
【保姆级爬虫】微博关键词搜索并获取博文和评论内容(python+selenium+chorme)



微博爬虫记录
写这个主要是为了防止自己忘记以及之后的组内工作交接,至于代码美不美观,写的好不好,统统不考虑,我只能说,能跑就不错了,上学压根没学过python好吧,基本上是crtl+c&ctrl+v丝滑小连招教会了我一点。
写的很简单,认真看完就会用了
文中筛选元素用到的一些筛选元素的正则匹配、beautifulsoup,css等相关方法我也不太懂,现学现用呗,还是那句话,能跑就行。
配置简介:
python3.6、selenium3.13.0,chorme以及与chorme版本对应的chormedriver
(selenium在4版本后的一些语句会需要修改,网上一大把自己查)
目录
1、启动程序控制的chorme,手动登录微博
2、在微博进行关键词的检索
3、微博的发布信息获取
4、保存数据
5、实现自动翻页
6、微博的评论信息获取
1、先启动一个由程序控制的chorme
(1)win+R,输入cmd打开命令行,输入代码进入chorme的安装位置
C:\Program Files\Google\Chrome\Application
(2)分配chorme的端口号(我这里设置的是9527)和数据目录(我这里是在D:\selenium\AutomationProfile)
chrome.exe --remote-debugging-port=9527 --user-data-dir="D:\selenium\AutomationProfile"
每次执行(1)(2)两行命令就能打开同一个chorme了,建议放在程序解析的最上方,这样浏览器关闭后下次可以通过命令行快速打开
(3)浏览器已经打开了,登录一下自己的微博
(4)链接一下程序和浏览器
# 这部分代码我直接扔在了所有函数之前,搞全局
# 把chormedriver的路径写到这里
chromedriver_path= "D:/Users/16653/AppData/Local/Programs/Python/Python36/chromedriver.exe"
option = ChromeOptions()
option.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
web = webdriver.Chrome(executable_path=chromedriver_path, options=option)
web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
web.implicitly_wait(10)# 等待网页的加载时间
2、进行关键词的检索
从这里开始写函数的主体,自己搞个函数名把这些代码放进去
关键词搜索的链接如下:
https://s.weibo.com/weibo?q=这里填关键词&Refer=index
搜索页面翻页直接在后面加一个page=页码,如第二页
https://s.weibo.com/weibo?q=这里填关键词&Refer=index&page=2
selenium获取初步搜索结果
web.get(url) # url就是搜索的链接 html = web.page_source print (html) # 输出当前程序获取到的网页信息,用于检查网页是否正常获取
在浏览器里点击右键选择检查,在浏览器里面可以用检查页面左上角的框框箭头符号方便得在左边选择图案或者文字,然后实时在右边看到这个被选择的要素在哪个标签
可以发现每个博文都在action-type="feed_list_item"的div标签下(结合下图左右蓝色部分理解,标签就是一个包含的东西)这是一个很重要的地方,学会用浏览器的这个功能选取自己需要的信息在哪个标签里面,下面所有获取信息的代码几乎都是基于此
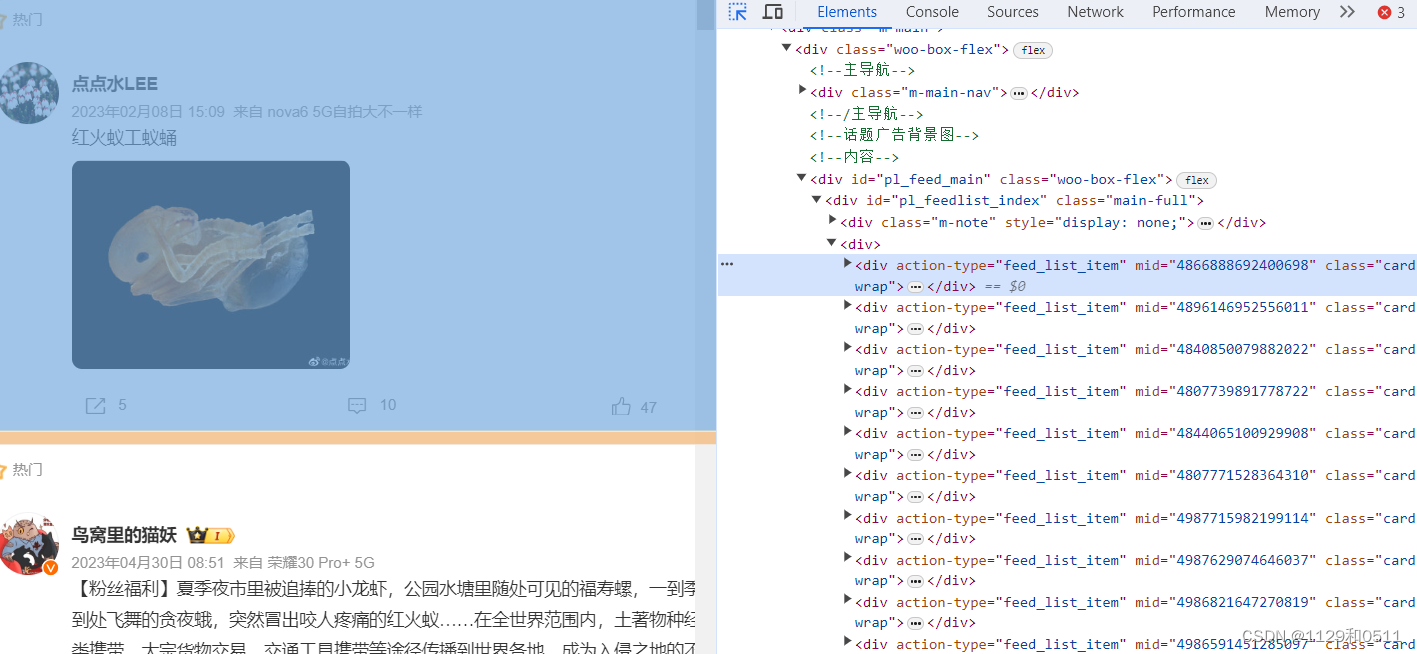
那我们可以通过beautifulsoup的findAll函数把所有这些标签的内容选择出来放进list(其他标签下提取信息也适用这个函数哦,只需要对应修改div,action-type,feed_list_item就行)
如果只想要找到的第一个div标签下的信息就用find函数,而不是findAll
soup = bs(html, 'html.parser')
list = soup.findAll("div", {'action-type': "feed_list_item"})
3、解析多种数据
(1)获取博文的文本内容,微博的文章字数太长会收起来,为了文本内容获取完整必须先将所有文本展开。

web_object = {}
html = web.page_source
# 获取这一网页的所有未展开的文章的展开按钮
button_list = web.find_elements_by_css_selector('a[action-type="fl_unfold"]') #点击所有展开
# 在for循环里面每个都点击展开
for bt in button_list:
try :
bt.click()
except Exception as e:
print(e.args)
# html转beautifulsoup格式
soup = bs(html, 'html.parser')
# 已经展开了,开始正常获取这一页的微博列表list
list = soup.findAll("div", {'action-type': "feed_list_item"})
for i in list:
# 获取微博的文本信息,strip用于跳过字符前面的空白
txt = i.findAll("p", {'class':"txt"})[-1].get_text().strip()
print(txt) # 输出获得的内容
web_object['text'] = txt
(2)获取微博的mid
