
Windows安装Tesseract OCR与Python中使用pytesseract进行文字识别



文章目录
- 前言
- 一、下载并安装Tesseract OCR
- 二、配置环境变量
- 三、Python中安装使用pytesseract
- 总结
前言
Tesseract OCR是一个开源OCR(Optical Character Recognition)引擎,用于从图像中提取文本。Pytesseract是Tesseract OCR的Python封装,它使得在Python中使用Tesseract OCR引擎变得容易。Pytesseract提供了简单的API,帮助开发者轻松地使用Tesseract OCR引擎来实现图像中文本的识别。本文主要介绍了Windows下安装Tesseract OCR、并在Python中使用pytesseract进行本地文字识别的流程。
一、下载并安装Tesseract OCR
在Tesseract OCR下载地址https://digi.bib.uni-mannheim.de/tesseract/下载合适的版本安装包,如下:
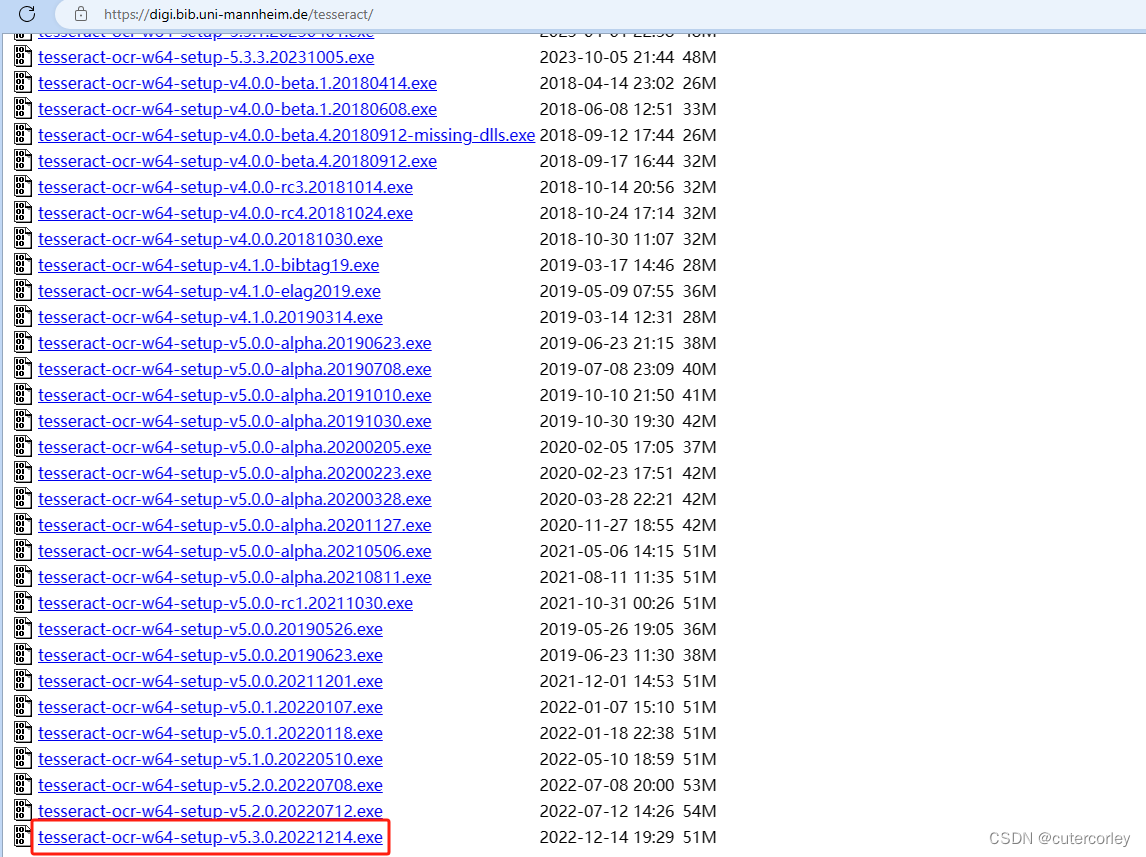
点击安装包进行安装:
语言选择英文:
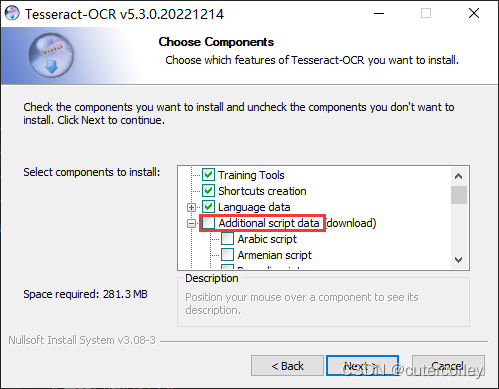
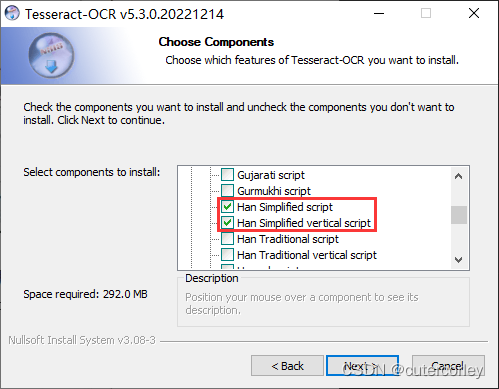
如果需要识别中文,则可以在安装过程中勾选下载中文语言包和脚本(也可以按需选择繁体):
自定义安装路径:
然后一直选择默认选项进行安装即可。
二、配置环境变量
为了方便使用Tesseract,需要将软件安装目录添加到系统环境变量中,这样不必每次执行命令时都切换到Tesseract的安装路径,如下:
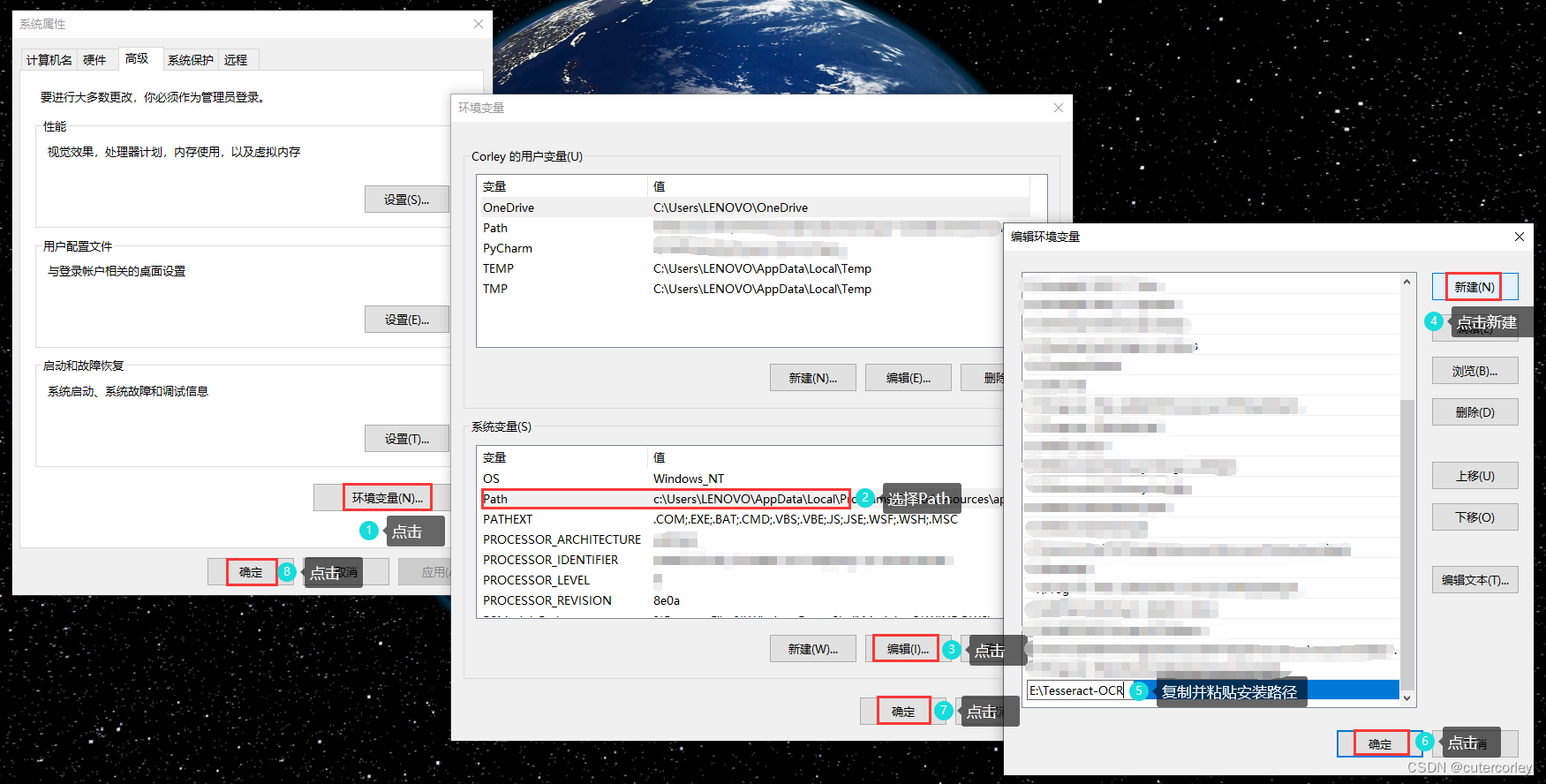
设置确定后之后,可以进行验证,打开CMD,输入tesseract --version,示意如下:
C:\Users\LENOVO>tesseract --version tesseract v5.3.0.20221214 leptonica-1.78.0 libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0 Found AVX2 Found AVX Found FMA Found SSE4.1 Found libarchive 3.5.0 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5 libzstd/1.4.5 Found libcurl/7.77.0-DEV Schannel zlib/1.2.11 zstd/1.4.5 libidn2/2.0.4 nghttp2/1.31.0
如果输出版本等信息,说明安装成功。
三、Python中安装使用pytesseract
Python通过API接入Tesseract OCR,就可以在Python中方便进行文字识别。在使用前需要进行安装,如下:
# 使用conda进行安装 conda install pytesseract -y # 使用pip安装 pip install pytesseract
安装成功即可使用,OCR示例如下:
In [1]: import pytesseract In [2]: import re In [3]: import requests In [4]: from PIL import Image In [5]: url = 'http://42.194.197.95:8001/static/imgs/phone_imgs/phone0.png' In [6]: image = Image.open(requests.get(url, stream=True).raw) In [7]: image Out[7]: In [8]: res = pytesseract.image_to_string(image) In [9]: res Out[9]: '14770126139\n' In [10]: re.search('\d+', res).group() Out[10]: '14770126139'总结
Tesseract OCR是一个本地的图片识别开源引擎,不需要额外的深度学习OCR模型即可实现简单、快速的识别,同时可以通过接口来与多种编程语言对接而集成,可以作为轻量OCR的最佳选择。
文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。



