
新型大数据架构之湖仓一体(Lakehouse)架构特性说明——Lakehouse 架构(一)



文章目录
- 为什么需要新的数据架构?
- 湖仓一体(Lakehouse)——新的大数据架构模式
- 同时具备数仓与数据湖的优点
- 湖仓一体架构
- 存储层
- 计算层
- 湖仓一体特性
- 单一存储
- 拥有数据仓库的查询性能
- 存算分离
- 开放式架构
- 支持各种数据源类型
- 支持各种使用方式
- 架构简单
- 数据共享
- schema 过滤和推演
- 时间回溯
为什么需要新的数据架构?
数据仓库和数据湖一直是实现数据平台最流行的架构,然而,过去几年,社区一直在努力利用不同的数据架构方法来实现数据平台。
寻找新方法而不是经过充分验证的传统数据架构(如数据仓库或数据湖)的动机主要有两个原因:- 传统架构在作为独立系统实现时存在一些限制。
- 过去几年中社区出现了许多技术进步,云空间内的创新和开源技术的成熟是主要推动力。
公司不断寻求克服传统架构的局限性,并利用新技术来构建可扩展、安全且可靠的平台。公司、独立服务供应商 (ISV) 和系统集成商 (SI) 尝试了不同的方法和创新解决方案来实施此类数据平台。
下面列出了其中一些方法:- 结合数据湖和数据仓库两层架构。
- 利用混合事务/分析处理 (HTAP) 技术,联合使用在线事务处理系统 (OLTP) 和联机分析处理系统 (OLAP) 的工作方式。
- 构建可以处理非结构化数据以及结构化和半结构化数据的现代云数据仓库。
- 构建高性能计算引擎,直接在数据湖上执行 BI。
社区多年来的所有这些努力表明需要一种新的架构模式,该模式可以提供以下功能:
- 支持实施一个可以处理所有数据格式并支持多种用例的统一平台
- 应提供ACID支持、优秀的BI性能以及数据仓库的访问控制机制
- 应该像数据湖一样可扩展、经济高效且灵活。
- 最重要的是,它应该支持构建一个简单开放的数据平台,可以帮助用户轻松消费数据。
这就是过去几年出现的一种新模式——湖仓一体架构。
湖仓一体(Lakehouse)——新的大数据架构模式
新工具、产品和开源技术改变了公司在过去几年中构建大数据系统的方式。这些新技术有助于简化复杂的数据架构,构建更可靠、开放和灵活的数据平台,以支持各种数据存储和数据分析工作。
Lakehouse 是一种新的架构模式,它利用这些技术增强来构建简单且开放的数据平台。如下图所示,LakeHouse的核心是一个带有附加事务层和高性能计算引擎的数据湖。附加事务层帮助它获得类似数据仓库的ACID属性和其他特性。说明
附加事务层有时也称为元数据层,因为为了保持一致性, 它提供与事务相关的元数据。
同时具备数仓与数据湖的优点
使用 Lakehouse 架构构建的数据平台同时具有数据仓库和数据湖的特性,因此被称为 Lakehouse。下图显示了 Lakehouse 的关键功能,它结合了数据湖和数据仓库的最佳功能。
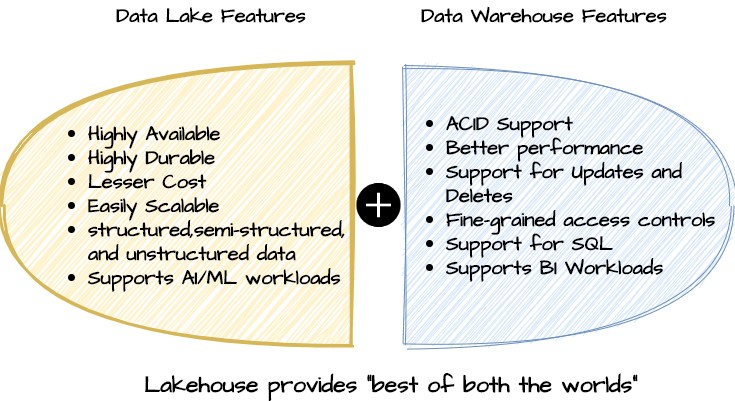
数据湖的优点- 高可用性
- 存储成本低
- 可扩展性好
- 支持各种结构化和非结构化数据存储
- 支持机器学习模型
数据仓库的优点
- 支持ACID 事物性
- 优秀的使用方式
- 支持更新和删除数据
- 权限控制简单
- 支持 SQL 查询
- 支持 BI 报表生成
Lakehouse 是如何支持数据湖的?
