
8类CNN-Transformer混合架构魔改方案盘点,附23个配套模型&代码



为进一步提高模型的性能,我们将CNN在局部特征提取方面的优势与Transformer在全局信息建模方面的优势两相结合,提出了CNN-Transformer混合架构。目前,它已经成为我们研究视觉任务、发文章离不开的模型。针对CNN+transformer组合方向的研究也成为了当下计算机视觉领域研究中的大热主题。
CNN-Transformer架构凭借众所周知的优势,在视觉任务上取得了令人瞩目的效果,它不仅可以提高模型在多种计算机视觉任务中的性能,还能实现较好的延迟和精度之间的权衡。为挖掘CNN-Transformer混合架构更多的潜力,有关于它的各种变体的研究也逐步增多。
为了方便同学们了解CNN-Transformer的最新进展与研究思路,我这次就和大家分享该架构常用的8种魔改方法,包含早期层融合、模块融合、基于注意力的融合等。每种方法的代表性模型以及配套的论文代码也都整理了,希望同学们阅读后可以获得缝合模块的启发,快速涨点。
23个模型原文及开源代码需要的同学看文末
1.早期层融合
Hybrid ViT
论文:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
用于大规模图像识别的Transformer
「简述:」Transformer架构在自然语言处理中很成功,但在计算机视觉中的应用有限。目前,注意力机制主要与卷积神经网络结合使用。我们发现,可以直接在图像补丁序列上应用纯Transformer,它在图像分类任务上表现很好。与最先进的卷积神经网络相比,Vision Transformer(ViT)在多个基准测试中取得了出色的结果,而且训练所需的计算资源大大减少。

DETR
论文:End-to-End Object Detection with Transformers
使用Transformers进行端到端目标检测
「简述:」论文提出了一种新的目标检测方法,将目标检测看作是一个直接集合预测问题。这种方法简化了检测流程,不需要像非最大抑制或锚点生成这样的手动设计组件。新方法的主要成分包括一个全局损失和一个变压器编码器-解码器架构。它通过推理对象之间的关系和全局图像上下文,直接并行输出最终预测集。这个模型概念简单,不需要专门的库,在COCO数据集上的准确性和运行时性能与Faster R-CNN相当。
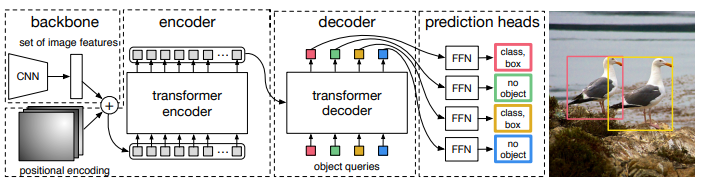
LeViT
