
Elasticsearch中的三种分页策略深度解析:原理、使用及对比



在Elasticsearch中,分页是查询操作中不可或缺的一部分。随着数据量的增长,如何高效地分页查询数据急需需要面对的问题。Elasticsearch提供了三种主要的分页方式:from + size、scroll和search_after。下面详细介绍这三种分页方式的特点和使用场景。
目录
- 方式一:from + size
- 实现原理
- 使用方式
- 优点
- 缺点
- 使用场景
- 方式二:scroll
- 实现原理
- 使用方式
- DSL 代码示例
- 优点
- 缺点
- 使用场景
- 方式三:search_after
- 实现原理
- 使用方式
- 优点
- 缺点
- 使用场景
- 三种方式总结
- 结语
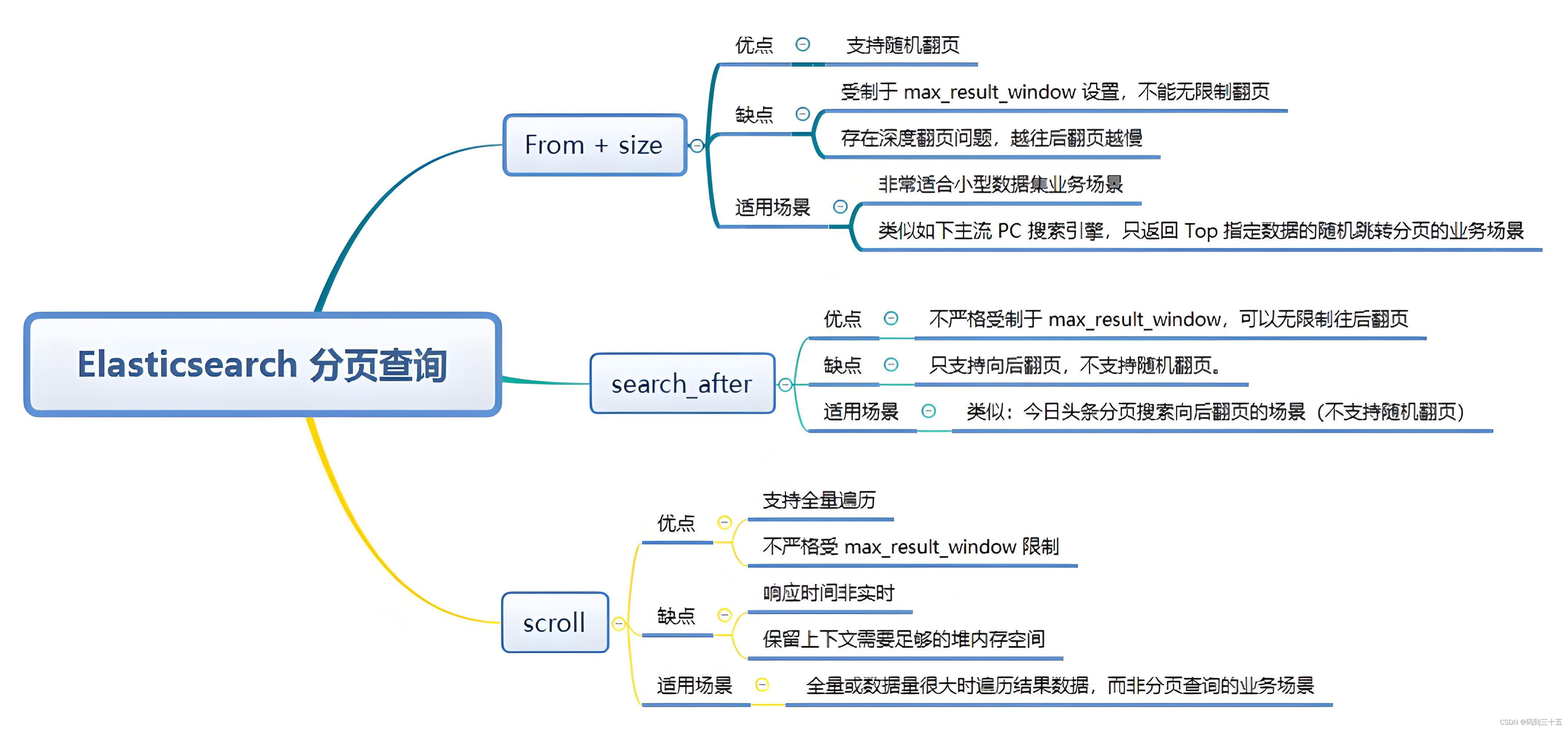
方式一:from + size
from + size是Elasticsearch中最直观的分页方式。其中,from参数表示从第几条记录开始返回,size参数表示返回的记录数。
实现原理
from + size 分页方式的原理相对简单。当你执行一个搜索查询并指定了 from 和 size 参数时,Elasticsearch 会进行以下步骤:
- 分发查询:Elasticsearch会将查询请求分发到所有相关的分片上。
- 查询分片:每个分片都会执行查询,并返回前 from + size 条符合条件的文档(但实际上只会用到最后的 size 条)。
- 合并和排序:协调节点(通常是执行搜索的Elasticsearch节点)会收集所有分片返回的结果,将它们合并成一个全局的结果集,并根据查询中指定的排序规则进行排序。
- 截断和返回:然后,协调节点会从排序后的结果集中截取从 from 位置开始的 size 条记录,并将它们返回给客户端。
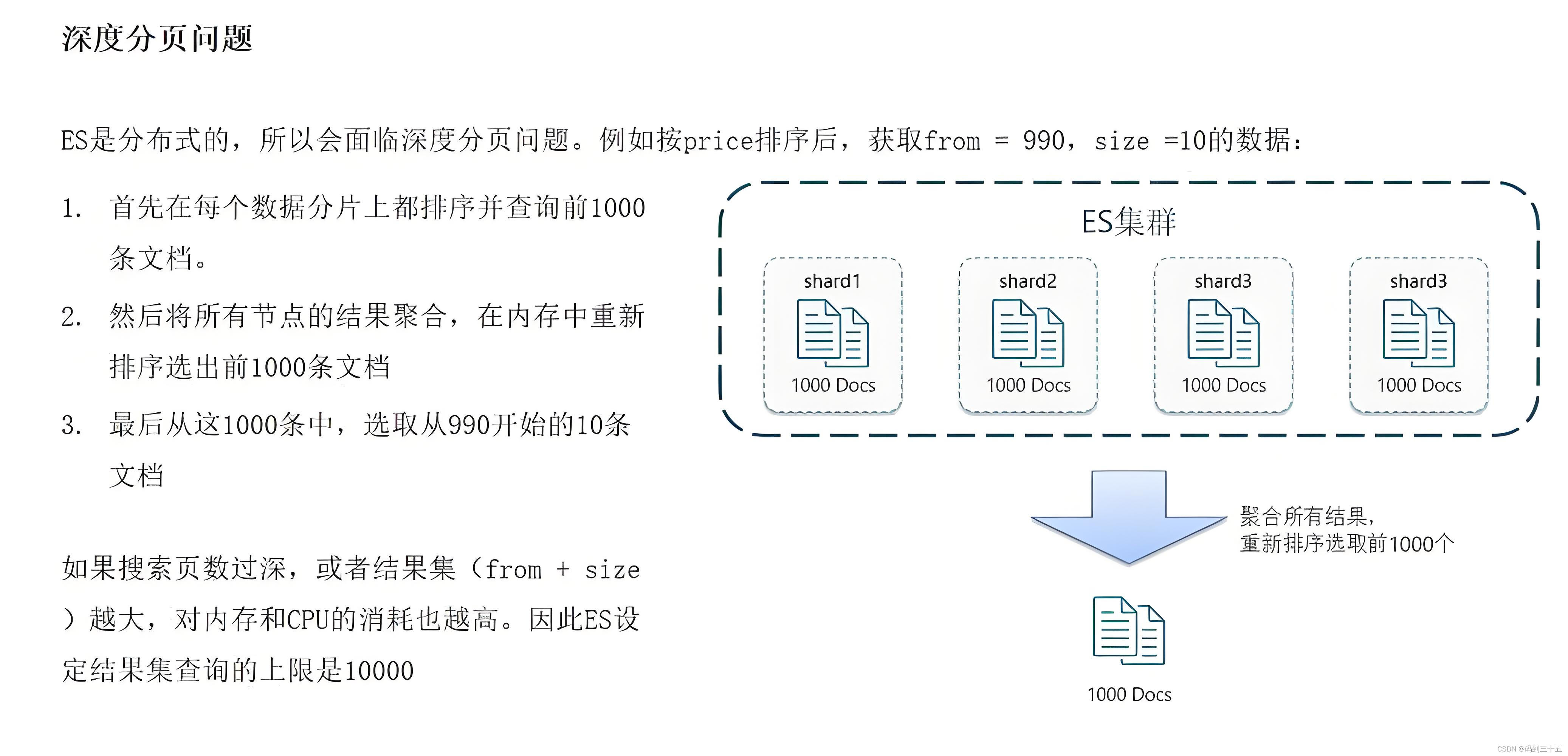
由于 from + size 需要合并和排序所有分片返回的结果,因此当 from 值很大时,这个过程可能会变得非常慢,因为它需要处理大量的数据。
使用方式
在Elasticsearch中,使用from和size进行分页查询的DSL(Domain Specific Language):
