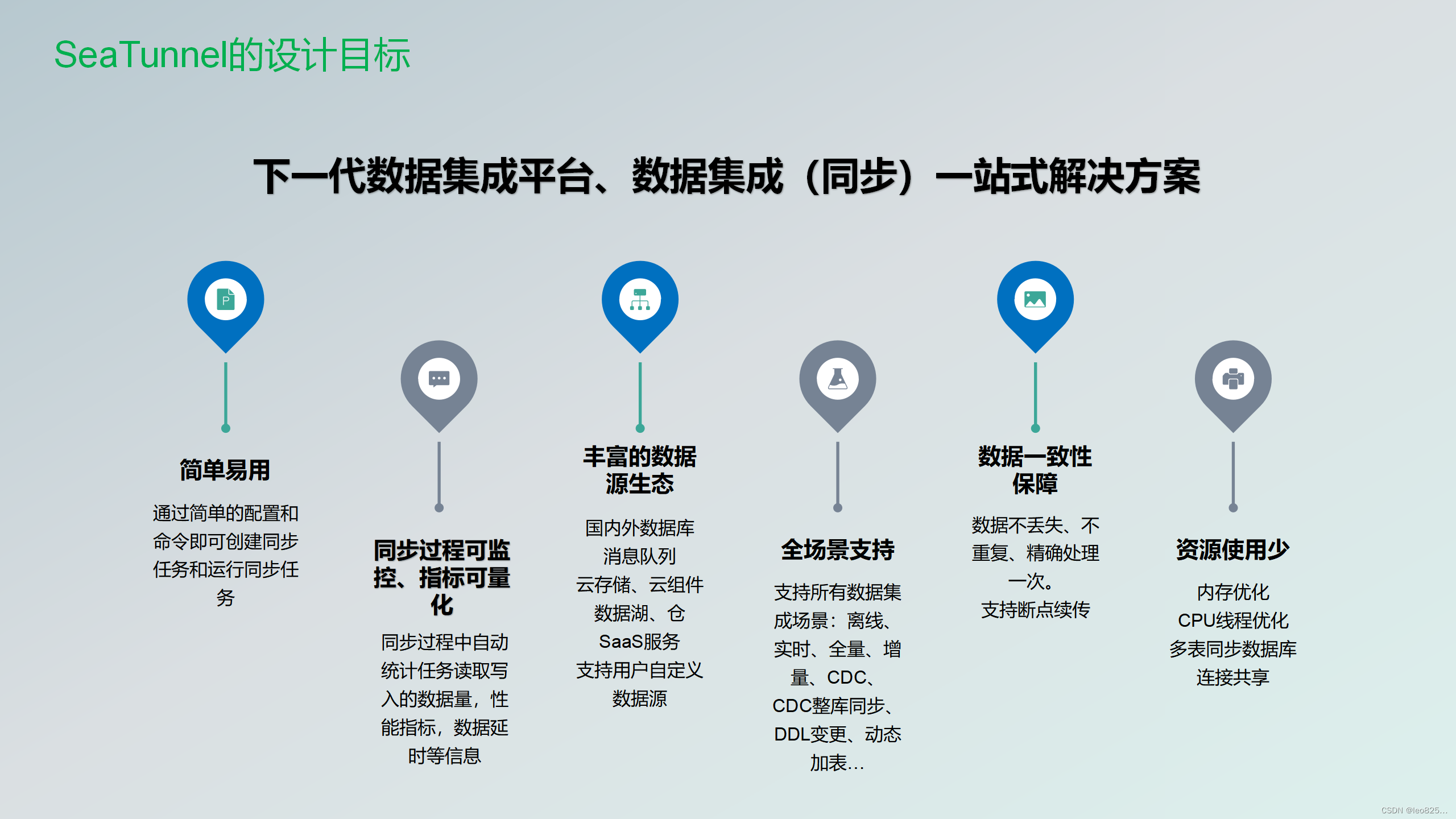
特性:
- 丰富且可扩展的Connector:SeaTunnel提供了不依赖于特定执行引擎的Connector API。 基于该API开发的Connector(Source、Transform、Sink)可以运行在很多不同的引擎上,例如目前支持的SeaTunnel Engine、Flink、Spark等。
- Connector插件:插件式设计让用户可以轻松开发自己的Connector并将其集成到SeaTunnel项目中。 目前,SeaTunnel 支持超过 100 个连接器,并且数量正在激增。 这是[当前支持的连接器]的列表(Connector-v2-release-state.md)
- 批流集成:基于SeaTunnel Connector API开发的Connector完美兼容离线同步、实时同步、全量同步、增量同步等场景。 它们大大降低了管理数据集成任务的难度。
- 支持分布式快照算法,保证数据一致性。
- 多引擎支持:SeaTunnel默认使用SeaTunnel引擎进行数据同步。 SeaTunnel还支持使用Flink或Spark作为Connector的执行引擎,以适应企业现有的技术组件。 SeaTunnel 支持 Spark 和 Flink 的多个版本。
- JDBC复用、数据库日志多表解析:SeaTunnel支持多表或全库同步,解决了过度JDBC连接的问题; 支持多表或全库日志读取解析,解决了CDC多表同步场景下需要处理日志重复读取解析的问题。
- 高吞吐量、低延迟:SeaTunnel支持并行读写,提供稳定可靠、高吞吐量、低延迟的数据同步能力。
- 完善的实时监控:SeaTunnel支持数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读写的数据数量、数据大小、QPS等信息。
- 支持两种作业开发方法:编码和画布设计。 SeaTunnel Web 项目 https://github.com/apache/seatunnel-web 提供作业、调度、运行和监控功能的可视化管理。
1.1.2、官方地址
- 官网地址
https://seatunnel.apache.org/
- 项目地址
https://github.com/apache/seatunnel https://github.com/apache/seatunnel-web
1.1.3、软件架构
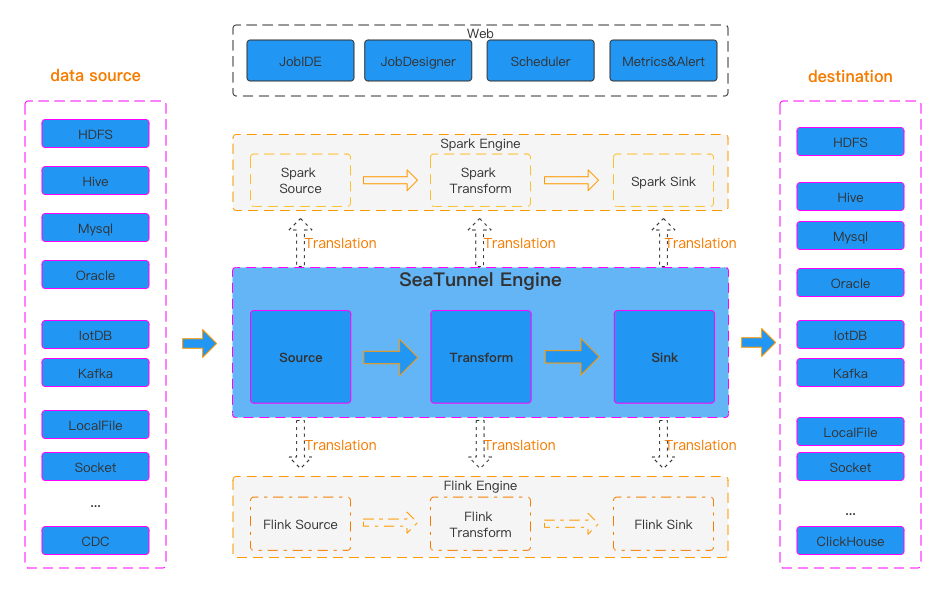
1.2、Alibaba DataX