论文:LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
用于更快推理的 ConvNet 服装中的视觉transformer
「简述:」论文设计了一种名为LeViT的混合神经网络架构,用于快速推理图像分类。该架构结合了卷积网络和视觉Transformer的优点,并引入了一些新的方法来提高准确性和效率。作者在不同硬件平台上进行了广泛的实验,结果表明LeViT在速度/准确性权衡方面优于现有的卷积网络和视觉Transformer。
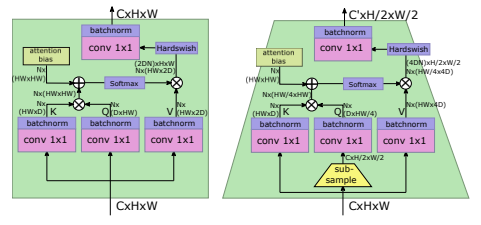
CPVT
论文:CONDITIONAL POSITIONAL ENCODINGS FOR VISION TRANSFORMERS
视觉transformer的条件位置编码
「简述:」论文提出了一种条件位置编码方案,用于视觉transformer。与先前的位置编码不同,作者的方案是动态生成的,并根据输入令牌的局部邻域进行条件化。这使得该方案可以推广到比模型在训练过程中见过的任何序列更长的输入序列,并提高了性能。作者还使用一个简单的位置编码生成器实现了该方案,并将其命名为条件位置编码视觉transformer(CPVT)。
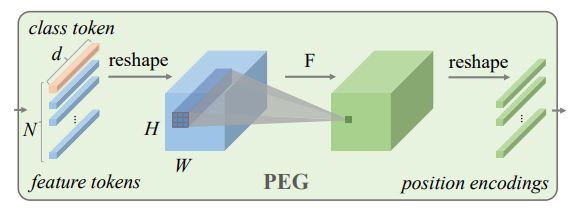
2.横向层融合
DPT
论文:Vision Transformers for Dense Prediction
用于密集预测的视觉transformer
「简述:」论文介绍了一种名为密集视觉transformer的网络架构,它使用视觉transformer代替卷积神经网络作为密集预测任务的主干。作者将来自视觉transformer不同阶段的令牌组合成不同分辨率的图像状表示,并逐步使用卷积解码器将它们合并为全分辨率预测。该架构在密集预测任务上表现出色,并在单目深度估计和语义分割等任务上创造了新的最高记录。
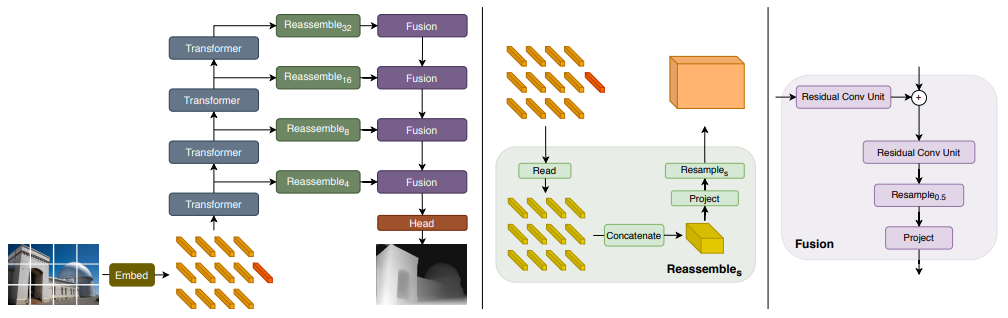
LocalViT
论文:LocalViT: Bringing Locality to Vision Transformers
将局部性引入视觉Transformer
「简述:」作者研究了如何将局部性机制引入视觉Transformer。通过在feed-forward网络中引入深度可分离卷积,增加了视觉Transformer的局部性。作者验证了局部性机制的重要性,并成功地将其应用于4种视觉Transformer。在ImageNet2012分类任务中,增强局部性的Transformer比基线表现更好,同时参数数量和计算量几乎没有增加。
