
一文带你了解何为哈希表(Hash Table)!



1、引言
在计算机科学领域,数据结构是构建程序和解决问题的基础。而其中一种关键的数据结构,哈希表(Hash Table),在各种应用中扮演着至关重要的角色。它以其快速的查找、插入和删除操作而闻名,成为了许多实际系统中的首选选择。
哈希表背后的核心思想是利用哈希函数将键映射到存储桶的索引上,从而实现高效的数据访问。通过这种方式,哈希表能够在平均情况下以O(1)的时间复杂度完成各种操作,使得它在处理大量数据时表现出色。
现在,让我们开始探索哈希表的奥秘吧!
2、哈希表(Hash Table)简介
哈希表又叫散列表,我们需要把查找的数据(key, value)通过一个函数映射Hash(key),找到存储数据的位置hashkey,这个过程被称为哈希。需要查找的数据本身被称为关键字key,通过函数映射将关键字变成哈希值的过程,这里的函数被称为 哈希函数。
而哈希表的本质其实是一个顺序表,通过哈希函数将关键字转换成哈希值也就是顺序表的下标,来存储元素。
上面提到的(key, value), 我们又称之为键值对。
2.1、何为键值对?
键值对由键和值组成,键和值都可以是任意类型(比如整型、浮点型、字符串、类 等等)
哈希表的实现过程中,我们需要通过一些手段将一个非整型的键转换成整数,也就是哈希值;从而通过 O(1)的时间快速索引到它对应在哈希表中哪个位置。
而将一个非整形的关键字转换成整形的方法就是哈希函数。
2.2、哈希函数
哈希函数可以理解为y = f(x)。这里的f(x)就是哈希函数,x就是键值,y就是哈希值。哈希函数有很多实现形式,如直接定址法,平方取中法,折叠法,除留余数法。这里我们主要用除留余数法来实现哈希表。
除留余数法:就是键的值模上哈希表长度,表示成函数 f (x) = x mod m,其中 m 代表了哈希表的长度。例如,对于一个长度为 4 的哈希表,可以将关键字 模 4 得到哈希值,再根据哈希值将value存储到哈希表内。
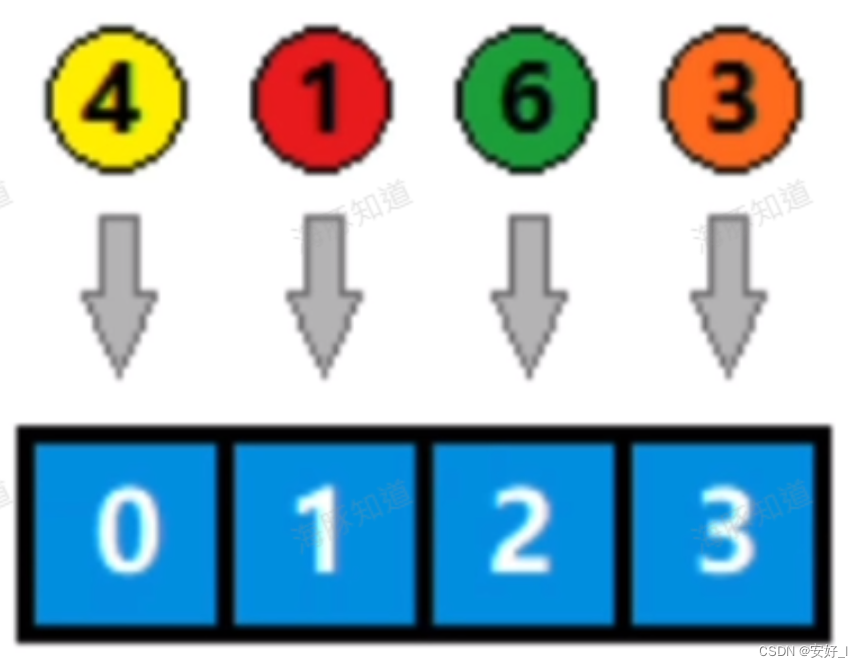
2.3哈希冲突
通过上面的介绍我们不难发现,当key = 4 和 8 时,他们的哈希值是相同的,这就会导致存储元素时会有冲突,这样的现象就叫做哈希冲突。而为了解决这样的问题,我们可以使用链地址法或者开放地址法来避免哈希冲突。
链地址法:前面说过哈希表的本质是顺序表,那么我们让哈希表的每个位置存储一个链表,当出现哈希冲突时,用链表将哈希值相同的元素串联起来,就解决了这个问题。
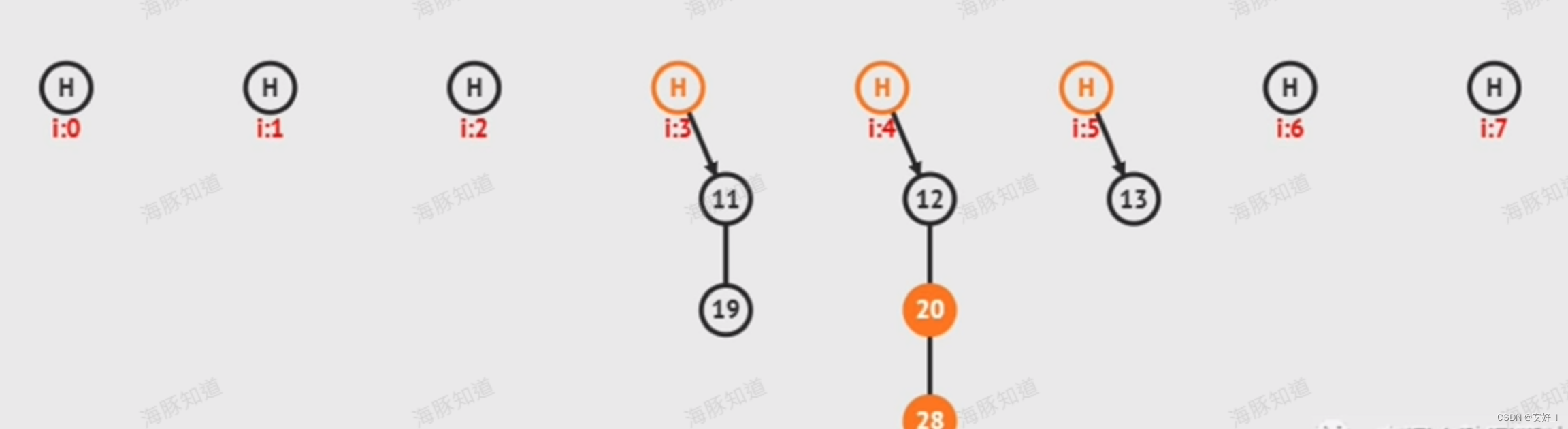
图中带数字的圆圈就是关键字,将 哈希值 = 关键字 % 长度8 ,可以看到12, 20, 28 的哈希值都等于4 所以用链表将他们串联起来就可以解决哈希冲突的问题。
3、哈希表代码实现(链地址法)
3.1、哈希节点
template
class HashNode {//哈希节点
public:
key_T key;//键值
value_T value;//实值
HashNode* next;//链地址法--数组存储链表头节点
HashNode(const key_T& key, const value_T& value) {
this->key = key;
this->value = value;
this->next = NULL;
}
};
