
【AI大模型应用开发】【LangFuse: LangSmith平替,生产级AI应用维护平台】0. 快速上手 - 基本功能全面介绍与实践(附代码)



- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
本站文章一览:
前面我们介绍了LangChain无缝衔接的LangSmith平台,可以跟踪程序运行步骤,提供详细调试信息,同时支持数据集收集和自动化测试评估等功能,极大方便了AI大模型应用程序的开发过程。
本文来介绍另一款生产级AI应用维护平台:LangFuse,它是开源的,是LangSmith 的平替,并且它可集成 LangChain,同时也可直接对接 OpenAI API。
官方网站:https://langfuse.com/
项目地址:https://github.com/langfuse
0. 环境准备
(1)先注册,登录,官网地址在上面
(2)创建Project

(3)生成私钥和公钥


一定要复制并记录下这个私钥和公钥,关闭这个窗口后,私钥就再也看不到了。
(4)本地安装 langfuse
pip install --upgrade langfuse
1. 开始使用
LangFuse有两种集成方式:
- OpenAI API集成
- LangChain集成
在运行之前,先将你的公钥和私钥放到环境变量中。例如.env文件中加入:
LANGFUSE_SECRET_KEY = "sk-lf-xxxxx" LANGFUSE_PUBLIC_KEY = "pk-lf-xxxxx"
这样才能使你的程序与你在LangFuse官网上建立的跟踪项目链接起来。
不了解怎么写.env文件的可以看下我前面的文章:【AI大模型应用开发】0. 开篇,用OpenAI API写个Hello World !
1.1 OpenAI API集成方式
集成步骤:
(1)引入langfuse中的openai:from langfuse.openai import openai,用这个才能集成langfuse
(2)使用Langfuse实例的trace函数,传入一些个人和项目信息
(3)openai接口调用,多了一个trace_id参数
from datetime import datetime from langfuse.openai import openai ## 1. 引入langfuse中的openai from langfuse import Langfuse import os ## 2. 使用Langfuse实例的trace函数,传入一些个人和项目信息 trace = Langfuse().trace( name = "hello-world", user_id = "同学小张", release = "v0.0.1" ) completion = openai.chat.completions.create( name="hello-world", model="gpt-3.5-turbo", messages=[ {"role": "user", "content": "对我说'Hello, World!'"} ], temperature=0, trace_id=trace.id, ## 3. openai接口调用,多了一个trace_id参数 ) print(completion.choices[0].message.content) ## 输出:Hello, World!运行之后看下LangFuse平台,应该能看到你的项目和调用了。


1.2 LangChain集成方式
通过 LangChain 的回调集成。
集成步骤:
(1)从langfuse中引入CallbackHandler:from langfuse.callback import CallbackHandler
(2)在CallbackHandler中设置个人和项目信息
(3)正常创建LangChain应用和流程
(4)invoke时,将CallbackHandler填入config参数中:config={"callbacks":[handler]}
from langfuse.callback import CallbackHandler handler = CallbackHandler( trace_name="SayHello", user_id="同学小张", ) from langchain_openai import ChatOpenAI from langchain.prompts import PromptTemplate from langchain.schema.output_parser import StrOutputParser from langchain.schema.runnable import RunnablePassthrough from langchain.schema import HumanMessage from langchain.prompts.chat import HumanMessagePromptTemplate from langchain.prompts import ChatPromptTemplate model = ChatOpenAI(model="gpt-3.5-turbo-0613") prompt_template = """ 我的名字叫【{name}】,我的个人介绍是【{description}】。 请根据我的名字和介绍,帮我想一段有吸引力的自我介绍的句子,以此来吸引读者关注和点赞我的账号。 """ prompt = ChatPromptTemplate.from_messages([ HumanMessagePromptTemplate.from_template(prompt_template) ]) # 定义输出解析器 parser = StrOutputParser() chain = ( {"name":RunnablePassthrough(), "description":RunnablePassthrough() } ## 这里是给prompt的输入,两个参数 | prompt | model | parser ) ## invoke的第一个参数,传入json格式的参数,key与prompt中的参数名一致 response = chain.invoke({'name': '同学小张', 'description': '热爱AI,持续学习,持续干货输出'}, config={"callbacks":[handler]}) print(response)运行之后看下LangFuse平台,应该能看到你的项目和调用了。

2. 详细信息查看 - Traces页面
使用Traces页面,可以看到你每次程序运行的详细过程,包括每一步的输入、输出、耗时、token数等。
(1)进入Traces,可以看到你所有的运行目录。

