
PaddleNLP:Docker下搭建基于ES的语义检索系统
文章目录
- 1. 什么是语义检索?
- 2. 安装部署
- 2.1 下载源码包
- 2.2 配置解释
- 2.3 开始安装
- 3. 使用
- 4. 文末
1. 什么是语义检索?
语义检索(也称基于向量的检索):指检索系统不再拘泥于用户 Query 字面本身(例如:sql查询的like),而是能精准 捕捉到用户 Query 后面的真正意图 并以此来搜索,从而更准确地向用户返回最符合的结果。
原理是通过使用最先进的 语义索引模型找到文本的向量 表示,在高维向量空间中对它们进行索引,并度量查询向量与索引文档的相似程度,从而解决了关键词索引带来的缺陷。
目前有一个很火的国内开源项目(pp飞桨的PaddleNLP),我们可以基于它的源码示例,搭建一套基于ES的语义检索系统。
项目地址:https://github.com/PaddlePaddle/PaddleNLP
本文主要是参照官网的示例来操作的:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/semantic-search
但是由于按照教程去部署,遇到了很多问题,所以我把源码下载下来,在服务器直接使用docker去安装了
本文准备了如下内容:
- Linux系统(本文使用的是CentOS 7,8核CPU:x86_64)
- Docker(本文使用的版本为:20.10.17,docker-compose版本为1.29.2)
- PaddleNLP源码(使用稳定的2.6.0版本)
2. 安装部署
2.1 下载源码包
首先下载源码包到本地(官方也推荐的2.6.0版本版本):https://codeload.github.com/PaddlePaddle/PaddleNLP/tar.gz/refs/tags/v2.6.0
上传到服务器目录,并解压:
tar -zxvf PaddleNLP-2.6.0.tar.gz
2.2 配置解释
进入解压后的docker目录(/PaddleNLP-2.6.0/pipelines/docker),使用ls命令并可以看到如下内容:
cd {当前解压目录}/PaddleNLP-2.6.0/pipelines/docker
docker-compose的内容如下,主要是启动Elasticsearch和pipelines-cpu-serving这两个服务,里面已经做了注释:
version: "3" services: elasticsearch: #定义服务名 # This will start an empty Elasticsearch instance (so you have to add your documents yourself) #image: "elasticsearch:8.3.3" # Docker镜像的版本 8.3.3 ,注释表示不使用该配置 image: "docker.elastic.co/elasticsearch/elasticsearch:8.3.3" # Docker镜像的地址 container_name: es01 # Docker容器的名称 ports: - 9200:9200 # 映射到主机的端口 restart: on-failure # 当程序运行失败时自动重启容器 environment: # 对容器添加环境变量 - discovery.type=single-node - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - cluster.routing.allocation.disk.threshold_enabled=false - xpack.security.enabled=false pipelines-cpu-serving: # 定义服务名 image: paddlepaddle/paddlenlp:pipelines-cpu-1.0 # Docker镜像的地址 build: # 构建Docker镜像的相关设置 context: . # Docker的构建上下文路径 dockerfile: Dockerfile # Dockerfile的文件名 container_name: pip01 # Docker容器的名称 network_mode: host # 网络模式设置为host restart: on-failure # 当程序运行失败时自动重启容器 volumes: # 数据卷,将主机的目录挂载至容器 - .:/paddle environment: # 对容器添加环境变量 - API_ENDPOINT=http://127.0.0.1:8891 - PIPELINE_YAML_PATH=rest_api/pipeline/semantic_search.yaml depends_on: # 定义容器启动顺序 - elasticsearch command: /bin/bash -c "sleep 15 && cd /paddle && sh start_compose.sh && tail -f /dev/null" # 容器启动后执行的命令 networks: default: # 默认的网络配置 name: elastic # 网络的名称继续看看启动pipelines-cpu-serving服务里面的配置start_compose.sh配置:
#!/bin/bash cd /root/PaddleNLP/pipelines/ # linux python utils/offline_ann.py --index_name dureader_robust_query_encoder \ --doc_dir data/dureader_dev \ --query_embedding_model rocketqa-zh-nano-query-encoder \ --passage_embedding_model rocketqa-zh-nano-para-encoder \ --port 9200 \ --host localhost \ --embedding_dim 312 \ --delete_index # 使用端口号 8891 启动模型服务 nohup python rest_api/application.py 8891 > server.log 2>&1 & # 在指定端口 8502 启动 WebUI nohup python -m streamlit run ui/webapp_semantic_search.py --server.port 8502 > client.log 2>&1 &可以看出,这个docker-compose的配置,已经帮我完成了官方文档里面的所有操作(包括一些示例数据的生成等):https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/semantic-search

2.3 开始安装
使用docker-compse启动es(网络较好的情况下,不用等太久):
docker-compose -f docker-compose.yml up -d elasticsearch
继续使用docker-compose启动paddle(网络较好的情况下,也需要等很久,镜像包超过8个G):
docker-compose -f docker-compose.yml up -d pipelines-cpu-serving
查看是否已经安装成功:
docker ps -a | grep -E 'paddle|es'

可以看到已经安装成功了,继续查看paddle的日志,可以看到日志显示正在下载示例数据:
docker logs -f pip01

日志内容大致如下:
[root@xx docker]# docker logs -f pip01 > logs.txt INFO - pipelines.utils.import_utils - Fetching from https://paddlenlp.bj.bcebos.com/applications/dureader_dev.zip to `data/dureader_dev` /bin/sh: 1: docker: not found WARNING - pipelines.utils.doc_store - Tried to start Elasticsearch through Docker but this failed. It is likely that there is already an existing Elasticsearch instance running. INFO - pipelines.utils.preprocessing - Converting data/dureader_dev/dureader_dev/dev537.txt INFO - pipelines.utils.preprocessing - Converting data/dureader_dev/dureader_dev/dev251.txt INFO - pipelines.utils.common_utils - Using devices: PLACE(CPU) INFO - pipelines.utils.common_utils - Number of GPUs: 0 [2024-03-15 09:12:26,049] [ INFO] - Already cached /root/.paddlenlp/models/rocketqa-zh-nano-query-encoder/rocketqa-zh-nano-query-encoder.pdparams [2024-03-15 09:12:28,896] [ INFO] - Already cached /root/.paddlenlp/models/rocketqa-zh-nano-para-encoder/rocketqa-zh-nano-para-encoder.pdparams [2024-03-15 09:12:31,342] [ INFO] - We are using to load 'rocketqa-zh-nano-query-encoder'. [2024-03-15 09:12:31,343] [ INFO] - Already cached /root/.paddlenlp/models/rocketqa-zh-nano-query-encoder/ernie_3.0_nano_zh_vocab.txt [2024-03-15 09:12:31,395] [ INFO] - tokenizer config file saved in /root/.paddlenlp/models/rocketqa-zh-nano-query-encoder/tokenizer_config.json [2024-03-15 09:12:31,396] [ INFO] - Special tokens file saved in /root/.paddlenlp/models/rocketqa-zh-nano-query-encoder/special_tokens_map.json [2024-03-15 09:12:31,397] [ INFO] - We are using to load 'rocketqa-zh-nano-para-encoder'. [2024-03-15 09:12:31,398] [ INFO] - Already cached /root/.paddlenlp/models/rocketqa-zh-nano-para-encoder/ernie_3.0_nano_zh_vocab.txt [2024-03-15 09:12:31,446] [ INFO] - tokenizer config file saved in /root/.paddlenlp/models/rocketqa-zh-nano-para-encoder/tokenizer_config.json [2024-03-15 09:12:31,447] [ INFO] - Special tokens file saved in /root/.paddlenlp/models/rocketqa-zh-nano-para-encoder/special_tokens_map.json INFO - pipelines.utils.logger - Logged parameters: {'processor': 'TextSimilarityProcessor', 'tokenizer': 'NoneType', 'max_seq_len': '0', 'dev_split': '0.1'} INFO - pipelines.document_stores.elasticsearch - Updating embeddings for all 1398 docs ... Updating embeddings: 10000 Docs [05:15, 31.74 Docs/s]至此,安装已经成功了,接下来我们使用下。
