
MySQL之窗口函数
一、什么是窗口函数
窗口函数:窗口、函数(应用在窗口内的函数)窗口类似窗户、限定一个空间。
那什么叫窗口呢?
窗口的概念非常重要,可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行,窗口的大小是固定的,这种属于静态窗口;不同的记录对应着不同的窗口,这种动态变化的窗口叫做滑动窗口。
窗口函数的基本用法如下:
函数名(开窗字段) over(子句);
其中over是关键字,用来指定函数执行的窗口范围,包含三个分析子句:
分组(partition by)子句类似group by;
排序(order by)子句;
窗口(rows)子句;
如果后面括号中什么都不写,则意味着窗口包含满足where条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下语法来设置窗口:
函数名() over(partition by order by rows between)
知识点总结:
sum(...A..) over(partition by ...B... order by ...C... rows between ..D1.. and ..D2..)
sum(...A..) over(partition by ...B... order by ...C... rows between ..D1.. and ..D2..)
A:需要被加工的字段名称
B:分组的字段名称
C:排序的字段名称
D:计算的行数范围
rows between unbounded preceding and current row #取当前行和前面所有行
rows between current row and unbounded following #包括本行和之后所有的行
rows between 3 preceding and current row #当前行和前面三行
rows between 3 preceding and 1 following #前面三行和下面一行总共五行
#当order by后面缺少窗口从句条件,窗口规范默认是rows between unbounded preceding and current row
#当order by和窗口从句都缺失,窗口规范默认是rows between unbounded preceding and unbounded following
二、窗口函数的应用
1、专有窗口函数
rank()
dense_rank()
row_number()
区别:
row_number():12345
rank():11345
dense_rank():11234
2、聚合类窗口函数
普通场景下,聚合函数往往和group by一起使用,但是窗口环境下,聚合函数也可以应用进来,那么此时他们就被称为聚合类窗口函数,属于窗口函数的一种
sum()
count()
avg()
max()
min()
窗口函数和聚合函数区别
窗口函数和普通场景下的聚合函数也很容易混淆,二者区别如下:
1、普通场景下聚合函数是将多条记录聚合为一条(多到一);窗口函数是每条记录都会执行,有几条记录执行完还是几条。
2、分组(partirtion by:窗口按照字段进行分组,窗口函数在不同的分组上分别执行。
3、排序(order by):按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号,可以和partition子句配合使用,也可以单独使用。如果没有partition子句,数据范围则是整个表的数据行。
4、窗口(rows):就是进行函数分析时要处理的数据范围,属于当前分区的一个子集,通常用来作为滑动窗口使用。比如要根据每个订单动态计算包括本订单和按时间顺序前后两个订单的移动平均支付金额,则可以设置rows子句来创建滑动窗口(rows)。
求和

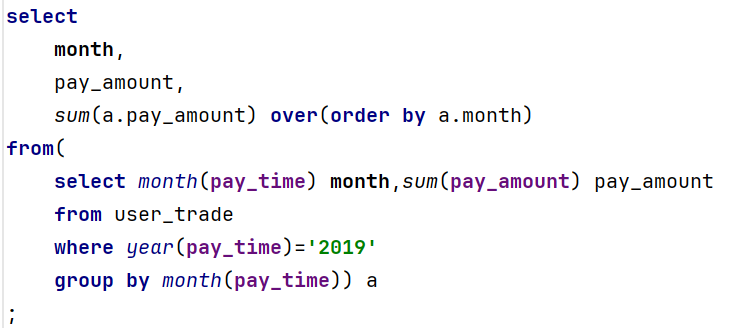
需求1、求2019年每月的支付总额和当年累计支付总额
step1:过滤出2019年数据
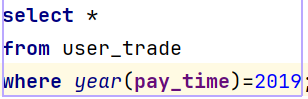
step2:在1的基础上按照月份进行group by分组,统计每个月支付总额
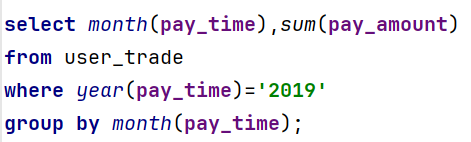
step3:在2的基础上应用窗口函数实现需求
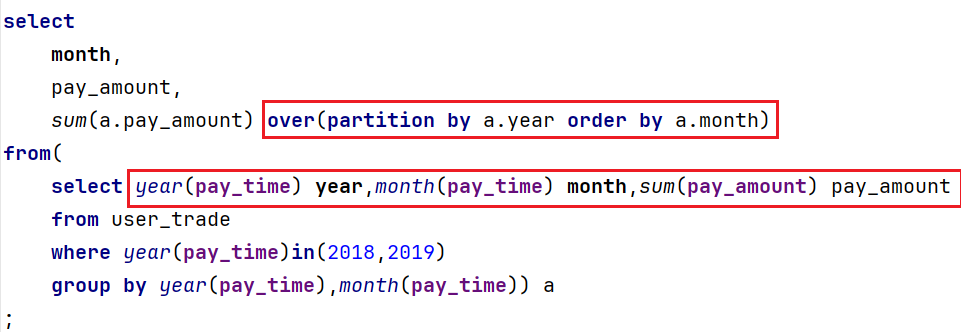
需求2、查询出2018-2019年每月的支付总额和当年的累计支付总额
需求3、查询出2019年每个月的近三个月移动平均支付金额
step1、查询2019年每个月的平均支付金额