GET /your_index/_search { "query": { "match_all": {} // 这里可以替换为任何你需要的查询条件 }, "from": 0, // 从第几条记录开始,索引从0开始 "size": 10, // 返回的记录条数 "sort": [ { "field_name": {"order": "asc"}} // 可选,根据某个字段进行排序 ] }from参数指定了从哪一条记录开始返回,size参数指定了要返回的记录条数。
假设一个名为products的索引,搜索名称中包含"apple"的产品,并且从第10条记录开始返回10条结果,按价格升序排序:
GET /products/_search { "query": { "match": { "name": "apple" } }, "from": 9, // 注意,索引从0开始,所以第10条记录的索引是9 "size": 10, "sort": [ { "price": {"order": "asc"}} ] }from设置为9以跳过前9条记录,size设置为10以返回接下来的10条记录,并且结果按照price字段的升序排列。
Elasticsearch会返回如下响应:
{ "took": 5, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 100, // 假设总共有100条符合查询条件的产品 "relation": "eq" }, "max_score": 1.0, "hits": [ { "_index": "products", "_type": "_doc", // 注意:在Elasticsearch 7.x及之后的版本中,_type字段通常被设置为"_doc" "_id": "10", "_score": 1.0, "_source": { "name": "Apple iPhone 12", "price": 999.99, // ... 其他字段 } }, // ... 其他9条产品的结果 { "_index": "products", "_type": "_doc", "_id": "19", "_score": 1.0, "_source": { "name": "Apple Watch Series 6", "price": 399.99, // ... 其他字段 } } ] } }优点
- 直观易用:开发者可以很容易地指定要返回的记录范围和数量。
- 实时性:适用于实时搜索场景,可以立即获取最新的查询结果。
缺点
- 性能问题:当from值很大时,Elasticsearch需要遍历大量数据才能找到起始位置,然后返回size条记录。这会导致查询性能下降,尤其是在数据量很大的情况下。
