
Oracle的这些BUG你要遇到,说明你是一个DBA老鸟...



作者:IT邦德
中国DBA联盟(ACDU)成员,10余年DBA工作经验,
Oracle、PostgreSQL ACE
CSDN博客专家及B站知名UP主,全网粉丝10万+
擅长主流Oracle、MySQL、PG、高斯及Greenplum备份恢复,
安装迁移,性能优化、故障应急处理
文章目录
- 前言
- 1 创建本地数据文件bug
- 1.1 现象
- 1.2 隐患
- 1.3 解决办法
- 2.数据字典Bug
- 2.1 现象
- 2.2 隐患
- 2.3 解决办法
- 3.OGG的bug
- 3.1 现象
- 3.2 解决办法
- 4.lag延迟
- 4.1现象
- 4.2 处理办法
- 5.总结
前言
本文总结了一些Oracle隐藏的很深的的BUG分享给大家,一起来探讨
1 创建本地数据文件bug
1.1 现象
RAC集群创建表空间的时候,由于数据文件路径写错
竟然自动创建到了本地$ORACLE_HOME/dbs目录下
既然RAC一直强调ASM共享的理念,
那么核心的表空间是共享的
为什么能自动创建到本地呢?
这样就会造成另外一个实例无法访问
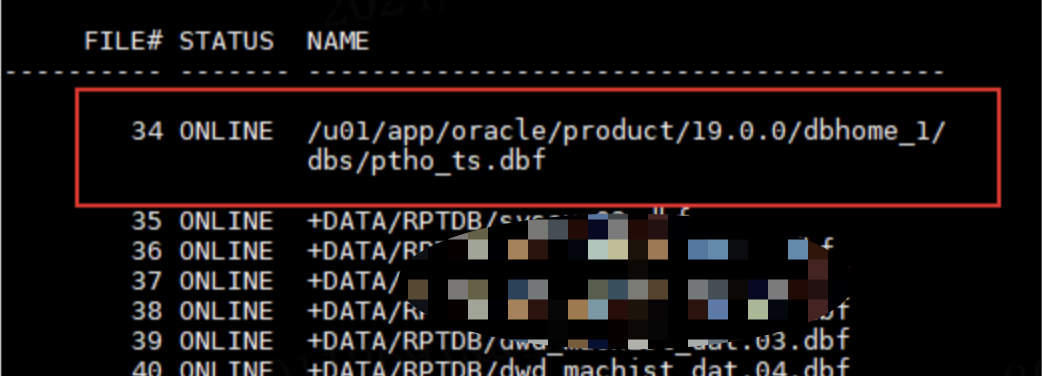
而此时我们通过过实例1 查询dba_data_files正常
sql rac1>select file_id,
tablespace_name,file_name,
status
from dba_data_files;
通过查询发现,新建的一个表空间建到了本地磁盘,
但是通过实例2去查询,发现错误,
select file_id,tablespace_name,
file_name,status
from dba_data_files;
ERROR at line 1:
ORA-01157: cannot identify/lock data file 34 - see DBWR trace file
ORA-01110: data file 34: '/u01/app/oracle/product/19.0.0/dbhome_1/dbs/ptho_ts.dbf
1.2 隐患
1.造成备份失败,因为RMAN备份前要做数据校验
同时会影响归档的删除,造成ASM磁盘撑爆
2.自动创建到本地后,业务正常写入数据,
发生故障转移,应用后大面积报错,同时也会撑爆本地磁盘
1.3 解决办法
offline数据文件恢复的方法
sql>alter database datafile 34 offline;
rman> backup as copy datafile 34 format ‘+data’;
rman> switch datafile 34 to copy;
sql>recover datafile 34;
sql>alter database datafile 34 online;
2.数据字典Bug
2.1 现象
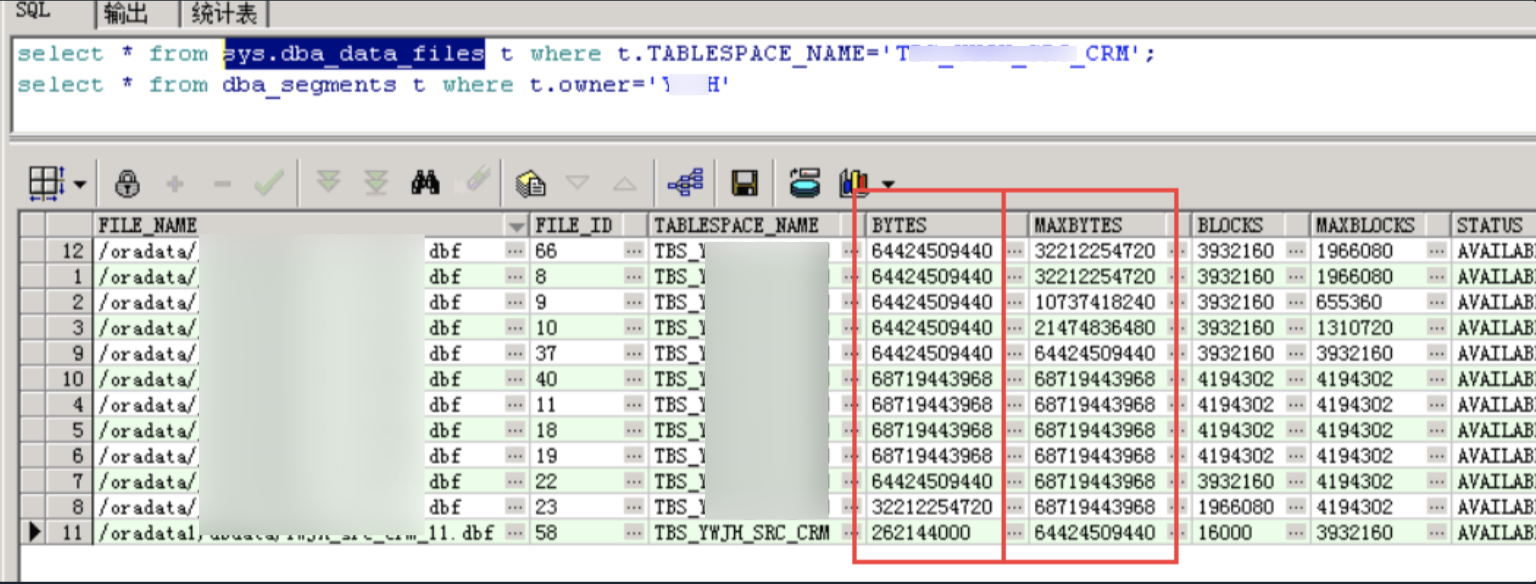
最近一次故障,设置的数据文件自增长,监控一直没有报警,
结果应用瘫痪了,提示表空间不足,
结果查询dba_data_files里的bytes值大于maxbytes值?
