
oracle 性能调优之执行计划详解



目录
SQL执行计划
SQL 编译器 (SQL Compiler)
Oracle 两种优化器
SQL 语句的执行过程
处理步骤包括
SQL 解析类型
生成和显示执行计划
通过包 dbms_xplan 显示计划
解决基数问题的建议
SQL执行计划
执行计划是指示Oracle 如何获取和过滤数据、产生最终的结果集,是影响 SQL 语句执行性能的关键因素。在深入了解执行计划之前,首先需要知道执行计 划是在什么时候产生的,以及如何让 SQL 引擎为语句生成执行计划。
先了解 SQL 语句的处理执行过程。当一条语句提交到Oracle后,SQL 引擎会 分为三个步骤对其处理和执行:解析 (Parse) 、执行(Execute) 和获取 (Fetch), 分别由 SQL 引擎的不同组件完成。

Oracle SQL 引擎的体系结构
SQL 编译器 (SQL Compiler)
SQL 编译器由解析器 (Parser) 、查询优化器 (Query Optimizer) 和行源生 成器 (Row Source Generator) 组成。
解析器 (Parser) :执行对 SQL 语句的语法、语义分析,将查询中的视图 展开、划分为小的查询块。
查询优化器 (Query Optimizer ) :Oracle 数据库中 SQL 优化器 (SQL Optimizer) 是 SQL 分析和执行的优化工具,为语句生成一组可能被使用的执行 计划,估算出每个执行计划的代价,并调用计划。
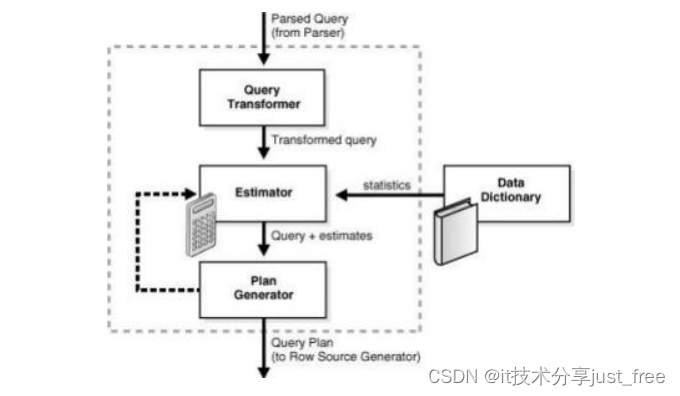
生成器 (Plan Generator): 生成 计划,比较计划的代价,最终选择一个代价最小的计划,优化器负责生成 SQL 的 执行计划。它对优化器来说输入的是解析后的 SQL 语句,输出的是执行计划。 查询优化器由查询转换器 (Query Transform) 、代价估算器 (Estimator) 和计划生成器 (Plan Generator) 组成。
Oracle 两种优化器
RBO (Rule-Based Optimizer) :基于规则的优化器
CBO (Cost-Based Optimizer) :基于成本的优化器 (11g 默认优化器)
从 Oracle 10g 开始,RBO 已经被弃用,但是我们依然可以通过 Hint 方式来使 用它。
上述优化器实际上指的是基于代价的优化器 (Cost Based Optimizer,CBO), CBO 也是当前采用的所有优化和调优技术的核心基础。
查询转换器 (Query Transformer) :决定是否重写用户的查询 (包括视图合 并、子查询反嵌套) ,以生成更好的查询计划。
代 价 估 算器 ( Estimator ) : 使 用 统 计 数 据 来 估 算 操 作 的 选 择 率 (Selectivity) 、返回数据集 (Cardinality) 和代价,并最终估算出整个执行 计划的代价。
计划生成器 (Plan Generator) :计划生成器会考虑可能的访问路径 (Access Path) 、关联方法和关联顺序,生成不同的执行计划,让查询优化器从这些计划 中选择出代价最小的一个计划。
行源生成器 (Row Source Generator) :从优化器接收到优化的执行计划后, 为该计划生成行源 (Row Source) 。行源是一个可被迭代控制的结构体,它能以
迭代方式处理一组数据行、并生成一组数据行。
SQL 执行引擎 (SQL Execution Engine)
SQL 执行引擎依照语句的执行计划进行操作,产生查询结果。在每一个操作 中,SQL 执行引擎会以迭代方式执行行源、生成数据行。
Oracle 引入一些新的优化技术时,例如,SPM、SPA 等,这些组件会与 SQL 引擎的组件融合,提供更好的优化和调优方法。
CBO 优化模式
(1) FIRST_ROWS(n)
(2) ALL_ROWS (默认值) 查看参数:
SQL> show parameter optimizer_mode
在同一系统环境下,同一条 SQL 语句选用不同的优化模式,将可能令优化 器生成不同的执行计划。
修改 CBO 优化 模式:
(1) Sessions 级别:
alter session set optimizer_mode = all_rows ;
(2) 系统级别:修改 spfile 参数
alter system set OPTIMIZER_MODE = ALL_ROWS ;
(3) 语句级别:用 Hint (/*+ ... */) 来设定
Select /*+ first_rows(10) */ name from table ;
SQL 语句的执行过程
用户发出待执行的 SQL 语句 -> 解析 -> 优化器 (查询转换,RBO 或 CBO 处理) -> 生成执行计划 -> 实际执行 -> 返回结果。
处理步骤包括
1、语法检查(syntax check): 检查此 sql 的拼写是否语法。例如:SELECT
* FORM employees
2、语义检查(semantic check): 访问对象是否存在及该用户是否具备相应
的权限。例如:SELECT * FROM nonexistent_table