1.2.1、简介
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
特性:
- 可靠的数据质量监控:完美解决数据传输个别类型失真问题,提供作业全链路的流量、数据量运行时监控,提供脏数据探测。
- 丰富的数据转换功能:DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
- 精准的速度控制:新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制作业速度,让作业在库可以承受的范围内达到最佳的同步速度。
- 强劲的同步性能:DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南
- 健壮的容错机制:DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。包括线程内部重试和线程级别重试。
- 极简的使用体验:易用,详细,DataX在运行日志中打印了大量信息,其中包括传输速度,Reader、Writer性能,进程CPU,JVM和GC情况等等。
1.2.2、官方地址
- 官网地址
https://github.com/alibaba/DataX/blob/master/introduction.md
- 项目地址
https://github.com/alibaba/DataX.git
1.2.3、软件架构
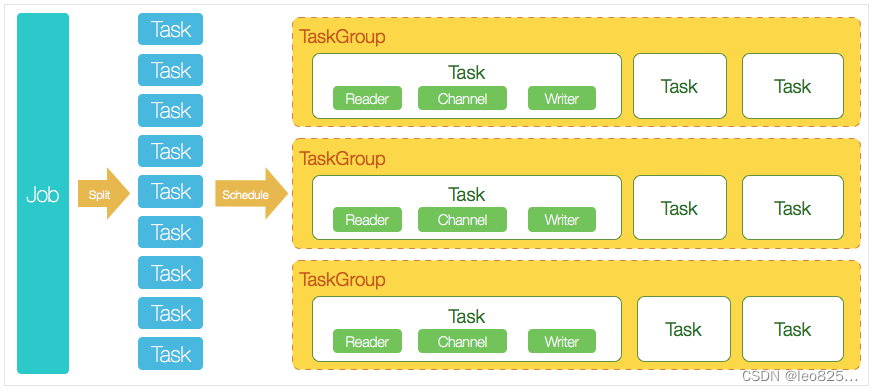
1.3、Apache Sqoop
1.3.1、简介
Sqoop 是一款开源工具,主要用于Hadoop (Hive) 数据和传统数据库(mysql ,postgresql)数据传递;可以把传统数据库数据转换到Hadoop HDFS 中,也可以把 HDFS 数据导入到关系型数据库中。
特性:
- 简单易用:Sqoop提供了简单易用的命令行接口,用户可以通过简单的命令来实现数据传输操作,而无需编写复杂的代码。
- 高效性能:Sqoop采用并行数据传输的方式,可以同时从关系型数据库中导入多张表或多个表的数据,提高了数据传输的效率。
- 数据完整性:Sqoop支持将关系型数据库中的数据导入到Hadoop中的HDFS时,保持数据的完整性,即保证数据的一致性和准确性。
- 支持多种关系型数据库:Sqoop支持多种主流的关系型数据库,包括MySQL、Oracle、SQL Server等,可以与不同的关系型数据库进行数据传输操作。