- 资源消耗:深度分页会消耗大量CPU和内存资源,对集群性能造成压力。
使用场景
适用于数据量不大、实时性要求高的场景。
方式二:scroll
scroll是一种基于游标的分页方式,它允许我们遍历大量数据而不需要在每次请求时重新计算整个搜索。
实现原理
scroll 分页方式的原理与游标(cursor)类似。当你执行一个带有 scroll 参数的搜索查询时,Elasticsearch 会:
- 初始化搜索上下文:Elasticsearch会为这次搜索创建一个快照(snapshot),并存储相关的搜索上下文(search context)。这个上下文包括查询本身、排序方式、聚合等所有与搜索相关的信息。
- 返回初始结果:然后,Elasticsearch会像普通搜索一样返回第一批结果,并附带一个 scroll_id。这个 scroll_id 是唯一标识这次搜索上下文的。
- 使用 scroll_id 获取更多结果:客户端可以使用这个 scroll_id 来请求更多的结果。Elasticsearch会基于之前存储的搜索上下文,从快照中检索更多的结果,并返回给客户端。这个过程可以重复多次,直到所有的结果都被检索完或搜索上下文过期。
由于 scroll 只需要在开始时计算一次搜索上下文,并在之后基于这个上下文来获取结果,因此它在处理大量数据时通常比 from + size 更快。但是,它也会消耗更多的服务器资源来维护搜索上下文和快照。
使用方式
在Elasticsearch中,scroll是一种用于检索大量数据(可能是数百万条记录)的分页机制,它允许你保持一个搜索的“上下文”并继续检索结果,而不需要为每一页都重新计算整个搜索。以下是使用scroll进行分页的DSL代码示例:
DSL 代码示例
// 初始化scroll搜索 POST /_search/scroll { "size": 100, // 每次返回的文档数量 "scroll": "1m", // 保持scroll上下文的活动时间,这里是1分钟 "query": { "match_all": {} // 可替换为任何需要的查询条件 } } // 后续的scroll请求(在第一次请求返回后) POST /_search/scroll { "scroll": "1m", // 保持与第一次请求相同的scroll上下文时间 "scroll_id": "你的scroll_id" // 第一次请求返回的scroll_id }说明