3.顺序融合
CoAtNet
论文:CoAtNet: Marrying Convolution and Attention for All Data Sizes
结合卷积和注意力处理各种数据规模
「简述:」论文介绍了一种混合模型CoAtNets,它结合了卷积网络和Transformer的优势。通过简单的相对注意力和垂直堆叠卷积层和注意力层的方式,CoAtNets在ImageNet上实现了最先进的性能,同时具有更高的效率和泛化能力。
CMT
论文:CMT in TREC-COVID Round 2: Mitigating the Generalization Gaps from Web to Special Domain Search
缓解从网络到特定领域搜索的泛化差距
「简述:」本文介绍了一种针对特定领域(如COVID)的搜索系统,利用领域自适应预训练和少次学习技术来帮助神经排序器缓解领域差异和标签稀缺问题。该系统在TREC-COVID任务第二轮中表现最佳,旨在从与COVID-19相关的科学文献中检索有用信息。
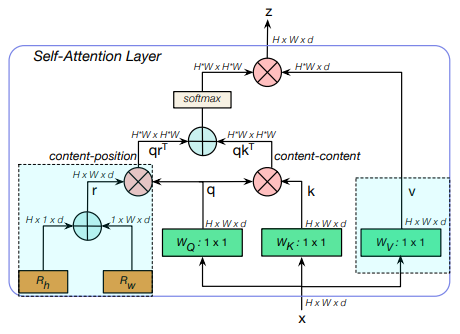
BoTNet
论文:Bottleneck Transformers for Visual Recognition
用于视觉识别的瓶颈Transformer
「简述:」论文介绍了一种名为BoTNet的骨干架构,它使用自注意力机制来处理计算机视觉任务,如图像分类、目标检测和实例分割。通过在ResNet的最后三个瓶颈块中使用全局自注意力替换空间卷积,该方法在实例分割和目标检测方面表现优异,同时减少了参数数量和延迟时间。作者还指出了如何将具有自注意力的ResNet瓶颈块视为Transformer块。
4.并行融合
Conformer
论文:Conformer: Local Features Coupling Global Representations for Visual Recognition
局部特征与全局表示相结合的视觉识别方法
「简述:」本文提出了一种名为Conformer的混合网络结构,结合了卷积操作和自注意力机制,以增强表示学习能力。Conformer采用并发结构,最大程度地保留局部特征和全局表示。实验表明,Conformer在ImageNet上比视觉变压器高出2.3%,在MSCOCO上比ResNet-101高出3.7%和3.6%的mAPs,分别用于目标检测和实例分割,展示了其作为通用骨干网络的巨大潜力。