根据以往的Oracle运维经验觉得这绝对是不可能的。
但是数据查出来的事实就是这样的
2.2 隐患
当一个datafile 手工resize到一个大于maxsize(maxbytes)的值之后,
DBA_DATA_FILES中bytes的值要比maxbytes的值要大
当该datafile被设置为autoextend on之后,
dba_data_files中的maxbytes 值被自动结算为一个非零值。
这样会造成监控的时候监控不到,导致down机
2.3 解决办法
–resiz到32G
SQL> alter database datafile ‘/oracle/test.dbf’ resize 34358689792;
–取消自动扩展
SQL> alter database datafile ‘/oracle/test.dbf’ autoextend off;
其实启动扩展会带来很多性能到问题,建议取消
3.OGG的bug
3.1 现象
我们知道OGG的配置文件非常的重要,
某套库配置的是OGG数据同步是采用的DML和DDL同步
最近业务频繁发生,主库在维护分区表的时候,
触发以下BUG,官方的说法是维护分区表执行了错误的命令,
但是主库发出的分区维护操作是正确的
类似这种主库命令操作错误导致OGG终端层出不群
OGG-00492 DDL error ignored: error code [DEFAULT],
filter [include all (default)],
error text [Error code [14075]
ORA-14075: partition maintenance operations
may only be performed on partitioned indices
3.2 解决办法
对应的报错设置过滤即可
DDLERROR 1234 ABENDD --结束报错
DDLERROR 5678 IGNORE --忽略报错
为了避免语法错误造成的OGG终止
在目的端的replicat进程参数文件中加入如下配置,
在启动进程,启动成功。
ddlerror default ignore retryop
4.lag延迟
4.1现象
关于Oracle GoldenGate 的 Lag at Chkpt和Time Since Chkpt的理解,
前提需要理解OGG的每个进程都有它自己的checkpoint file。
每当一个进程看到在事务的commit时,
检查点文件中就将产生一个检查点。
OGG的恢复进程总是以检查点作为起点。
而OGG是通过监控的checkpoint和Lag at Chkpt
和Time Since Chkpt这2个指标来衡量数据同步延迟时效的。
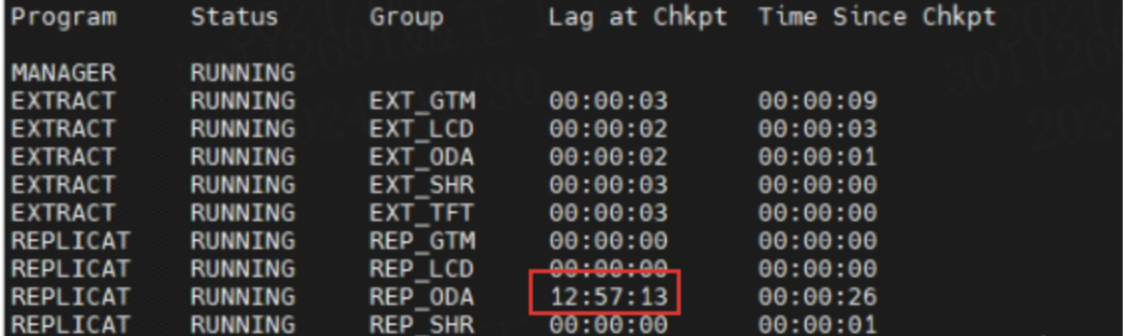
OGG复制一直正常同步,可是Lag at Chkpt为何有延迟呢
4.2 处理办法
官方的解释如下:
Time Since Checkpoint
指ogg的extract或replicat进程产生最近的一个检查点,
再从这个检查点到目前为止有多长时间没有更新了,
即最近一个检查点与当前系统时间的时间差。
该值可以通过info看到是在不断变化
(特别是当处理长会话时,会持续增长,直到处理完该长会话)。
Lag at Checkpoint
lag是复制进程处理最后一条记录的操作系统时间和此条记录在trail文件中记录的时间戳的差值,这里需要注意的是lag延迟只有在检查点更新时才会更新,
所以这个值不是实时更新的,
具有一定的离散性,
实际上应该理解成最后一个检查点的最后一条记录与当前系统时间的时间差。
OGG的lag指的是数据复制的延迟
–那么也就是长时间主库如果没有事物提交就会发生这种现象
解决的办法如下:
–前滚重新生成一个新的队列文件
alter extract xxx etrollover
–重置读取进程,重新从0号trial文件开始读取。
alter replicat rep1,extseqno 0,extrba 0 或者
alter rep1,begin now
5.总结
以上报错,仅个人的一点独特见解,希望大家一起讨论分享你们的认为的bug