mid = i.get("mid")
print("mid",mid)
web_object['mid'] = mid
(3)获取发布者的昵称
user_name = i.find("a", {'class': "name"}).get_text()#名字放在class为name的a标签里面
print("昵称", user_name)
web_object['user_name'] = user_name
(4)获取时间
i = i.find("div",{'class':"card"})
itime = i.find("div", {'class': "from"})
uptime = itime.find("a").get_text().strip()
print("发布时间:", uptime)
web_object['date'] = uptime
(5)点赞、评论、转发的人数
cardact = i.find("div", {'class': "card-act"})
repost_num = cardact.findAll("li")[0].get_text().strip()
if repost_num =="转发":
repost_num = 0
print("转发人数:", repost_num)
web_object['repost_num'] = repost_num
comment_num = cardact.findAll("li")[1].get_text().strip()
if comment_num == "评论":
comment_num = 0
print("评论人数:", comment_num)
web_object['comment_num'] = comment_num
like_num = cardact.findAll("li")[2].get_text().strip()
if like_num == "赞":
like_num =0
print("点赞人数:", like_num)
web_object['like_num'] = like_num
(6)获取更多关于微博博主的信息
需要先从微博的搜索页面跳转到用户的界面,获取完信息后需要再跳转回来
# 控制跳转
user_link=i.find("a").get("href")
print("用户主页:", user_link)
web_object['user_link'] = user_link
# 拼出用户的主页链接user_url
user_url = "'" + "https:" + user_link+ "'"
js = "window.open(" + user_url + ");"
web.execute_script(js)
time.sleep(random.randint(2, 5))
# 切换到新窗口
# 获得打开的第一个窗口句柄
window_1 = web.current_window_handle
# 获得打开的所有的窗口句柄
windows = web.window_handles
# 切换到最新的窗口
for current_window in windows:
if current_window != window_1:
web.switch_to.window(current_window)
html = web.page_source
soup = bs(html, 'html.parser')
print("切换到用户主页")
(7)获取用户类型(红V,蓝V,黄V等)
同样的,先获取这个类型所在的网页标签,然后得到具体内容,如果没有红V,蓝V,黄V则程序执行异常,通过try语句抓取异常,将用户类型设置为普通用户
try:
typehtml = soup.find("div",{'class':"woo-avatar-main woo-avatar-hover ProfileHeader_avatar2_1gEyo"})
user_type = typehtml.find("span").get("title")
web_object['user_type'] = user_type
print("用户类型", user_type)
except AttributeError as e:
web_object['user_type'] = '普通用户'
print("用户类型:", '普通用户')
(8)获取用户性别
genderhtml = soup.find("div",{'class': "woo-box-flex woo-box-alignCenter ProfileHeader_h3_2nhjc"})
gender = genderhtml.find("span").get("title").strip()
print("用户性别:", gender)
web_object['gender'] = gender
(9)获取用户的粉丝和关注人数
fanshtml = soup.find("div",{'class': "woo-box-flex woo-box-alignCenter ProfileHeader_h4_gcwJi"})
followers = fanshtml.findAll("a")[0].get_text().strip('粉丝')
followers =followers[3:]
follow = fanshtml.findAll("a")[1].get_text().strip('关注')
follow = follow[3:]
print("粉丝数量:",followers,"关注人数:",follow)
web_object['follow'] = follow
web_object['followers'] = followers
(10)获取用户的ip以及年龄,