3. 使用
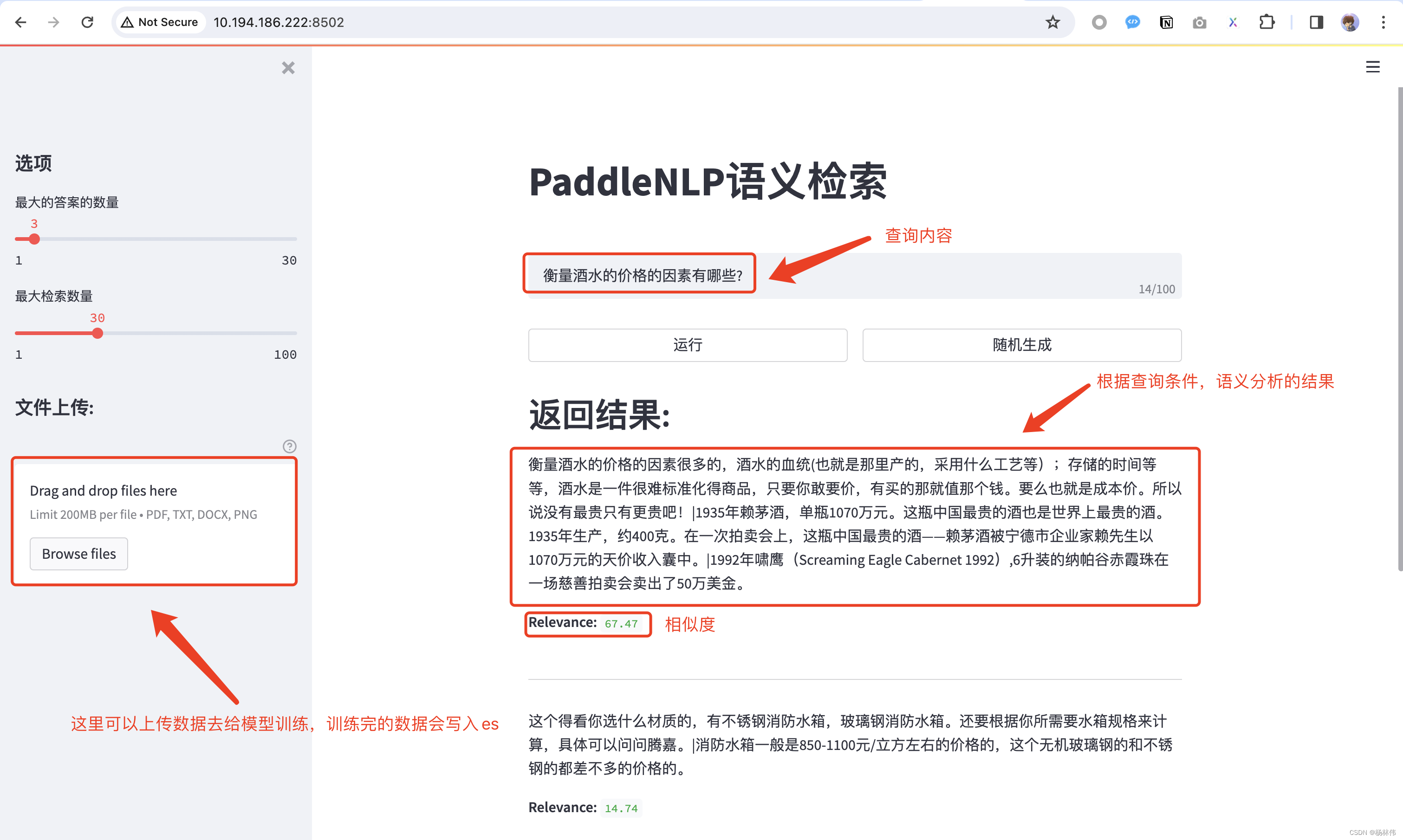
浏览器访问:http://服务器地址:8502,可以看到检索系统运行正常,我们可以输入内容进行语义搜索,这里就使用了默认的提示搜索
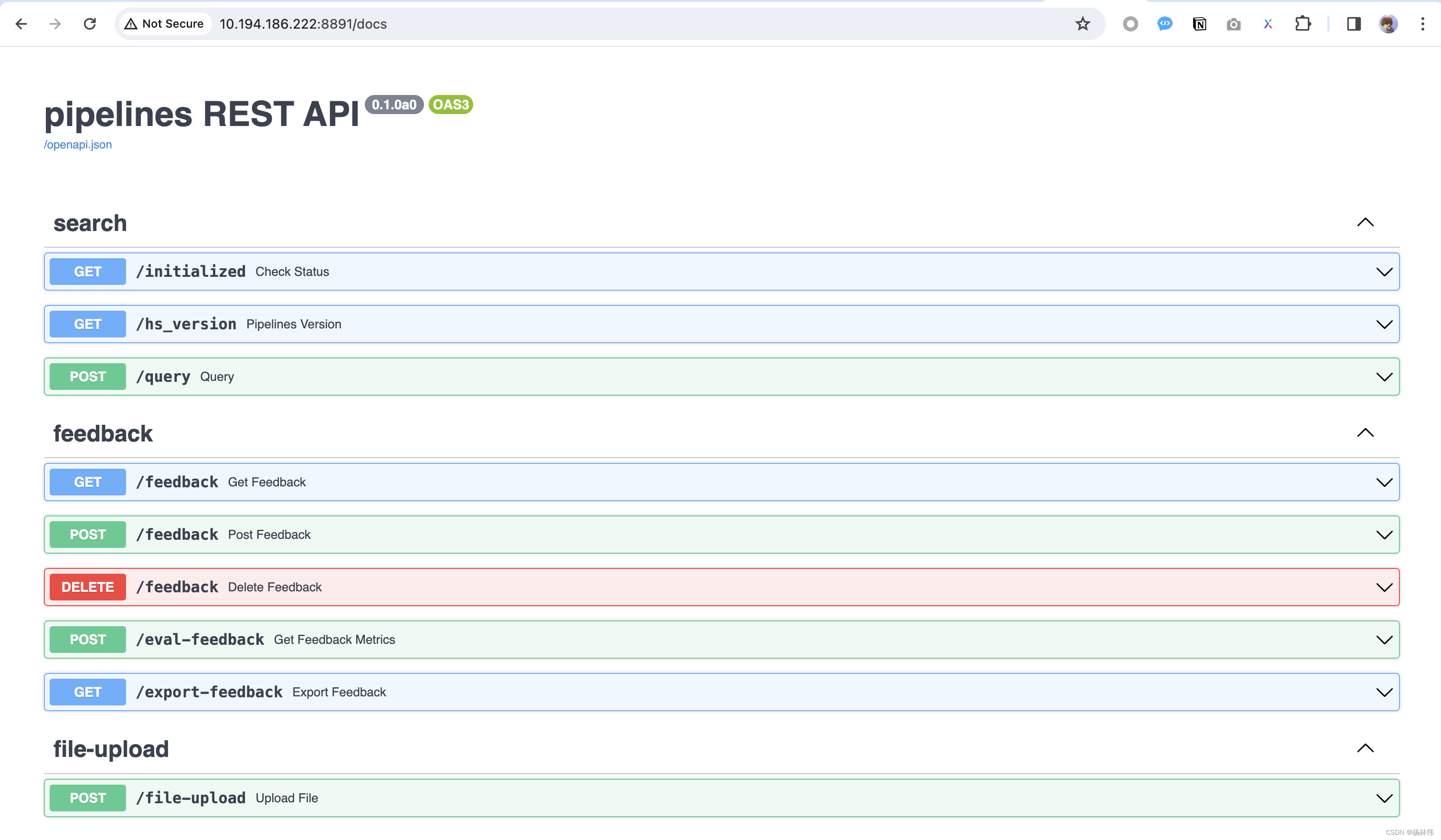
同时也可以查询这个界面的API接口:http://服务器地址:8891/docs
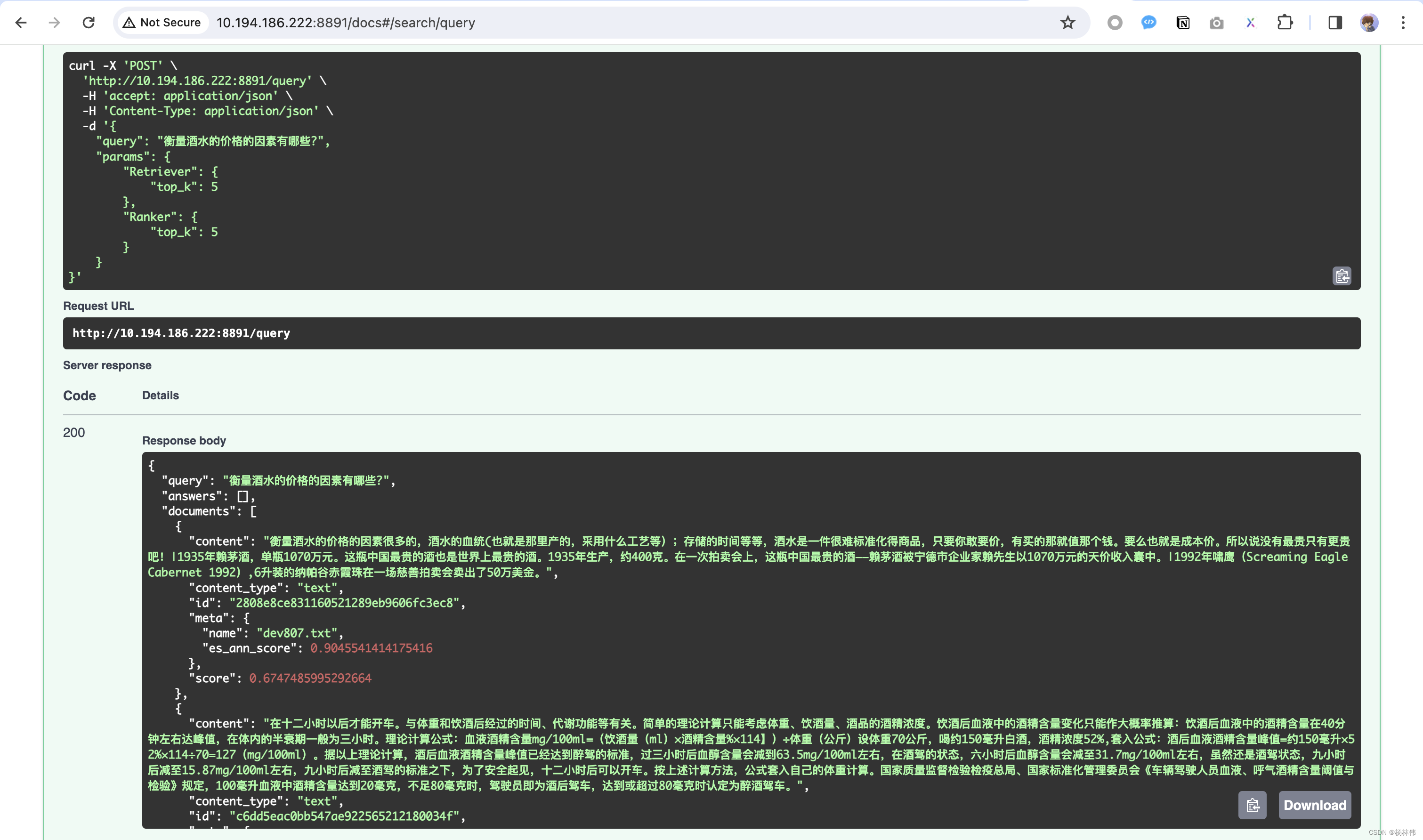
调试query接口:
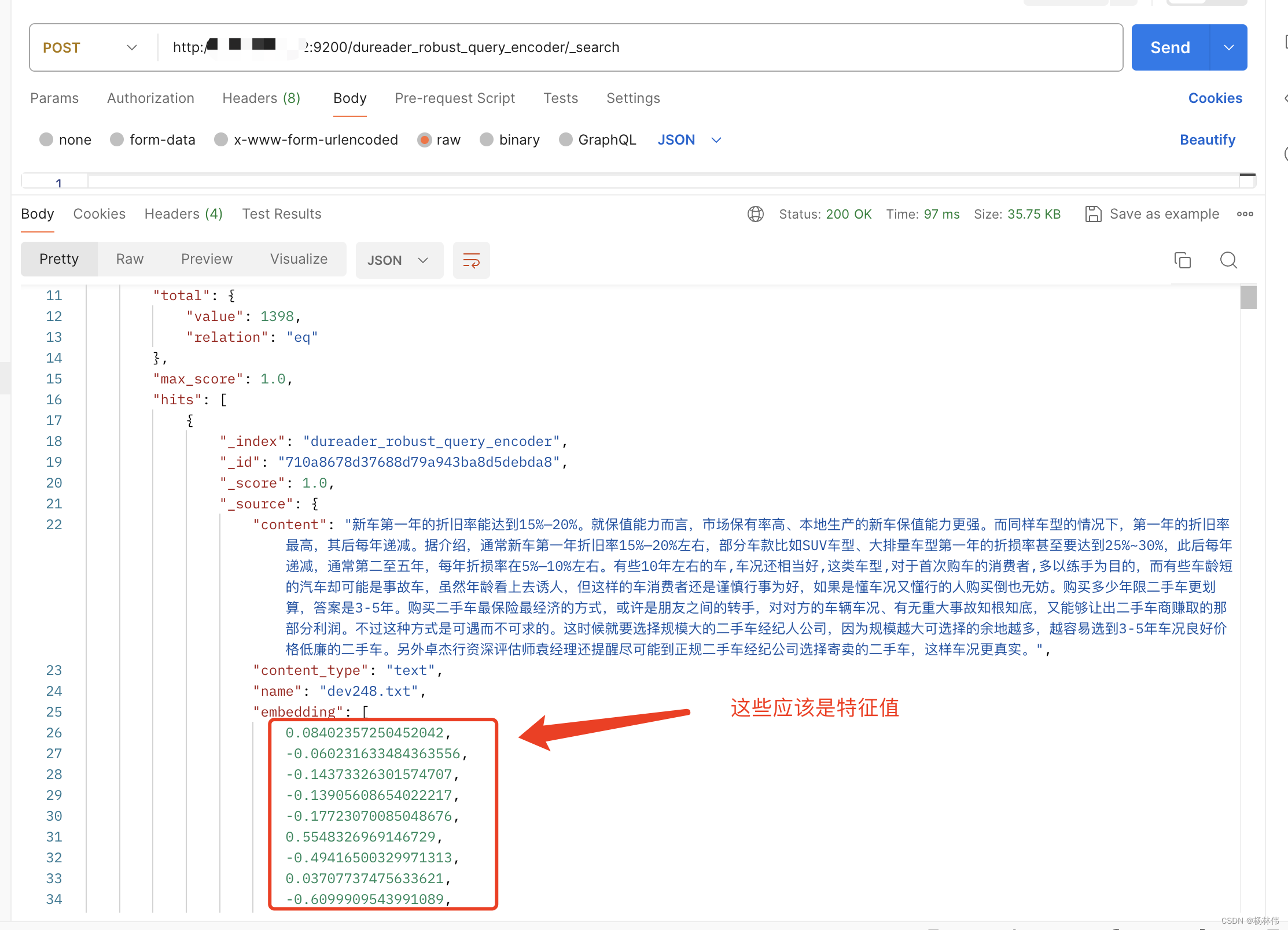
我们使用postman查询es的内容:http://服务器地址:9200/dureader_robust_query_encoder/_search
经过前面的步骤,博主理解它的整个流程应该如下:
- 首先,输入一段查询的文字,然后通过模型计算出这段文字的特征值(或者说是该文字在向量空间中的位置)。
- 接着,利用计算出的特征值与存储在Elasticsearch(ES)中其他文本的特征值进行比对和计算,以找出最匹配的结果。
- 最后,返回匹配的内容。
这其中涉及到的是信息检索(Information Retrieval)和自然语言处理(NLP)的知识。
4. 文末
最终,我们成功地在Docker环境下搭建了基于ES的语义检索系统。全过程的整体来看并非易事,出现了各种问题,我们现在看到的是一个成功的版本。
一个常见的问题就是:出现提示"[Paddle]Error: Your machine doesn‘t support AVX, but the installed PaddlePaddle is avx core, you…"。
之前我是在使用装有M2芯片的Mac笔记本并通过使用Docker Desktop进行安装。这里的错误提示的原因可能是与我笔记本的CPU架构不匹配,我的笔记本的硬件并不支持这种架构的PaddlePaddle。
我尝试使用命令 “docker buildx build --load --platform linux/amd64 -t” 来声明为X86架构进行操作,且在容器内下载不需支持AVX指令集的paddlepaddle版本,但是依然未能解决问题。
最终我选择在满足环境需求的服务器(CentOS 7)上进行操作。当然,用户也可以在自己 GPU 硬件环境进行,速度更快。
最后,希望大家都能安装成功并使用,谢谢大家的阅读,希望能帮助到大家,本文完!