3、共享池检查(Shared Pool Check),生成 SQL 语句的 Hash 值和 SQL_ID, 按 SQL_ID 及其 Hash 值在 Shared Pool 中查找匹配的相同 SQL 语句。
4、加载 SQL 代码至内存,生成内存共享数据 (cursor) ,生成执行计划 (execution plan)。
5、执行 SQL,返回结果(execute and return)。
SQL 解析类型
Hard Parse (硬解析): 也称为"library cache miss"。进行语法检查、语 义检查,加载 SQL 语句至 Shared pool 的 Library Cache 中,生成执行计划。
大小写、空格等差异都会令同一条语句被解析为不同的语句。由于须要加载 到内存中,需要专门分配内存空间并进行内存管理,因此,硬解析需要占用 CPU、 获取 library cache latch 和 shared pool latch 等资源,对于 SQL 的执行 来说,硬解析是最消耗资源的。所以,应当尽量避免硬解析,力求实现 SQL 语句 的一次解析,多次执行。
Soft Parse (软解析): 也称为"library cache hit"。在 SQL 语法和语义 检查后,如果在 SharedPool 中找到了与之完全相同的 SQL 语句,则无需执行 内存加载,直接调用已有的执行计划并执行。
提高软解析的方法包括:增加 shared_pool_size,使用绑定变量优化 SQL 语句,调整 cursor_sharing 参数等。
Softer Soft Parse(软软解析): 当设置了 session_cached_cursors 这个 参数之后,Cursor 被直接 Cache 在当前 Session 的 UGA (User Global Area) 中的,会话端重复执行相同的 SQL 时,先在 UGA 中查找,如果发现完全相同的 Cursor,就直接到 Shared pool 中取结果,也就实现了 Softer Soft Parse。
| 创建测试表 alter session set container=pdb1 ; startup |
| drop table test purge ; alter system flush shared_pool ; create table test as select * from dba_objects where 11 ; 收集 test 表统计信息 exec dbms_stats.gather_table_stats('sys','test') ; 下面语句为硬解析 select * from test where object_id=20 ; select * from test where object_id=30 ; select * from test where object_id=40 ; select * from test where object_id=50 ; 下面语句为软件解析 var oid number exec :oid:=20 ; select * from test where object_id=:oid ; exec :oid:=30 ; select * from test where object_id=:oid ; exec :oid:=40 ; select * from test where object_id=:oid ; exec :oid:=50 ; select * from test where object_id=:oid ; 下面语句为软软解析 declare i number ; begin for i in 1..14 loop execute immediate 'select * from test where object_id=:i' using i ; end loop ; end ; / 查询语句执行情况 |
| col sql_text format a40 select sql_text,parse_calls,loads,executions from v$sql s where sql_text like 'select * from test where object_id%' order by 1,2,3,4 ; SQL_TEXT PARSE_CALLS LOADS EXECUTIONS ------------------------ ----------- ---------- ---------- select * from test where object_id=20 1 1 1 select * from test where object_id=30 1 1 1 select * from test where object_id=40 1 1 1 select * from test where object_id=50 1 1 1 select * from test where object_id=:i 1 1 14 select * from test where object_id=:oid 4 1 4 设置 cursor_sharing 参数为 force,设置为 force 后,oracle 将 2 条类似的 SQL 的谓词用一个变量代替,同时将它们看做同一条 SQL 语句处理。这种方式很 粗暴,但极可能造成执行计划的不准确。