- 可扩展性:Sqoop支持自定义插件,用户可以根据自己的需求开发新的插件,实现更加灵活和定制化的数据传输操作。
1.3.2、官方地址
- 官网地址
https://sqoop.apache.org/
- 项目地址
https://github.com/apache/sqoop.git
1.3.3、软件架构
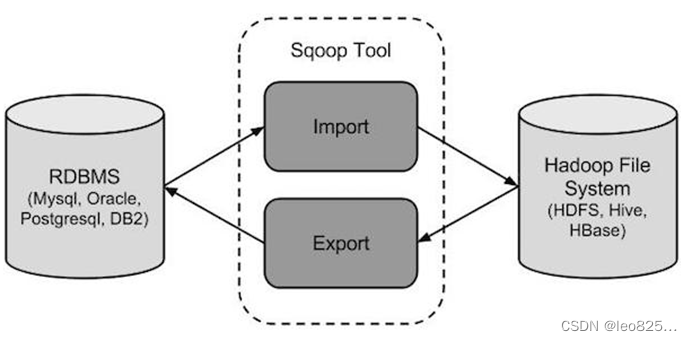
1.4、Apache Flume
1.4.1、简介
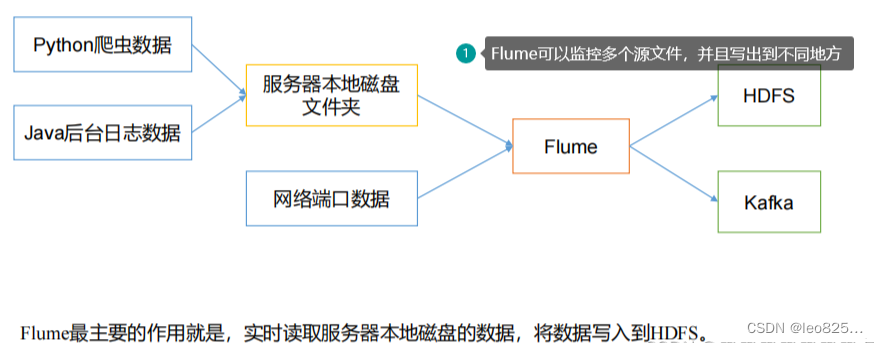
Flume是一种可配置、高可用的数据采集工具,主要用于采集来自各种流媒体的数据(Web服务器的日志数据等)并传输到集中式数据存储区域。
Flume 支持在日志系统中定制各种数据发送方,用于收集数据;并且可以对数据进行简单处理,将其写到可定制的各种数据接收方(如文本、HDFS、HBase等)。
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
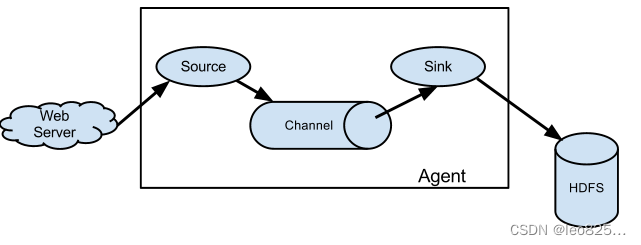
Apache Flume是一个用于收集、聚合和传输大规模数据的分布式系统。它具有许多特性,使其适用于各种数据流处理场景。
特性:
- 可扩展性: Flume可以在集群中部署多个代理,从而实现水平扩展,处理大规模的数据流量。
- 数据收集和传输: Flume支持从多种数据源(如日志、事件、日志文件等)收集数据,并将数据传输到目标存储或处理系统(如Hadoop HDFS、HBase、Kafka等)。
- 多通道支持: Flume提供不同类型的通道(Channel),允许你根据需求将数据路由到不同的通道,实现数据流的灵活分发和聚合。
- 事务性传输: Flume支持事务性传输,确保数据在从源到目标的传输过程中是原子性的,避免数据不完整。
- 数据去重和过滤: Flume可以消除重复的数据,以及通过拦截器(Interceptors)对数据进行处理、过滤和转换。
- 多种数据源和目标: Flume支持多种数据源和目标,可以集成不同的数据存储和处理系统,如Hadoop生态系统、Kafka、HBas
1.4.2、官方地址
- 官网地址
https://flume.apache.org/
- 项目地址
资源地址:http://flume.apache.org/download.html 程序地址:http://apache.fayea.com/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz 源码地址:http://mirrors.hust.edu.cn/apache/flume/1.6.0/apache-flume-1.6.0-src.tar.gz