哈希节点中存储三样东西,key--键值, value--实值,以及链表的头节点 ;构造函数用于申请内存的同时完成赋值操作。
3.2、哈希表
template
class HashTable {
private:
int size;//哈希表数组大小
HashNode** table;//存储哈希表节点的数组,
//同时每个数组元素是存储链表头的指针
int hash(const key_T& key)const {
//第一个const 表示传进来的key不能被改变
//第二个const函数在被调用时不能改变哈希表的成员变量
int hashkey = key % size;//通过哈希函数(除留余数法)得到哈希值
if (hashkey
需要注意的是 table是一个 HashNode 类型的二级指针,原因是 table是由new申请出空间的数组,并且存放的是每个链表头的指针,所以才是二级指针。
3.3、构造函数
template
HashTable::HashTable(int size) {
this->size = size;
this->table = new HashNode* [size];//创建一个size大小的哈希数组
for (int i = 0; i table[i] = NULL;
}
}
3.4、insert函数
template
void HashTable::insert(const key_T& key, const value_T& value) {
int index = hash(key);//通过哈希函数找到键的索引
HashNode* now = new HashNode(key, value);//创建一个哈希节点
if (table[index] == NULL) {//如果当前哈希表为空,则直接将新节点作为链表头赋值
table[index] = now;
}
else {//如果不为空,则用头插法,将新节点插入到链表头中,保证哈希表的插入操作是O(1);
now->next = table[index];
table[index] = now;
}
}
通过hash函数获得key对应的哈希值index,当index对应的位置为空时,直接将now赋值在这个位置;当index对应的位置不为空时,用头插法将值插入到链表中保证哈希表的插入操作是O(1)。
3.5、erase函数
template
void HashTable::erase(const key_T& key) {
int index = hash(key);//通过哈希函数找到对应的哈希值
if (table[index]) {
if (table[index]->key == key) {//如果头节点就是需要删除的值就delete,并将下一个节点作为头节点
HashNode* next = table[index]->next;
delete table[index];
table[index] = next;
}
else {//如果头节点不是需要删除的值
HashNode* cur = table[index];
while (cur->next && cur->next->key != key) {//循环遍历找到删除值
cur = cur->next;
}
if (cur->next) {
HashNode* next = cur->next->next;
delete cur->next;
cur->next = next;