适用场景:在无法将应用的代码修改为 绑定变量情况下,oracle 提供的一种解决方法。 alter system flush shared_pool ; alter session set cursor_sharing=force ; 查询语句 select * from test where object_id=60 ; select * from test where object_id=70 ; select * from test where object_id=80 ; select * from test where object_id=90 ; select * from test where object_id=100 ; select * from test where object_id=110 ; 查询语句执行情况 col sql_text format a50 select sql_id,child_number,sql_text,buffer_gets from v$sql where sql_text like 'select * from test where object_id%' ; |
生成和显示执行计划
任何一条 SQL 语句要正确运行并返回结果,SQL 执行引擎都必须获得一个相应的执行计划。当缓存当中找不到与当前环境相匹配的执行计划时,SQL 编译器 会解析和生成一个相应的执行计划。已经生成的执行计划会驻留在缓存当中,直 至其失效或者被清出缓存。
执行计划 (Execution Plan)
* 执行计划显示一条 SQL 语句的详细执行步骤,包括从数据库读取数据以及
对数据的处理。
* 这些步骤表示为一组数据库运算操作 (Operation) ,使用这些运算操作并
返回数据行。
* 这些运算操作及其实施的顺序由优化器使用查询转换及物理优化技术的组
合来确定。
* 执行计划通常以表格的形式显示,但它实际上为树形。

同样的 SQL 语句,其执行计划会因用户环境(Schemas) 和执行成本 (Costs) 的不同而改变,例如:
* 在不同的数据库中执行;
* 以不同的用户执行;
* 用户数据方案变化 (例如修改了索引) ;
* 不同的数据量和统计信息;
* 语句的变量参数输入了不同的类型和取值;
* 系统初始参数的变化 (包括改变了全局或局部会话的参数等,如:优化模式
改变等) 。
通过包 dbms_xplan 显示计划
dbms_xplan 包可以根据我们选择的函数以及输入的参数来格式化显示相关 的执行计划 。dbms_xplan 使用函数用于输出格式化的执行计划 ,display、 display_cursor、display_sqlset,分别用于显示 explain plan 命令解释的计 划、内存中的执行计划、sql优化集中语句的计划。
display
display 函数用于显示存储在 plan_table 中的执行计划,此外,如果从视图 v$sql_plan_statistics_all 可以获得该执行计划的相关统计数据,display 也 可以格式化输出这些数据。
参数描述:
table_name:存储查询计划的表名 (不区分大小写) ,默认值为 plan_table。
statement_id:sql 语句 id。在 plan_table 中,每条语句的执行计划都会 有一个唯一的 id 来标识。这个 id 可以在执行 explain plan 命令时,通过 set statement_id 子句来指定。如果输入为null,则会获取最近一条被解释的语句。
format:输出格式。在 display 函数中,有以下预定义的格式 (模板) 可供 选择:
'basic':基本格式。输出的内容最少,仅仅输出查询计划中每个操作的 id、 名称和选项以及操作的对象名。
'typical':典型格式。输出的内容是我们进行语句调优时大多数情况下所 需要的信息。除了基本格式中的内容外,还会输出优化器估算出的每个操作的记 录行数、字节数、代价和时间,以及相关的提示信息 (如远程 sql、优化器建议 等) 。如果存在谓词 (predicate) 条件,还会输出每个操作中的过滤 (filter) 条件和访问 (access) 条件。此外,如果查询涉及分区表,还会输出分区裁剪信 息;如果查询涉及并行查询,还会输出并行操作的相关信息 (如表队列信息、并 行查询分布方式等) 。这种格式是默认格式。
'serial':串行执行格式。这种格式和典型格式的输出内容基本一致,不同 之处在于,对并行查询,它不会输出相关的并行内容。
'all':完全格式。输出的内容相对完整。除了典型格式的内容以外,还会 输出字段投射信息和别名信息。
除了这些预定义的格式外,用户还可以通过在格式化字符串中添加或者屏蔽 一些关键词进行细化输出。每一个细化选项代表了输出内容中的单个信息 (可能 是执行计划表中的一个列,也可能是一个附加信息) 。在 display 函数中,有以
下细化控制选项可供选择:
rows:优化器估算出的记录行数;
bytes:优化器估算出的字节数;
cost:优化器估算出的代价;
partition:分区裁剪;
parallel:并行查询;
predicate:谓词;
projection:字段投射;
alias:别名;
remote:分布式查询信息;
note:相关注释信息。
