
Kafka(一)使用Docker Compose安装单机Kafka+Kafka UI+Prometheus JMX Exporter



文章目录
- Kafka中涉及到的术语
- Kafka镜像选择
- Kafka官方镜像
- Docker Hub社区镜像
- Kafka UI镜像选择
- Docker Compose文件
- Kafka配置项说明
- KRaft vs Zookeeper
- 和KRaft有关的配置
- 关于Controller和Broker的概念解释
- Listener的各种配置
- 集成Prometheus JMX Exporter
- Kafka UI配置项说明
- 测试
- 启用JMX或集成Prometheus后执行kafka命令出现Address already in use
- 解决方案
- Kafka集群
- 一个基本的高可用Kafka集群需要多少个节点?
- Kafka集群示例配置
- Kafka vs RabbitMQ vs Pulsar性能对比
Kafka中涉及到的术语
对于Kafka中经常用到的术语,可参考confluent的官方文档,这里不再赘述。
Kafka镜像选择
Kafka官方镜像
2024-05-14更新:官方在3.7.0中引入了官方Docker镜像,具体使用和例子请参考官方文档 > Docker部分.
由于写文章的时候还没有官方镜像,文章剩余内容均针对的是Docker Hub社区镜像
Docker Hub社区镜像
镜像选择Docker Hub上使用最多的bitnami Kafka,主要注意的点是环境变量和Kafka配置的映射关系
Additionally, any environment variable beginning with KAFKA_CFG_ will be mapped to its corresponding Apache Kafka key. For example, use KAFKA_CFG_BACKGROUND_THREADS in order to set background.threads or KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE in order to configure auto.create.topics.enable
还有就是,当使用任何来自于bitnami的镜像,如何遇到了问题,想查看日志,可以将镜像的Debug日志打开,通过环境变量
BITNAMI_DEBUG=true
控制
由于Docker Hub的说明字数限制,可以在Github上查看完整文档
Kafka UI镜像选择
对于Kafka的UI工具,没有仔细调查,原因是在使用初期阶段,还不知道对于Kafka的监控和管理的痛点在哪,所以先用起来再说。
Kafka UI官方Github地址 > 文档网址 > Compose examples 下面可以找打很多Kafak ui的compose文件示例,不仅对UI的配置很有帮助,而且对刚入门Kafka的同学,也提供了非常好的示例,包括Kraft模式的Kafka集群等。
其他配置则阅读官方文档即可。
Docker Compose文件
version: "3" services: kafka: image: 'bitnami/kafka:latest' container_name: kafka ports: - "9092:9092" - "9093:9093" - "9998:9998" - "9095:9095" volumes: - type: volume source: kafka_standalone_data target: /bitnami/kafka read_only: false - type: bind source: ./jmx_prometheus_javaagent-1.0.1.jar target: /opt/bitnami/kafka/config/jmx_prometheus_javaagent-1.0.1.jar read_only: true - type: bind source: ./kafka-kraft-3_0_0.yml target: /opt/bitnami/kafka/config/kafka-kraft-3_0_0.yml read_only: true environment: - BITNAMI_DEBUG=yes # 启用KRaft模式必须设置下面三个属性 - KAFKA_CFG_NODE_ID=1 - KAFKA_CFG_PROCESS_ROLES=broker,controller - KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER # broker id - KAFKA_BROKER_ID=1 # listener的各种配置 - KAFKA_CFG_LISTENERS=CONTROLLER://:9094,BROKER://:9092,EXTERNAL://:9093 