}
}
}
}
通过hash函数获得需要删除的value的哈希值,如果存储在index位置的 key == 传入的key就直接删除;如果不等于,就遍历链表,如果是尾节点就直接删除;如果不是尾节点,就在删除后将后面的节点链接到上一个节点后。
3.6、find函数
template
bool HashTable::find(const key_T& key, value_T& value)const {
int index = hash(key);
if (table[index]) {
if (table[index]->key == key) {
value = table[index]->value;
return true;
}
else {
HashNode* cur = table[index];
while (cur->next && cur->next->key != key) {
cur = cur->next;
}
if (cur->next) {
value = cur->value;
return true;
}
}
}
return false;
}
find操作和erase操作类似, 如果找到,就将实值通过value返回出去,因为value的值可能会变,所以没有加const修饰。
3.7、析构函数
template
HashTable::~HashTable() {
for (int i = 0; i next;
delete cur;
cur = temp;
}
table[i] = NULL;//头节点置空
}
}
delete table;//哈希数组delete
table = NULL;
}
析构则是先将链表全部删除,最后再把哈希表删除。
3.8、完整代码
#include
using namespace std;
//哈希表--运用链地址法存储
template
class HashNode {//哈希节点
public:
key_T key;//键值
value_T value;//实值
HashNode* next;//链地址法--数组存储链表头节点
HashNode(const key_T& key, const value_T& value) {
this->key = key;
this->value = value;
this->next = NULL;
}
};
template
class HashTable {
private:
int size;//哈希表数组大小
HashNode** table;//存储哈希表节点的数组,同时每个数组元素是存储链表头的指针
int hash(const key_T& key)const {
//第一个const 表示传进来的key不能被改变
//第二个const函数在被调用时不能改变哈希表的成员变量
int hashkey = key % size;//通过哈希函数(除留余数法)得到哈希值
if (hashkey size = size;
this->table = new HashNode* [size];//创建一个size大小的哈希数组
for (int i = 0; i table[i] = NULL;
}
}
template
void HashTable::insert(const key_T& key, const value_T& value) {
int index = hash(key);//通过哈希函数找到键的索引