细化控制选项和预定格式一起使用。例如,如果希望输出基本格式内容,并 输出优化器估算出的记录行数,可以用“basicrows”作为格式字符串;而如果 希望输出典型格式,但不要其中的谓词条件,则可以输入“typical -predicate” 作为格式字符串,即在希望被屏蔽信息的对应控制选项前加上“- ”。
filter_preds:该参数接收合法的谓词过滤条件 (可以是谓词逻辑表达式, 也可以包含子查询),以过滤从查询计划表中读取的内容。例如,可以输入“cost >
10”以限制输出所有估算代价大于 10 的操作。
生成执行计划
explain plan for select * from scott.dept ;
典型格式输出执行计划,即默认 typical格式输出
select * from table(dbms_xplan.display()) ;
-----------------------------------------------------------------
Id Operation Name Rows Bytes Cost (%CPU) Time
-----------------------------------------------------------------
|0| SELECT STATEMENT | | 4 |
|1 | TABLE ACCESS FULL| DEPT | 4 | 80 |
80 | 3 (0) | 00:00:01 | 3 (0) | 00:00:01 |
-----------------------------------------------------------------
基本格式输出执行计划,包括 ROWS BYTES
select * from table(dbms_xplan.display(null,null,'BASIC ROWS
BYTES')) ;
--------------------------------------------------
| Id | Operation | Name | Rows | Bytes |
--------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 80 |
| 1 | TABLE ACCESS FULL| DEPT | 4 | 80 |
--------------------------------------------------
基本格式输出执行计划,包括 ROWS BYTES COST
select * from table(dbms_xplan.display(null,null,'BASIC ROWS BYTES COST')) ;
Id | Operation | Name | Rows | Bytes | Cost (%CPU) |
0 | SELECT STATEMENT | | 4 |
80 |
3 (0) |
1 | TABLE ACCESS FULL| DEPT | 4 | 80 | 3 (0) |
典型格式输出执行计划
select * from table(dbms_xplan.display(null,null,'TYPICAL')) ;
Id|Operation | Name | Rows | Bytes | Cost (%CPU) | Time
0| SELECT STATEMENT | | 4 | 80 | 3 (0) | 00:00:01
1| TABLE ACCESS FULL| DEPT | 4 | 80 | 3 (0) 00:00:01
屏蔽 rows
select * from table(dbms_xplan.display(null,null,'TYPICAL -rows')) ;
Id | Operation | Name | Bytes | Cost (%CPU) | Time
0 | SELECT STATEMENT | | 80 | 3 (0) | 00:00:01
1 | TABLE ACCESS FULL| DEPT | 80 | 3 (0) 00:00:01
display_cursor
display_cursor 函数可以显示内存中一个或者多个游标的执行计划。同样, 可以通过输入参数限定 sql、游标以及输出格式 。用户必须对视图 v$sql、 v$sql_plan 和 v$sql_plan_statistics_all 的 select 有权限,才能正常调用
display_cursor 函数。
参数描述:
sql_id:所显示执行计划的 sql 语句的 id。该 id 可以从 v$sql.sql_id、 v$session.sql_id 或者 v$session.prev_sql_id 获得。如果没有指定 sql_id(指 定 null) ,则默认会显示当前会话中最后一条执行的 sql语句。
cursor_child_no:语句的子游标序号。我们知道,受到执行环境的影响, 一条 sql语句可能会产生多个版本的子游标,每个子游标都会与一个执行计划相 映射 (多个子游标也可能映射同一个执行计划) 。通过 cursor_child_no 可以限 制仅显示某一个子游标的执行计划。如果不指定该参数,则会显示该语句的所有 子游标的执行计划。
