
最简单的Hadoop+Spark大数据集群搭建方法,看这一篇就够啦



最简单的 Hadoop+Spark 大数据集群搭建方法,看这一篇就够啦
前言:最近有小伙伴私信我,flink 软件安装在虚拟机上很简单,就是安装包解压即可,有没有 hadoop + spark 的安装文档呢?所以今天周六刚好不用上班,花了一天时间整理了一下自己现在使用集群的搭建过程,希望对各位小伙伴有帮助!
Tips:以下是集群搭建过程的记录啦,word 文档和搭建好了的集群,我后续会上传资源区啦,有需要的小伙伴后续可以在我的资源区下载哦!希望和大家一起进步,有啥不清楚滴地方可以一起交流! 这一次梳理搭建过程我觉得很有意义,熟悉了各类配置文件之间的关联,以及大数据组件之间的配置关系,很开心和大家分享此文,那就,继续加油吧!
(一)在VMware中创建Centos虚拟机
1. 环境准备
(1)Windows 11
(2)VMware WorkStation Pro 16
2. 实验步骤
(1)创建虚拟机向导,选择自定义(高级)

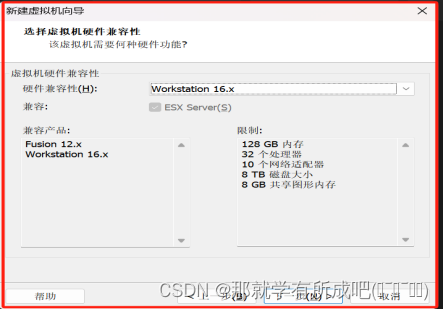
(2)选择虚拟机兼容性,选择Workstation 16.x
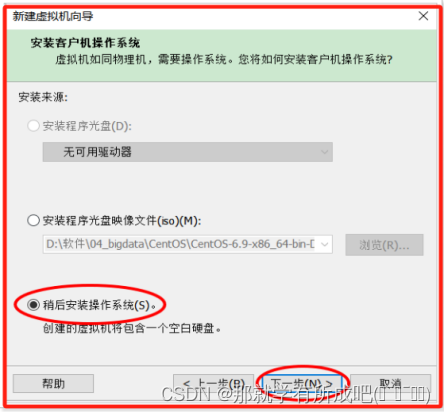
(3)选择稍后安装操作系统,因为待会可以使用自己下载的镜像文件
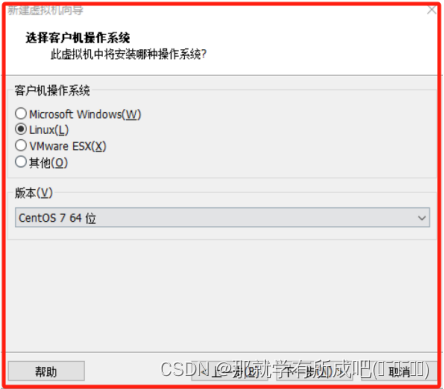
(4)选择客户机操作系统,肯定选择Linux
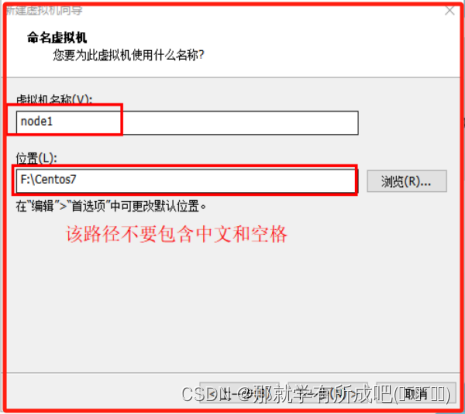
(5)命名虚拟机名称node1,并存放在除了c盘以外的文件夹下
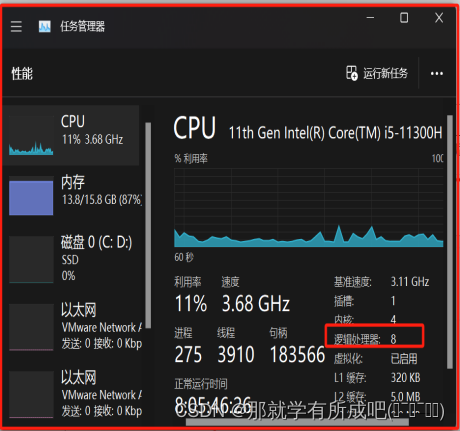
(6)处理器配置,因为我的电脑8个逻辑处理器,目前分配虚拟机使用4个
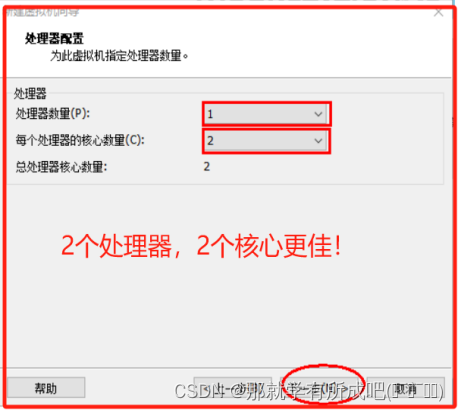
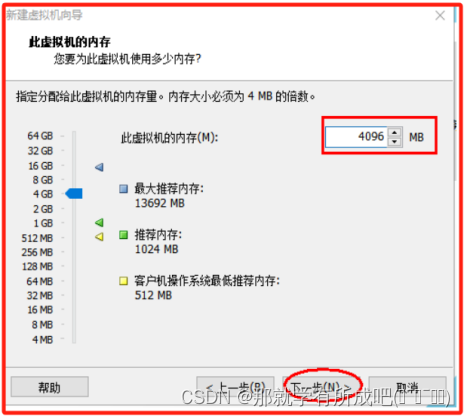
(7)虚拟机内存配置,因为我的电脑16G,目前分配首台虚拟机使用4G
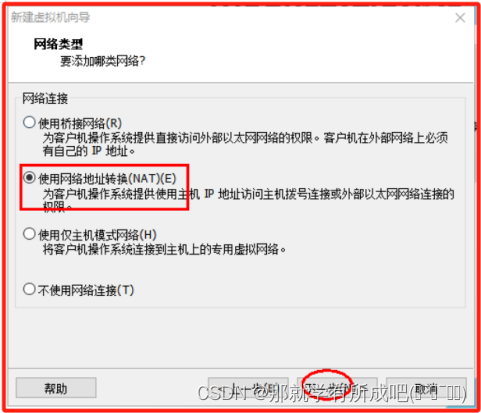
(8)配置网络类型,使用网络地址转换(NAT)(E)
(9)选择I/O控制器类型,使用LSI Logic(L)
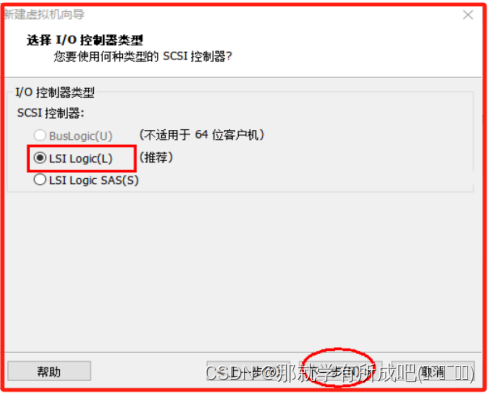
(10)选择磁盘类型,使用SCSI(S)
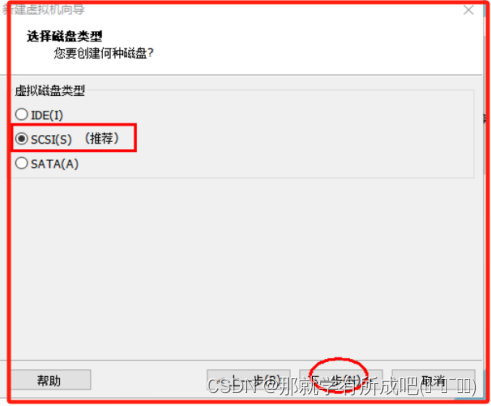
(11)选择磁盘,使用创建新虚拟磁盘
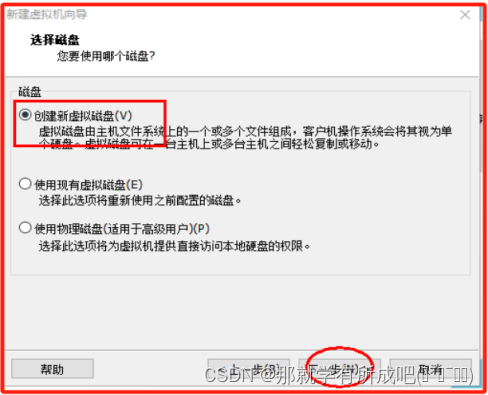
(12)指定磁盘容量,担心后面虚拟机内存不够,故选择60GB
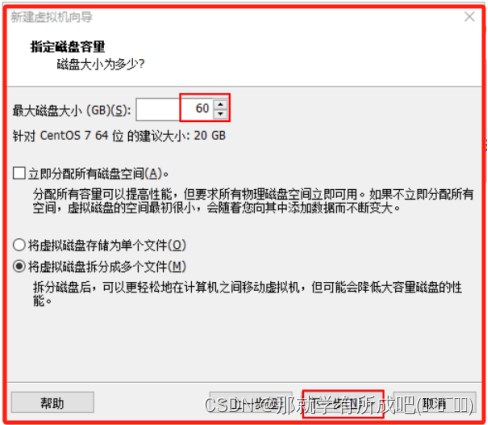
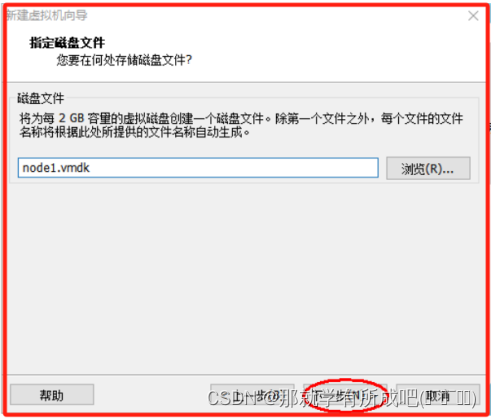
(13)指定磁盘文件,node1.vmdk
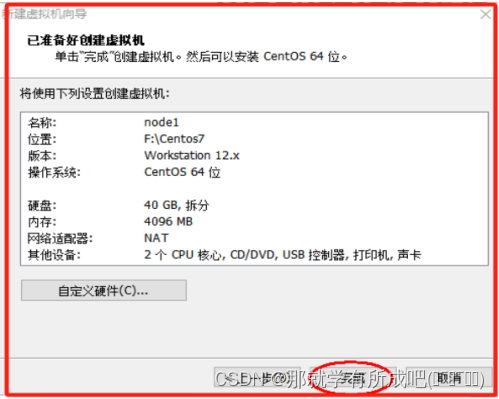
(14)虚拟机的模拟硬件已准备好
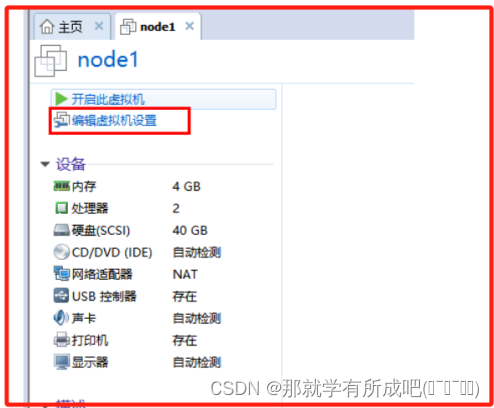
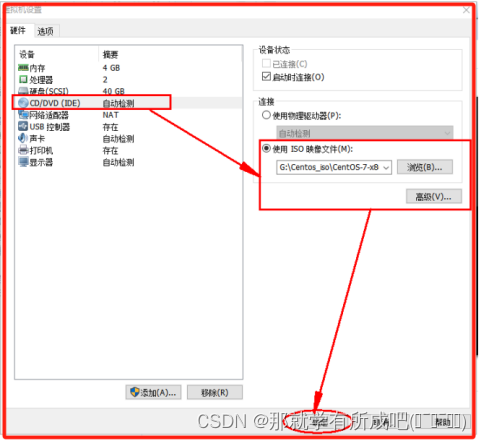
(15)关联Centos镜像文件
(16)安装虚拟机镜像,启动后一路回车
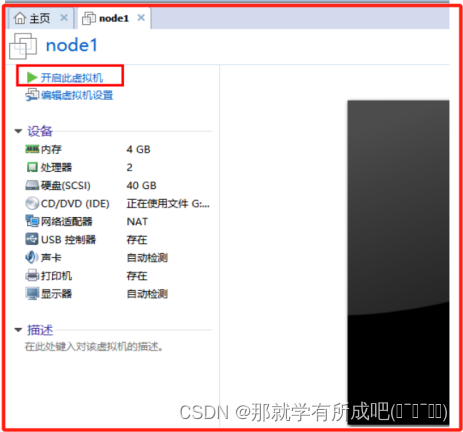
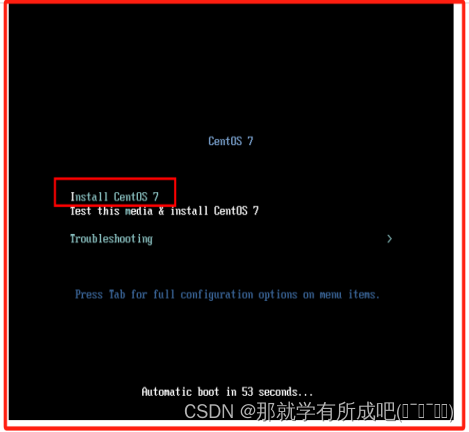
(17)按下ESC键跳过镜像检测

