
NLP的奥秘:用 Python 揭秘人类语言与人工智能的桥梁【6000 字长文含代码示例】
目录
NLP 的核心任务
NLP 的发展历史
NLP 的技术与方法
传统的 NLP 技术与方法
规则基础方法:语言学的智慧
统计学习方法:数据的力量
深度学习方法:人工智能的新浪潮
NLP 的应用领域
Python在 NLP 中的应用
1、NLTK (Natural Language Toolkit)
2、spaCy
3、TextBlob
4、Gensim
5、Pattern
6、StanfordNLP
7、AllenNLP
8、其他
NLP 的挑战
NLP 的未来展望
自然语言处理(NLP)是一门交叉学科,它结合了计算机科学、人工智能和语言学的理论与技术,旨在使计算机能够理解、解释、生成和响应人类语言的内容。NLP 的目标是实现人机交互的自然化,让机器能够像人类一样处理和理解语言。仅用这一篇文章将带您深入了解 NLP 的世界,探索它的核心任务、技术、应用、Python 库实现、挑战以及未来趋势。
NLP 的核心任务
NLP 涵盖了许多任务,旨在让计算机能够像人类一样处理语言。以下是几个主要的 NLP 任务:

NLP 的发展历史
NLP 的发展历程可以追溯到 20 世纪 50 年代,经历了多个重要的阶段:
-
规则基础方法 (1950s - 1980s):早期 NLP 系统主要依赖于语言学家制定的规则来处理语言。
-
统计学习方法 (1980s - 2010s):随着机器学习技术的兴起,统计学习方法开始在 NLP 领域占据主导地位。
-
深度学习方法 (2010s - 至今):深度学习技术的突破为 NLP 带来了革命性的变化,取得了显著的成果。
NLP 的技术与方法
-
分词(Tokenization):将文本分割成句子、单词或其他可识别的语言单位。
-
词性标注(Part-of-Speech Tagging):识别文本中每个单词的词性(名词、动词、形容词等)。
-
句法分析(Parsing):分析句子的语法结构,确定词语之间的关系。
-
语义分析(Semantic Analysis):理解句子或文本的意义,包括词义消歧和句子意义理解。
-
实体识别(Named Entity Recognition, NER):识别文本中的特定实体,如人名、地点、组织名等。
-
情感分析(Sentiment Analysis):判断文本表达的情感倾向,如正面、负面或中性。
-
机器翻译(Machine Translation):将一种自然语言文本自动翻译成另一种语言。
-
文本生成(Text Generation):自动生成新闻文章、故事、诗歌等文本内容。
-
问答系统(Question Answering):根据用户的问题从大量文本中找到或生成答案。
-
语音识别(Speech Recognition):将人类的语音转换成文本。
-
文本摘要(Text Summarization):自动创建文本的简短摘要,保留关键信息。
传统的 NLP 技术与方法
自然语言处理的技术发展经历了漫长的历程,从早期的规则基础方法,到统计学习方法,再到如今的深度学习方法,每一次技术的进步都推动着 NLP 领域向前迈进。
规则基础方法:语言学的智慧
在 NLP 的早期阶段,语言学家扮演着重要的角色。他们通过分析语言结构和语法规则,制定出一套套规则,指导计算机如何处理语言。这些规则通常以 if-then 的形式存在,例如:
-
-
如果 一个词以“ing”结尾,那么 它很可能是一个动词。
-
如果 一个词后面跟着一个名词,那么 它很可能是一个形容词。
规则基础方法的优点是易于理解和解释,但缺点也很明显:
-
-
规则制定困难: 语言规则复杂多样,很难穷尽所有情况。
-
难以处理歧义: 规则难以处理自然语言中普遍存在的歧义现象。
-
缺乏泛化能力: 规则难以适应不同的语言和领域。
-
优点: 易于理解和解释。
-
缺点:
-
制定规则困难,难以覆盖所有语言现象。
-
难以处理歧义。
-
缺乏泛化能力,难以适应不同的语言和领域。
统计学习方法:数据的力量
随着计算机技术的进步和文本数据的爆炸式增长,统计学习方法开始在 NLP 领域占据主导地位。这些方法利用机器学习算法,从大量的文本数据中学习语言模式,并构建统计模型进行预测。常见的统计学习方法包括:
-
常用的方法
-
-
隐马尔可夫模型 (HMM)
-
用于词性标注、语音识别等任务。
-
支持向量机 (SVM)
-
用于文本分类、情感分析等任务。
-
最大熵模型 (MaxEnt)
-
用于机器翻译、文本摘要等任务。
-
优点:
-
-
可以处理大规模数据。
-
自动学习语言模式。
-
缺点:
-
-
需要大量的标注数据进行训练。
-
模型的可解释性较差。
统计学习方法的优点是可以处理大规模数据,并自动学习语言模式,但缺点是需要大量的标注数据进行训练,而且模型的可解释性较差。
深度学习方法:人工智能的新浪潮