format:格式化控制字符串。display 函数的格式化控制字符串的所有选项 都 适 用 于 display_cursor 函 数 。 由 于 运 行 语 句 还 可 以 通 过 提 示 gather_plan_statistics 或设置系统参数 statistics_level 为“all”收集语 句运行的性能统计数据,因此在细化选项中还有额外的选项,以选择是否输出这 些数据。
iostats:是否输出计划的输入输出 (io) 统计数据;
memstats:在启用了 pga 自动管理(参数 pga_aggregate_target 的值大于 0) 的情况下,是否输出计划的输入内存统计数据 (操作的内存使用量、内存读次数 等) ;
allstats:包含了 iostats 和 memstats 的全部内容;
last: 以上三个选项输出的统计数据都是实际产生的数据,而非估算数据, 它们是该游标所有执行所产生的数据的总和。你可以增加 last选项以限定仅显 示最后一次运行的统计数据。
此外,还有一些未公布的选项可用于该函数的输出控制。首先是预定义格式:
'advanced':高级格式。高级格式除了会输出完全格式中的所有内容外,还 会视情况输出绑定变量窥视信息和计划概要 (outline) 信息;
outline:是否以提示 (hint) 的方式显示计划概要;
peeked_binds:是否显示绑定变量窥视信息;
buffstats:是否显示内存读次数 (包括一致性读和当前读次数) ,该信息 为 iostats 的一部分;
plan_hash:是否显示计划的哈希值,该选项同样适用于 display 函数。
-- Show the execution plan in the cursor
select e.last_name, d.department_name from hr.employees e, hr.departments d where e.department_id = d.department_id ;
dbms_xplan.display_cursor 的 3 个参数:
1) sql_id: SQL 语句在游标缓存区的 ID。默认为 NULL,此会话中最后一 条执行的语句。
2) cursor_child_no:子编号,默认为 0。
3) format: 显示格式。默认为 TYPICAL,可选 basic/typical/serial/all 等。
set linesize 200
set pagesize 50
select * from table(dbms_xplan.display_cursor()) ;
select /*+gather_plan_statistics*/* from scott.dept ;
select * from table(dbms_xplan.display_cursor(null,null,'basic last allstats')) ;
PLAN TABLE OUTPUT
_ _
------------------------
EXPLAINED SQL STATEMENT:
------------------------
select /*+gather_plan_statistics*/* from scott.dept
Plan hash value: 3383998547
---------------------------------------------------------------
Id Operation Name Starts E-Rows A-Rows A-Time Buffers
------------------------------------------------------------
|0| SELECT STATEMENT | | 1 | | 4 |00:00:00.01 | 7 |
| 1| TABLE ACCESS FULL| DEPT | 1 | 4 | 4 |00:00:00.01 | 7 |
----------------------------------------------------------------
2、autotrace
autotrace 是 oracle 自 带 的 客 户 端 工 具 sql*plus 的 一 个 特 性 。 启 用
autotrace 后,sql*plus 会自动收集执行过的语句的执行计划、性能统计数据等, 并在语句执行结束后显示在 sql*plus 中。
要使用 autotrace,需要先做以下准备,用 dba 用户创建角色 plustrce,并
将该角色赋予用户:
conn / as sysdba
@?/sqlplus/admin/plustrce.sql
grant plustrace to scott ;
在执行语句之前,在 sql*plus 中打开 autotrace。可以在打开 autotrace 时选择不同选项,以控制输出的内容。选项如下所示:
set autotrace on:打开 autotrace,并输出所有内容,包括语句本身的查 询结果、执行计划,以及性能统计数据。
set autotrace on explain:打开 autotrace,并输出语句本身的查询结果 和执行计划,不输出性能统计数据。
set autotrace on statistics:打开 autotrace,并输出语句本身的查询结 果和性能统计数据,不输出执行计划。