(2)点击上方的任一ID,可以进入到本次运行的详细跟踪页面。该页面包含了本次运行的过程:详细执行步骤(右侧)。点击任一步骤,可以在左侧看到本步骤的输入和输出,以及耗时和token数(图中的148->241表示输入148token,输出241token)。

有了这个页面,你可以轻易的跟踪输入输出是否有问题,哪一步有问题,从而更好的调优你的程序。这个比自己打日志的信息更详细和更好用多了。
3. 在线数据标注和收集
Langfuse与LangSmith一样,也可以在线进行数据标注和收集。
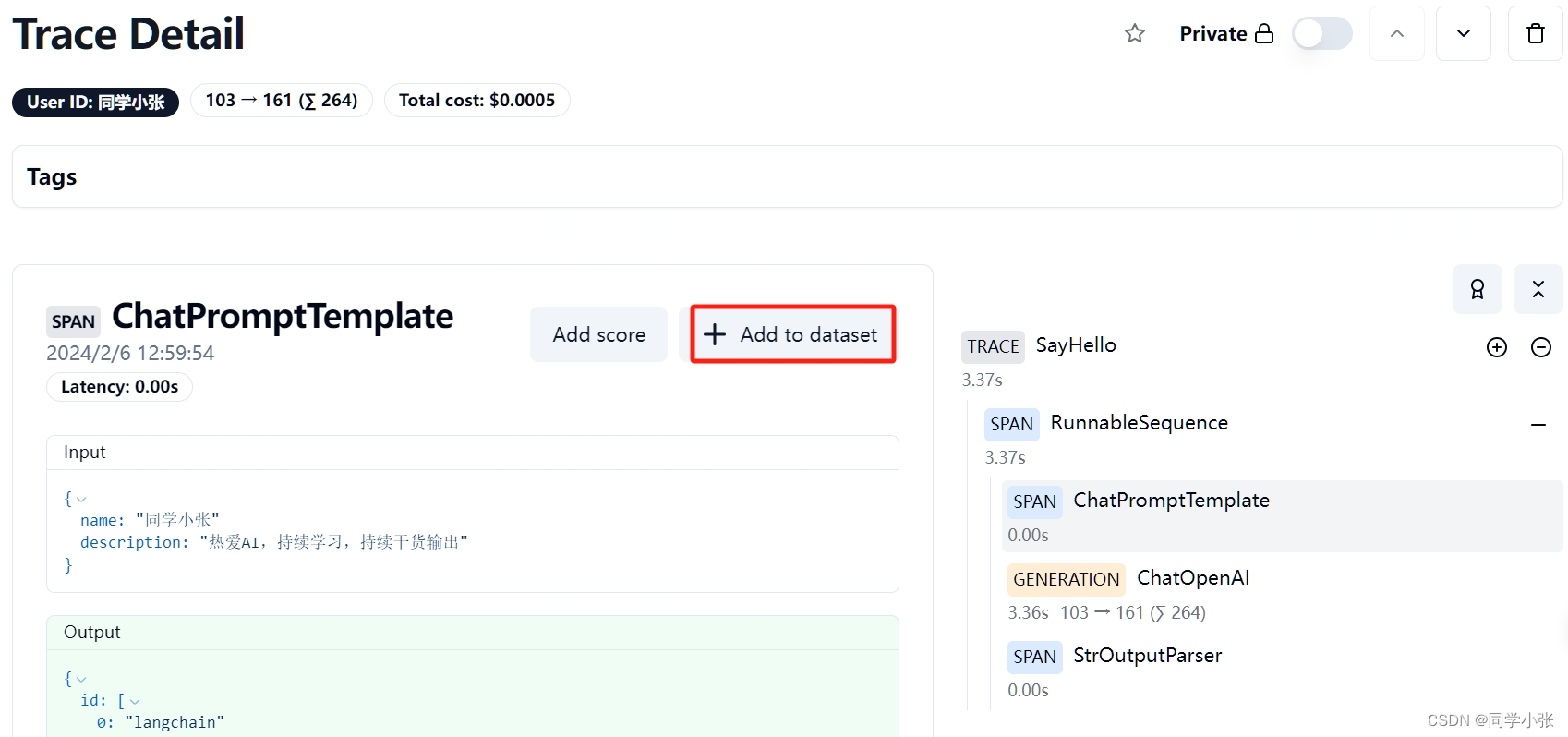
(1)首先你需要先创建一个数据集的名称。
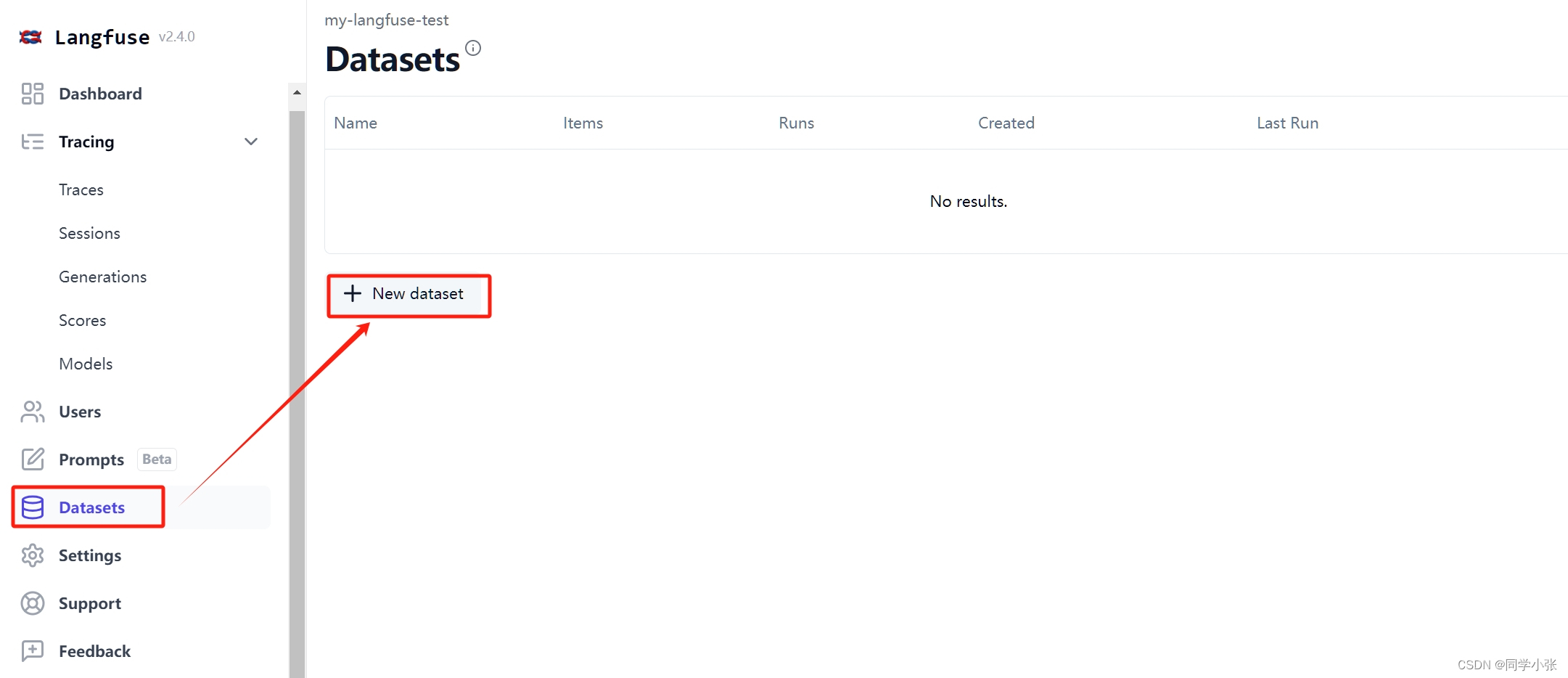
(2)如果没有事先创建数据集名称,在下面这一步无法选择dataset… 这是操作不如LangSmith的地方