1.4.3、软件架构
1.5、Apache Flink CDC
1.5.1、简介
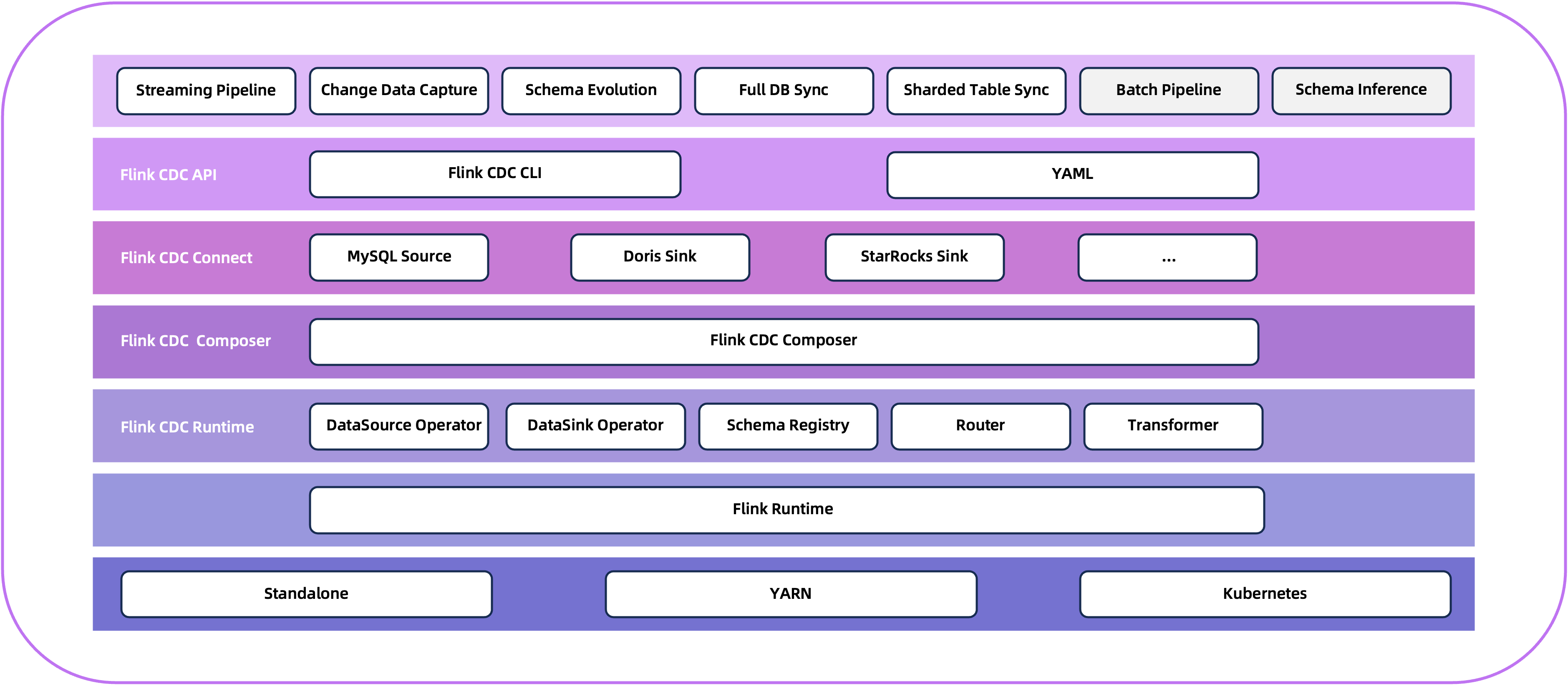
Flink CDC 是一个基于流的数据集成工具,旨在为用户提供一套功能更加全面的编程接口(API)。 该工具使得用户能够以 YAML 配置文件的形式,优雅地定义其 ETL(Extract, Transform, Load)流程,并协助用户自动化生成定制化的 Flink 算子并且提交 Flink 作业。 Flink CDC 在任务提交过程中进行了优化,并且增加了一些高级特性,如表结构变更自动同步(Schema Evolution)、数据转换(Data Transformation)、整库同步(Full Database Synchronization)以及 精确一次(Exactly-once)语义。
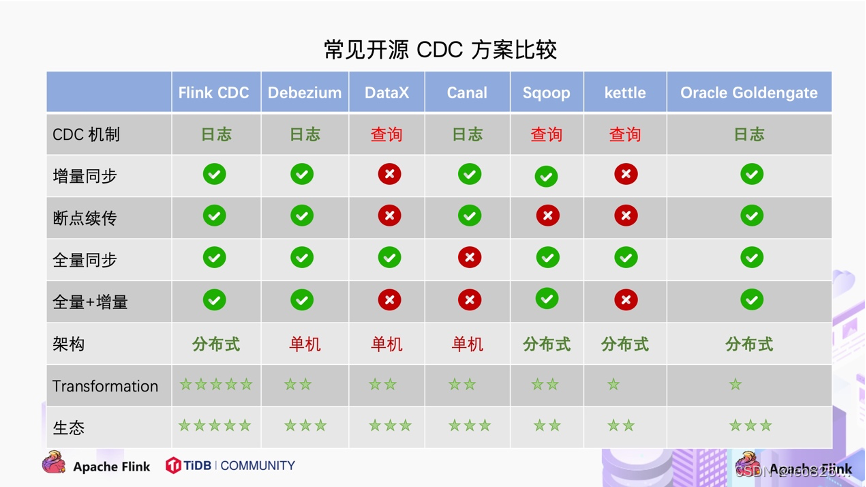
Flink CDC 深度集成并由 Apache Flink 驱动,提供以下核心功能:
✅ 端到端的数据集成框架
✅ 为数据集成的用户提供了易于构建作业的 API
✅ 支持在 Source 和 Sink 中处理多个表
✅ 整库同步
✅具备表结构变更自动同步的能力(Schema Evolution),
1.5.2、官网地址
- 官网地址
https://nightlies.apache.org/flink/flink-cdc-docs-release-3.0/zh/
- 项目地址
源码地址:https://github.com/apache/flink-cdc.git
1.5.3、软件架构
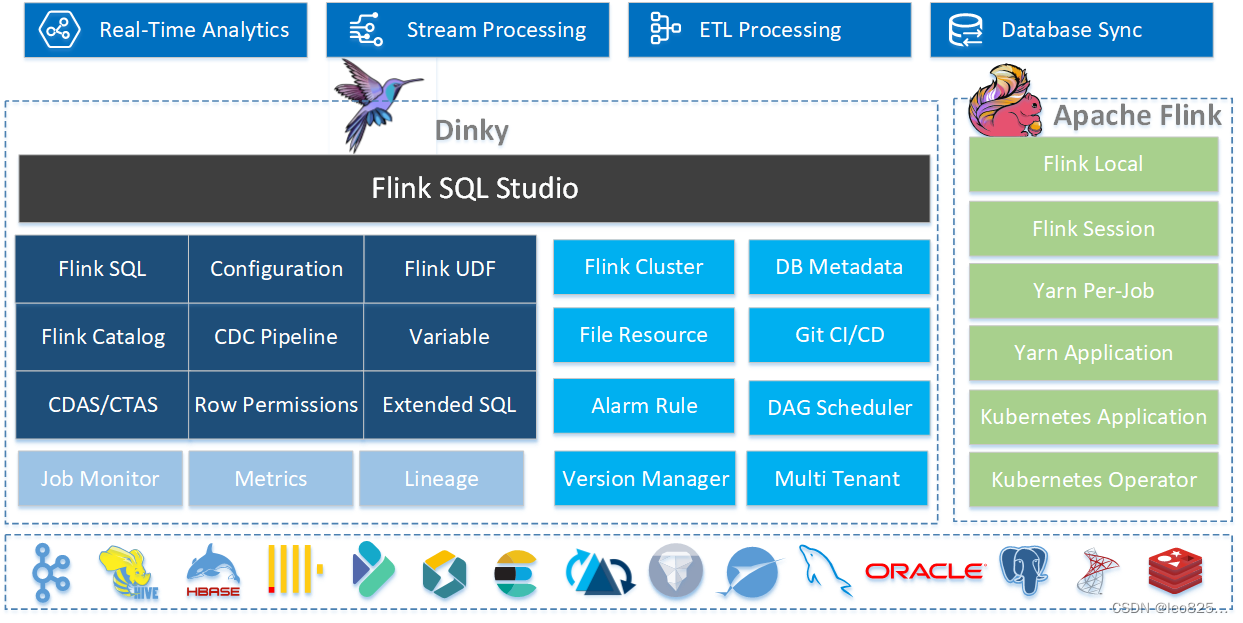
1.6、Dinky
1.6.1、简介
Dinky 是一个开箱即用、易扩展,以 Apache Flink 为基础,连接 OLAP 和数据湖等众多框架的一站式实时计算平台,致力于流批一体和湖仓一体的探索与实践。 致力于简化Flink任务开发,提升Flink任务运维能力,降低Flink入门成本,提供一站式的Flink任务开发、运维、监控、报警、调度、数据管理等功能。
特性:
- 沉浸式 FlinkSQL 数据开发:自动提示补全、语法高亮、语句美化、在线调试、语法校验、执行计划、Catalog支持、血缘分析等。
- Flink SQL语法增强,如 CDC任务,jar任务,实时打印表数据,实时数据预览,全局变量增强,语句合并、整库同步等。