- 首次POST /_search/scroll请求会返回一部分结果(基于size参数)以及一个scroll_id。
- 使用这个scroll_id,你可以通过后续的POST /_search/scroll请求来获取更多的结果。
- scroll参数定义了在多长时间内可以保持scroll上下文有效。如果在这个时间内没有新的scroll请求,那么scroll上下文就会被删除,无法再获取更多结果。
响应结果
第一次请求会返回如下结果:
{ "_scroll_id": "DnF1ZXJ5THV6QXRlbl84791547351", "took": 1, "timed_out": false, "_shards": { "total": 5, "successful": 5, "failed": 0 }, "hits": { "total": { "value": 1000, "relation": "eq" }, "max_score": 1.0, "hits": [ { "_index": "your_index", "_type": "_doc", "_id": "1", "_score": 1.0, "_source": { // ... 文档的源数据 ... } }, // ... 其他文档 ... ] } }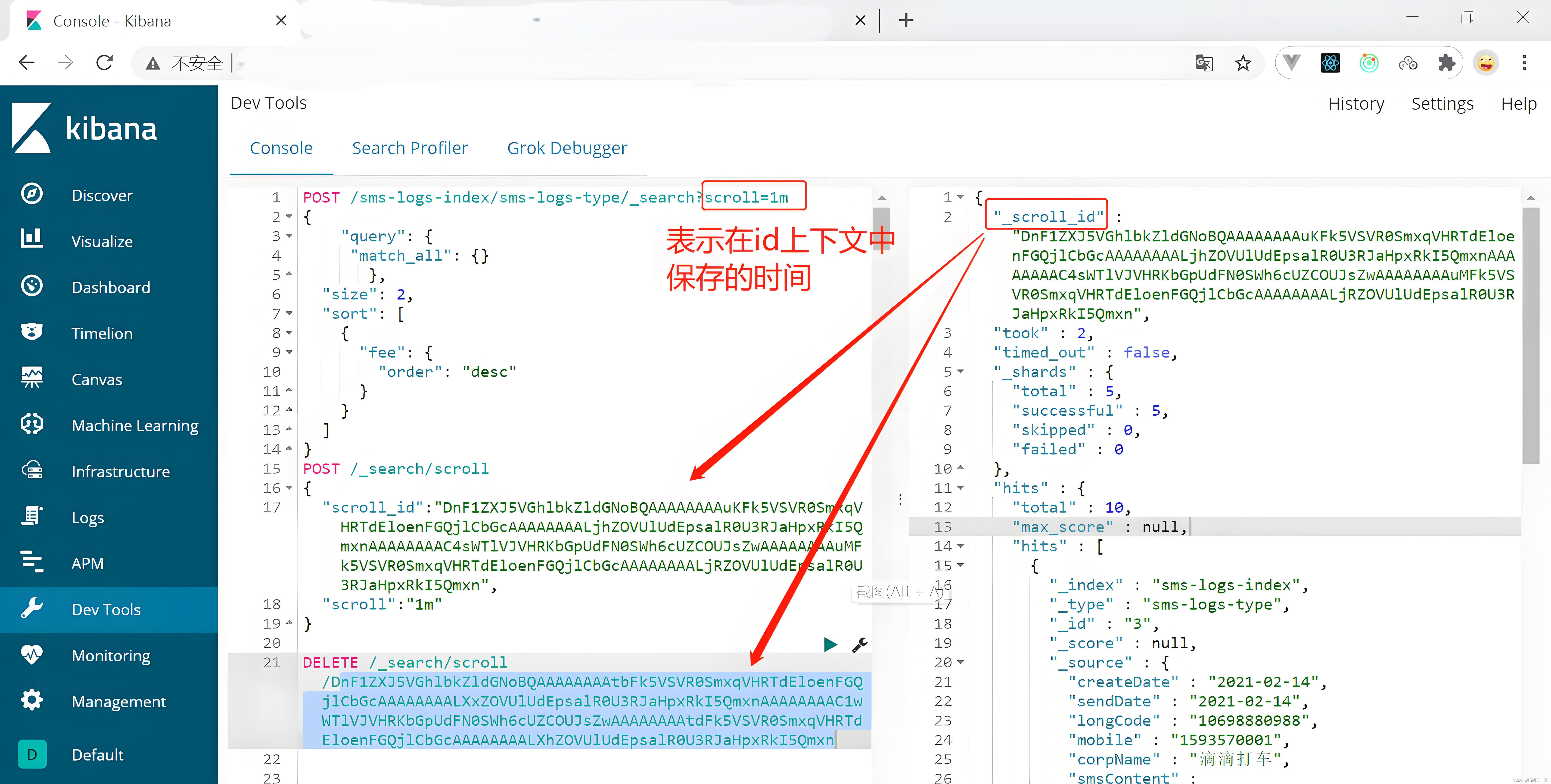
响应中可以看到_scroll_id字段,这个值需要用于后续的scroll请求。
后续的scroll请求
使用上面响应中的_scroll_id进行后续的scroll请求:
POST /_search/scroll { "scroll": "1m", "scroll_id": "DnF1ZXJ5THV6QXRlbl84791547351" }这个请求会返回下一批文档,直到所有的文档都被检索完或者scroll上下文过期。
根据你的Elasticsearch集群的实际设置和性能需求来调整size和scroll参数的值。
优点
- 高效性:scroll会维护一个游标,通过游标来获取下一批数据,而不是重新计算整个搜索。这使得scroll在处理大量数据时更加高效。
- 实时性:scroll可以获取到查询发起时刻的数据快照,并在整个scroll过程中保持这个快照。这意味着在scroll过程中,即使有新数据写入,也不会被包含在查询结果中。
缺点
- 非实时性:由于scroll是基于数据快照的,因此它不适用于需要实时获取最新数据的场景。
- 资源消耗:scroll会消耗大量的服务器资源来维护游标和数据快照,因此需要谨慎使用。