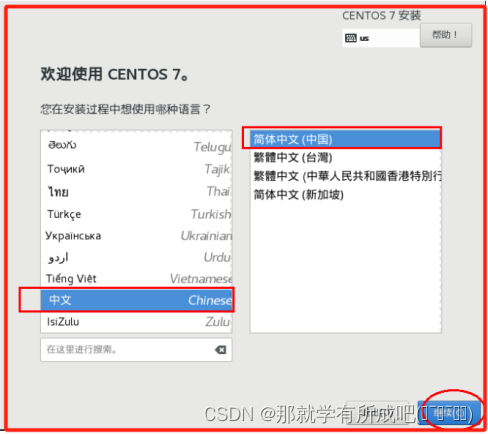
(18)选择中文版安装,或者英文版安装都可以
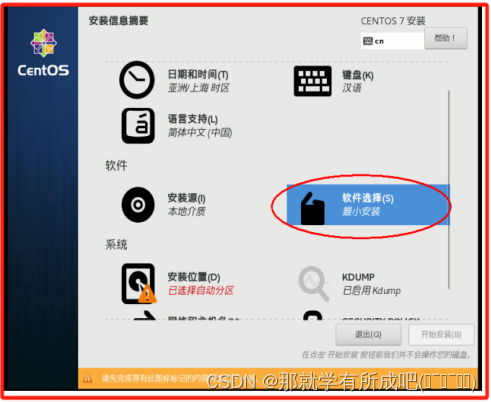
(19)想要节约内存,可以选择最小版安装
(20)软件安装选择基本网页服务器
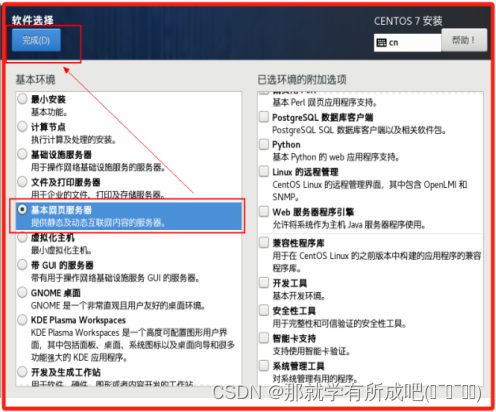
(21)进行安装位置配置
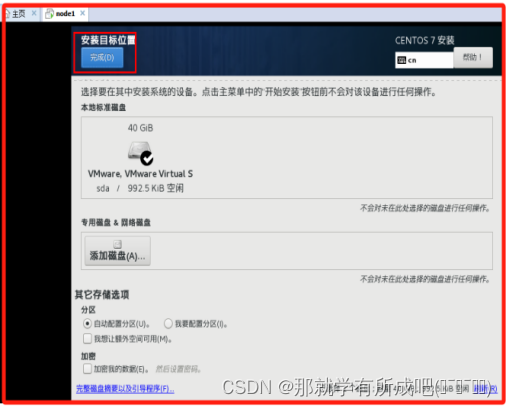
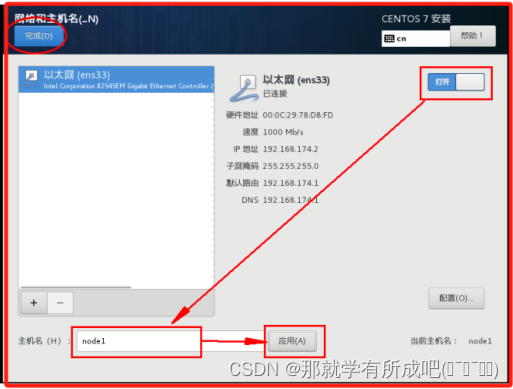
(22)进行网络和主机名配置,主机名为node1
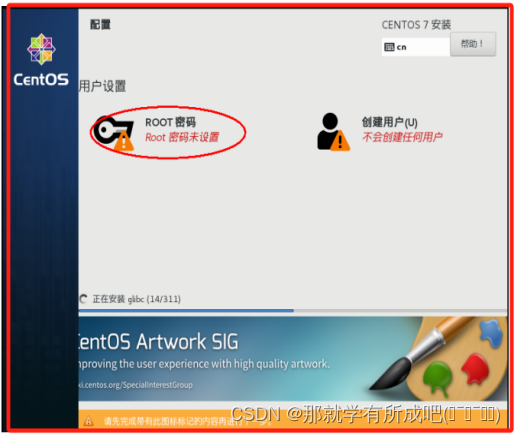
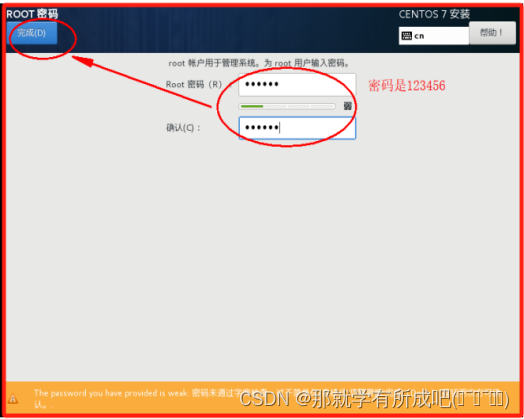
(23)进行虚拟机密码配置
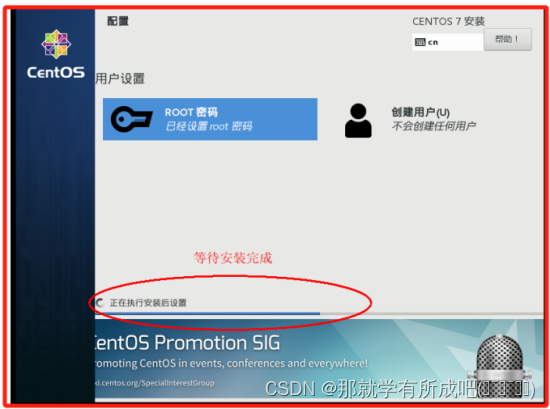
(24)进行虚拟机正式安装