近年来,深度学习技术的兴起为 NLP 领域带来了革命性的变化。深度神经网络,特别是循环神经网络(RNNs)和 Transformer 模型,在 NLP 各项任务中取得了显著的成果。这些模型能够学习复杂的语言特征,并进行更准确的预测。
-
常用的模型
-
-
循环神经网络 (RNNs)
-
擅长处理序列数据,例如文本和语音。
-
长短期记忆网络 (LSTMs)
-
一种特殊的 RNN,能够解决 RNN 的梯度消失问题。
-
Transformer 模型
-
基于注意力机制,能够更好地捕捉句子中单词之间的关系。
-
优点:
-
-
能够处理复杂的语言现象。
-
取得更高的准确率。
-
缺点:
-
-
需要大量的计算资源进行训练。
-
模型的可解释性更差。
深度学习方法的优点是能够处理复杂的语言现象,并取得更高的准确率,但缺点是需要大量的计算资源进行训练,而且模型的可解释性更差。
NLP 的应用领域
NLP 应用广泛,影响着我们生活的方方面面:
-
搜索引擎: 提高搜索结果的相关性和精确度。
-
推荐系统: 根据用户喜好提供个性化推荐。
-
社交媒体监控: 分析用户情绪和社会舆论。
-
语音助手: 例如 Siri、Google Assistant 和 Alexa。
-
自动摘要: 生成文档的简短摘要。
-
客户服务: 通过聊天机器人自动化客户支持。
Python在 NLP 中的应用
Python 是NLP领域最受欢迎的编程语言之一,得益于其丰富的库支持。以下是几个流行的 Python 库及其示例,它们被广泛用于NLP任务:
如下代码中对于一下数据、模型等只需要下载一次,后期实现时,代码中可以追加判断实现只加载一次
1、NLTK (Natural Language Toolkit)
NLTK (Natural Language Toolkit) 是一个领先的平台,用于构建Python程序以处理人类语言数据。它提供了简单易用的接口,以及丰富的库和工具,用于处理文本的各个方面,从基本的操作到复杂的文本分析。NLTK是自然语言处理领域中最早期和最知名的Python库之一。
以下是NLTK的一些主要特点:
-
丰富的功能:
NLTK包含文本处理的各个方面,包括词性标注、命名实体识别、句法分析、语义推理等。
-
教育资源:
NLTK伴随着一本广受欢迎的书籍《Natural Language Processing with Python》,这本书提供了大量的教程和指导,非常适合初学者学习NLP的基础知识。
-
强大的社区:
由于NLTK已经存在了很长时间,它拥有一个庞大的用户和贡献者社区,这意味着网络上有大量的教程、讨论和第三方扩展。
-
数据集和资源:
NLTK提供了许多内置的文本数据集和资源,这些资源对于教学和研究都非常有用。
-
可扩展性:
虽然NLTK自身包含了许多功能,但它也设计得易于扩展,可以与其他NLP和机器学习库一起使用。
-
适合原型开发:
NLTK非常适合进行快速原型开发和教学目的,但在生产环境中,由于性能和可伸缩性的考虑,开发者可能会选择更高效的库,如spaCy。
NLTK的主要缺点是它的速度和效率不如一些新的库,如spaCy,而且它的一些功能可能不如这些新库那么先进或精确。然而,对于教育和研究目的,NLTK仍然是一个非常有价值的资源。
安装
pip install nltk
示例代码
import nltk from nltk.tokenize import word_tokenize # 下载NLTK数据(仅首次使用需要) nltk.download('punkt') # 分词示例 text = "This is a sentence." tokens = nltk.word_tokenize(text) # 输出:['This', 'is', 'a', 'sentence', '.'] print("分词示例", tokens) # 下载 NLTK 数据(仅首次使用需要) nltk.download('averaged_perceptron_tagger') # 词性标注示例 tagged_tokens = nltk.pos_tag(tokens) # 输出:[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('sentence', 'NN'), ('.', '.')] print("词性标注示例", tagged_tokens) """解释 'This' 的词性是 'DT'(determiner,限定词) 'is' 的词性是 'VBZ'(verb,singular present,现在时的单数形式) 'a' 的词性是 'DT'(determiner,限定词) 'sentence' 的词性是 'NN'(noun,singular or mass,名词,单数或集合名词) '.' 的词性是 '.'( punctuation mark,标点符号) 例如, 'This' 是一个限定词,用来限定后面的名词,表明它所指的对象。 'is' 是一个动词,在这里是第三人称单数形式,表示存在。 'a' 也是一个限定词,用来修饰后面的名词 'sentence',表明它所指的对象。 'sentence' 是一个名词,表示一个句子。 '.' 是一个标点符号,表示句子的结束。 词性标注是自然语言处理中的一项基础工作,它有助于计算机理解和解释文本。 """2、spaCy