set autotrace trace:打开 autotrace,并输出执行计划和性能统计数据, 不输出语句本身的查询结果。
set autotrace trace explain:打开 autotrace,并输出执行计划,不输出 语句本身的查询结果和性能统计数据。
set autotrace trace statistics:打开 autotrace,并输出性能统计数据, 不输出语句本身的查询结果和执行计划。
set autotrace off:关闭 autotrace。
一个完整的autotrace 报告输出包括三个部分:
第一部分为 sql本身的执行结果;
第二部分为 sql 的执行计划;
第三部分为 sql 实际执行的性能统计数据。
由于执行计划和执行的性能数据都是进行 sql调优时的重要参考信息,因此 autotrace 是进行 sql语句性能调优的一个非常实用的辅助方法。
当打开 autotrace 后,在执行语句之前,oracle 会调用 explain plan 命令 对语句进行解析;在执行完成后,从 plan_table 中查询和显示执行计划。因此, 由于受到共享游标、绑定变量窥视等设置的影响,这一执行计划可能会与实际执
行计划不同。
除了上述方法外,还可以通过其他一些途径获取到语句的执行计划。
二、解读执行计划
掌握了获取和显示执行计划的方法后,就可以开始了解如何来读懂一个执行 计划。一个执行计划实际上是一个树状关系的结构图。在这个树状结构图中,每 一个节点代表了一个操作 (相应的,它们在 PLAN_TABLE、V$SQL_PLAN 等执行计 划表、视图中都有一条记录) ,每个支节点 (或者说父节点) 下都有一个或多个 子操作;除根节点外,每个节点都仅隶属于一个支节点。同一层操作按照它们的 ID 顺序执行。操作由顶向下调用,即父操作调用子操作;数据由底向上返回, 即子节点获取到的数据在处理完成后返回给父节点。
执行计划包含了相当丰富的信息。通过执行计划,不仅可以知道 SQL 引擎将 以什么样的访问顺序访问对象、获取语句的输出结果,而且还可以获得优化器估 算出的代价结果、运行时间以及其他一些额外信息。
exec sql_explain('select o.owner, o.object_name, o.object_id from t_users u, t_objects o where u.username=o.owner and o.object_name like :A
and u.user_id=:B','BASIC PREDICATE') ;

以表格样式输出查询计划。该表有多个列,其中 ID 是计划中每个操作的唯 一序列号,Operation 是每个操作的名称和方式,Name 是操作的对象。实际上, 该表还有其他一些列代表了优化、统计等信息。
再看每行记录的数据,每行数据中的 Operation 都带有长短不一的前导空格,
使之看起来成为一个树状结构。这个结构也就是操作之间的调用关系。
首先看第一条,ID 为 0,操作为 SELECT STATEMENT。这一行实际上只表示这 条语句的类型是一条 SELECT 语句,而非一个真正的操作。因此在一些执行计划 的显示当中,没有显示 ID 为 0 的操作。
ID 为 1 的操作是 NESTED LOOPS,表明它需要对两个数据集以嵌套循环的方 式进行数据关联。而这两个数据集则是由其两个子操作 2 和 4 分别从表 T_USERS 和 T_OBJECTS 上读取得来,也就是说,操作 1 按顺序调用操作 2 和 4,获取它们 返回的数据进行关联。而要实现嵌套循环,就需要两个循环体。其中,操作 2 就是第一个循环体,也就是外循环;操作 4 就是第二个循环体,即内循环。
ID 为 2 的操作是 TABLE ACCESS BY INDEX ROWID,Name 是 T_USERS,表明它 是通过索引上的 ROWID 来访问表 T_USERS 以获取数据。而索引上的 ROWID 则需要 通过其子操作 3 来获取;
ID 为 3 的操作是 INDEX UNIQUE SCAN,Name 是 T_USERS_PK,表明它是对索 引 T_USERS_PK 进行唯一键值的访问以获取其父操作所需要的 ROWID。T_USERS_PK 是表 T_USERS 的主键,也是一个唯一索引。而对唯一索引的唯一键值的访问,需 要有一个数值的输入作为访问条件。在它的 ID 列,我们可以留意到*符号,表示 这个操作有相关的谓词条件 (访问条件或者过滤条件) 。而我们这里也特地显示 了 谓 词 条 件 。 在 下 面 谓词 信 息 输 出 部 分 , 可 以 找 到 一 条 信 息 3 - access("U"."USER_ID"=TO_NUMBER(:B)),表明这是操作 ID 为 3 的谓词条件,其 中 access 表示它是访问条件,内容是通过某个数值定位 USER_ID 键值。
访问条件和过滤条件都属于谓词条件,但它们对操作的作用大不相同。访问 条件可以帮助操作从物理对象上定位到符合条件的数据,然后再读取数据;而过 滤条件是操作已经从物理存储上读取到了数据,然后将不符合条件的数据过滤 掉。它们对语句的性能影响很大,了解了它们之间的差别,就有助于我们对语句 进行进一步调优。