(25)进行虚拟机重启
(26)进入虚拟机登录界面,输入用户名、密码
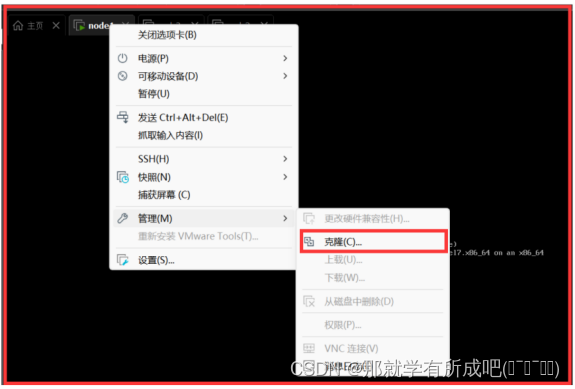
(27)克隆另外两台虚拟机node2和node3
(二)虚拟机基础环境配置
1.修改好虚拟机主机名
vi /etc/hostname,将其改为node1,另外两台修改为node2和node3



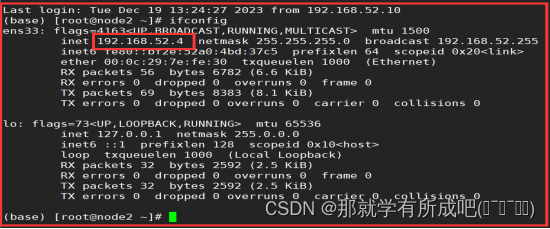
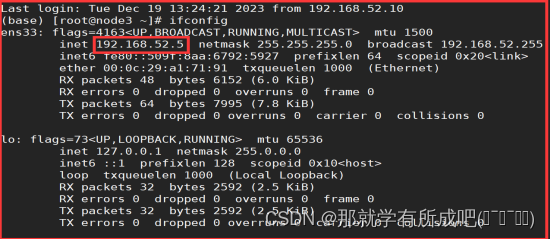
2.查看虚拟机IP地址
ifconfig,IP地址:node1是192.168.52.3,node2是192.168.52.4,node3是192.168.52.5