与数据湖一样,lakehouse 使用 Amazon S3、ADLS 或 OSS 等云对象存储,并以 Apache Parquet、Apache Avro 或 Apache ORC 等开放文件格式存储数据。
这种云存储使 Lakehouse 能够拥有数据湖的所有最佳功能,例如高可用性、高耐用性、成本低廉、可扩展性、支持所有数据类型(结构化、半结构化、非结构化)以及支持 AI/ML 用例。Lakehouse 是如何支持数据仓库的?
与数据湖相比,Lakehouse 有一个额外的组件 - 事务层,它是文件格式之上的附加层,这个额外的层将 Lakehouse 与数据湖区别开。它使 Lakehouse 能够获得数据仓库功能,例如 ACID 合规性、更新/删除支持、更好的 BI 性能和细粒度访问控制。用于实现该事务层的技术称为“open table formats”或“storage frameworks”。湖仓一体架构
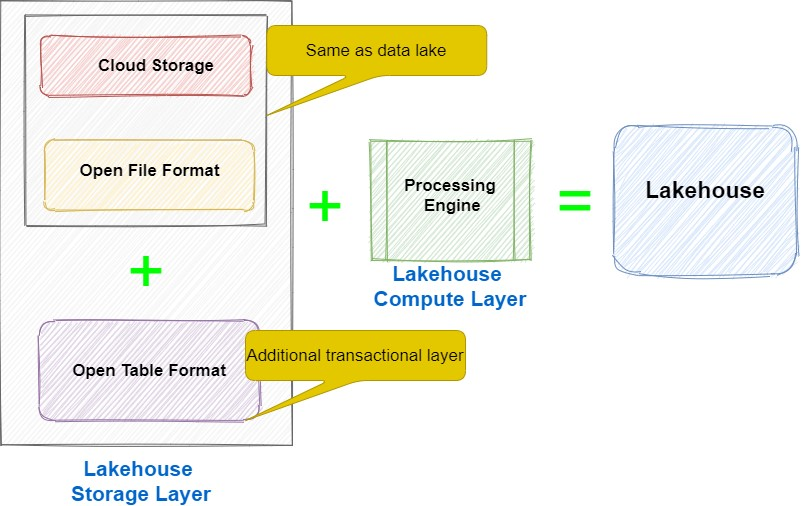
下图是数据湖仓的简单架构图,包括存储层和计算层:

Lakehouse架构由存储层和计算层组成,计算层的数据来源于存储层。存储层
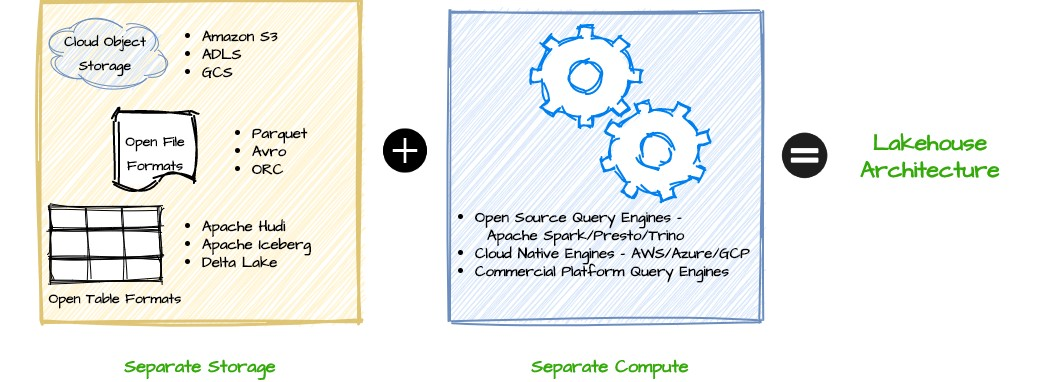
存储层主要由三个组件组成——云存储、开放的文件格式(open file format)和开放的表格式(open table format)。
云存储
云存储是一种提供实施数据湖和 Lakehouse 平台所需的高可用性、持久性和可扩展性的服务,可以使用亚马逊的 S3 存储或者阿里云的 OSS 对象存储等云服务商提供的对象存储。
公司也可以使用本地 HDFS 存储来实施 Lakehouse,仅使用云对象存储来实现 Lakehouse 是没有必要的。但考虑到成本低、计算与存储分离、易于扩展等特点,建议使用云对象存储作为实现 Lakehouse 的底层基础设施。开放的文件格式
数据平台可以将不同文件格式的数据存储在云存储中,CSV、JSON 和 XML 等文件格式是最流行的。对于分析平台,最广泛采用的三种文件格式是:- Apache Parquet
- Apache ORC
- Apache AVRO
这几种都是开源的列式存储格式,很多存储和处理应引擎都会兼容这几种存储格式。
开放的表格式
湖仓 Lakehouse 支持多种表存储格式,目前开源社区比较流行的是下边三种:-
Apache Iceberg
Apache Iceberg 是一种开放表格式,可与基于云的数据湖和 Apache Parquet、Apache AVRO 和 Apache Optimized Row Columnar (ORC) 等开放文件格式一起使用,以实现 Lakehouse 架构。它支持时间回溯、schema 推演和 SQL 查询等功能,使 Lakehouse 的构建更快、更容易。
-
Apache Hudi
Apache Hudi 有助于实现事务数据湖,并可用于为数据湖带来类似数据仓库的功能。它提供 ACID 事务保证、时间回溯和回滚能力以及schema 推演功能。
-
Linux 基金会的 Delta Lake
Databricks 将 Delta Lake 作为一个内部项目启动,后来在 Linux 基金会下将其开源。它通常被称为用于构建 Lakehouse 架构的开源存储框架。 Delta Lake 为数据湖提供元数据层和 ACID 功能。它还提供时间回溯、schema 推演以及审计跟踪记录等功能。
计算层