- 适配 FlinkSQL 多种执行模式:Local、Standalone、Yarn/Kubernetes Session、Yarn Per-Job、Yarn/Kubernetes Application。
- 增强 Flink 生态拓展:Connector、FlinkCDC、Table Store 等。
- 支持 FlinkCDC 整库实时入仓入湖、多库输出、自动建表、模式演变。
- 支持 Flink Java / Scala / Python UDF 开发与自动提交。
- 支持 SQL 作业开发:ClickHouse、Doris、Hive、Mysql、Oracle、Phoenix、PostgreSql、Presto、SqlServer、StarRocks 等。
- 支持实时在线调试预览 Table、 ChangeLog、统计图和 UDF。
- 支持 Flink Catalog、Dinky内置Catalog增强,数据源元数据在线查询及管理。
- 支持自动托管的 SavePoint/CheckPoint 恢复及触发机制:最近一次、最早一次、指定一次等。
- 支持实时任务运维:作业信息、集群信息、作业快照、异常信息、历史版本、报警记录等。
- 支持作为多版本 FlinkSQL Server 以及 OpenApi 的能力。
- 支持实时作业报警及报警组:钉钉、微信企业号、飞书、邮箱等。
- 支持多种资源管理:集群实例、集群配置、数据源、报警组、报警实例、文档、系统配置等。
- 支持企业级管理功能:多租户、用户、角色、命名空间等。
1.6.2、官网地址
- 官网地址
https://dinky.org.cn/
- 项目地址
源码地址:https://github.com/DataLinkDC/dinky?tab=readme-ov-file
1.6.3、软件架构
1.7、TIS
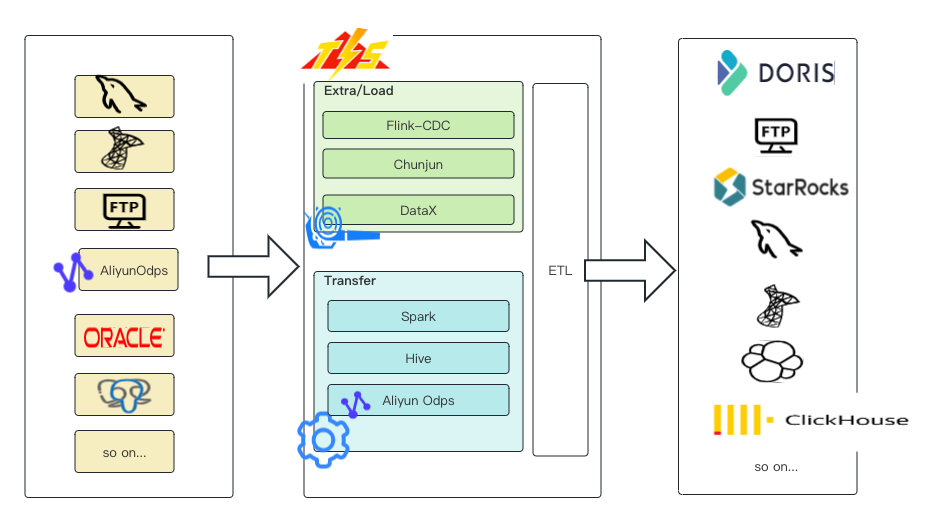
1.7.1、简介
TIS快速为您提供企业级数据集成产品,基于批(DataX),流(Flink-CDC、Chunjun)一体,提供简单易用的操作界面,降低用户实施各端(MySQL、PostgreSQL、Oracle、ElasticSearch、ClickHouse、Doris等) 之间数据同步的实施门槛,缩短任务配置时间,避免配置过程中出错,使数据同步变得简单、有趣且容易上手。
核心特性
- 简单易用:TIS的安装还是和传统软件安装一样,只需要三个步骤,一、下载tar包,二、解压tar包,三、启动TIS。是的,就这么简单。