使用场景
适用于需要遍历大量数据、非实时性要求高的场景,如日志导出、数据迁移等。
方式三:search_after
search_after是一种基于排序值的分页方式,它允许我们根据上一页的最后一条数据的排序值来获取下一页的数据。
实现原理
search_after 分页方式的原理是基于上一次查询的结果来确定下一次查询的起始位置。当你执行一个带有 search_after 参数的搜索查询时,Elasticsearch 会:
- 排序和返回结果:首先,Elasticsearch会像普通搜索一样执行查询,并根据指定的排序字段对结果进行排序。然后,它会返回第一批结果。
- 确定下一次查询的起始位置:客户端可以选择结果集中的任意一条记录作为下一次查询的起始位置。这通常是通过记录该条记录的排序字段值来实现的。
- 使用 search_after 获取更多结果:在下一次查询时,客户端会指定 search_after 参数,并将上一次查询的起始位置(即排序字段值)作为该参数的值。Elasticsearch会基于这个值来确定下一次查询的起始位置,并返回该位置之后的结果。
由于 search_after 不需要像 from + size 那样合并和排序所有分片返回的结果,也不需要像 scroll 那样维护搜索上下文和快照,因此它在深度分页时通常比这两种方式更高效。但是,它要求排序字段的值必须是唯一的,以确保能够准确地确定下一次查询的起始位置。
使用方式
有一个名为products的索引,它包含产品的信息,想要根据产品的价格和上架时间进行分页查询。
1. 索引结构
products索引有以下的字段结构:
- product_id (keyword类型,作为文档的唯一标识)
- price (float或scaled_float类型,表示产品价格)
- created_at (date类型,表示产品上架时间)
2. 初始查询(没有search_after)
首先执行一个初始查询来获取第一页的结果,并基于price(降序)和created_at(升序)进行排序。
GET /products/_search { "size": 10, "query": { "match_all": {} // 或者你可以添加具体的查询条件 }, "sort": [ { "price": {"order": "desc"}}, { "created_at": {"order": "asc"}} ] }3. 处理响应并准备search_after参数