spaCy是一个开源的高性能自然语言处理库,专注于执行常见的NLP任务,如词性标注、命名实体识别、依存句法分析等。它的设计目标是高效且易于使用,提供了预训练的模型和词向量,并且支持多种语言。
安装
pip install spacy
示例代码
import spacy # 下载spacy en_core_web_sm 模型(仅首次使用需要) spacy.cli.download("en_core_web_sm") # 加载英文模型 nlp = spacy.load("en_core_web_sm") text = "Apple is looking at buying U.K. startup for $1 billion" doc = nlp(text) # 命名实体识别示例 print("命名实体识别结果:") for ent in doc.ents: print(ent.text, ent.label_) # 输出:Apple ORG, U.K. GPE, $1 billion MONEY # 分词、词性标注示例 print("分词和词性标注结果:") for token in doc: print(token.text, token.pos_)输出结果
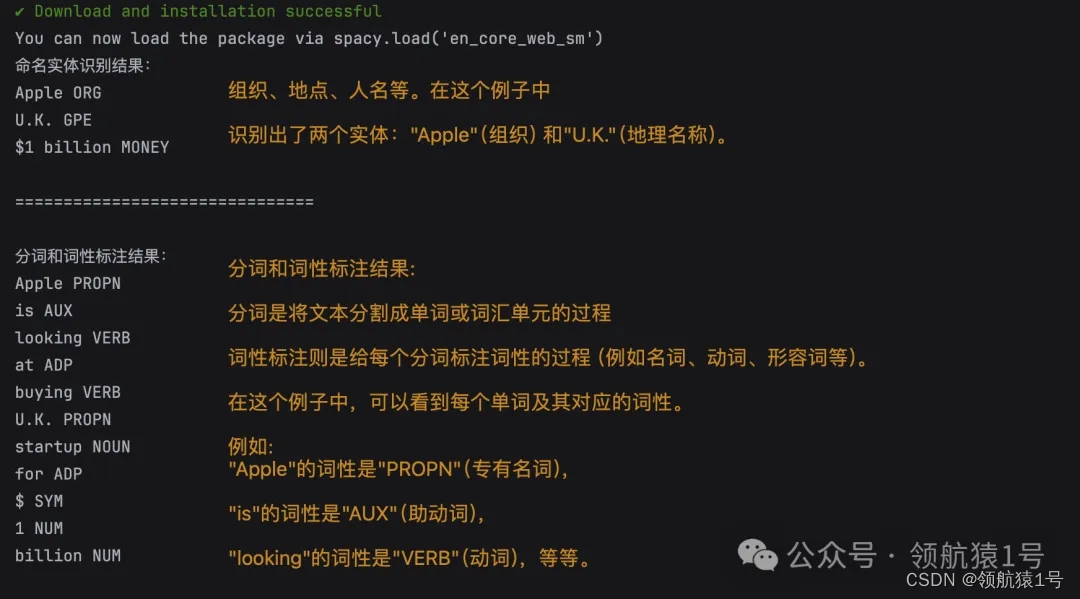
3、TextBlob
TextBlob是一个简单的 Python 库,用于处理文本数据。它提供了一个简单的 API 来进行常见的 NLP 任务(适合初学者),如词性标注、名词短语提取、情感分析、翻译等。TextBlob背后是 NLTK 库,它对 NLTK 进行了封装,使得接口更加友好。
安装
pip install textblob
示例代码
from textblob import TextBlob # 文本情感分析示例【尝试不同的描述看输出结果的不同】 text = "TextBlob is a good library!" # text = "TextBlob is a great library!" blob = TextBlob(text) # 返回浮点数,表示文本情感的极性。-1 表示最负面的情感,1 表示最正面的情感 sentiment = blob.sentiment.polarity # 输出:0.875 print("情感分析结果:", sentiment) # 返回元组,第一个值是情感极性(与 blob.sentiment.polarity 相同),第二个值是情感主观性。情感主观性是一个介于 0 和 1 之间的浮点数,其中 0 表示最客观的情感,1 表示最主观的情感。 sentiment = blob.sentiment # 输出结果:情感分析结果:Sentiment(polarity=0.875, subjectivity=0.6000000000000001) print("情感分析结果:", sentiment)在这段代码中,blob.sentiment.polarity 和 blob.sentiment 两种写法都是用来进行文本情感分析的。但是它们返回的结果是略有不同的。
-
blob.sentiment.polarity:这个写法会返回一个介于 -1 和 1 之间的浮点数,表示文本情感的极性。-1 表示最负面的情感,1 表示最正面的情感。在提供的示例中,情感分析的结果是 0.8,表示这是一个积极的情感。
-
blob.sentiment:这个写法会返回一个元组,其中包含两个值。第一个值是情感极性(与 blob.sentiment.polarity 相同),第二个值是情感主观性。情感主观性是一个介于 0 和 1 之间的浮点数,其中 0 表示最客观的情感,1 表示最主观的情感。在提供的示例中,情感主观性值是 0.2,表示这是一个相对主观的情感。
总结一下,blob.sentiment.polarity 和 blob.sentiment 的主要区别在于后者还会返回情感主观性值。
4、Gensim
Gensim是一个专注于主题建模和文档相似性处理的 Python 库。它使用了高效的算法来处理大型文本集合,能够实现如Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), 和 word2vec 等算法。
安装
pip install gensim pip install numpy
代码示例1
-
适用场景:单文档