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,BROKER:PLAINTEXT,EXTERNAL:PLAINTEXT # 注意EXTERNAL配置的是当前Docker所在的主机地址,BROKER可以使用Docker内部的网络地址即可 - KAFKA_CFG_ADVERTISED_LISTENERS=BROKER://kafka:9092,EXTERNAL://192.168.0.101:9093 # 内部各个broker之间通信用的listener - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=BROKER # 用来进行选举的Controller服务器,如果有多个Controller则都需要写上,这里本机 - KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@127.0.0.1:9094 - ALLOW_PLAINTEXT_LISTENER=yes # 开启JMX监控 - JMX_PORT=9998 - KAFKA_JMX_OPTS=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=kafka -Dcom.sun.management.jmxremote.rmi.port=9998 # 集成Prometheus JMX Exporter - KAFKA_OPTS=-javaagent:/opt/bitnami/kafka/config/jmx_prometheus_javaagent-1.0.1.jar=9095:/opt/bitnami/kafka/config/kafka-kraft-3_0_0.yml kafka-ui: container_name: kafka-ui image: provectuslabs/kafka-ui:latest ports: - "9095:8080" depends_on: - kafka environment: KAFKA_CLUSTERS_0_NAME: kafka-stand-alone KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092 KAFKA_CLUSTERS_0_METRICS_PORT: 9998 SERVER_SERVLET_CONTEXT_PATH: /kafkaui AUTH_TYPE: "LOGIN_FORM" SPRING_SECURITY_USER_NAME: admin SPRING_SECURITY_USER_PASSWORD: kafkauipassword DYNAMIC_CONFIG_ENABLED: 'true' volumes: kafka_standalone_data: driver: localKafka配置项说明
KRaft vs Zookeeper
这里我们的配置是选择的是KRaft,因为Kafka官方已经计划在Kafak中移除Zookeeper。至于为什么要移除?confluentinc官方写了很多文章,这里不再一一列举,在Google上一搜就一大堆
KRaft site:confluent.io
下面是几篇文章
- why move to kraft
- Why ZooKeeper Was Replaced with KRaft
- Apache Kafka Without ZooKeeper
- Getting Started with the KRaft Protocol
和KRaft有关的配置
- node.id
The node ID associated with the roles this process is playing when process.roles is non-empty. This is required configuration when running in KRaft mode.
- porcess.roles
The roles that this process plays: ‘broker’, ‘controller’, or ‘broker,controller’ if it is both. This configuration is only applicable for clusters in KRaft (Kafka Raft) mode (instead of ZooKeeper). Leave this config undefined or empty for Zookeeper clusters
- controller.listener.names
A comma-separated list of the names of the listeners used by the controller. This is required if running in KRaft mode
关于Controller和Broker的概念解释
一句话解释:
Controller负责协调Broker(详细解释可见Kafak权威指南的第5章,该书可在Apache Kafak官网 > Get Started > Books 中找到免费下载)