地址有两种,一种直接在用户界面写ip属地后面接ip地址,另一种是地点的小图标后接ip地址,所以需要先判断是不是能用第一种拿到ip,不行就用第二种,都不行就是没有ip
浏览器检查网页可以发现,展开后的一条条的信息标签都是一样的,不好区分,这里采用获取文本信息后进行关键词的监测来从中获取ip属地和出生日期

# 点击展开用户主页信息
button = web.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/div[2]/main/div/div/div[2]/div[1]/div[1]/div[3]/div/div/div[2]')
button.click()
html = web.page_source
soup = bs(html, 'html.parser')
ipflag = 0# 为1时表示已经获取ip信息
infohtml = soup.findAll("div",{'class': "woo-box-item-flex ProfileHeader_con3_Bg19p"})
for info in infohtml:
str1 = str(info.get_text()).strip()
print(str1)
try:
if (keywords_check('加入微博', str1)):#日期后面跟一个“加入微博”,排除
print("加入微博时间,不是生日")
else: # 正则匹配日期格式
result = re.findall("\d{4}[-|.|/]?\d{2}[-|.|/]?\d{2}", str1)
if(result):
print("生日", result[0])
age = age_calc(result[0], '2024-01-06')#网上搜的一个生日计算的方法
print(age)
web_object['age'] = age
except TypeError as e:
print('')
if (keywords_check('IP属地', str1)):# 检查用户主页是否有ip属地这种格式的ip
ipflag = 1 # 有的话标记为1,表示已经拿到ip
ip = str1[5:] # 将(ip属地:)五个字符去掉,保留后面的地址
print("地址", ip)
if ipflag == 0: #如果前面没找到ip属地,则找ip图标来判断
try:
iphtml = soup.find("div",{'class':"ProfileHeader_box3_2R7tq"})
ip = iphtml.find("i",{'class':"woo-font woo-font--proPlace"}).parent.parent.get_text()
print("ip:", ip)
except AttributeError as e:
print("该用户没有ip信息")
网上随便找的根据日期计算生日的方法
def age_calc(birth_date, end_date):
# 将日期转化为datetime类型
birth_date = datetime.strptime(birth_date, '%Y-%m-%d')
end_date = datetime.strptime(end_date, '%Y-%m-%d')
# 分别计算年月日
day_diff = end_date.day - birth_date.day
month_diff = end_date.month - birth_date.month
year_diff = end_date.year - birth_date.year
if day_diff >= 0:
if month_diff >= 0:
years_old = year_diff
else:
years_old = year_diff - 1
else:
if month_diff >= 1:
years_old = year_diff
else:
years_old = year_diff - 1
return years_old
检查关键词的方法,keywords是要找的关键词,text是全部文本
def keywords_check(keyswords, text): keyswords result = re.search(keyswords, text) return result
4、保存数据
# 保存数据
def save_data(web_data,filename):
fieldnames = ['mid', 'text', 'date', 'user_name', 'gender', 'follow', 'followers','age','ip','user_type','user_link','repost_num','comment_num','like_num']
with open(filename, mode='a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
# 判断表格内容是否为空,如果为空就添加表头
if not os.path.getsize(filename):
writer.writeheader() # 写入表头
writer.writerows([web_data])
如此一来,一个微博内容以及发布者的信息获取就完成了,我们保存数据后再次切换网页到搜索页面,在此之后就是继续对前文提到的微博列表list里面的下一个微博进行上述处理,文章3.1写到的for已经帮助我们进行了循环功能,所以这下面的代码放在for循环里面就可以了
save_data(web_object, filename)# 保存
web.close()
# 回到主页面
web.switch_to.window(web.window_handles[0])
5、搜索结果翻页
前面我们只实现了一页网页的数据,下面实现翻页
page_count = 50 # 总页数设置