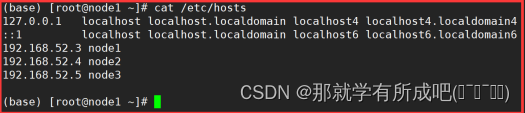
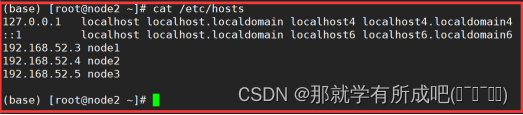
3.修改主机名和IP的映射关系
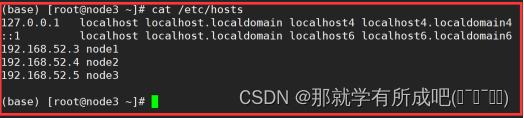
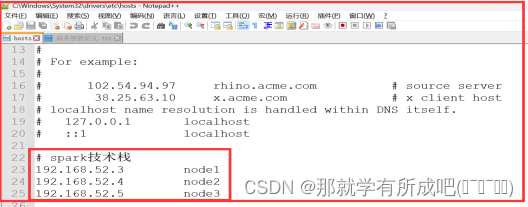
vim /etc/hosts,输入: 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.52.3 node1 192.168.52.4 node2 192.168.52.5 node3 与此同时,同步修改windows的C:\Windows\System32\drivers\etc\hosts文件
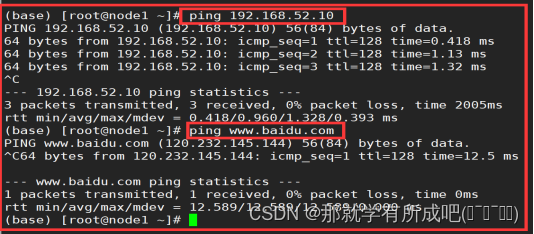
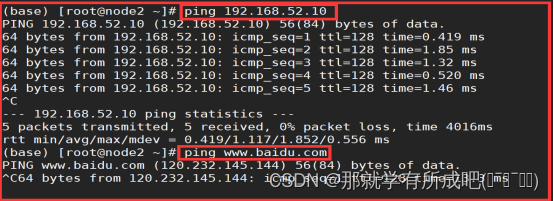
4.用主机名ping通:宿主机IP和外网IP
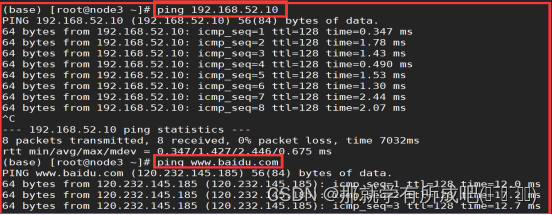
ping 192.168.52.10 ping www.baidu.com
5.关闭虚拟机防火墙和windows防火墙
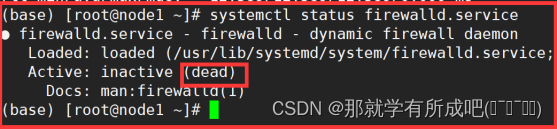
(1)关闭虚拟机防火墙
#查看/关闭/禁止 防火墙 systemctl status /stop / disable firewalld.service

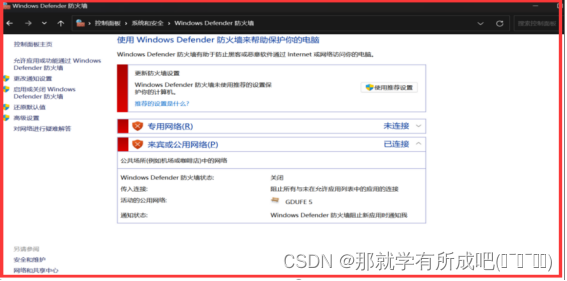
(2)关闭windows防火墙
(三)三台机器安装jdk1.8
1.上传jdk
rz jdk-8u65-linux-x64.tar.gz,需要安装rz命令(yum install -y lrzsz)
2.解压jdk
tar -zxvf jdk-8u65-linux-x64.tar.gz -C /export/server 其中,tar命令参数解释如下: -z:使用解压方式 -x:解压gz的文件 -v:显示解压信息 -f:带解压文件名 -C:指定解压路径
3.将java添加到环境变量中
vim /etc/profile #在文件最后添加 #java_home export JAVA_HOME=/export/server/jdk1.8.0_65 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
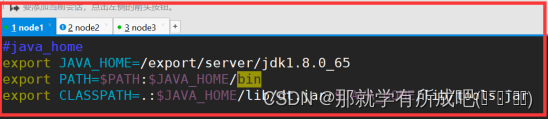
(三台机器都要配置环境变量)
4.刷新配置文件
source /etc/profile 三台机器都需要刷新环境变量
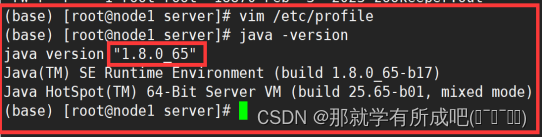
5.查看jdk安装情况
java -version
(四)重新编译hadoop源码包
1.官方网站下载源码包
https://archive.apache.org/dist/
2.下载对应版本编译包
https://archive.apache.org/dist/hadoop/common/ hadoop-3.3.0-src.tar.gz //source 源码包 hadoop-3.3.0.tar.gz //官方编译后安装包
3.进行hadoop源码包编译
在源码的根目录下有编译相关的文件BUILDING.txt 指导如何编译。 使用maven进行编译 联网jar.
4.编译环境进行目录创建
mkdir -p /export/server
5.安装编译相关的依赖
yum install gcc gcc-c++ make autoconf automake libtool curl lzo-devel zlib-devel openssl openssl-devel ncurses-devel snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst zlib -y yum install -y doxygen cyrus-sasl* saslwrapper-devel*
6.手动安装cmake
#yum卸载已安装cmake 版本低 yum erase cmake #解压 tar zxvf CMake-3.19.4.tar.gz #编译安装 cd /export/server/CMake-3.19.4 ./configure make && make install #验证 [root@node1 ~]# cmake -version cmake version 3.19.4 #如果没有正确显示版本 请断开SSH连接 重写登录
7.手动安装snappy
#卸载已经安装的 rm -rf /usr/local/lib/libsnappy* rm -rf /lib64/libsnappy* #上传解压 tar zxvf snappy-1.1.3.tar.gz #编译安装 cd /export/server/snappy-1.1.3 ./configure make && make install #验证是否安装 [root@node1 snappy-1.1.3]# ls -lh /usr/local/lib |grep snappy -rw-r--r-- 1 root root 511K Nov 4 17:13 libsnappy.a -rwxr-xr-x 1 root root 955 Nov 4 17:13 libsnappy.la lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so -> libsnappy.so.1.3.0 lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so.1 -> libsnappy.so.1.3.0 -rwxr-xr-x 1 root root 253K Nov 4 17:13 libsnappy.so.1.3.0
8.安装maven
#解压安装包
tar zxvf apache-maven-3.5.4-bin.tar.gz
#配置环境变量
vim /etc/profile
export MAVEN_HOME=/export/server/apache-maven-3.5.4
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=:$MAVEN_HOME/bin:$PATH
source /etc/profile
#验证是否安装成功
[root@node1 ~]# mvn -v
Apache Maven 3.5.4
#添加maven 阿里云仓库地址 加快国内编译速度
vim /export/server/apache-maven-3.5.4/conf/settings.xml
alimaven
aliyun maven
http://maven.aliyun.com/nexus/content/groups/public/
central
9.安装ProtocolBuffer 3.7.1
#卸载之前版本的protobuf #解压 tar zxvf protobuf-3.7.1.tar.gz #编译安装 cd /export/server/protobuf-3.7.1 ./autogen.sh ./configure make && make install #验证是否安装成功 [root@node1 protobuf-3.7.1]# protoc --version libprotoc 3.7.1
10.编译hadoop
#上传解压源码包 tar zxvf hadoop-3.3.0-src.tar.gz #编译 cd /root/hadoop-3.3.0-src mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib #参数说明: Pdist,native :把重新编译生成的hadoop动态库; DskipTests :跳过测试 Dtar :最后把文件以tar打包 Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】 Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径
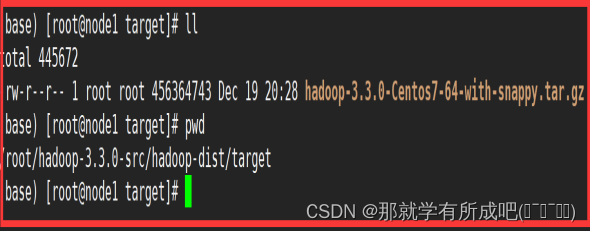
11.编译后安装包路径
[root@node1]# cd /root/hadoop-3.3.0-src/hadoop-dist/target [root@node1]# ll 发现存在hadoop已经编译好的安装压缩包: Hadoop-3.3.0-Centos7-64-with-snappy.tar.gz 这个包就可以用来安装hadoop3.3.0了。
(五)三台机器安装zookeeper
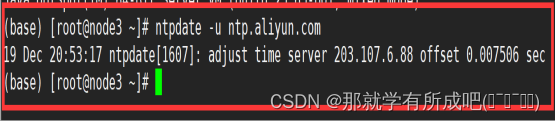
1.集群时间同步
# 三台虚拟机同步阿里云时间 ntpdate -u ntp.aliyun.com