ID 为 4 的操作是 TABLE ACCESS FULL,Name 是 T_OBJECTS,表明它是对表 T_OBJECTS 进行全表扫描。全表扫描即读取表的物理段 (Segment) 的高水位线 (High Water Mark,HWM) 以下的所有数据块。同样,它的 ID 也有*符号,从谓 词信息部分可以找到关联的谓词条件 4 - filter("O"."OBJECT_NAME" LIKE :A AND "U"."USERNAME"="O"."OWNER")。filter 表明它是一个过滤条件,即读取了 表 T_OBJECTS 的所有数据,再过滤掉不符合条件("O"."OBJECT_NAME" LIKE :A AND
"U"."USERNAME"="O"."OWNER")的数据。
通过执行计划,可以清楚地了解一条语句是通过什么样的方式读取物理对象 的数据,如何对数据进行处理 (过滤、排序等) ,最终获取到符合条件的数据。 再结合执行计划中的其他数据,可以进一步定位语句的性能瓶颈在哪里,从而为
实施优化奠定基础。
在执行计划中,除了 ID、Operation 和 Name 之外,还有其他一些列。这些 列的数据是根据需要从 PLAN_TABLE、V$SQL_PLAN、V$SQL_PLAN_STATISTICS_ALL 等表和视图中读取的。它们可以帮助我们进一步理解该执行计划 (例如优化器对 各个操作的估算数据、实际运行中各个操作的性能数据等) 。以下是各个列的描
。
Rows/E-Rows:优化器估算出当前操作返回给上一级操作的数据记录数,如 果计划中同时输出收集到实际记录数,则会显示为 E-Rows 以和实际记录数区别,
在优化器中,又称为数据集的行数 (Cardinality) ;
Bytes/E-Bytes:优化器估算出当前操作返回给上一级操作的数据的字节数, 如果计划中同时输出收集到实际字节数,则会显示为 E-Bytes 以和实际字节数区
别;
TempSpc/E-Temp:优化器估算出完成当前操作 (仅部分操作需要临时空间, 如 SORT、Hash Join) 所需要的临时表空间的大小,如果计划中同时输出收集到
实际临时空间大小,则会显示为 E-Temp 以和实际临时空间大小区别;
Cost(%CPU):优化器估算出完成当前操作的代价 (包含子操作的代价) ,它 是 IO 代价和 CPU 代价总和。其中,IO 代价是最基本的代价。而对于 CPU 代价, 在默认情况下,优化器会将 CPU 代价计算在内,并且将 CPU 代价根据系统配置由 特定的转换公式转换为 IO 代价。也可以通过优化器参数_optimizer_cost_model 指定是否在代价模型中包括 CPU 代价。括号中数据即为 CPU 代价在总代价中的比
例;
Time/E-Time:优化器估算出完成当前操作所需要的时间,这个时间是其子 操作的累计时间,如果计划中同时输出收集到实际时间,则会显示为 E-Time 以和实际时间区别;
Pstart:分区裁剪 (Partition Prunning) 后,访问的起始分区,仅在含有分区表访问操作的执行计划中出现;
Pstop:分区裁剪 (Partition Prunning) 后,访问的结束分区,仅在含有分区表访问操作的执行计划中出现;
Inst:分布式查询中,远程对象所在的数据库实例名;
TQ:并行查询中的表队列 (Table Queue) ,我们会在相关操作中进一步阐 述该列数据;
IN-OUT:并行查询或分布式查询中数据传输方式;
PQDistrib:并行查询中,并行服务进程之间的数据分发方式;
Starts:当前操作实际被启动的次数,如果输出格式中指定了LAST 关键字, 则为计划最后一次执行中当前操作实际被启动的次数,否则为所有被启动次数总
和;
Rows:当前操作实际返回的记录数,如果输出格式中指定了 LAST 关键字, 则为最后一次执行的记录数,否则为所有执行的记录数总和;
Time:执行当前操作的实际时间,如果输出格式中指定了 LAST 关键字,则 为最后一次执行的时间,否则为所有执行的时间总和;
Buffers:当前操作中发生读内存的次数,如果输出格式中指定了LAST 关键 字,则为最后一次执行的读内存次数,否则为所有执行的读内存次数总和。内存
读次数包括一致性读 (Consistent Read,CR) 和当前模式读 (Current Get,CU);
Reads:当前操作中发生读磁盘的次数,如果输出格式中指定了LAST 关键字, 则为最后一次执行的读磁盘次数,否则为所有执行的读磁盘次数总和;
Writes:当前操作中发生写磁盘的次数,如果输出格式中指定了 LAST 关键 字,则为最后一次执行的写磁盘次数,否则为所有执行的写磁盘次数总和;
OMem:当前操作完成所有内存工作区 (Work Area) 操作所总共使用私有内 存 (PGA) 中工作区的大小。需要使用内存工作区的操作为:哈希操作,如哈希分组 (Hash Group) 、哈希关联 (Hash Join) 和排序 (Sort) 操作,它们分别 占有工作区中哈希区 (Hash Area) 和排序区 (Sort Area) 进行工作,这个数据
是由优化器统计数据以及前一次执行的性能数据估算得出的;
1Mem:当工作区大小无法满足操作所需要的大小时,需要将部分数据写入临 时磁盘空间中 (如果仅需要写入一次就可以完成操作 ,就称为一次通过 , One-Pass;否则为多次通过,Multi-Pass) 。该列数据为语句最后一次执行中, 单次写磁盘所需要的内存大小,这个数据是由优化器统计数据以及前一次执行的