使用 preprocess_string 对给定的文本进行预处理。preprocess_string 是 gensim.parsing.preprocessing 模块中的一个函数,它可以移除文本中的停用词,转换为小写等。
-
产生的作用结果:
预处理后的文本被用于创建一个包含该预处理文本的词典和语料库。这可以更好地处理单文档,因为它可以更好地保留文档的结构和信息。
from gensim import corpora from gensim.models import LdaModel from gensim.parsing.preprocessing import preprocess_string # 文本预处理 text = "Gensim is a Python library for topic modeling, document indexing, and similarity retrieval with large corpora." preprocessed_text = preprocess_string(text) # 创建语料库 dictionary = corpora.Dictionary([preprocessed_text]) corpus = [dictionary.doc2bow(preprocessed_text)] # 训练LDA主题模型 lda_model = LdaModel(corpus, num_topics=1, id2word=dictionary) print("LDA主题模型结果:", lda_model.print_topics())代码示例 2
-
适用场景:多文档
将每个文档拆分为单词列表。这是基于 bag of words(词袋模型)的预处理方式,它忽略了单词的顺序和上下文信息,仅将文档视为单词的集合。
-
产生的作用结果:
预处理后的文本被用于创建一个词典和语料库,其中每个文档都被视为单词的集合。这可以更好地处理多文档,因为它可以更好地发现文档之间的相似性和主题。
from gensim import corpora, models from gensim.models import LdaModel from gensim.parsing.preprocessing import preprocess_string # 文档集合 documents = ["This is a document.", "This is another document."] # 构建词典和创建语料库 texts = [[word for word in document.lower().split()] for document in documents] dictionary = corpora.Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts] # 训练 LDA 主题模型 lda_model = models.LdaModel(corpus, id2word=dictionary, num_topics=2) print("LDA主题模型结果:", lda_model.print_topics())5. Transformers (by Hugging Face)
Transformers 库由 Hugging Face 公司开发,提供了大量预训练的模型,如BERT、GPT、RoBERTa、T5等,这些模型可以用于文本分类、信息抽取、问答系统、文本生成等多种NLP任务。Transformers库的一个关键特点是它支持多种深度学习框架,如T tensorFlow 和 PyTorch。
安装
pip install transformers pip install tensorflow 或 pip install torch torchvision torchaudio
示例代码
from transformers import pipeline # 加载文本生成模型 generator = pipeline("text-generation") # 文本生成示例 text = "In the beginning" result = generator(text, max_length=50) print("情感分析结果:", result[0]["generated_text"]) # 加载情感分析模型 classifier = pipeline("sentiment-analysis") # 文本情感分析示例 text = "Transformers is an exciting library for NLP tasks." result = classifier(text) print("情感分析结果:", result)5、Pattern