2.集群SSH免密登录
# 分别在node1,node2,node3的home目录下执行 #生成ssh连接的公私钥 ssh-keygen -t rsa ==========================然后一直回车============================== # 罗列隐藏文件 ls -al

=========================三台机器均需要执行======================== #将node1的免密公钥拷贝到自身服务器和node2与node3的服务器上,实现node1免密登录自身服务器node2与node3服务器 #将公钥拷贝到node1机器上 ssh-copy-id node1 #将公钥拷贝到node2机器上 ssh-copy-id node2 #将公钥拷贝到node3机器上 ssh-copy-id node3 # 测试结点之间是否可以免密登录 在node1上测试:ssh node2,ssh node3 在node2上测试:ssh node1,ssh node3 在node3上测试:ssh node1,ssh node2
3.准备zookeeper的安装包
zookeeper-3.4.6.tar.gz
4.上传安装包并重命名
cd /export/server tar zxvf zookeeper-3.4.6.tar.gz mv zookeeper-3.4.6/ zookeeper
5.修改配置文件zoo.cfg
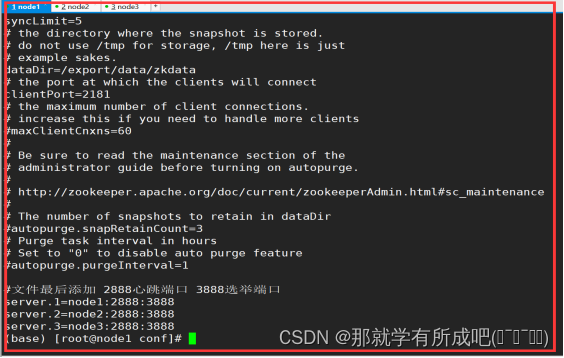
#zk默认加载的配置文件是zoo.cfg 因此需要针对模板进行修改。保证名字正确。 cd zookeeper/conf mv zoo_sample.cfg zoo.cfg vi zoo.cfg #修改 dataDir=/export/data/zkdata #文件最后添加 2888心跳端口 3888选举端口 server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:3888
6.修改配置文件myid
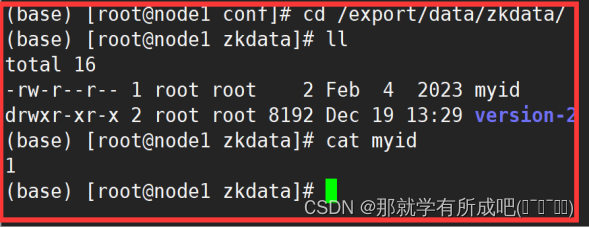
#在每台机器的dataDir指定的目录下创建一个文件 名字叫做myid #myid里面的数字就是该台机器上server编号。server.N N的数字就是编号 [root@node1 conf]# mkdir -p /export/data/zkdata [root@node1 conf]# echo 1 >/export/data/zkdata/myid
7.把安装包同步到其他节点上
cd /export/server scp -r zookeeper/ node2:$PWD scp -r zookeeper/ node3:$PWD
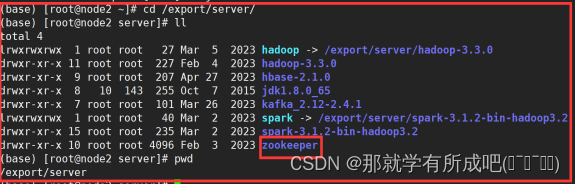

8.创建其他机器上myid和datadir目录
[root@node2 ~]# mkdir -p /export/data/zkdata [root@node2 ~]# echo 2 > /export/data/zkdata/myid [root@node3 ~]# mkdir -p /export/data/zkdata [root@node3 ~]# echo 3 > /export/data/zkdata/myid


