
Flink+Paimon在阿里云大数据云原生运维数仓的实践



1. 背景
随着大数据产品云原生化的推进,云原生集群的规模和数量都在增加,云原生集群的运维难度也在不断增加,云原生集群的资源审计、资源拓扑、资源趋势的需要就比较迫切。云原生集群的资源审计主要是 node 资源、pod 资源,如当前集群的 node 数量以及Pod 数量;资源拓扑主要构建用户->实例->pod->node->集群的关联关系,例如一个公有云用户,提供给运维团队可以通过 uid 查询到用户实例以及实例所在的节点/集群信息。资源趋势是整个团队所管理的集群资源使用趋势,pod 数量趋势、node 数量趋势、以及用户使用资源趋势。
为了提升大数据产品云原生集群的运维能力,我们构建一个实时云原生运维数仓,业务能力提供资源审计、资源拓扑、资源趋势等能力。在数据性能方面最终数据需要具备实时性(分钟级)和一致性。
目前 Flink 已经是实时计算的标准解决方案,在这个基础上阿里云开源大数据团队推出 Paimon 为低成本的数据湖解决方案。本文我们使用 Flink+Paimon 为 流式数仓解决方案应用到云原生运维数仓中,提供实时(分钟级)的数据服务,提升云原生集群的运维能力。
2. 总体设计
2.1 方案选型
如 1 中背景所述,因为数据的实时性需求,所以我们不考虑离线数仓解决方案,直接考虑实时数仓解决方案。目前阿里云实时数仓解决方案中,比较推荐使用的是 Flink+Hologres 和 Flink+Paimon 两种解决方案。其中 Flink+Hologres 已经比较成熟,本文中我们不详细描述,其主要缺点是 Hologres 存储成本比较高。最终我们选择使用 Flink+Paimon 的方案,优势在于存储成本低,实时性高。
2.2 最终方案
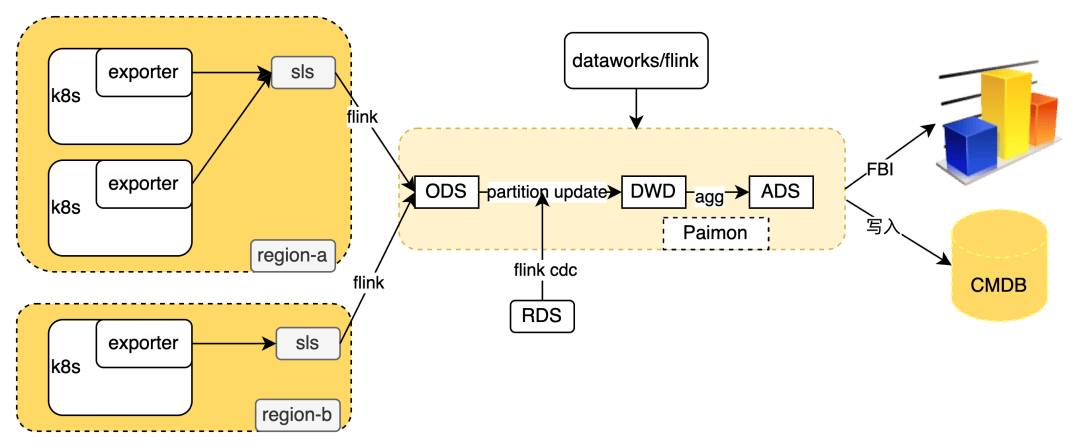
数据采集采用 exporter operator 实现 kubernet 负载数据到 sls,为了适配阿里云多 region 网络隔离的问题,我们在数据出 region 之前先同步到 sls 中,再直接同步到 sls 的跨域网络同步到 paimon ods 表中,同步的过程需要处理数据排序问题。flink 作业通过运维数仓本身有比较高的实时性的要求,我们在数据处理过程中采用 Flink+Paimon 的解决方案,paimon 支持元数据注册到 maxcompute 中,可以直接使用 dataworks /flink 查询数据;最终数据报表采用 FBI 进行展示,资源拓扑数据写入到 CMDB 中给运维系统使用。
3. 落地实践
3.1 数据采集
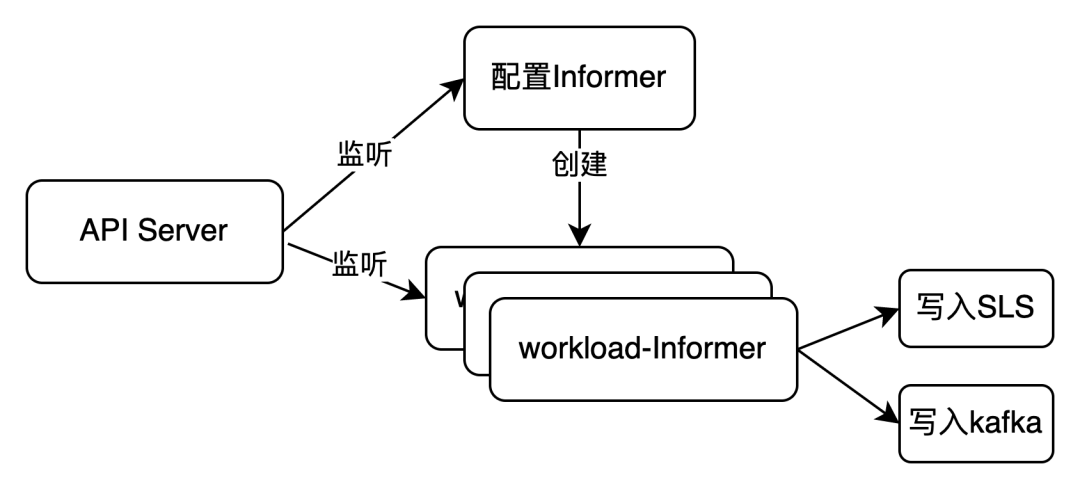
我们研发了 exporter-operator 工具,嵌入 Kubernetes 集群中的哨兵,实时监听 Kubernetes api server 中 workload 数据变化。作为集群生态系统的 addon 组件,exporter-operator 以高效的响应机制驻留内部。
通过配置 Informer 中的自定义资源(CR),exporter-operator 灵活启用了多个 workload-informer 实例,针对各类工作负载实施监听,赋予系统卓越的灵活性,使其能够灵活监控多种工作负载信息。
exporter-operator 不断捕获并即时传输这些关键的工作负载数据,无缝对接阿里云日志服务(SLS)或 Apache Kafka 流处理平台,实现实时记录与深度分析集群运行状态,为优化集群效能提供强有力的数据支持。
3.2 数据清洗
为了数据分析可以使用 dataworks 进行分析,数据清洗前需要按照文档Paimon外部表进行配置。配置完成后创建 Paimon 表的元数据会直接同步到 dataworks 中,就可以直接进行数据分析。
3.2.1 ods 层
ods 层数据直接把 sls/kafka 中的数据同步到 paimon ods 表,保存有所有同步到的负载数据。
CREATE TABLE IF NOT EXISTS `abm-exporter-paimon`.`abm_exporter_db`.`ods_realtime_exporter_lakehouse`
(
`sls_time` bigint
,`cluster` varchar
,`content` varchar
) PARTITIONED BY (cluster) with( 'orc.write.batch-size' = '128','file.format' = 'avro','bucket' = '8')
insert into `abm-exporter-paimon`.`abm_exporter_db`.`ods_realtime_exporter_lakehouse` /*+ OPTIONS('orc.write-buffer-size' = '128','file.format' = 'avro') */