性能数据估算得出的;
Used-Mem:语句最后一次执行中,当前操作所使用的内存工作区大小,括号
里面为 (发生磁盘交换的次数,1 次即为 One-Pass,大于 1 次则为Multi-Pass,
如果没有使用磁盘,则显示 OPTIMAL) ;
Used-Tmp:语句最后一次执行中,当前操作所使用的临时段的大小,无法一 次在工作区完成操作的数据被临时写入该段;
O/1/M:语句所有的执行总共使用内存或磁盘完成操作的执行次数,分别是 Optimal (优化的,仅适用内存完成操作) /One-Pass/Multi-Pass;
Max-Tmp:语句所有执行中,当前操作所使用的临时段的最大空间。
通常我们所说的执行计划操作包含两个部分:操作与其选项。例如,哈希关 联反关联 (HASH JOIN ANTI) 中,哈希关联 (HASH JOIN) 是一种操作,“反” 关联 (ANTI) 则是其选项;该操作还可以与其他选项 (如“半”关联,SEMI) 配 合形成不同的执行计划操作。
实际上,在执行计划里出现的操作包含两个信息,一个是操作类型 (在 PLAN_TABLE、V$SQL_PLAN 等表或视图中,字段名为 OPERATION) ;一个是操作的 选项 (在相关表和视图中,字段名为 OPTIONS) 。例如 TABLE ACCESS BY INDEX ROWID,它的操作类型是 TABLE ACCESS,即访问表,选项是 BY INDEX ROWID,即 通过索引中的 ROWID 来访问表。
执行计划的谓词 (Predicate Information)
是查询语句中的 WHERE 子句中的过滤条件。
Access: 表示这个谓词条件中的值将会影响数据的访问方式(表、索引、Hash
。
Filter:表示这个谓词条件中的值起了数据过滤的作用。
执行计划的备注 (Note)
补充说明本次执行计划的内容。如:使用了动态采样、专门的查询优化技术、指 定的 SQL Profile 等。
执行计划的统计项目
| 名称 | 描述 |
| recursive calls | 执行递归调用的数量。DML 语句与 SELECT 都可能 引起 recursive SQL,触发器也可视为 recursive SQL。 |
| db block gets | 读 取 缓 存 的 当 前 数 据 块 次 数 。 使 用 insert,update,delete,select for update 等语句 |
| 时会产生。 | |
| consistent gets | 一致性读取缓存的数据块次数。Oracle 为了保证数 据的一致性,在查询时,若当前数据块被修改而还 未提交确认,则 Oracle 将根据回滚信息来扫描缓 存中的数据块,直至读取到修改前的数据, 以确保 用户查询的数据一致性。 |
| physical reads | 物理读数据块的数量,指从磁盘直接读取、以及读 进 IO 缓存中的数据块数 量。逻辑读 (= db block gets + consistent gets) 是 Oracle 从内存读取数据,当在内存中找不到所 需的数据时就需要从磁盘中读取,于是就产生了 "physical reads"。 |
| redo size | DML 语句产生的 redo 字节数量。 |
| bytes sent through SQL*Net to client | 从前台进程发送给用户端的总字节数量。 |
| bytes received through SQL*Net from client | 从用户端接收到的总字节数量。 |
| SQL*Net round-trips to/from client | 向用户端发送及接收信息的往来次数。 |
| sorts (memory) | 使用内存空间排序的次数 |
| sorts (disk) | 使用临时磁盘空间排序的次数(至少发生一次写盘) |
| rows processed | 本次操作处理的数据行数量。 |
执行计划的内容
执行计划的执行顺序:按缩行深度及 Id 顺序,一般遵循规则 " 最右最上 最先 执行"。即:先从最开头一直往右看,直到看到最右边的并列的地方,对于 不并列的,靠右的先执行;对于并列的,靠上的先执行。

Cost ( 执行计划的 开销)
Cost 是一个估算的成本量度,其中包含了对每步处理所估算的 I/O、CPU、 内存等资源耗用成本。
Rows ( 基数/ 数据行数 )
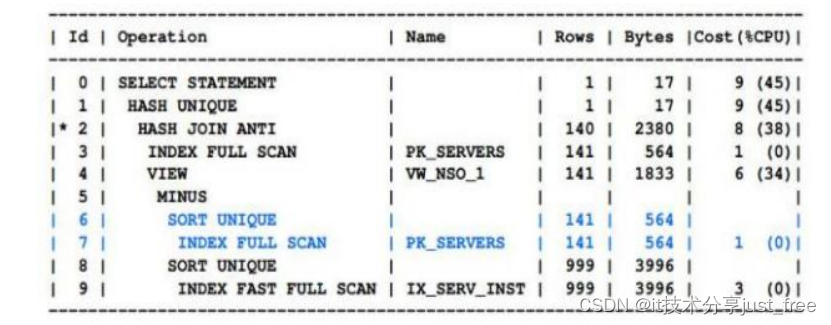
查看每个对象是否生成正确的行数?

解决基数问题的建议
| 原因 | 解决方法 |
| 统计信息陈旧/缺少 | dbms_stats |
| 数据偏差 | 创建一个柱状图 |
| 一个表有多个单列谓 词 | 使用 dbms_stats.create_extended_stats 创建一个列 组的统计信息 |
| 一个联接中使用多个 列 | 使用 dbms_stats.create_extended_stats 创建一个列 组的统计信息 |
| 包含函数的列 | 使用 dbms_stats.create_extended_stats 创建有关包 含函数的列的统计信息 |
| 复杂表达式 (包含来自多个表的 列) | 使用 4 级或更高的动态抽样级别。 (optimizer_dynamic_sampling >= 4) |