To summarize, Kafka uses Zookeeper’s ephemeral node feature to elect a controller
and to notify the controller when nodes join and leave the cluster. The controller is
responsible for electing leaders among the partitions and replicas whenever it notices
nodes join and leave the cluster. The controller uses the epoch number to prevent a
“split brain” scenario where two nodes believe each is the current controller.
Broker负责处理生产者生产消息的请求、存储消息、消费者消费消息的请求。
A single Kafka server is called a broker. The broker receives messages from producers,
assigns offsets to them, and commits the messages to storage on disk. It also services
consumers, responding to fetch requests for partitions and responding with the mes‐
sages that have been committed to disk
来自Kafka权威指南第1章>Enter Kafka > Broker And Clusters
Listener的各种配置
当时看官方文档的时候,这部分一直被搞得晕头转向,直到看到这篇关于Kfaka的Listener文章,才彻底明白了各种listener,强烈推荐读一下这篇文章。
listener可分为3种:
- 用来选举Controller的listener
- kafka集群内部各broker节点通信的listener
- 外部客户端,例如Java Client连接Kafka
了解了3中controller,结合上面的这篇文章+Apache Kafka官方文档的配置说明,配置listener就变得很容易了。
集成Prometheus JMX Exporter
按照prometheus官方文档集成即可,kafka-kraft-3_0_0.yml则来自于官方Github > example_configs
启动之后访问,能看到数据即为正常
Kafka UI配置项说明
注意UI配置中的METRICS_PORT要设置成Kafka配置中的JMX_PORT,至于为什么,了解JMX原理的同学应该都知道,不清楚JMX的可参考JMX快速入门。
稍微有心的同学,可能发现,在docker compose中要访问另外一个服务,需要使用container_service_host_name:port(Docker官方文档Networking in Compose部分),但是这里配置项中只配置了port,Kafka UI是如何拼接JMX的URL呢?我去看了一下它的源码,发现它是可以拿到host的,所以这里不用担心
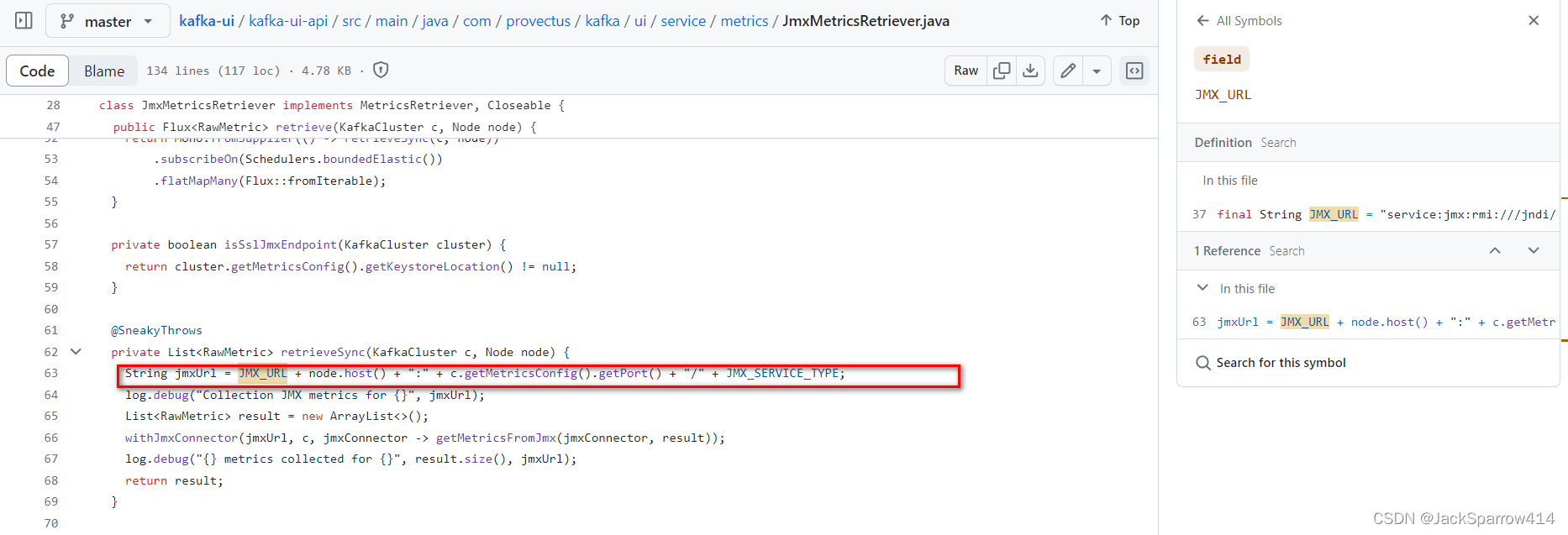
对于其他UI配置项没什么特别要说的,这里只是提一下,注意这里的docker-compose.yml中environment的写法,和上面的Kafka镜像中environment的写法不同,这是两种不同的写法
详细文档见Docker Compose文档规范中environment章节
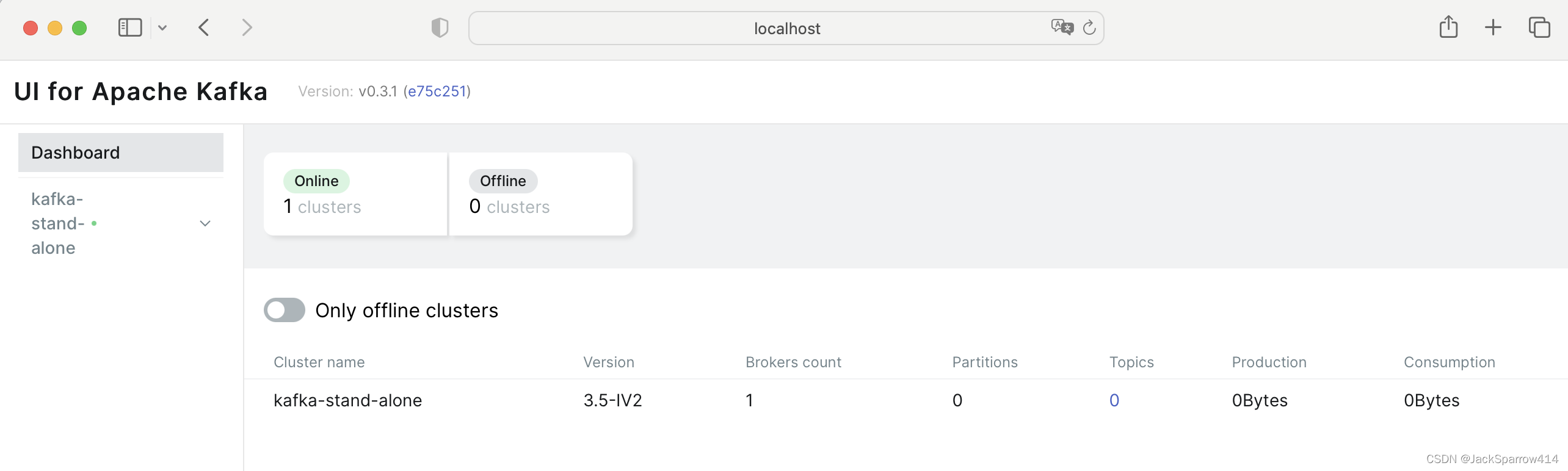
测试
使用上述docker-compose.yml文件,启动
docker-compose -f docker-compose.yml up -d
在本地浏览器打开
http://localhost:9095/kafkaui/auth
输入用户名、密码,进入UI界面
访问
http://localhost:9095/metrics
能看到metrics数据
启用JMX或集成Prometheus后执行kafka命令出现Address already in use
为什么启用JMX或集成Prometheus后执行kafka命令会出现此问题见why-do-kafka-tools-fail-when-jmx-is-enabled
解决方案
- 在docker container外部使用exec执行命令时设置JMX_PORT和KAFKA_OPTS
docker exec -e JMX_PORT= -e KAFKA_OPTS= kafka /opt/bitnami/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --if-not-exists --topic test-topic --partitions 20 --replication-factor 1 --config min.insync.replicas=1 --config retention.bytes=1073741824