Mobile-Former
论文:Mobile-Former: Bridging MobileNet and Transformer
连接MobileNet和Transformer
「简述:」论文提出了Mobile-Former网络结构,它结合了MobileNet和Transformer的优点,中间有双向桥接。该结构利用了MobileNet在局部处理和Transformer在全局交互方面的优势,并且桥接可以实现局部和全局特征的双向融合。Mobile-Former中的Transformer包含很少的令牌(例如6个或更少),这些令牌是随机初始化的,以学习全局先验知识,从而降低了计算成本。结合提出的轻量级交叉注意力来模拟桥接,Mobile-Former不仅计算效率高,而且具有更强的表示能力。
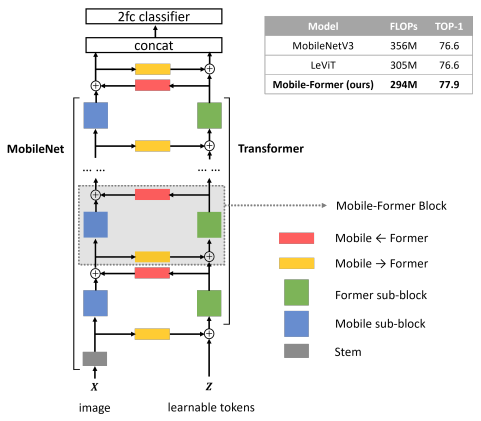
BossNAS
论文:BossNAS: Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search
使用分块自监督神经网络结构搜索探索混合CNN-Transformers
「简述:」论文提出了BossNAS无监督神经网络结构搜索方法,用于解决以前方法中由于大权重共享空间和有偏见的监督而导致的不准确架构评级问题。该方法将搜索空间分解为多个块,并利用自监督训练方案分别对每个块进行训练,然后将它们作为一个整体搜索向种群中心。在具有挑战性的HyTra搜索空间上,该方法搜索到的模型BossNet-T在ImageNet上实现了高达82.5%的准确性,比EfficientNet高出2.4%。
5.模块融合
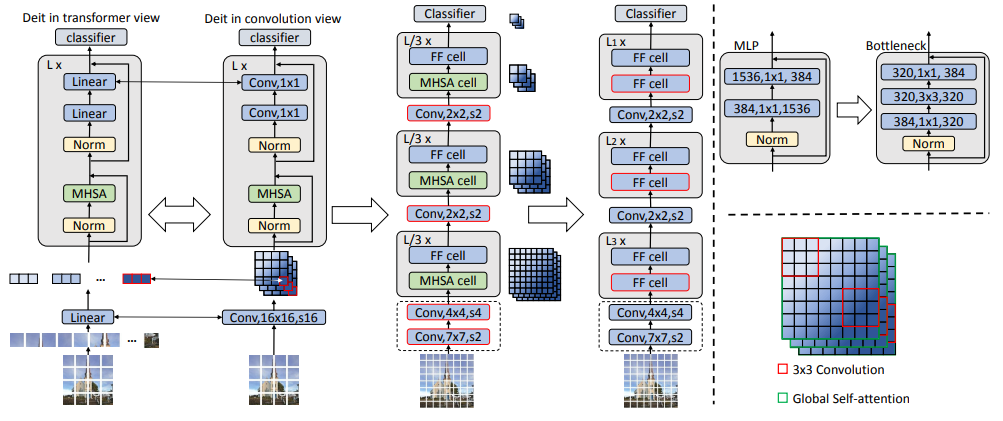
Early convolutions help transformers see better
早期的卷积有助于Transformer更好地观察
「简述:」本文研究了Vision transformer (ViT) 模型的优化问题,发现其对优化器的选择、超参数和训练计划长度非常敏感。作者认为这个问题可能与ViT模型的patchify stem有关,该stem是通过将输入图像应用一个步幅为p(默认为16)的p×p卷积实现的。为了测试这种非典型设计选择是否会导致问题,作者分析了原始patchify stem和用少量堆叠的步幅为2的3×3卷积替换ViT stem的简单对应物的ViT模型的优化行为。使用卷积stem替代ViT极大地提高了优化稳定性,并提高了峰值性能(在ImageNet-1k上提高了约1-2%的top-1准确性),同时保持了flops和运行时间不变。