HashNode* now = new HashNode(key, value);//创建一个哈希节点
if (table[index] == NULL) {//如果当前哈希表为空,则直接将新节点作为链表头赋值
table[index] = now;
}
else {//如果不为空,则用头插法,将新节点插入到链表头中,保证哈希表的插入操作是O(1);
now->next = table[index];
table[index] = now;
}
}
template
void HashTable::erase(const key_T& key) {
int index = hash(key);//通过哈希函数找到对应的哈希值
if (table[index]) {
if (table[index]->key == key) {//如果头节点就是需要删除的值就delete,并将下一个节点作为头节点
HashNode* next = table[index]->next;
delete table[index];
table[index] = next;
}
else {//如果头节点不是需要删除的值
HashNode* cur = table[index];
while (cur->next && cur->next->key != key) {//循环遍历找到删除值
cur = cur->next;
}
if (cur->next) {
HashNode* next = cur->next->next;
delete cur->next;
cur->next = next;
}
}
}
}
template
bool HashTable::find(const key_T& key, value_T& value)const {
int index = hash(key);
if (table[index]) {
if (table[index]->key == key) {
value = table[index]->value;
return true;
}
else {
HashNode* cur = table[index];
while (cur->next && cur->next->key != key) {
cur = cur->next;
}
if (cur->next) {
value = cur->value;
return true;
}
}
}
return false;
}
template
HashTable::~HashTable() {
for (int i = 0; i next;
delete cur;
cur = temp;
}
table[i] = NULL;//头节点置空
}
}
delete table;//哈希数组delete
table = NULL;
}
4.测试
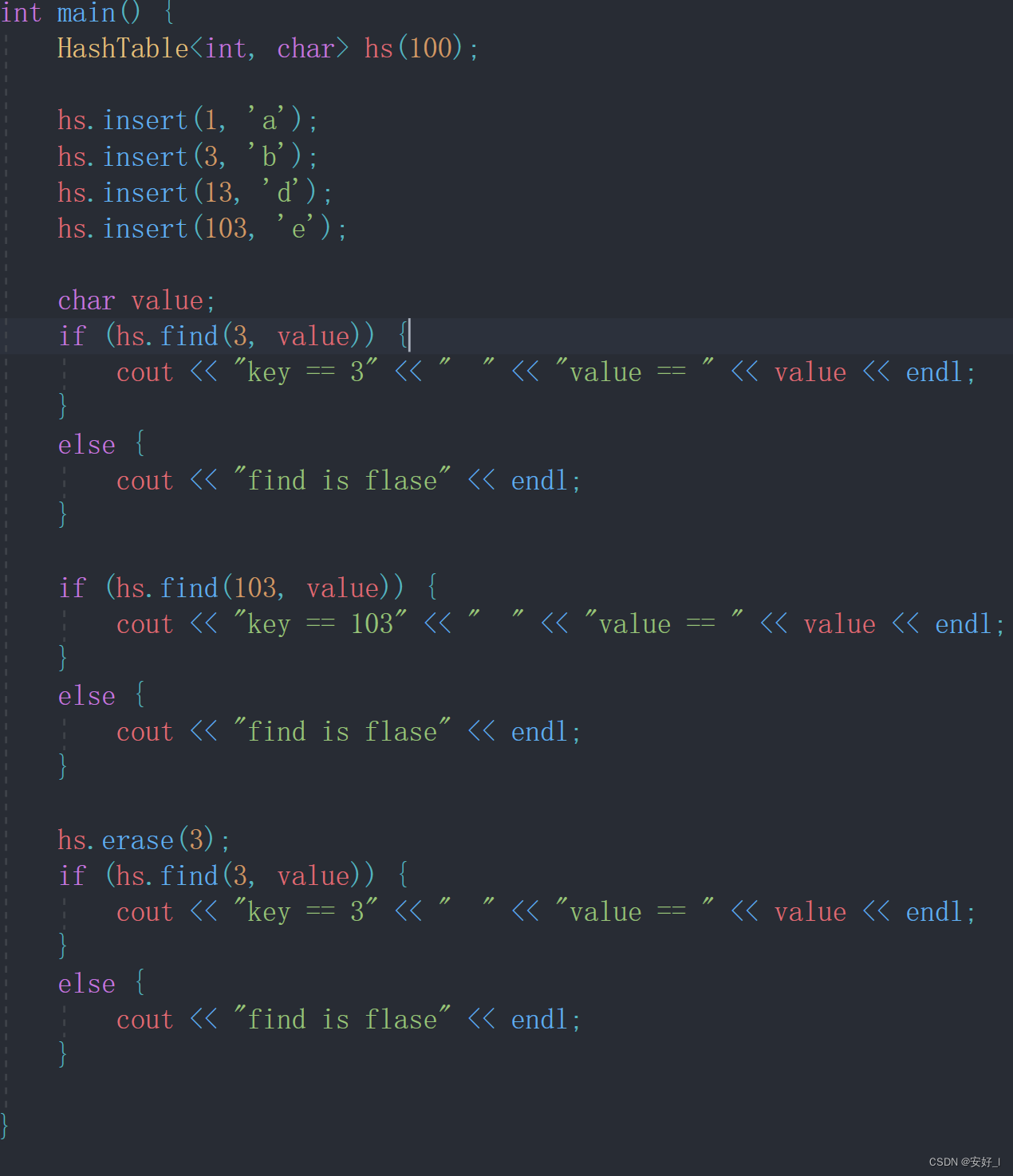
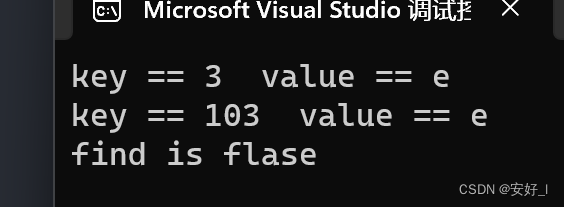
初始化一个长度为100的哈希表hs, 插入(1, a)(3,b)(13,d)(103,e)。可以得到,a在哈希表中的下标是1, b和e的下标是3, d的下标是13;
得到的结果是:
以上就是哈希表的全部讲解,其中还有一些是笔者没有提到的,感兴趣的朋友们可以再去了解了解,这篇文章如果有什么问题还请多多包涵!