- 在docker container内部执行具体命令之前unset
# 进入容器 docker exec -it kafka bash # 进入容器后先执行这两行命令 unset JMX_PORT unset KAFKA_OPTS #具体的命令
- 使用单独的docker container来执行要请求的命令,见回答
Kafka集群
本篇文章重点在于搭建单机版Kfaka环境,集群不在文章讨论范围之内,如果对集群配置感兴趣和有需要的同学,这里仅给出几个示例的Github仓库仅供参考,并且全部使用KRaft而不是Zookeeper
一个基本的高可用Kafka集群需要多少个节点?
我个人的理解,最小的集群应该是3个controller+3个broker, 为什么是3个broker呢?Kafka官方文档Replication一节 提到过
With this ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages
意思是,如果topic的复制因子replication factor是2(复制因子是包括leader的,见官方文档:The total number of replicas including the leader constitute the replication factor),那么在一个节点失败的情况下,Kafka还是可以正常工作的。这里Kafka采用的算法和ZooKeeper, Elasticsearch集群的算法是不一样的。如果换成ZK和ES,只有两个节点,这时ZK和ES是无法工作的。
The downside of majority vote is that it doesn’t take many failures to leave you with no electable leaders. To tolerate one failure requires three copies of the data, and to tolerate two failures requires five copies of the data. In our experience having only enough redundancy to tolerate a single failure is not enough for a practical system, but doing every write five times, with 5x the disk space requirements and 1/5th the throughput, is not very practical for large volume data problems. This is likely why quorum algorithms more commonly appear for shared cluster configuration such as ZooKeeper but are less common for primary data storage
那这么看来,Kafka集群其实只需要2个节点就可以了,为什么还是3个节点呢?带着这个疑问,我查了一下stackoverflow,还真有人问过这个问题,见in kafka ha why minimum number of brokers required are 3 and not 2
- 如果复制因子是2,min.insync.replicas也是2,当有一个节点失败时,生产者无法完成写入
- 如果复制因子是2,min.insync.replicas是1,当leader失败时,follower则可能没有改消息
- 如果复制因子是3,min.insync.replicas是2,当有一个节点失败时,生产者还是可以正常写入
- 如果复制因子是3,min.insync.replicas是2,当leader失败时,至少还有一个follower的消息时和leader同步的,所以这时可以完成leader的切换
Kafka集群示例配置
Kafka关于KRaft模式下Controller的部署建议
- 2024-05-14更新,官方在3.7.0中引入官方镜像并提供了很多示例,集群的示例参考官方Github库
- 来自bitnami的Kafka集群示例,三个节点皆为controller和broker。
- 来自confluentic的Kafka集群配置,我个人倾向于这个配置,毕竟confluentic是Kafka商业化的公司,其创始人来自LinkedIn。这里是四个节点,一个controller和3个broker。
- 来自Github的Kafka-In-Box,使用4个节点。
Kafka vs RabbitMQ vs Pulsar性能对比
见confluent官方博文
- node.id