for page in range(page_count):
print('开始获取第%d页的搜索结果'%(page+1))
temp =str(page+1)
url ='https://s.weibo.com/weibo?q=关键词&Refer=index&page=%s'%(temp)
filename = os.getcwd()+'/data/微博/搜索结果.csv' # 没有目录就新建一个目录
start_crawler(url, filename)
将以上内容串起来
下面的start_crawler函数就是爬虫的主体,也就是写
web.get(url)
print(“=开始了开始啦====”)
html = web.page_source
等等等上述代码
if __name__ == '__main__':
# 测试用的url链接
page_count = 50 # 总页数设置
for page in range(page_count):# for循环进行翻页
print('开始获取第%d页的搜索结果'%(page+1))
temp =str(page+1)
url ='https://s.weibo.com/weibo?q=关键词&Refer=index&page=%s'%(temp)
filename = os.getcwd()+'/data/关键词.csv' # 没有目录就先新建一个目录
start_crawler(url, filename)
6、微博的评论信息获取
这是另一个python文件了,这里用的评论链接获取的网页和前面的网页不同,是json格式的数据,解析数据时用到的方法不同,详情可以自行搜索
6.1先看主函数
read_mid读取目标微博的mid号列表,然后用mid拼成每条微博评论所在的链接url,通过start_crawler爬取每条微博的所有评论
if __name__ == '__main__':
# 测试用的url链接
filename = r"放你上面步骤爬取得到的的文件路径"
write_path = r"随意路径\微博评论.csv"
midlist = read_mid(filename)
count = 1
for i in midlist:
if count >9:
print("====================第%d篇微博==============="%count)
mid = i[3:]
url = 'https://m.weibo.cn/comments/hotflow?id=%s&mid=%s'%(mid,mid)
print(url)
start_crawler(url, write_path,i)# 也存一下评论属于哪一条微博
count = count+1
6.2 read_mid函数
def read_mid(filename):
data = pd.read_csv(filepath_or_buffer=filename, encoding="utf-8",converters={"mid":str})
return data['mid'][data['comment_num']>=10] # 获取评论数不少于10的微博mid
6.3 start_crawler函数
涉及到评论翻页的问题,评论翻页用max_id来标记(微博自己设置的),为0时翻页完毕
将获取的网页数据识别成json处理
def start_crawler(url,filename,mid):
comment_url = url
max_id = 1 # 评论翻页的位置
page = 1
while (max_id):
if max_id == 0:
break
elif max_id != 1:
url = comment_url+'&max_id='+str(max_id)
print(url)
print("======================第%d页===================="%page)
web.get(url)
time.sleep(random.randint(3, 6)) # 不要爬取太快哦,小心被关进小黑屋
html = web.page_source
soup = bs(html, 'lxml')
ss = soup.select('pre')[0]
res = json.loads(ss.text) # 转json格式
max_id = get_info(web,res,filename,mid) # 获取一页评论,并且返回max_id用于翻页
page = page+1
6.3 get_info 函数
不太想解释了,下次有空再解释吧
计算年龄的函数同上文
def get_info(web,res,filename,mid):
try :
datalist = res['data']['data']
except KeyError as e:
return
max_id = res['data']['max_id']
for i in datalist:
web_object = {}
web_object['mid'] = mid
print("\033[34m发表时间:\033[0m" + i['created_at'])
web_object['date'] = i['created_at']
print("\033[35m评论内容:\033[0m" + i['text'])
web_object['text'] = i['text']
print("\033[36m位置:\033[0m" + str(i['source'])[2:])
web_object['ip'] = str(i['source'])[2:]
print("\033[36m昵称:\033[0m" + i['user']['screen_name'])
web_object['user_name'] = i['user']['screen_name']