从响应中可以获取最后一篇文档的排序字段值(即price和created_at的值)。这些值将用于下一页的search_after请求。
响应中的最后一个文档:
{ "_index": "products", "_type": "_doc", "_id": "最后一个产品的ID", "_score": null, "_sort": [ 129.99, // 最后一个产品的price值 "2023-10-23T12:00:00Z" // 最后一个产品的created_at值 ], "_source": { // ... 产品的详细信息 ... } }将这些_sort字段的值(即129.99和"2023-10-23T12:00:00Z")作为下一页请求中的search_after参数。
4. 使用search_after进行下一页查询
使用search_after来请求下一页的数据:
GET /products/_search { "size": 10, "query": { "match_all": {} // 保持与初始查询相同的查询条件 }, "sort": [ { "price": {"order": "desc"}}, { "created_at": {"order": "asc"}} // 保持与初始查询相同的排序字段和顺序 ], "search_after": [ 129.99, // 上一页最后一个产品的price值 "2023-10-23T12:00:00Z" // 上一页最后一个产品的created_at值 ] }5. 重复以上步骤以获取更多页
可以继续执行上述步骤来获取更多的页面,直到没有更多的结果返回为止。记得每次都要使用上一页最后一个文档的排序字段值来设置search_after参数。
优点
- 高效性:相比from + size,search_after在深度分页时更加高效。因为它不需要像from + size那样获取并排序大量的数据,而只需要根据排序值获取下一页的数据。
- 灵活性:search_after允许我们跳过中间的页面,直接获取指定位置的数据。
缺点
- 依赖排序字段:search_after需要依赖一个或多个排序字段来确定下一页的位置。如果排序字段的值不是唯一的,可能会导致查询结果不准确。
- 实时性:虽然search_after比scroll更实时,但它仍然无法获取到查询发起后的最新数据。
使用场景
适用于需要深度分页、实时性要求相对较高、且排序字段唯一的场景。
三种方式总结
-
from + size(浅分页)