select
`__timestamp__` as sls_time
,`__topic__` as cluster
,`content`
from source_k8s_meta;
注意:
paimon 默认文件格式是 orc,orc 是列存,所以需要先在内存里攒批然后写出去。默认一批是 1024 行,目前写入数据一行几 mb ,1024 行的 buffer 就几 G 了,堆内存会不够。所以选择使用行存:设置 ‘file.format’ = ‘avro’,用 avro 格式;另外也可以设置 ‘orc.write.batch-size’ = ‘128’,把批的大小改成 128 来解决。
3.2.2 dwd 层
dwd 层的功能有三个部分,1.将数据按照 primary key 聚合 ,确保资源数据的唯一性 2.将数据进行排序,确保 delete 的数据在最后发生 3.集群维度进行维表 join,丰富集群维度字段。
CREATE TABLE IF NOT EXISTS `abm-exporter-paimon`.`abm_exporter_db`.`dwd_realtime_exporter_lakehouse` ( type varchar ,obj varchar ,k8s_group varchar ,version varchar ,kind varchar ,namespace varchar ,name varchar ,resourceversion varchar ,region_id varchar NOT NULL ,cluster varchar NOT NULL ,watchname varchar NOT NULL ,watchsetuptimestamp bigint NOT NULL ,uid varchar PRIMARY KEY NOT ENFORCED ,collect_time bigint NOT NULL ,sls_time bigint ,cluster_id varchar ,region varchar ,zone varchar ) with ( 'merge-engine' = 'partial-update' ,'changelog-producer' = 'lookup' ,'partial-update.ignore-delete'='true' );
set 'table.exec.sink.upsert-materialize' = 'NONE';
insert into `abm-exporter-paimon`.`abm_exporter_db`.`dwd_realtime_exporter_lakehouse` /*+ OPTIONS('orc.write-buffer-size' = '128','file.format' = 'avro') */
select
json_value(`content`, '$.type') as `type`
,json_value(`content`, '$.obj') as `obj`
,json_value(`content`, '$.group') as `k8s_group`
,json_value(`content`, '$.version') as `version`
,json_value(`content`, '$.kind') as `kind`
,json_value(`content`, '$.namespace') as `namespace`
,json_value(`content`, '$.name') as `name`
,json_value(`content`, '$.resourceversion') as `resourceversion`
,'cn-zhangjiakou' as `region_id`
,`cluster` as `cluster`
,json_value(`content`, '$.watchname') as `watchname`
,cast(json_value(`content`, '$.watchsetuptimestamp') as bigint) as `watchsetuptimestamp`
,json_value(`content`, '$.uid') as `uid`
,cast(UNIX_TIMESTAMP() as bigint) as `collect_time`
,`sls_time` as `sls_time`
,NULL
,NULL
,NULL
from (
SELECT
*
FROM (
SELECT
*
,ROW_NUMBER()
OVER (
PARTITION BY `cluster`, json_value(`content`, '$.uid')