9.zk集群的启动
# 单个结点启动集群 #在哪个目录执行启动命令 默认启动日志就生成当前路径下 叫做zookeeper.out /export/server/zookeeper/bin/zkServer.sh start|stop|status #3台机器启动完毕之后 可以使用status查看角色是否正常。 #还可以使用jps命令查看zk进程是否启动。 [root@node3 ~]# jps 2034 Jps 1980 QuorumPeerMain #看我,我就是zk的java进程
10.封装脚本启动集群
(1)一键启动
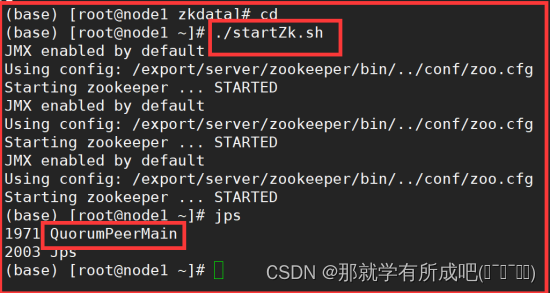
[root@node1 ~]# vim startZk.sh
#!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "source /etc/profile;/export/server/zookeeper-3/bin/zkServer.sh start"
done
# 赋予脚本用户执行权限 [root@node1 ~]# chmod u+x startZk.sh
一键启动演示:
(2)一键关闭
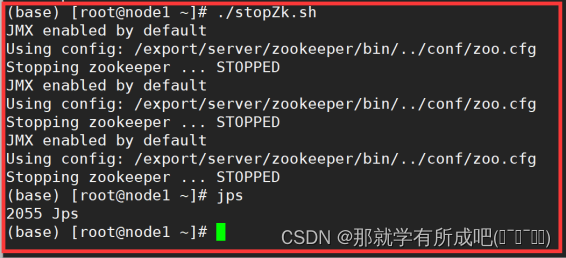
[root@node1 ~]# vim stopZk.sh
#!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "/export/server/zookeeper-3.4.6/bin/zkServer.sh stop"
Done
# 赋予脚本用户执行权限 [root@node1 ~]# chmod u+x stopZk.sh
一键关闭演示:
(六)三台机器安装Hadoop
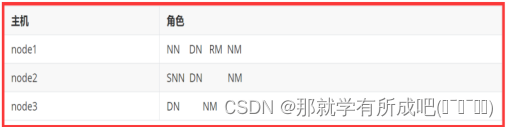
1.hadoop集群规划
2.准备hadoop安装包
hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
3.上传Hadoop安装包到node1 /export/server
cd /export/server rz hadoop-3.3.0-Centos7-64-with-snappy.tar.gz tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
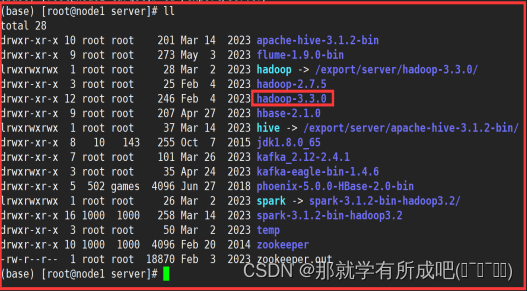
4.修改配置文件hadoop-env.sh
export JAVA_HOME=/export/server/jdk1.8.0_65 #文件最后添加 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
5.修改配置文件core-site.xml
fs.defaultFS
hdfs://node1:8020
hadoop.tmp.dir
/export/data/hadoop-3.3.0
hadoop.http.staticuser.user
root
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
6.修改配置文件hdfs-site.xml
dfs.namenode.secondary.http-address
node2:9868
7.修改配置文件mapre-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
node1:10020
mapreduce.jobhistory.webapp.address
node1:19888
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
8.修改配置文件yarn-site.xml
yarn.resourcemanager.hostname
node1
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
yarn.log-aggregation-enable
true
yarn.log.server.url
http://node1:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
9.修改文件workers
node1 node2 node3
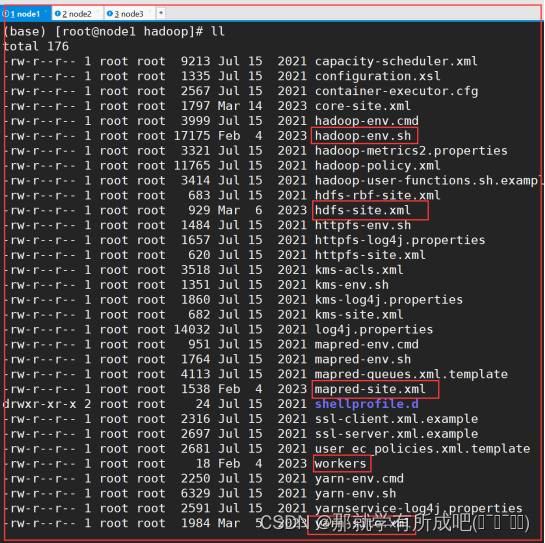
10.分发同步hadoop安装包
cd /export/server scp -r hadoop-3.3.0 root@node2:$PWD scp -r hadoop-3.3.0 root@node3:$PWD
11.三台机器均配置环境变量
vim /etc/proflie export HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile
12.集群首次格式化
(首次启动)格式化namenode hdfs namenode -format
13.一键启动hadoop集群
cd /export/server/hadoop-3.3.0/sbin ./start-all.sh
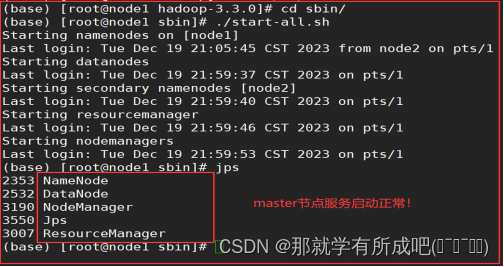
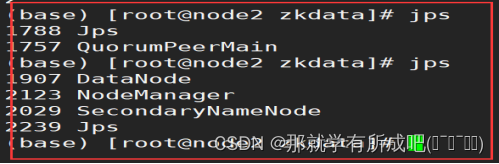
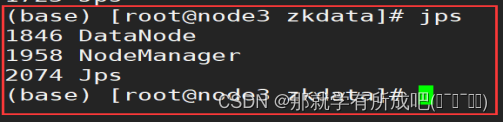
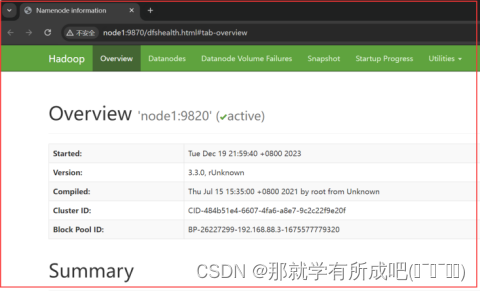
14.登录hdfs的UI界面node1:9870
15.一键关闭hadoop集群
cd /export/server/hadoop-3.3.0/sbin ./stop-all.sh
(七)三台机器安装MySQL
1.准备mysql安装包
mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar
2.卸载Centos7自带的mariadb
[root@node1 ~]# rpm -qa|grep mariadb mariadb-libs-5.5.64-1.el7.x86_64 [root@node1 ~]# rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps [root@node1 ~]# rpm -qa|grep mariadb [root@node1 ~]#
3.建立存储文件夹,上传解压安装包
mkdir /export/software/mysql #上传mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar 到上述文件夹下 解压 tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar
4.执行安装
#执行安装 yum -y install libaio [root@node1 mysql]# rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm warning: mysql-community-common-5.7.29-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-common-5.7.29-1.e################################# [ 25%] 2:mysql-community-libs-5.7.29-1.el7################################# [ 50%] 3:mysql-community-client-5.7.29-1.e################################# [ 75%] 4:mysql-community-server-5.7.29-1.e################ ( 49%)
5.mysql初始化设置
#初始化 mysqld --initialize #更改所属组 chown mysql:mysql /var/lib/mysql -R #启动mysql systemctl start mysqld.service #查看生成的临时root密码 cat /var/log/mysqld.log [Note] A temporary password is generated for root@localhost: o+TU+KDOm004
6.设置mysql密码
[root@node1 ~]# mysql -u root -p Enter password: #这里输入在日志中生成的临时密码 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.29 Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> #更新root密码 设置为hadoop mysql> alter user user() identified by "hadoop"; Query OK, 0 rows affected (0.00 sec)
7.授权mysql远程登录
#授权 mysql> use mysql; mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION; mysql> FLUSH PRIVILEGES; #mysql的启动和关闭 状态查看 (这几个命令必须记住) systemctl stop mysqld systemctl status mysqld systemctl start mysqld
8.授权mysql开机自启动
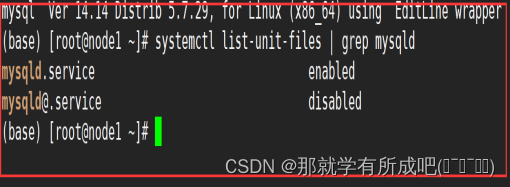
#建议设置为开机自启动服务 [root@node1 ~]# systemctl enable mysqld Created symlink from /etc/systemd/system/multi-user.target.wants/mysqld.service to /usr/lib/systemd/system/mysqld.service. #查看是否已经设置自启动成功 [root@node1 ~]# systemctl list-unit-files | grep mysqld mysqld.service enabled
9.其他2台机器也安装mysql
node1,node2,node3 均按照以上步骤安装mysql软件。
(八)主节点机器安装Hive
1.准备Hive安装包
apache-hive-3.1.2-bin.tar.gz
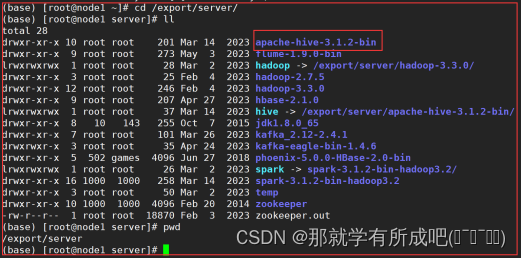
2.上传解压Hive安装包
tar zxvf apache-hive-3.1.2-bin.tar.gz -C /export/server
3.解决Hive与Hadoop之间guava版本差异
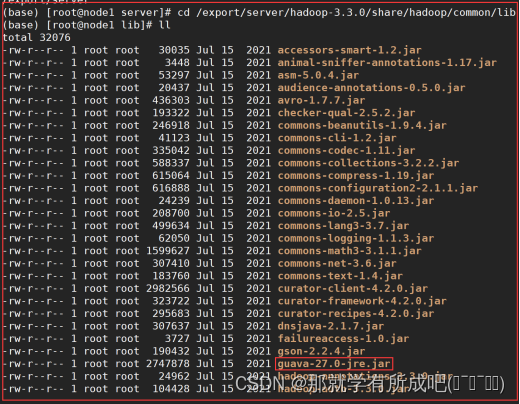
cd /export/server/apache-hive-3.1.2-bin/ rm -rf lib/guava-19.0.jar cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
4.修改配置文件hive-env.sh
cd /export/server/apache-hive-3.1.2-bin/conf mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/export/server/hadoop-3.3.0 export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib
5.修改配置文件hive-site.xml
vim hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
hadoop
hive.server2.thrift.bind.host
node1
hive.metastore.uris
thrift://node1:9083
hive.metastore.event.db.notification.api.auth
false
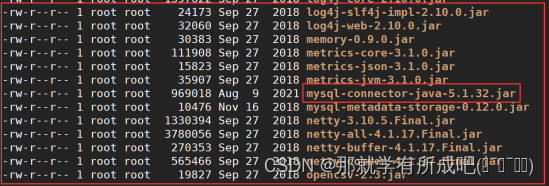
6.上传mysql jdbc 驱动包到hive安装包的lib目录下
mysql-connector-java-5.1.32.jar
7.初始化元数据metadata
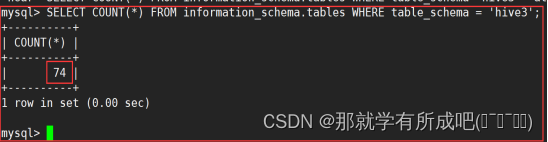
cd /export/server/apache-hive-3.1.2-bin/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表 # node1中进入mysql mysql -u用户名 -p密码 # 查看mysql的hive3数据库下面有多少张表 SELECT COUNT(*) FROM information_schema.tables WHERE table_schema = 'hive3'; # 退出mysql是`exit;`
8.在hdfs上创建hive的存储目录
# 创建临时文件目录和hive数据表存储目录 hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse # 赋予两个目录用户组写的权限 hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse
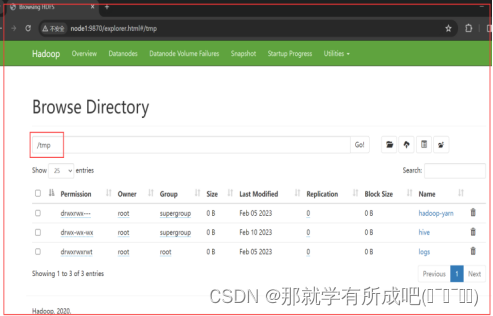
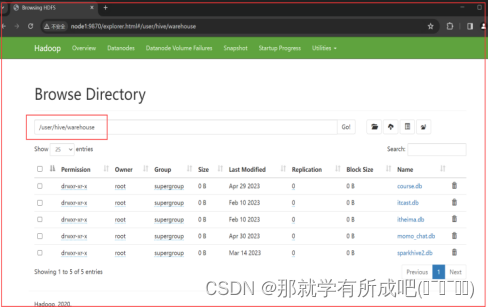