Pattern 是一个用于 Python 的 Web 挖掘模块,它提供了 NLP 工具、机器学习、网络爬虫和数据挖掘功能。它可以用于情感分析、词性标注、命名实体识别等任务,并且包含了一些用于数据检索和处理的API。
安装
pip install pattern
代码示例
from pattern.en import parse, Sentence, entiment # 情感分析示例 text = "This is a great day!" print("情感分析结果:", sentiment(text)) # 输出:(0.7, 0.0) # 句法分析示例 text = "Pattern is a web mining and natural language processing module for Python." sentence = Sentence(text) parsed_sentence = parse(sentence, lemmata=True) print("句法分析结果:", parsed_sentence)6、StanfordNLP
StanfordNLP是斯坦福大学开发的一个NLP库,它提供了一系列语言处理工具。它是CoreNLP Java库的Python封装,支持多种语言的NLP任务,如词性标注、命名实体识别等。
安装
pip install allennlp
代码示例
import stanfordnlp # 加载英文模型 nlp = stanfordnlp.Pipeline(lang="en") # 句法分析示例 text = "This is a sentence." doc = nlp(text) print(doc.sentences[0].print_dependencies())
7、AllenNLP
AllenNLP是由Allen Institute for AI开发的一个开源NLP研究库,专注于深度学习和NLP。它提供了一系列预训练模型和框架,用于语义角色标注、文本蕴含、机器阅读理解等高级NLP任务。
安装
pip install allennlp
代码示例
from allennlp.predictors.predictor import Predictor # 加载命名实体识别模型 predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/ner-model-2020.02.10.tar.gz") # 文本命名实体识别示例 text = "AllenNLP is a powerful library for NLP tasks." result = predictor.predict(sentence=text) print("命名实体识别结果:", result)8、其他
-
Scikit-learn:
虽然Scikit-learn主要是一个机器学习库,但它也提供了一些基础的NLP功能,如特征提取、文本预处理等。它广泛用于分类、回归、聚类等任务,并且与其他Python科学计算包(如NumPy和SciPy)有良好的集成。
-
Flair:
Flair是一个由Humboldt University of Berlin开发的NLP库,它提供了一种简单而强大的方法来使用预训练的模型。Flair的特点是它的词嵌入方法,它结合了经典的词嵌入和最新的上下文化词嵌入技术。
-
Flair:
Flair是一个由Humboldt University of Berlin开发的NLP库,它提供了一种简单而强大的方法来使用预训练的模型。Flair的特点是它的词嵌入方法,它结合了经典的词嵌入和最新的上下文化词嵌入技术。
总结:选择合适的 NLP 库取决于您的具体需求和项目要求。每个库都有其优势和局限性,需要根据任务的类型、性能要求、易用性和社区支持等因素进行选择。
NLP 的挑战
尽管 NLP 取得了巨大进步,但仍然面临一些挑战:
-
歧义解析: 自然语言的歧义性,同一句话在不同语境下可能含义不同。
-
多语言处理: 世界上语言众多,开发能够处理多种语言的 NLP 系统是一项挑战。
-
语言变化: 语言随着时间推移而演变,需要 NLP 系统不断适应。
-
文化差异: 不同文化背景下的语言使用存在差异,需要 NLP 系统理解和适应。
NLP 的未来展望
NLP 发展迅速,未来将会更加智能和灵活:
-
多模态学习: 将 NLP 与视觉和听觉信息结合,实现更丰富的交互体验。
-
更强大的语言模型: 能够更好地理解和生成自然语言。
-
个性化 NLP: 为用户提供更定制化的语言体验。
NLP 作为人工智能领域的关键技术,将继续推动人机交互的进步,并在各个领域发挥重要作用。随着技术的不断发展,NLP 的未来充满无限可能。
更多关于 AI 全栈知识,请看原文:https://www.yuque.com/lhyyh/ai
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-