Escaping the big data paradigm with compact transformers
用紧凑型Transformer摆脱大数据范式
「简述:」本文介绍了一种名为Compact Transformers的小型学习方法,通过合适的大小、卷积化的分词技术,使transformers能够避免过拟合,并在小数据集上超越最先进的CNN。该方法具有灵活性,模型大小可以很小,只有0.28M参数即可获得有竞争力的结果。在CIFAR-10上从零开始训练时,最佳模型可以达到98%的准确率,这是以前基于transformer的模型的数据效率的显著提高,比其他transformer小10倍以上,是ResNet50的15%大小,同时达到类似的性能。
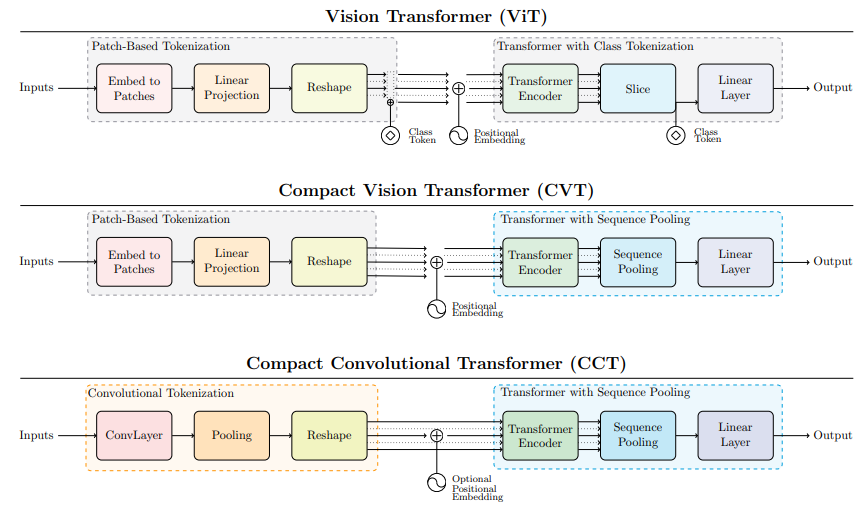
6.分层融合
MaxViT
论文;MAXIM: Multi-Axis MLP for Image Processing
用于图像处理的多轴MLP
「简述:」本文介绍了MAXIM多轴多层感知器(MLP)架构,用于图像处理任务。该架构使用UNet形状的分层结构,并支持长范围交互。MAXIM包含两个基于MLP的构建模块:一个多轴门控MLP和一个交叉门控块。作者的实验结果表明,所提出的MAXIM模型在多个图像处理任务上实现了最先进的性能,同时需要比竞争模型更少或相当数量的参数和FLOPs。
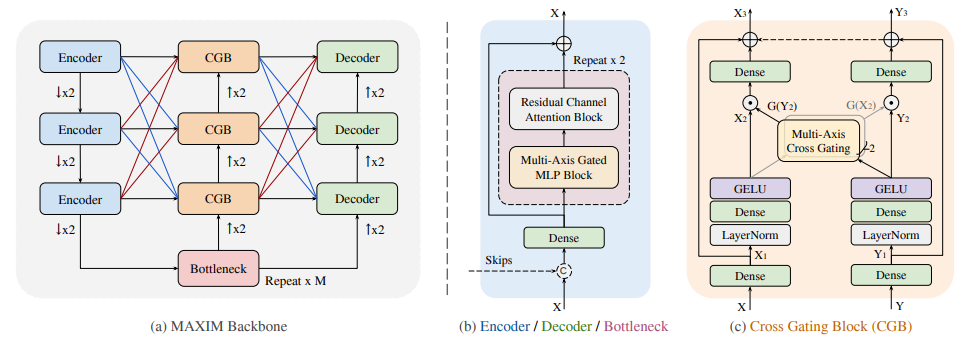
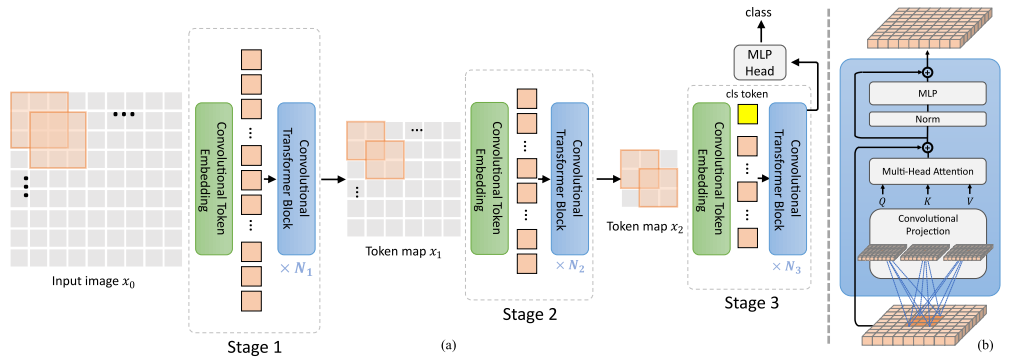
CvT
论文:CvT: Introducing Convolutions to Vision Transformers
将卷积引入视觉Transformers
「简述:」论文介绍了Convolutional vision Transformer(CvT)新架构,通过将卷积引入视觉Transformer来提高性能和效率。作者通过两个主要修改来实现这一目标:包含新卷积嵌入的Transformer层次结构和利用卷积投影的卷积Transformer块。这些更改将CNN的有利属性引入ViT架构,同时保持了Transformer的优点。作者通过实验验证了CvT,表明该方法在ImageNet-1k上实现了比其他视觉Transformer和ResNets更好的性能,同时具有更少的参数和更低的FLOPs。
Visformer
论文:Visformer: The Vision-friendly Transformer
视觉友好的Transformer
「简述:」论文介绍了一种名为Visformer的新架构,该架构通过逐步将基于Transformer的模型转换为基于卷积的模型来提高视觉识别性能。作者进行了实证研究,并在转换过程中获得了有用的信息。基于这些观察结果,作者提出了Visformer,它在ImageNet分类准确性方面优于其他模型,并且当模型复杂度较低或训练集较小时,优势更加显著。
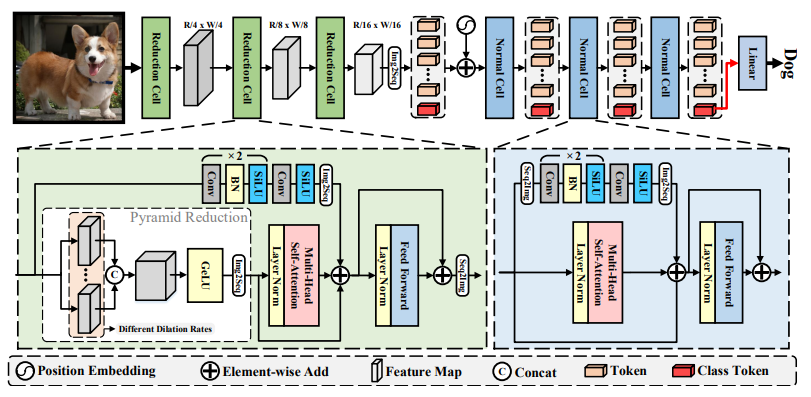
ViTAE
论文:ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias
通过探索内在归纳偏差提高视觉Transformer性能
「简述:」本文介绍了ViTAE架构,该架构通过从卷积中探索内在归纳偏差来提高视觉Transformer的性能。ViTAE具有多个空间金字塔缩减模块,能够降低输入图像的尺寸并将其嵌入到具有丰富多尺度上下文的令牌中,从而获得内在尺度不变性IB。此外,在每个Transformer层中,ViTAE还具有并行的卷积块,其特征被融合并输入到前馈网络中,以获得内在局部性IB。实验证明,ViTAE在ImageNet和下游任务上优于基线Transformer和并发工作。
ConTNet
论文:ConTNet: Why not use convolution and transformer at the same time?
为什么不同时使用卷积和Transformer?
「简述:」本文介绍了ConTNet架构,将Transformer与ConvNet结合起来,以提供更大的感受野。ConTNet可以像普通的ConvNets一样进行优化,并保持出色的鲁棒性。作者展示了ConTNet在图像分类和下游任务上的优越性和有效性。ConTNet还作为Faster-RCNN和Mask-RCNN的骨干网络,在COCO2017数据集上分别比ResNet50高出2.6%和3.2%。
7.基于注意力的融合
EA-AA-ResNet
论文:Evolving Attention with Residual Convolutions
使用残差卷积来发展注意力
「简述:」作者提出了一种基于进化注意力的新颖通用机制,以提高transformer的性能。一方面,不同层的注意力图共享共同知识,因此前面的层的注意力可以通过残差连接指导后续层的注意力。另一方面,低级和高级注意力在抽象水平上有所不同,因此作者采用卷积层来模拟注意力图的演化过程。所提出的进化注意力机制在多种任务上取得了显著的性能提升,包括图像分类、自然语言理解和机器翻译。