print("\033[31m个签:\033[0m" + i['user']['description'])
web_object['status'] = i['user']['description']
user_id = '%d' % (i['user']['id'])
print("\033[37mid号:\033[0m" + user_id)
web_object['user_id'] = user_id
user_link = "https://weibo.com/"+user_id+ '?refer_flag=1001030103_'
print("\033[36m用户主页:\033[0m" + user_link)
web_object['user_link'] = user_link
print("\033[32m性别:\033[0m" + i['user']['gender'])
web_object['gender'] = i['user']['gender']
user_follow_count = '%d' % (i['user']['follow_count'])
print("\033[31m关注人数:\033[0m" + user_follow_count)
web_object['follow'] = user_follow_count
user_followers_count = (i['user']['followers_count'])
print("\033[31m被关注人数:\033[0m" + user_followers_count)
web_object['followers'] = user_followers_count
# =========================================切换到用户主页的窗口
user_url = "'" + user_link + "'"
js = "window.open(" + user_url + ");"
web.execute_script(js)
time.sleep(random.randint(2, 5))
# 切换到新窗口
# 获得打开的第一个窗口句柄
window_1 = web.current_window_handle
# 获得打开的所有的窗口句柄
windows = web.window_handles
for current_window in windows:
if current_window != window_1:
web.switch_to.window(current_window)
html = web.page_source
soup = bs(html, 'html.parser')
print("切换到用户主页")
web.implicitly_wait(4)
try:
typehtml = soup.find("div", {'class': "woo-avatar-main woo-avatar-hover ProfileHeader_avatar2_1gEyo"})
user_type = typehtml.find("span").get("title")
web_object['user_type'] = user_type
print("用户类型:", user_type)
except AttributeError as e:
web_object['user_type'] = '普通用户'
print("用户类型:", '普通用户')
# ============================点击展开============================
button = web.find_element_by_xpath(
'//*[@id="app"]/div[2]/div[2]/div[2]/main/div/div/div[2]/div[1]/div[1]/div[3]/div/div/div[2]')
button.click()
html = web.page_source
soup = bs(html, 'html.parser') # woo-box-item-inlineBlock ProfileHeader_item3_1bUM2,woo-box-item-flex ProfileHeader_con3_Bg19p
infohtml = soup.findAll("div", {'class': "woo-box-item-flex ProfileHeader_con3_Bg19p"})
# print(infohtml)
for info in infohtml:
str1 = str(info.get_text()).strip()
# print(str1)
try:
if (keywords_check('加入微博', str1)):
print("加入微博时间,不是生日")
else:
result = re.findall("\d{4}-\d{2}-\d{2}", str1)
if (len(result) != 0):
try :
print("生日:", result[0])
age = age_calc(result[0], '2024-01-06')
print(age)
web_object['age'] = age
except ValueError as e:
print('')
except TypeError as e:
print('没有年龄信息')
# sys.exit() # 退出当前程序,但不重启shell
time.sleep(random.randint(2, 6))
web.close()
# 回到主页面
web.switch_to.window(web.window_handles[0])
save_data(web_object, filename)
print(max_id)
return max_id