- 原理:通过指定from(起始偏移量)和size(每页大小)来分页。默认from为0,size为10。
- 优点:简单直观,易于理解。
- 缺点:
- 当from值很大时,性能会显著下降,因为Elasticsearch需要从每个分片中获取指定数量的文档,然后在协调节点进行全局排序以获取最终的结果。这会导致大量的网络传输和CPU/内存消耗。
- 不适合处理大量数据或深度分页的情况。
- 适用场景:适用于数据量较小或不需要深度分页的场景。
-
scroll
- 原理:类似于数据库中的游标,通过保持一个滚动上下文来获取大量数据。每次请求会返回一个scroll_id,用于获取下一页数据。
- 优点:
- 适用于需要获取大量数据(如数据导出)的场景。
- 可以保持滚动上下文,无需在每次请求时重新计算。
- 缺点:
- 滚动上下文会占用服务器资源,如果长时间不关闭,可能会导致资源耗尽。
- 不支持随机访问页面,只能顺序获取数据。
- 默认情况下,scroll请求会保持一段时间(如1分钟)的上下文,如果在这段时间内没有新的请求,上下文将被自动清除。
- 适用场景:适用于需要按顺序获取大量数据的场景,如数据导出。
-
search_after
- 原理:通过指定上一页最后一个文档的排序值来获取下一页数据。需要配合sort字段使用。
- 优点:
- 在深度分页时性能较好,因为它避免了全局排序和大量网络传输。
- 可以随机访问页面。
- 缺点:
- 需要确保每次请求都使用相同的排序字段和顺序。
- 如果排序字段的值发生更改(如文档被更新或删除),可能会导致结果不一致。
- 适用场景:适用于需要深度分页或随机访问页面的场景。
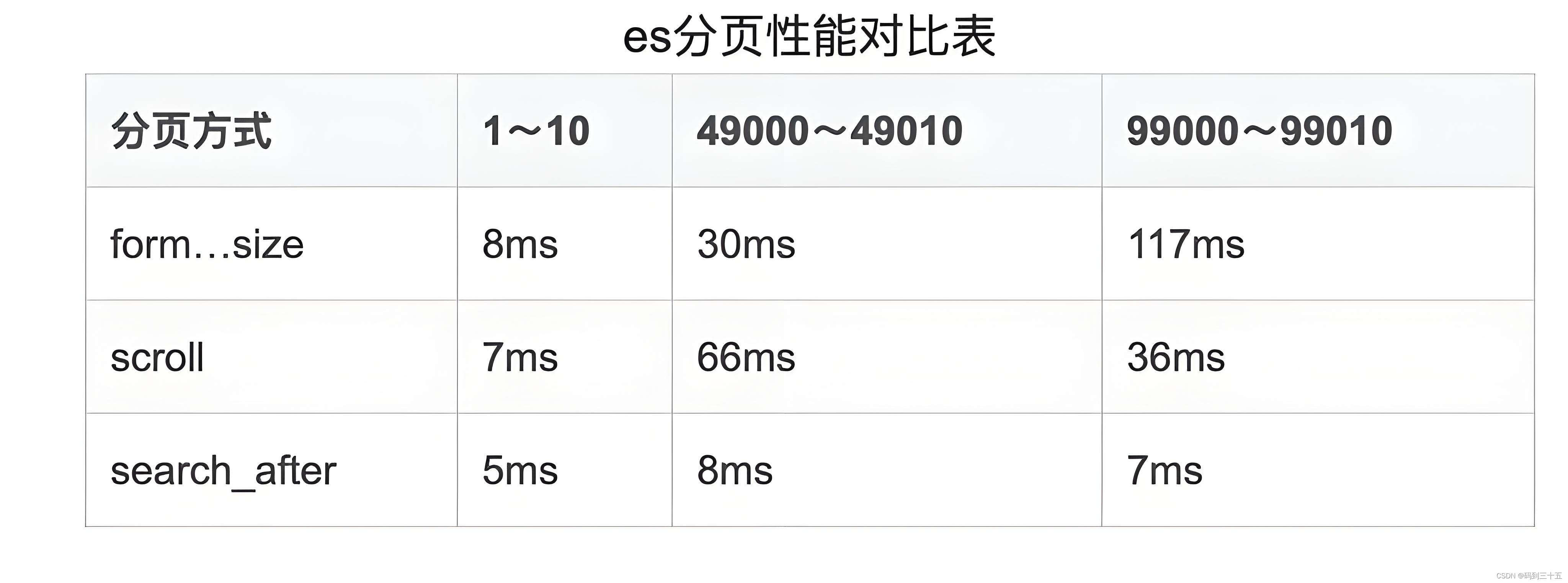
选择哪种分页方式取决于你的具体需求和场景。对于大多数常见的分页需求,from + size(浅分页)可能足够使用。但是,如果你需要处理大量数据或进行深度分页,那么scroll或search_after可能是更好的选择。
结语
在选择Elasticsearch的分页方式时,需要根据具体的需求和使用场景来权衡各种方式的优缺点。from + size适用于数据量不大、实时性要求高的场景;scroll适用于需要遍历大量数据、非实时性要求高的场景;而search_after则适用于需要深度分页、实时性要求相对较高、且排序字段唯一的场景。通过合理使用这些分页方式,可以提高Elasticsearch的查询性能,更好地满足业务需求。
更多深度内容...请关注公众号,纯技术,纯干货 !
-