- 扩展性强:TIS 继承了Jenkin 的设计思想,使用微前端技术,重新构建了一套前端框架,前端页面可以自动渲染。TIS 提供了良好的扩展性和SPI机制,开发者可以很轻松地开发新的插件。
- 基于白屏化操作:将传统的 ETL 工具执行以黑屏化工具包的方式(json+命令行执行)升级到白屏化 2.0的产品化方式,可以大大提高工作效率。
- 基于 DataOps 理念:借鉴了 DataOps、DataPipeline 理念,对各各执行流程建模。不需要了解底层模块的实现原理,基本实现傻瓜化方式操作。
1.7.2、官网地址
- 官网地址
https://www.tis.pub/
- 项目地址
源码地址:https://github.com/datavane/tis
1.7.3、软件架构
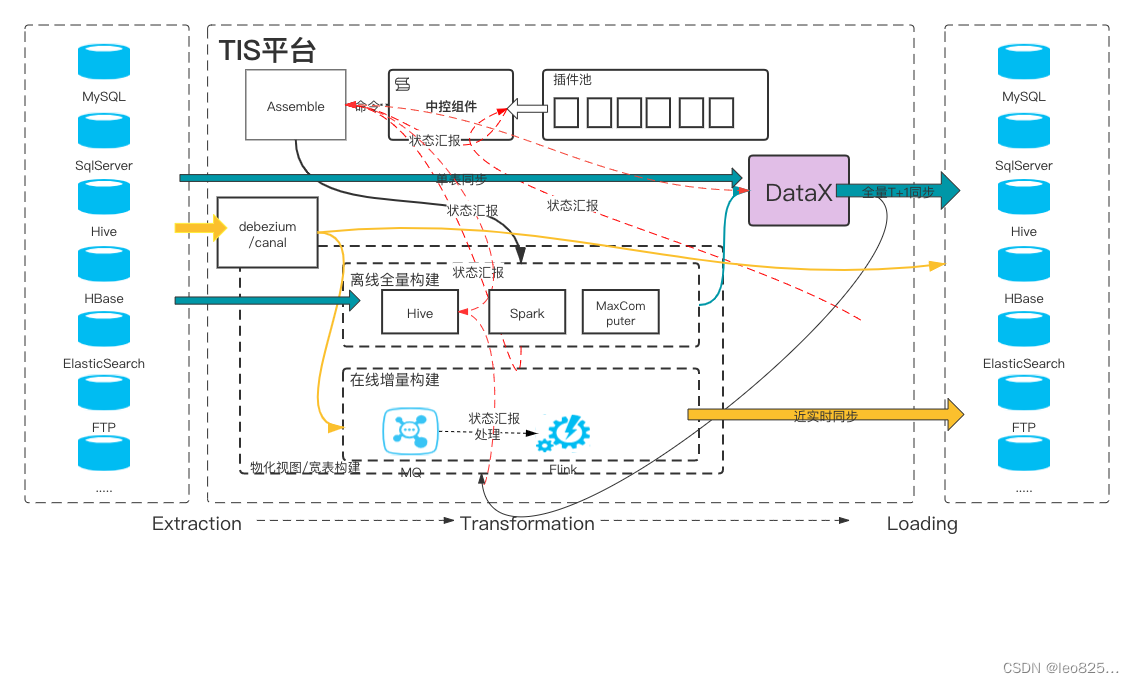
TIS平台
1.8、Chunjun
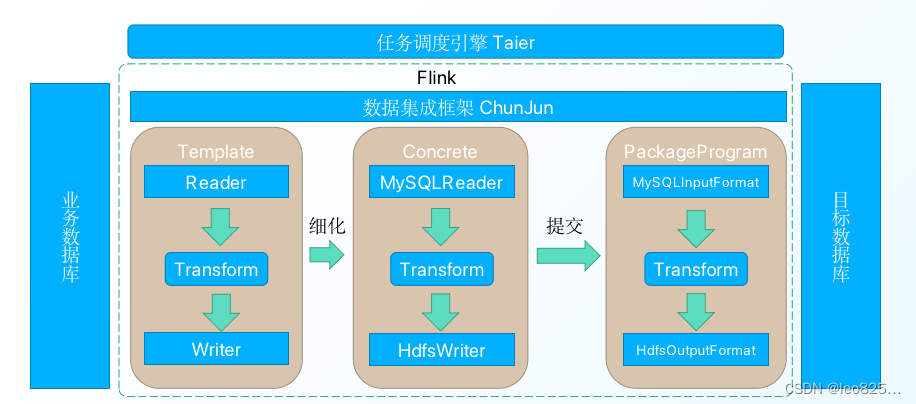
1.8.1、简介
FlinkX 现改名为 Chunjun(纯钧) ,它其实就是一款基于 Flink 实现 多种异构数据源 之间的数据同步与计算,且支持流批一体的开源数据集成框架。FlinkX将不同的数据库抽象成了 reader/source 插件,writer/sink 插件和lookup 维表插件。
特点:
- 基于实时计算引擎Flink,支持JSON模版配置任务,兼容Flink SQL语法;
- 支持分布式运行,支持flink-standalone、yarn-session、yarn-per job等多种提交方式;
- 支持Docker一键部署,支持K8S 部署运行;
- 支持多种异构数据源,可支持MySQL、Oracle、SQLServer、Hive、Kudu等20多种数据源的同步与计算;
- 易拓展,高灵活性,新拓展的数据源插件可以与现有数据源插件即时互通,插件开发者不需要关心其他插件的代码逻辑;
- 不仅仅支持全量同步,还支持增量同步、间隔轮训;
- 批流一体,不仅仅支持离线同步及计算,还兼容实时场景;
- 支持脏数据存储,并提供指标监控等;
- 配合 checkpoint 实现断点续传;
- 不仅仅支持同步DML数据,还支持Schema变更同步。
1.8.2、官网地址
- 官网地址
https://dtstack.github.io/chunjun/
- 项目地址
源码地址:https://github.com/DTStack/chunjun
1.8.3、软件架构
2、总结
各类产品对比