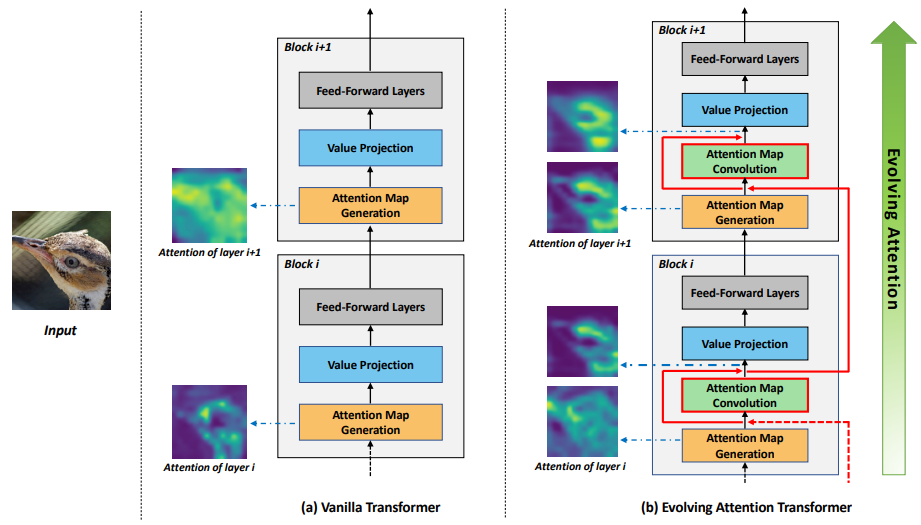
ResT
论文:ResT: An Efficient Transformer for Visual Recognition
用于视觉识别的高效Transformer
「简述:」论文介绍了一种名为ResT的高效多尺度视觉Transformer,可作为通用的图像识别主干。与现有的Transformer方法相比,ResT具有一些优势,如内存高效的多头自注意力机制、灵活的位置编码和重叠卷积操作的补丁嵌入等。实验结果表明,所提出的ResT可以大幅超越最近最先进的主干网络。
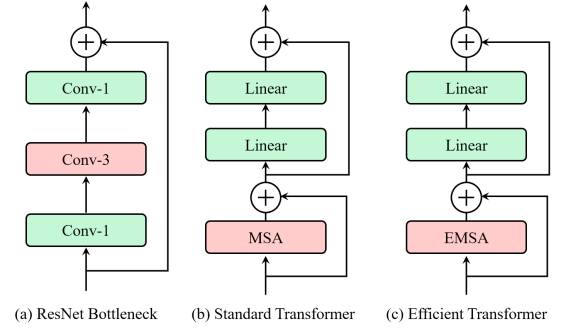
CeiT
论文: Incorporating Convolution Designs into Visual Transformers
将卷积设计融入视觉Transformers
「简述:」论文提出了CeiT架构,将CNN和Transformer结合起来,以提取低层次特征、加强局部性和建立长范围依赖关系。实验结果表明,CeiT具有更好的效果和泛化能力,无需大量训练数据和额外的CNN教师。此外,CeiT模型还表现出更好的收敛性,可以显著降低训练成本。
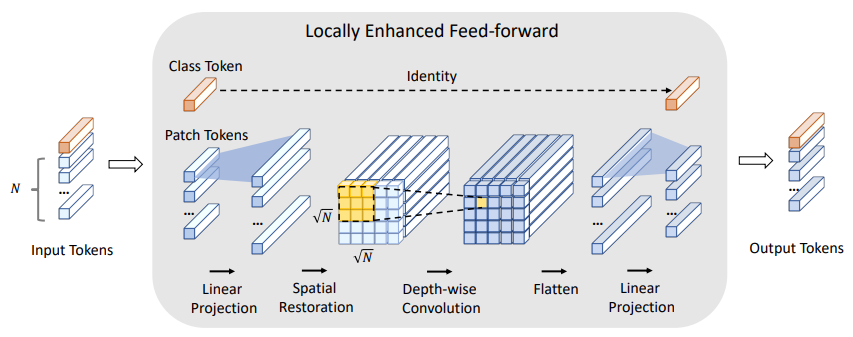
8.通道增强融合
CB-HVTNet
论文:CB-HVTNet: A channel-boosted hybrid vision transformer network for lymphocyte assessment in histopathological images
用于组织病理图像中淋巴细胞评估的信道增强混合视觉变换网络
「简述:」论文提出了一种名为CB-HVT的混合视觉变换器网络,用于组织病理学图像中淋巴细胞的评估。该网络使用迁移学习生成增强通道,并同时使用变换器和CNN来分析淋巴细胞。CB-HVT由五个模块组成,可以有效地识别淋巴细胞。在两个公开可用的数据集上进行的实验结果表明,CB-HVT具有良好的泛化能力,可以成为病理学家的有价值的工具。
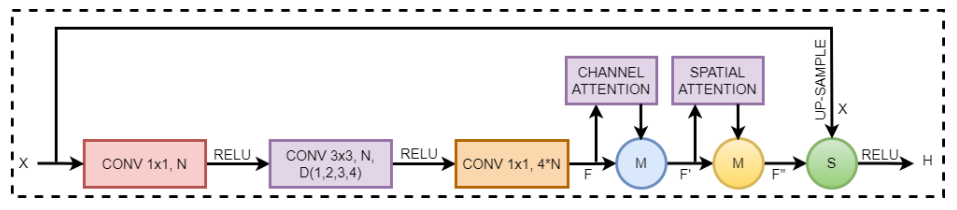
关注下方《学姐带你玩AI》🚀🚀🚀
回复“缝合模型”获取模型+论文+代码
码字不易,欢迎大家点赞评论收藏