9.本集群选择node3作为beeline客户端
# 拷贝node1上的hive安装包到node3上 scp -r /export/server/apache-hive-3.1.2-bin/ node3:/export/server/
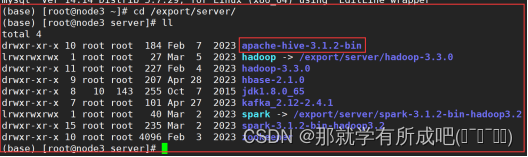
10.启动hive的metastore服务(推荐后台启动)
# 首先需要启动hadoop集群服务和zookeeper服务 # hive的metastore服务前台启动 关闭ctrl+c /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore #前台启动开启debug日志 /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console ==================后台启动 进程挂起 关闭使用jps+ kill -9================== nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
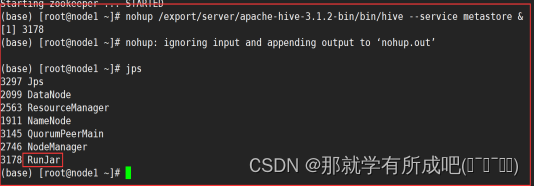
11.启动hive的hiveserver2服务(推荐后台启动)
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 & #注意 启动hiveserver2需要一定的时间 不要启动之后立即beeline连接 可能连接不上
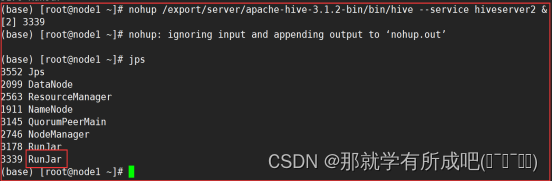
12.在node3上访问hive的beeline客户端
/export/server/apache-hive-3.1.2-bin/bin/beeline

beeline> ! connect jdbc:hive2://node1:10000 beeline> root beeline> 直接回车
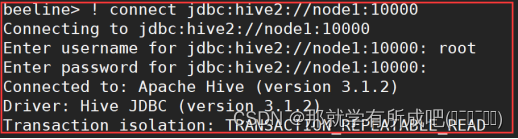
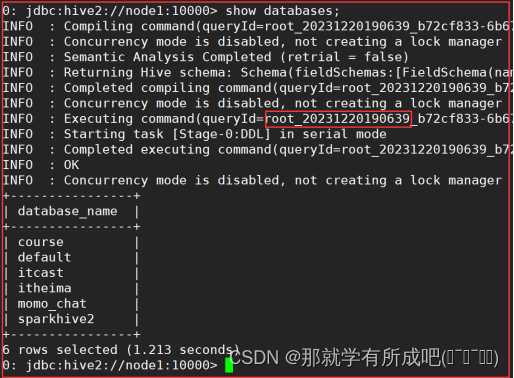
# 展示hive中的数据库 show databases; # 退出beeline客户端 命令:!q
(九)三台机器安装Anaconda
1.准备linux版本的Anaconda安装文件
Python3.8.8版本:Anaconda3-2021.05-Linux-x86_64.sh
2.执行linux版本的Anaconda安装文件
# 切换到下载目录 cd bash Anaconda3-2021.05-Linux-x86_64.sh # 之后一路enter回车即可安装完毕

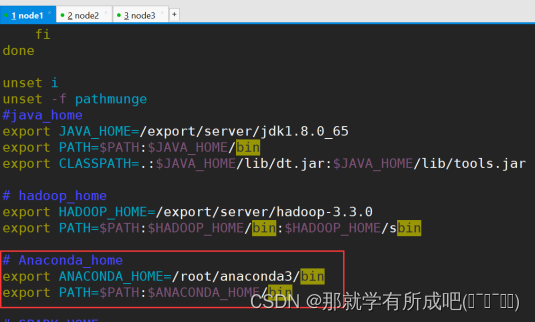
3.配置环境变量
vim /etc/profile ##增加如下配置 export ANACONDA_HOME=/root/anaconda3/bin export PATH=$PATH:$ANACONDA_HOME/bin # 刷新环境变量 source /etc/profile # 断开xshell重新连接
4.检测安装效果
# 输入python查看Python版本 python
5.conda命令详情
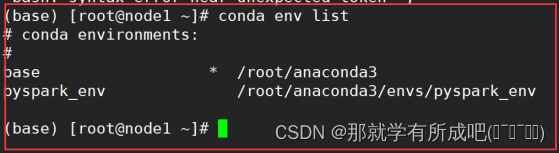
conda install 包名 pip install 包名 conda uninstall 包名 pip uninstall 包名 conda install -U 包名 pip install -U 包名 # 设置国内下载镜像 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set show_channel_urls yes # 环境管理 conda env list conda create py_env python=3.8.8 #创建python3.8.8环境或3.8以上版本,否则异常 activate py_env #激活环境 deactivate py_env #退出环境 source activate 可以进入conda环境 source deactivate 可以退出conda环境
(十)三台机器安装Spark
1.准备与hadoop兼容的spark安装包
spark-3.1.2-bin-hadoop3.2.tgz
2.上传node1与解压spark安装包
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server/
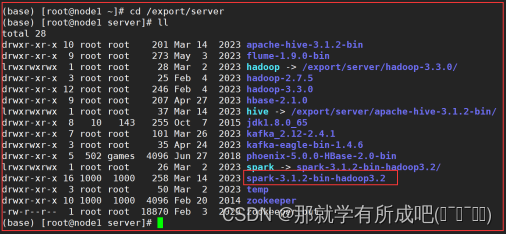
3.修改文件夹权限
# 目录下所有文件和子目录的所有者(owner)都更改为 root 用户 chown -R root /export/server/spark-3.1.2-bin-hadoop3.2 # 目录下所有文件和子目录的所属群组(group)都更改为 root 组 chgrp -R root /export/server/spark-3.1.2-bin-hadoop3.2
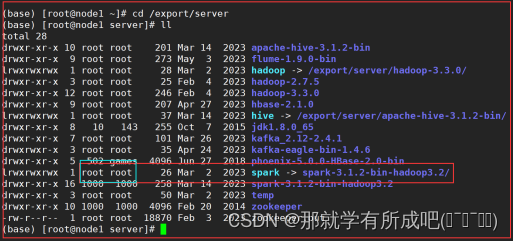
4.改名和创建软链接,方便后期升级
ln -s /export/server/spark-3.1.2-bin-hadoop3.2 /export/server/spark