对比项 SeaTunnel DataX Sqoop Flume Flink CDC Dlinky TIS Chunjun 社区 活跃 非常不活跃 已经从 Apache 退役 非常不活跃 非常活跃 非常活跃 活跃 非常不活跃 定位 ETL数据集成平台 ETL数据同步工具 ETL数据同步工具 ETL数据同步工具 ETL数据同步工具 ETL数据同步工具 ETL数据集成平台 ETL数据同步工具 部署难度 容易 容易 中等,依赖于 Hadoop 生态系统 容易 中等,依赖于 Flink 或 Hadoop 生态 容易 容易,插件需要单独下载 容易 运行模式 分布式,也支持单机 单机 本身不是分布式框架,依赖 Hadoop MR 实现分布式 分布式,也支持单机 分布式,也支持单机 分布式,也支持单机 分布式,也支持单机 分布式,也支持单机 健壮的容错机制 无中心化的高可用架构设计,有完善的容错机制 易受比如网络闪断、数据源不稳定等因素影响 MR 模式重,出错处理麻烦 有一定的容错机制 健壮的容错机制 健壮的容错机制 健壮的容错机制 健壮的容错机制 支持的数据源丰富度 支持 MySQL、PostgreSQL、Oracle、SQLServer、Hive、S3、RedShift、HBase、Clickhouse等过 100 种数据源 支持 MySQL、ODPS、PostgreSQL、Oracle、Hive 等 20+ 种数据源 仅支持 MySQL、Oracle、DB2、Hive、HBase、S3 等几种数据源 支持 Kafka、File、HTTP、Avro、HDFS、Hive、HBase等几种数据源 支持 MySQL、PostgresSQL、MongoDB、SQLServer 等 10+ 种数据源 支持 MySQLCDC 到 PostgresSQL、MongoDB、SQLServer 等 10+ 种数据源 支持MySQL、MySQLCDC、PostgresSQL、Doris、ClickHouse、Oracle、SQLServer、Hive、Kafka、HDFS等10+数据源 支持MySQL、MySQLCDC、PostgresSQL、Doris、ClickHouse、Oracle、SQLServer、Hive、Kafka、HDFS等10+数据源 内存资源占用 少 多 多 中等 少 少 中等,插件越多占内存越多 少 数据库连接占用 少(可以共享 JDBC 连接) 多 多 多 多(每个表需一个连接) 多(每个表需一个连接) 多(每个表需一个连接) 多(每个表需一个连接) 自动建表 支持 不支持 不支持 不支持 支持 支持 支持 支持 整库同步 支持 不支持 不支持 不支持 