Lakehouse 架构的主要优点之一是其开放性以及可由任何兼容处理引擎直接访问或查询的能力。它不需要任何特定的专有引擎来运行 BI 工作负载或交互式分析。这些计算引擎可以是开源的,也可以是专为 Lakehouse 架构设计的专用商业查询引擎。
计算引擎
可以通过Apache Spark、Presto、Trino 和 Hive 等开源计算引擎,进行数据湖数据查询分析。湖仓一体特性
单一存储
如前面所说,lakehouse 的核心是一个使用云对象存储和附加事务层构建的数据湖。没有像专用数据仓库那样的单独存储来支持 BI 查询,所有消费者都直接从数据湖读取、访问或查询数据。相同的云对象存储支持所有用例,包括 BI 和 AI/ML 工作负载。
拥有数据仓库的查询性能
虽然数据湖使用对象存储保存数据,但是对象存储不适合进行大数据查询和分析,可以通过湖仓一体架构的计算层去查询计算存储层中(对象存储)的数据,拥有类似传统数据仓库的查询性能。
存算分离
Lakehouse 架构将存储和计算分离,这有助于单独扩展存储和计算容量,可以轻松添加更多存储,而无需增加计算容量,如下如所示:
开放式架构
Lakehouse架构使用“开放”方法来实现数据平台。它使我们可以自由地为我们的数据平台使用开源数据格式和开源计算引擎。与传统数据仓库不同,传统数据仓库计算和存储紧密绑定,Lakehouse 架构可以使用与底层存储格式兼容的任何分布式计算引擎。
这这种开放的架构设计可以使数据平台直接从云存储中访问数据,而不需要依赖于供应商绑定的各种软件。
支持各种数据源类型
因为使用的是对象存储,可以支持各种结构化和非结构化的源数据,并且使用的是 ELT 的加载模式,数据源在写入的时候,不会进行 schema 校验,可以快速的接入各种类型的数据源。
支持各种使用方式
因为支持各种类型的数据源接入,Lakehouse 架构除了支持 BI 报表查询,ETL 等,还支持 AI/ML 机器学习模型存储,实时计算等。
架构简单
所有数据都驻留在 Lakehouse 架构中的单个存储层中。由于没有单独的专用仓库,因此它简化了数据架构,并减少了将数据从数据湖移动到数据仓库所需的额外 ETL 管道。
它还避免了与数据集成到数据湖和数据仓库相关的延迟、故障或数据质量问题。
这种具有单存储层的架构有几个优点:
- 无需额外的工作即可在数据湖和数据仓库之间同步数据。
- 无需担心数据湖和数据仓库之间数据类型的更改。
- Lakehouse 中的数据治理变得更加容易,因为我们只需在一处实施访问控制。在两层存储系统中,我们必须维护单独的访问控制机制来访问数据湖和数据仓库中的数据,并确保它们始终同步。
- ML 工作时可以直接从 Lakehouse 读取数据,直接访问底层 Parquet、Avro 或 ORC 存储文件,而无需将任何聚合数据从数据仓库复制到 Lakehouse。
数据共享
下游数据消费者可以使用自己喜欢的方式直接从云对象存储中获取他们想要的数据,而无需和数据平台绑定,使用平台的工具,这使得数据共享非常简单。
另外数据生产者也不用关心用户改如何获取数据,只需要通过外部共享服务来做权限控制即可,如下图所示:
schema 过滤和推演
Lakehouse 架构在接入数据源时可以定义 schema 来保证写入的数据是要我们想要的类型和格式,但是也可以在写入时不定义 schema,这将可以保存各种格式和类型的数据,只需要在读取时定义 schema 就可以获取我们想要的数据。
这种 schema 推演可以保证数据的时效性,以及不丢失性。时间回溯
Lakehouse 架构的事物层使其能够维护各种版本的数据,这有助于我们查询各个版本的数据,只需要简单的指定版本号或者时间戳即可。
-