5.查看目录结构,里面的文件夹含义
bin 可执行脚本 conf 配置文件 data 示例程序使用数据 examples 示例程序 jars 依赖 jar 包 python pythonAPI sbin 集群管理命令 yarn 整合yarn需要的东东
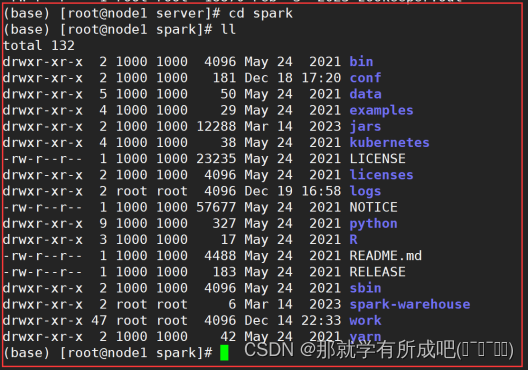
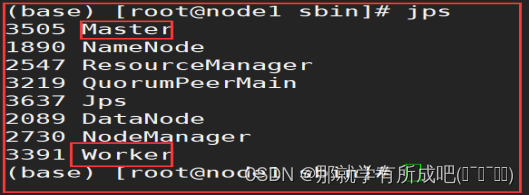
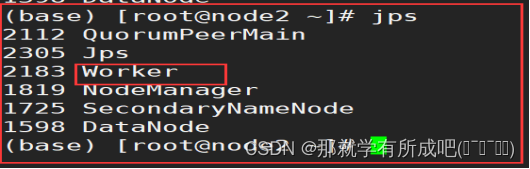
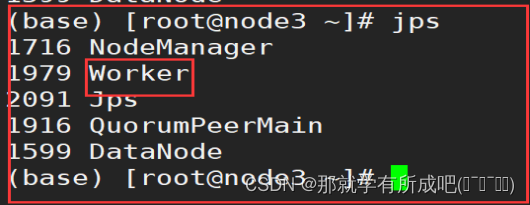
6.三台机器安装完毕后,在node1测试集群启动
/export/server/spark/sbin/start-all.sh
7.在node1测试本地启动spark-shell——scale交互式
# 本地模式 /export/server/spark/bin/spark-shell --master local[4] # standlone模式 /export/server/spark/bin/spark-shell --master spark://node1:7077 # HA模式 /export/server/spark/bin/spark-shell --master spark://node1:7077,node2:7077 # 退出模式 命令:`:q`
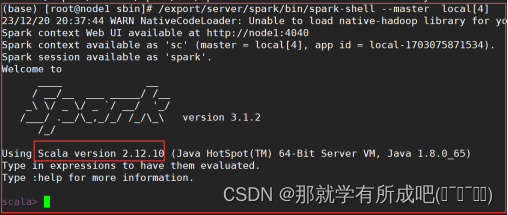
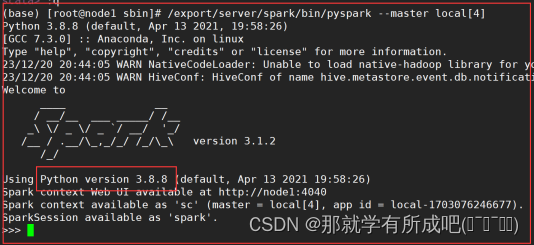
8.在node1测试本地启动pyspark——python交互式
# 本地模式 /export/server/spark/bin/pyspark --master local[4] # standlone模式 /export/server/spark/bin/pyspark --master spark://node1:7077 # HA模式 /export/server/spark/bin/pyspark --master spark://node1:7077,node2:7077 # 退出模式 命令:`exit()`
(十一)node1安装IDEA
1.准备idea安装包
idealU-2023.2.tar.gz
2.解压idea安装包
# 我在local路径下新建了文件夹idea,用来存放解压后的文件(新建文件夹命令mkdir) tar -zxvf idealU-2023.2.tar.gz -C /usr/local/idea
3.配置环境变量
vim ~/.bashrc
export IDEA_HOME=/usr/local/idea/idea-IU-232.8660.185/
export PATH=${IDEA_HOME}/bin:$PATH
4.重启环境变量
source ~/.bashrc
5.打开idea
ieda.sh,启动后安装
(十二)集群软件版本及部署架构
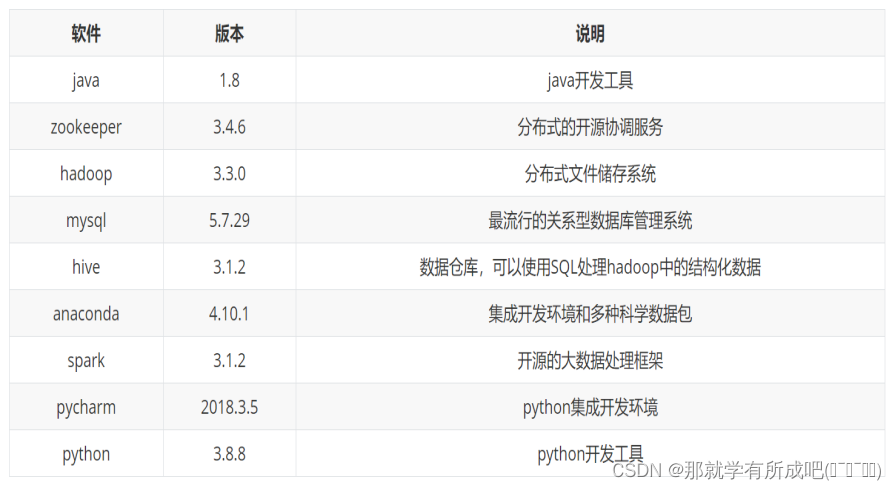
1.集群软件版本
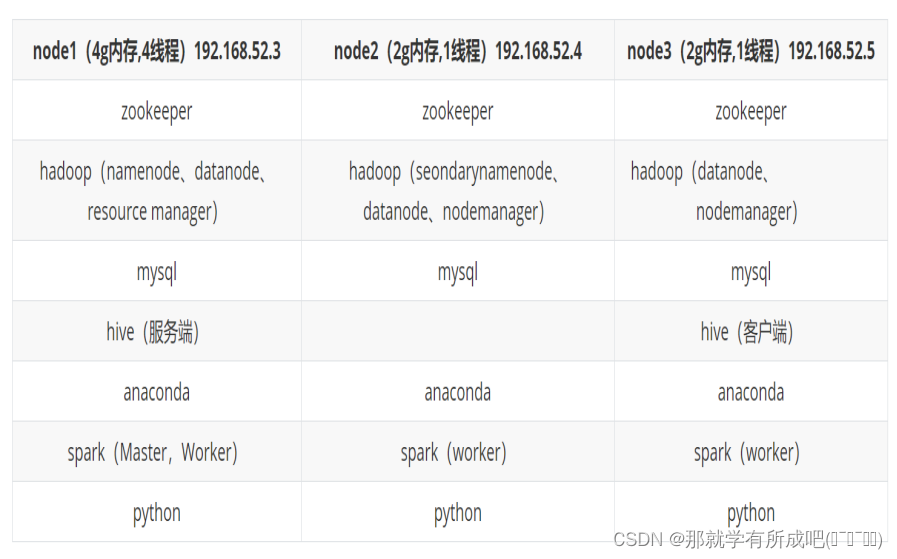
2.集群部署架构
3.集群镜像环境
使用apache软件(虚拟机安装镜像:CentOS-7-x86_64-Minimal-1908)