支持 支持 支持(可配置每张表字段) 支持 断点续传 支持 不支持 不支持 不支持 支持 支持 支持 支持 多引擎支持 支持 SeaTunnel Zeta、Flink、Spark 3 个引擎选其一作为运行时 只能运行在 DataX 自己引擎上 自身无引擎,需运行在 Hadoop MR 上,任务启动速度非常慢 支持 Flume 自身引擎 只能运行在 Flink 上 只能运行在 Flink上 插件支持DataX、FlinkCDC、Chunjun、Hudi 只能运行在 Flink上 数据转换算子(Transform) 支持 Copy、Filter、Replace、Split、SQL 、自定义 UDF 等算子 支持补全,过滤等算子,可以 groovy 自定义算子 只有列映射、数据类型转换和数据过滤基本算子 只支持 Interceptor 方式简单转换操作 支持 Filter、Null、SQL、自定义 UDF 等算子 支持Filter、SQL 支持前置后置操作 文档不全 单机性能 比 DataX 高 40% - 80% 较好 一般 一般 较好 较好 较好 较好 离线同步 支持 支持 支持 支持 支持 支持 支持 支持 增量同步 支持 支持 支持 支持 支持 支持 支持 支持 实时同步 支持 不支持 不支持 支持 支持 支持 支持 支持 CDC同步 支持 不支持 不支持 不支持 支持 支持 支持 支持 批流一体 支持 不支持 不支持 不支持 支持 支持 支持 支持 精确一致性 MySQL、Kafka、Hive、HDFS、File 等连接器支持 不支持 不支持 不支持精确,提供一定程度的一致性 MySQL、PostgreSQL、Kakfa 等连接器支持 MySQL、PostgreSQL、Kakfa 等连接器支持 精确一致性 精确一致性 可扩展性 插件机制非常易扩展 易扩展 扩展性有限,Sqoop主要用于将数据在Apache Hadoop和关系型数据库之间传输 易扩展 易扩展 不易扩展 易扩展,可使用插件扩展 不易扩展 统计信息 有 有 无 有 无 有 有 无 Web UI 正在实现中(拖拉拽即可完成) 无 无 无 无 有 有 无 与调度系统集成度 已经与 DolphinScheduler 集成,后续也会支持其他调度系统 不支持 不支持 不支持 无 可与DolphinScheduler集成 不支持不支持
- 项目地址
- 官网地址
- 项目地址
- 官网地址
- 项目地址
- 官网地址
- 项目地址
- 官网地址
- 项目地址
- 官网地址
- 项目地址
- 官网地址
- 项目地址
- 官网地址
- 项目地址
- 官网地址