step2、在1的基础上应用窗口函数实现
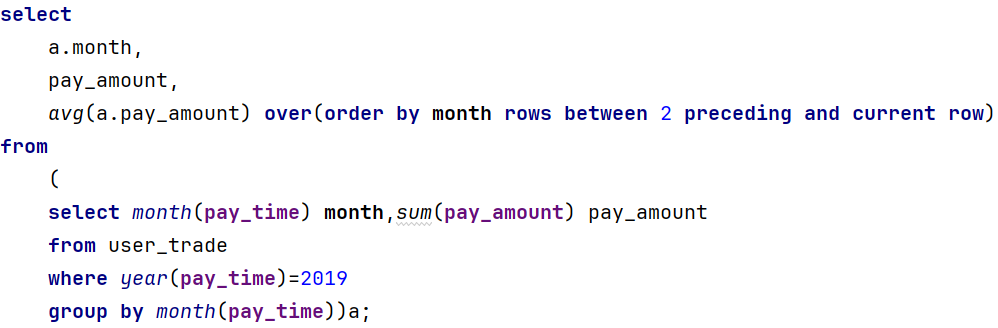
需求4、查询每四个月的最大月总支付金额
step1、查询每个月的月度总支付金额

step2、在1的基础上应用窗口函数实现

排序函数
row_number() over(....)
rank() over(....)
dense_rank() over(......)
需求5、2020年1月,购买商品品类数的用户排名
2020年1月(基础数据范围)
一个商品属于某一个品类
A用户购买100件商品,那么可能涉及到10个品类
B用户购买了50件商品,那么可能涉及到了15个品类
根据所购买商品涉及的品类数量进行(给用户)排名
思路:
(1)先把各个用户所购买的商品涉及的品类给统计出来

(2)在1的基础上进行排名(三种排序函数比较)

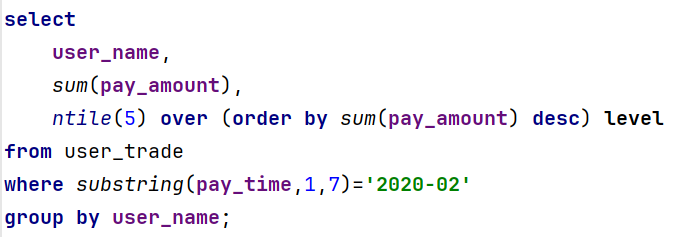
需求6、查询出将2020年2月的支付用户,按照支付金额分成五组后的结果。
ntile(n) over(partition by ...A... order by ...B...)
n:切片的片数
A:分组字段
B:排序的字段名
ntile(n),用于将分组数据按照顺序切分成n片,返回当前切片值
ntilte不支持rows between
(1)查询2020年2月

(2)查询2020年2月用户的支付金额

(3)按照用户金额进行排序,分成5档
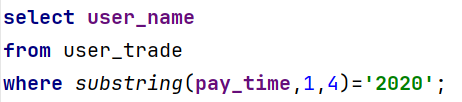
需求7、查询2020年支付金额排名前30%的所有用户
(1)查询2020年所有用户
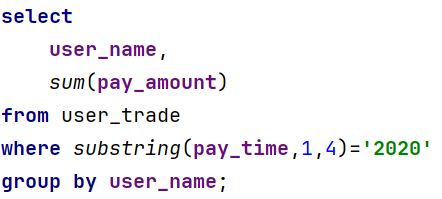
(2)查询2020年每个支付总额
(3)将查询的支付总额分成十个等级并进行排序
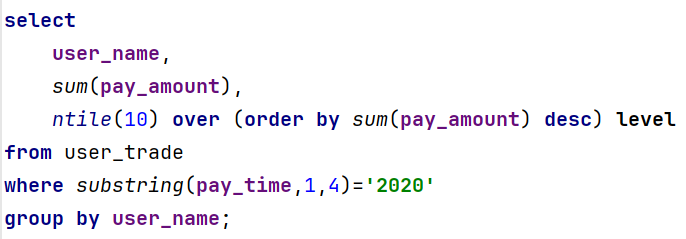
(4)将其中的1、2、3等级的金额拿出来

偏移分析函数
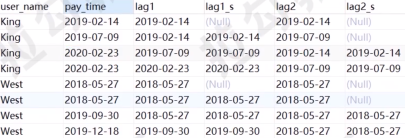
lag(...) over(....):向上偏移
lead(...) over(...):向下偏移
lag和lead函数可以在同一次查询中取出同一字段的前N行数据(lag)和后N行数据(lead)作为独立的列。
在实际应用当中,若要用到取昨天和今天的某个字段的差值,就能用到lag和lead函数
语法:
lag(exp_str,offset,defval) over(partition by.... order by....)
lead(exp_str,offset,defval) over(partition by.... order by....)
exp_str是要偏移的字段名称:
offset是偏移量(默认是1):向上或者向下找1或者N行
defval默认值(没有指定为null):如果向上或者向下寻找N行后,不存在则返回默认值
需求8、查询出King和West的时间偏移(前N行)

需求9、查询出支付时间间隔超过一百天的用户数


需求10、查询出每年支付时间间隔最长的用户
2018年找出这年订单时间间隔最长的那个人
2019~
2020~
关键词:支付时间间隔
①把相邻的订单时间pay_time通过窗口函数放置到一行(方便后续计算)
②计算出来用户购买订单的时间间隔
③将用户购买订单的时间间隔按从大到小的顺序排列出来
④将排序的第一名通过where条件判断出来




