
python DataFrame数据合并 merge()、concat()方法




相比方法①,区别在于,如图,方法②合并出的数据中有重复列。
重要参数
pd.merge(right,how=‘inner’, on=“None”, left_on=“None”, right_on=“None”, left_index=False, right_index=False )
| 参数 | 描述 |
| — | — |
| left | 左表,合并对象,DataFrame或Series |
| right | 右表,合并对象,DataFrame或Series |
| how | 合并方式,可以是left(左合并), right(右合并), outer(外合并), inner(内合并) |
| on | 基准列 的列名 |
| left_on | 左表基准列列名 |
| right_on | 右表基准列列名 |
| left_index | 左列是否以index为基准,默认False,否 |
| right_index | 右列是否以index为基准,默认False,否 |
其中,left_index与right_index 不能与 on 同时指定。
合并方式 left right outer inner
准备数据‘
新准备一组数据:
import pandas as pd
df1 = pd.DataFrame({‘id’: [‘001’, ‘002’, ‘003’],
‘num1’: [120, 101, 104],
‘num2’: [110, 102, 121],
‘num3’: [105, 120, 113]})
df2 = pd.DataFrame({‘id’: [‘001’, ‘004’, ‘003’],
‘num4’: [80, 86, 79]})
print(df1)
print(“=======================================”)
print(df2)
print(“=======================================”)

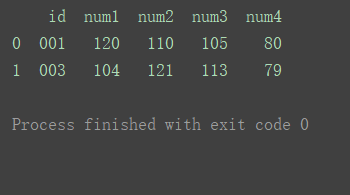
inner(默认)
使用来自两个数据集的键的交集
df_merge = pd.merge(df1, df2, on=‘id’)
print(df_merge)
outer
使用来自两个数据集的键的并集
df_merge = pd.merge(df1, df2, on=‘id’, how=“outer”)
print(df_merge)

left
使用来自左数据集的键
df_merge = pd.merge(df1, df2, on=‘id’, how=‘left’)
print(df_merge)

right
使用来自右数据集的键
df_merge = pd.merge(df1, df2, on=‘id’, how=‘right’)
print(df_merge)
2.多对一合并
import pandas as pd
df1 = pd.DataFrame({‘id’: [‘001’, ‘002’, ‘003’],
‘num1’: [120, 101, 104],
‘num2’: [110, 102, 121],
‘num3’: [105, 120, 113]})
df2 = pd.DataFrame({‘id’: [‘001’, ‘001’, ‘003’],
‘num4’: [80, 86, 79]})
print(df1)
print(“=======================================”)
print(df2)
print(“=======================================”)

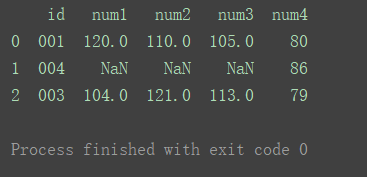
如图,df2中有重复id1的数据。
合并
df_merge = pd.merge(df1, df2, on=‘id’)
print(df_merge)
合并结果如图所示:

依然按照默认的Inner方式,使用来自两个数据集的键的交集。且重复的键的行会在合并结果中体现为多行。
3.多对多合并
如图表1和表2中都存在多行id重复的。
import pandas as pd
df1 = pd.DataFrame({‘id’: [‘001’, ‘002’, ‘002’, ‘002’, ‘003’],
‘num1’: [120, 101, 104, 114, 123],
‘num2’: [110, 102, 121, 113, 126],
‘num3’: [105, 120, 113, 124, 128]})
df2 = pd.DataFrame({‘id’: [‘001’, ‘001’, ‘002’, ‘003’, ‘001’],
‘num4’: [80, 86, 79, 88, 93]})
print(df1)
print(“=======================================”)
print(df2)
print(“=======================================”)

df_merge = pd.merge(df1, df2, on=‘id’)
print(df_merge)

concat()
==============================================================================
pd.concat(objs, axis=0, join=‘outer’, ignore_index:bool=False,keys=None,levels=None,names=None, verify_integrity:bool=False,sort:bool=False,copy:bool=True)
| 参数 | 描述 |
| — | — |
| objs | Series,DataFrame或Panel对象的序列或映射 |
| axis | 默认为0,表示列。如果为1则表示行。 |
| join | 默认为"outer",也可以为"inner" |
| ignore_index | 默认为False,表示保留索引(不忽略)。设为True则表示忽略索引。 |
其他重要参数通过实例说明。
1.相同字段的表首位相连
首先准备三组DataFrame数据:
import pandas as pd
df1 = pd.DataFrame({‘id’: [‘001’, ‘002’, ‘003’],
‘num1’: [120, 114, 123],
‘num2’: [110, 102, 121],
‘num3’: [113, 124, 128]})
df2 = pd.DataFrame({‘id’: [‘004’, ‘005’],
‘num1’: [120, 101],
‘num2’: [113, 126],
‘num3’: [105, 128]})
df3 = pd.DataFrame({‘id’: [‘007’, ‘008’, ‘009’],
‘num1’: [120, 101, 125],
‘num2’: [113, 126, 163],
‘num3’: [105, 128, 114]})
print(df1)
print(“=======================================”)
print(df2)
print(“=======================================”)
print(df3)

合并
dfs = [df1, df2, df3]
result = pd.concat(dfs)
print(result)

如果想要在合并后,标记一下数据都来自于哪张表或者数据的某类别,则也可以给concat加上 参数keys 。
result = pd.concat(dfs, keys=[‘table1’, ‘table2’, ‘table3’])
print(result)

此时,添加的keys与原来的index组成元组,共同成为新的index。
print(result.index)

2.横向表合并(行对齐)
准备两组DataFrame数据:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
g-blog.csdnimg.cn/img_convert/46506ae54be168b93cf63939786134ca.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)