ORDER BY cast(json_value(`content`, '$.resourceversion') as bigint) DESC,cast(json_value(`content`, '$.__time_milli__') as bigint) DESC
) as rowNum
FROM `abm-exporter-paimon`.`abm_exporter_db`.`ods_realtime_exporter_lakehouse`
)
WHERE rowNum = 1
);
3.2.3 ads 层
ads 层进行数据聚合,flink 处理逻辑只负责将数据写入到 Paimon 中,使用 Paimon 的merge-engine='aggregation’进行字段的聚合。这样计算逻辑不在 flink 中,不需要在 flink state 中进行,大量减少 state 的资源消耗。因为 Paimon 的计算是在 flink checkpoint 结束后触发,所以减少 flink checkpoint 的间隔时间可以提高数据的实时性。
CREATE TABLE IF NOT EXISTS `abm-exporter-paimon`.`abm_exporter_db`.`ads_realtime_exporter_lakehouse`
(
kind varchar
,cluster varchar NOT NULL
,workload_num bigint
,PRIMARY KEY (kind, cluster) NOT ENFORCED
)
with (
'merge-engine' = 'aggregation'
,'changelog-producer' = 'lookup'
,'fields.workload_num.aggregate-function' = 'sum'
)
;
insert into `abm-exporter-paimon`.`abm_exporter_db`.`ads_realtime_exporter_lakehouse`
select
kind
,cluster
,case
when type = 'ADDED' then 1
when type = 'DELETED' then -1
ELSE 0
end as workload_num
from `abm-exporter-paimon`.`abm_exporter_db`.`dwd_realtime_exporter_lakehouse`;
3.3 数据分析
如果只需要查询一次的情况可以使用 dataworks 进行数据查询,当然也可以直接使用 flink 进行数据查询,当前 VVP 里面已经开发了查询的功能。如果需要生成报表就使用fbi 等工具进行数据分析,也可以使用 flink 将相关的数据清洗到 cmdb 系统中去。
use bigdata_sre; SET odps.table.scan-options.odps.external.sub.disable.hyper=true; SET odps.sql.common.table.planner.ext.hive.bridge = true; set odps.sql.submit.ddltask.via.common.table=true; SET odps.sql.hive.compatible = false; set odps.compiler.verify=true; set odps.isolation.session.enable=true; -- select * from ods_realtime_exporter_lakehouse limit 100; -- select * from dwd_realtime_exporter_lakehouse where kind='Node' limit 100; select * from ads_realtime_exporter_lakehouse order by workload_num desc limit 100;
4. 总结
目前 Flink+Paimon 实时数据湖的方案已经比较成熟,使用成本不高,相关的生态也比较完善,在低成本和低延迟的要求下,这个方案还是非常好的选择。如果对成本没太高的要求,Flink+Hologres 在延迟方面会有些优势。
参考文件:
-
《Flink+Paimon构建流式数据湖仓》
https://ata.atatech.org/articles/11000268231?spm=ata.25287382.0.0.6be65f6948opbG
-
《Paimon外部表》
https://help.aliyun.com/zh/maxcompute/user-guide/paimon-external-table
-
《当流计算邂逅数据湖:Paimon 的前生今世》
https://xie.infoq.cn/article/63890f6dc8afcbfaac312444f