(3)创建了数据集名称之后,下面这一步就可以正常添加了

(4)然后你就可以看到你添加的数据集了

4. 本地数据集的导入
Langfuse除了支持在线的数据标注和收集,也支持从本地导入数据集。
以AGI课堂中的数据集例子给大家做演示。
数据集格式如下( .jsonl文件 ):outlines、user_input 以及 label字段,其中label为标注,也就是输出结果。
{"outlines": "Assistants API\n✅1. OpenAI 给了我们更大空间\n✅2. 原生 API、GPTs、Assistants API、国产/开源大模型选型参考\n✅3. Assistants API 的主要能力\n✅4. 做一个自己的 GPT\n 1. 创建 assistant\n 2. 管理 thread\n 3. 添加 message\n 4. 开始 run\n 5. 中控调度\n 6. Function Calling\n 7. Code Interpreter\n 8. RAG", "user_input": "别进reddit的中文话题,那是最没营养的区域", "label": "N"} {"outlines": "【神秘嘉宾】大模型时代的AI产品新挑战\n1. AI 能力演进路线\n✅2. LLMs 带来的变化\n✅3. 如何将大模型落地到实际场景中\n✅4. LLMs 存在哪些问题\n✅5. LLMs 落地三要素\n✅6. LLMs 短期、中期和长期落地方向", "user_input": "对话式交互也不是所有场景都合适", "label": "N"}接口:create_dataset_item
实现代码:
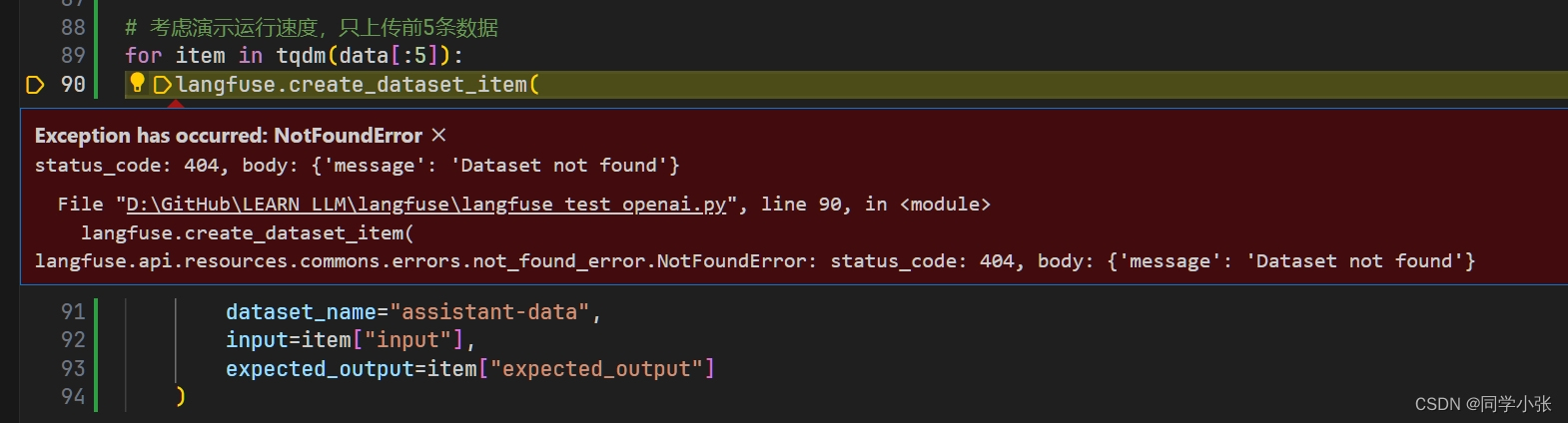
import json data = [] with open('D:\GitHub\LEARN_LLM\langsmith\my_annotations.jsonl','r',encoding='utf-8') as fp: for line in fp: example = json.loads(line.strip()) item = { "input": { "outlines": example["outlines"], "user_input": example["user_input"] }, "expected_output": example["label"] } data.append(item) from langfuse import Langfuse from langfuse.model import CreateDatasetRequest, CreateDatasetItemRequest from tqdm import tqdm # init langfuse = Langfuse() # 考虑演示运行速度,只上传前5条数据 for item in tqdm(data[:5]): langfuse.create_dataset_item( dataset_name="assistant-data", ## 注意:这个dataset_name需要提前在Langfuse后台创建 input=item["input"], expected_output=item["expected_output"] )注意:dataset_name的名称需要首先在langfuse平台中手动创建。否则报错:
运行成功后,langfuse中可以看到上传的数据:

5. 数据集的测试与评估
5.1 定义评估标准
这里定义一个简单的标准,就是比较输出和期望的结果是否一样。
def simple_evaluation(output, expected_output): return output == expected_output
5.2 定义Chain
在这里定义你的待评估的主要数据处理流程程序,也就是你的大模型应用。
from langchain.prompts import PromptTemplate need_answer=PromptTemplate.from_template(""" ********* 你是AIGC课程的助教,你的工作是从学员的课堂交流中选择出需要老师回答的问题,加以整理以交给老师回答。 课程内容: {outlines} ********* 学员输入: {user_input} ********* 如果这是一个需要老师答疑的问题,回复Y,否则回复N。 只回复Y或N,不要回复其他内容。""") model = ChatOpenAI(temperature=0,model_kwargs={"seed":42}) parser = StrOutputParser() chain_v1 = ( need_answer | model | parser )5.3 运行测试
下面的代码中几个关键点:
(1)ThreadPoolExecutor用来开启线程池,并行测试数据集内的测试数据,可不用,串行测试即可,只是需要花更多时间。
(2)获取数据集的接口: dataset = langfuse.get_dataset(dataset_name)
(3)通过callback与LangChain集成:handler = item.get_langchain_handler(run_name=run_name)
(4)评分:handler.root_span.score,其中value为上面咱们自定义的评估标准函数
(5)本次测试的名称:run_name,也就是“v1-xxxxx”。
from concurrent.futures import ThreadPoolExecutor from functools import partial from langfuse import Langfuse langfuse = Langfuse() def run_evaluation(chain, dataset_name, run_name): dataset = langfuse.get_dataset(dataset_name) def process_item(item): handler = item.get_langchain_handler(run_name=run_name) # Assuming chain.invoke is a synchronous function output = chain.invoke(item.input, config={"callbacks": [handler]}) # Assuming handler.root_span.score is a synchronous function handler.root_span.score( name="accuracy", value=simple_evaluation(output, item.expected_output) ) print('.', end='',flush=True) # Using ThreadPoolExecutor with a maximum of 10 workers with ThreadPoolExecutor(max_workers=4) as executor: # Map the process_item function to each item in the dataset executor.map(process_item, dataset.items) run_evaluation(chain_v1, "assistant-data", "v1-"+str(uuid.uuid4())[:8])5.4 运行结果
测试结果:

每个数据的测试结果及详情:
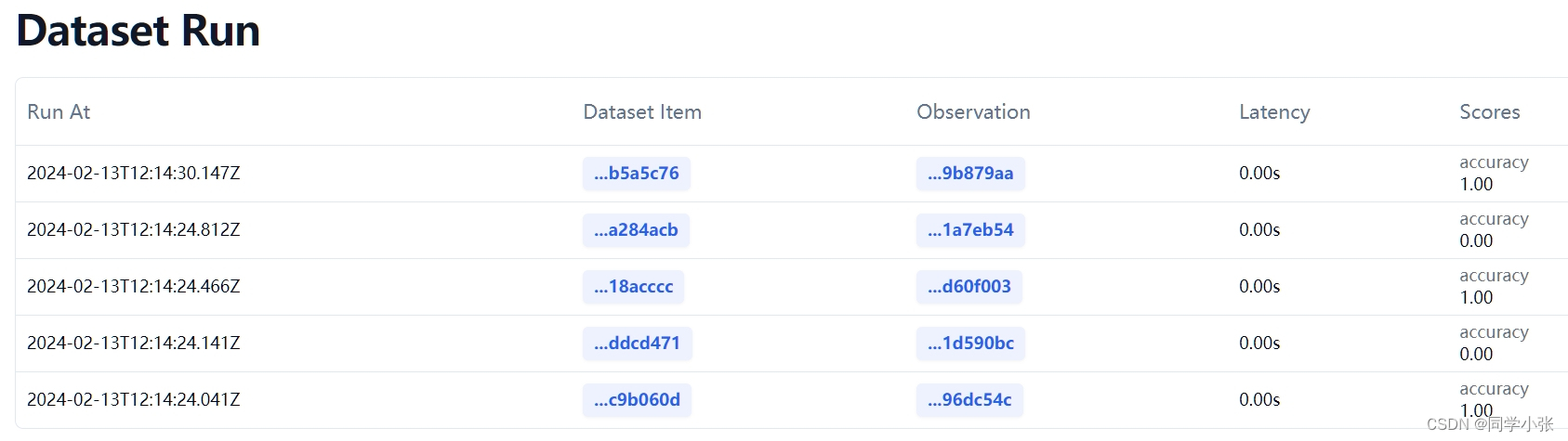
本文到这里就结束了,在本文中,我们全面介绍了Langfuse平台的基本功能:从程序运行监控、跟踪,到数据集的创建、建立自己的评估标准,再到实际运行一个测试,得到测试结果。简单的使用,相信大家能对langfuse平台有一个全面的认识。
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
本站文章一览:



