
Stable Diffusion | Gradio界面设计及webUI API调用
本文基于webUI API编写了类似于webUI的Gradio交互式界面,支持文生图/图生图(SD1.x,SD2.x,SDXL),Embedding,Lora,X/Y/Z Plot,ADetailer、ControlNet,超分放大(Extras),图片信息读取(PNG Info)。
1. 在线体验
本文代码已部署到百度飞桨AI Studio平台,以供大家在线体验Stable Diffusion ComfyUI/webUI 原版界面及自制Gradio界面。
项目链接:Stable Diffusion webUI 在线体验
2. 自制Gradio界面展示
文生图界面:
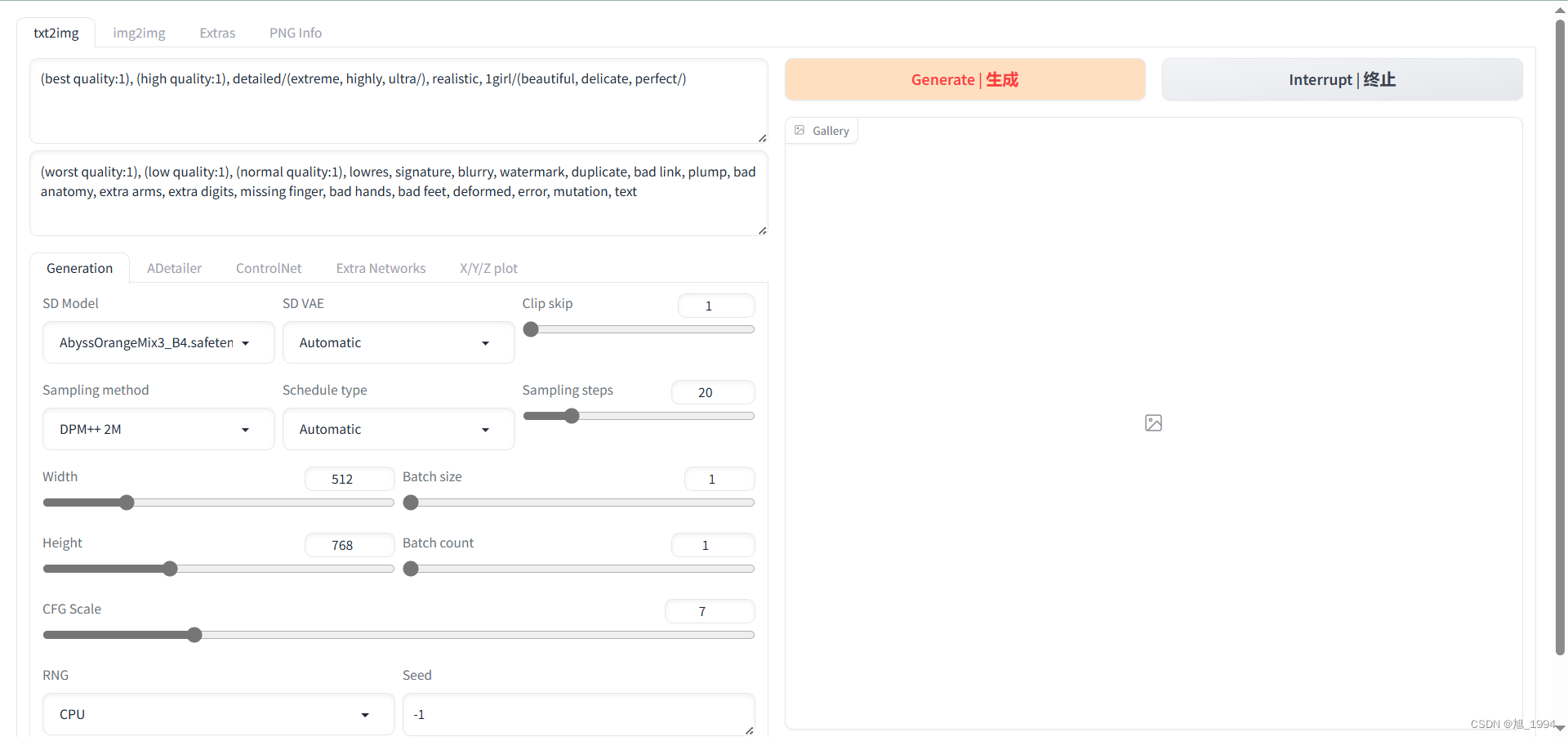
Adetailer 设置界面:
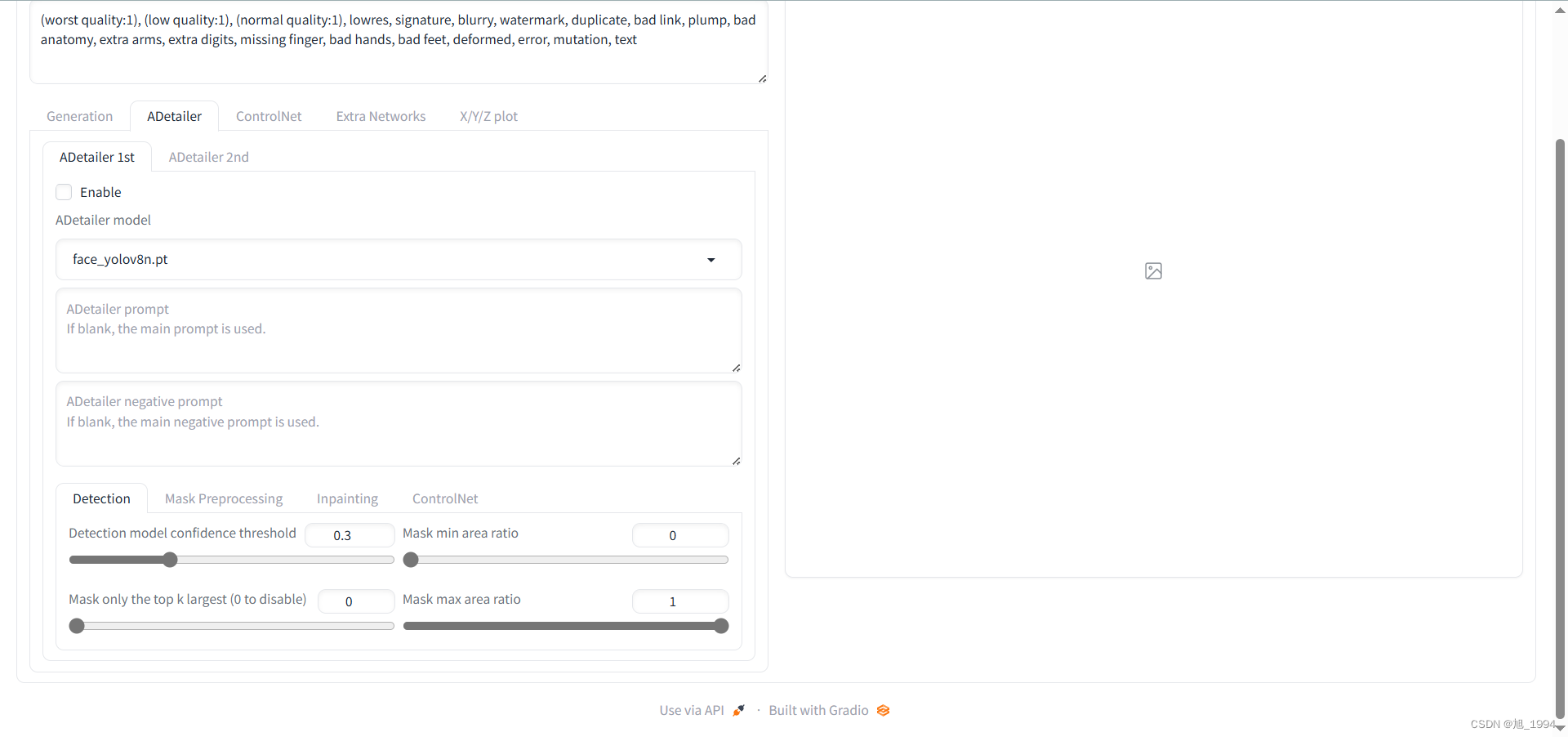
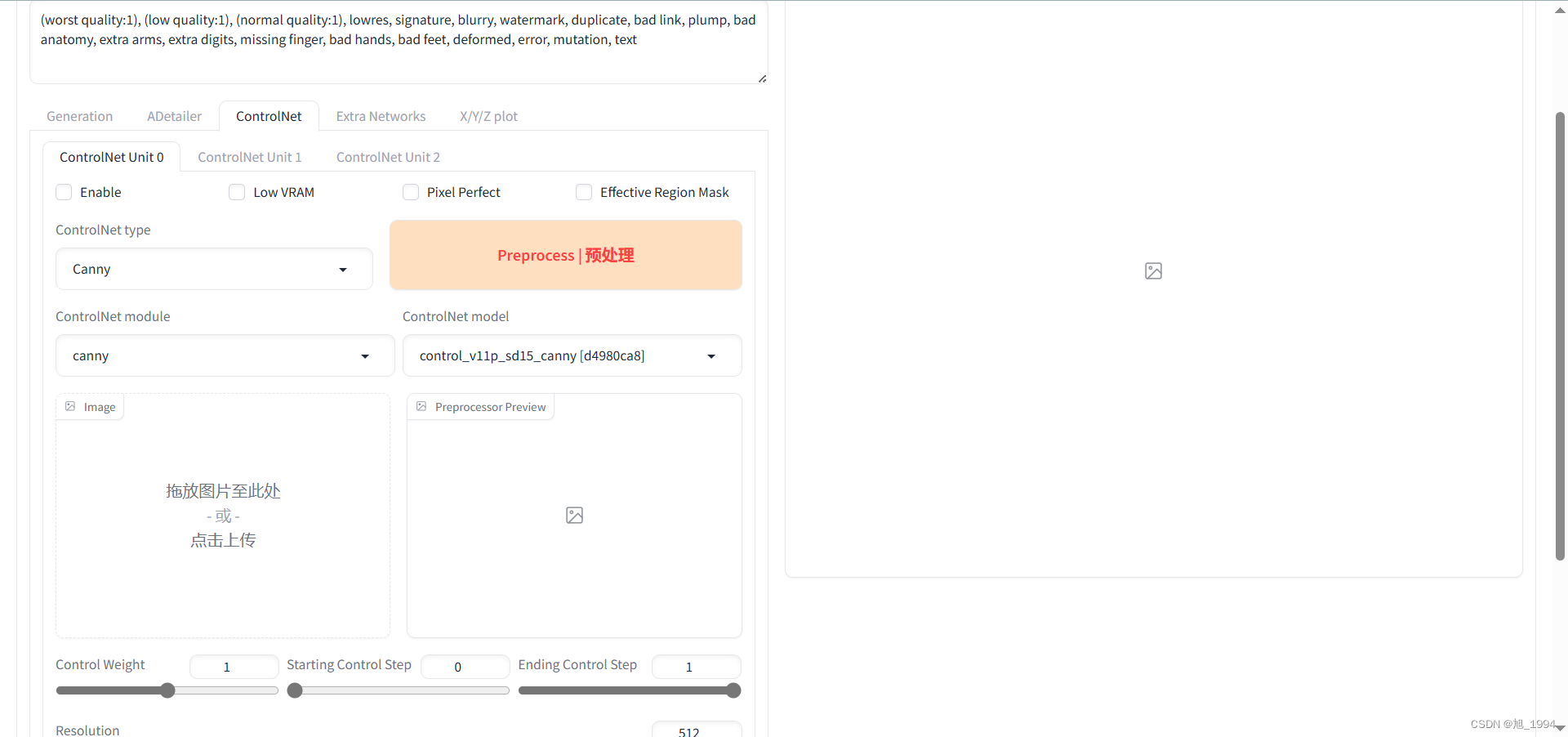
ControlNet 设置界面:
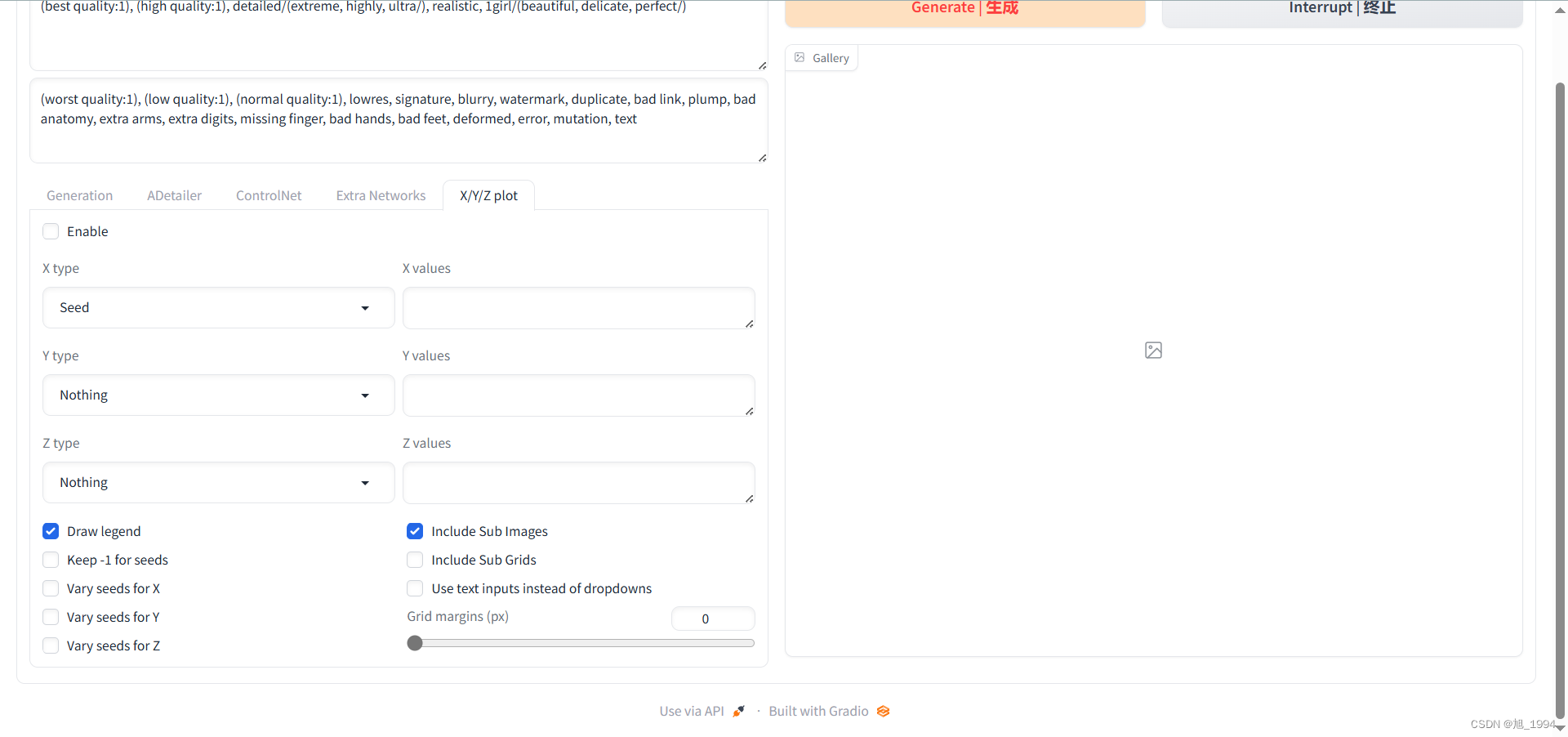
X/Y/Z Plot 设置界面:
图生图界面:
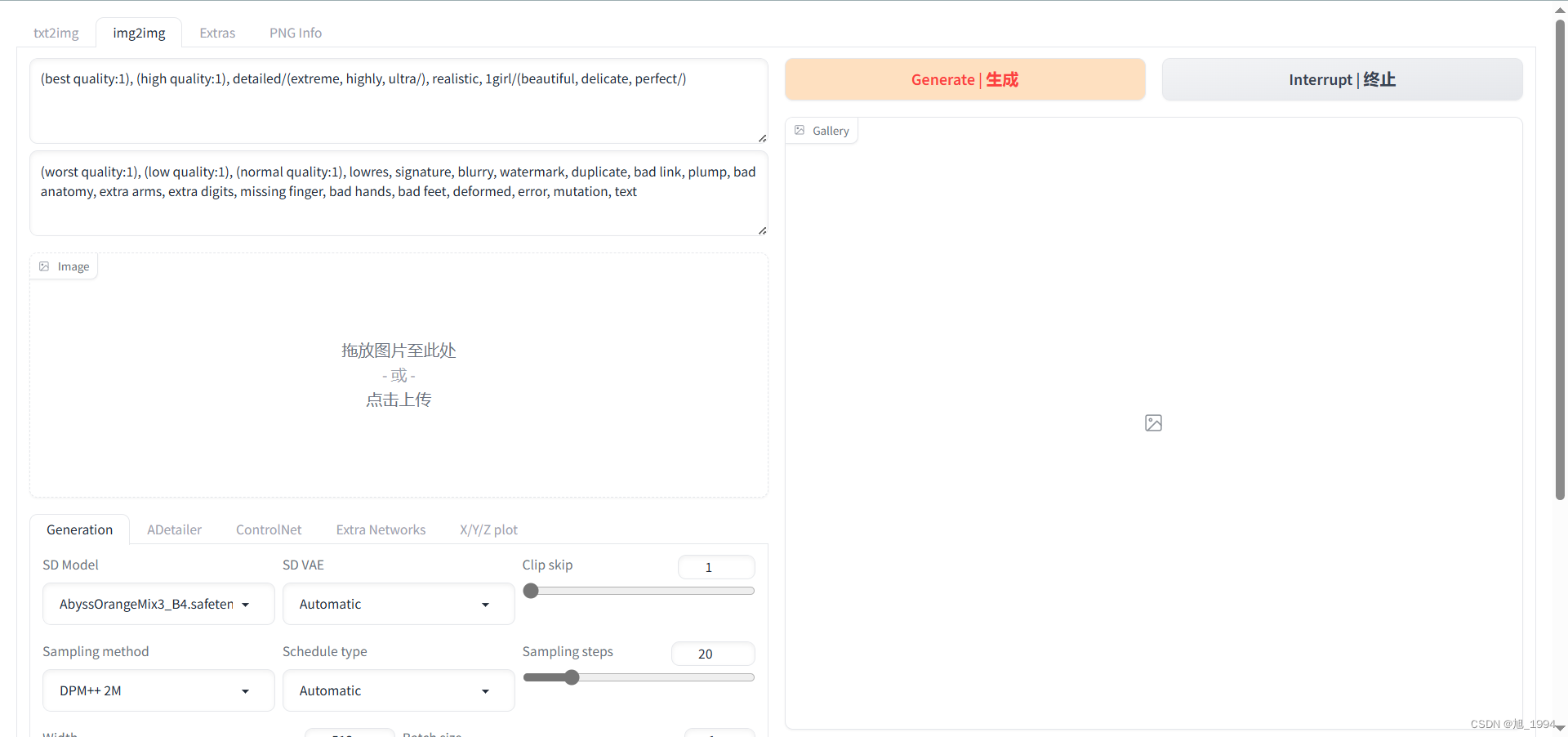
图片放大界面:
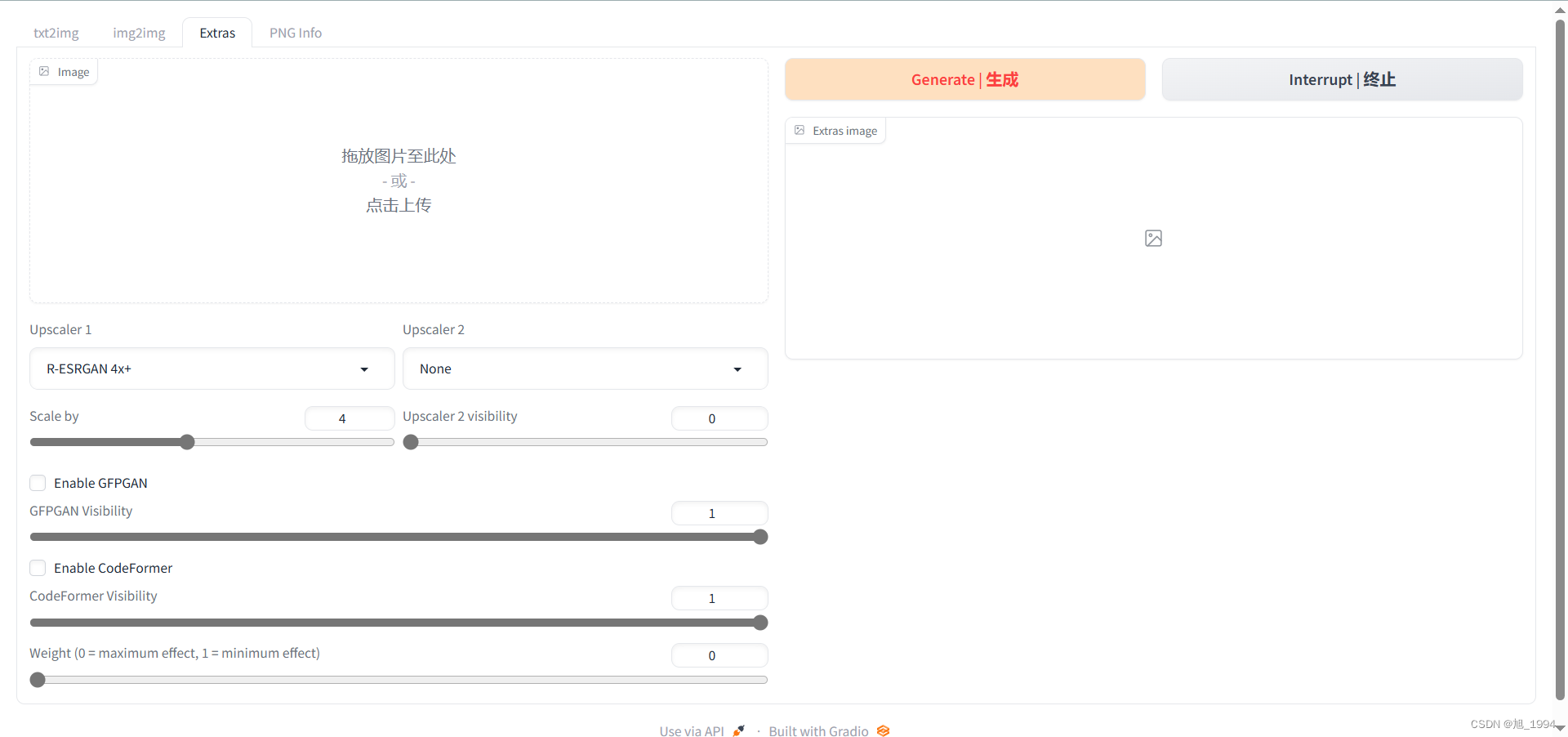
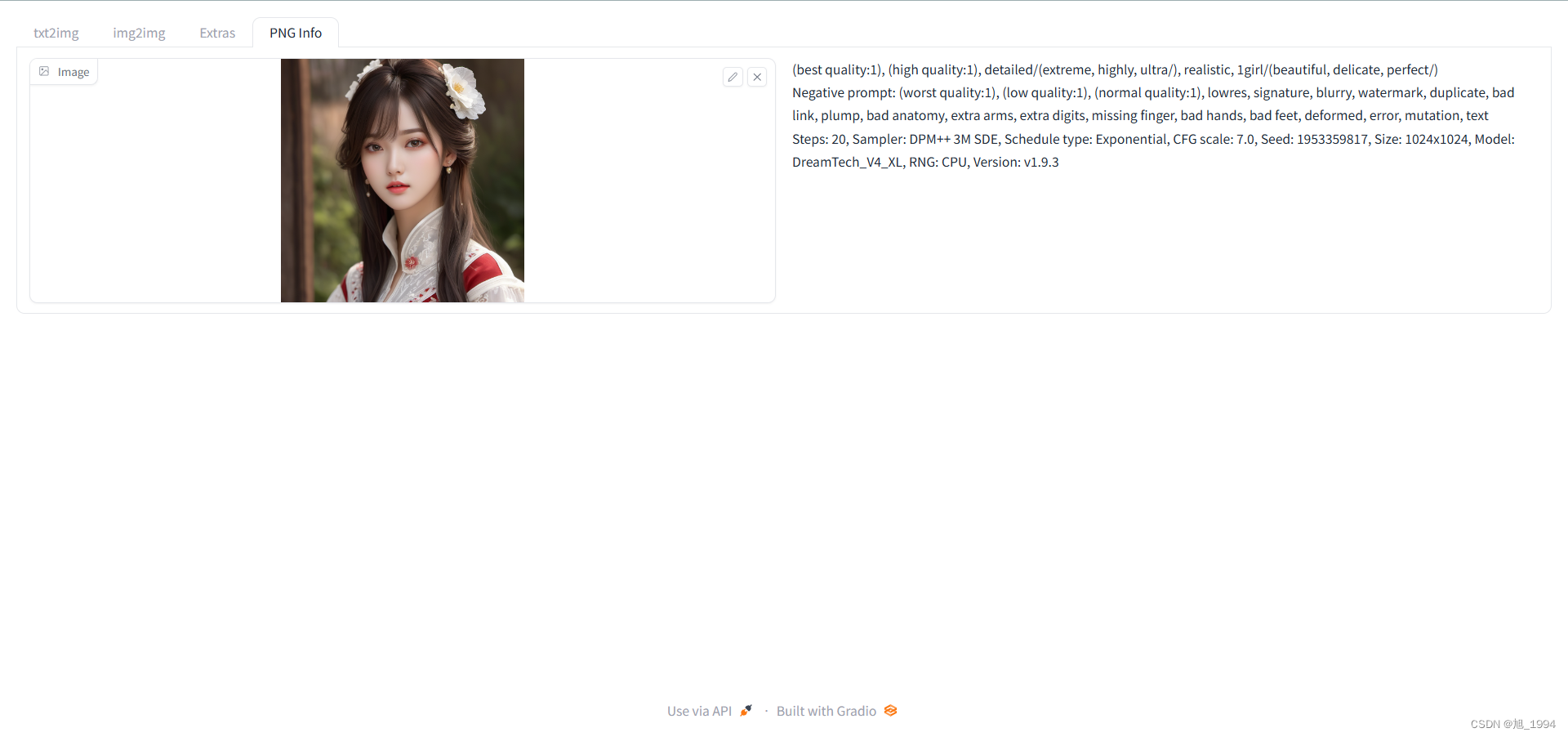
图片信息读取界面:
3. Gradio界面设计及webUI API调用
import base64
import datetime
import io
import os
import re
import subprocess
import gradio as gr
import requests
from PIL import Image, PngImagePlugin
design_mode = 1
save_images = "Yes"
url = "http://127.0.0.1:7860"
if design_mode == 0:
cmd = "netstat -tulnp"
netstat_output = subprocess.run(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True).stdout.splitlines()
for i in netstat_output:
if "stable-diffus" in i:
port = int(re.findall(r'\d+', i)[6])
url = f"http://127.0.0.1:{port}"
output_dir = os.getcwd() + "/output/" + datetime.date.today().strftime("%Y-%m-%d")
os.makedirs(output_dir, exist_ok=True)
os.environ["GRADIO_ANALYTICS_ENABLED"] = "False"
default = {
"prompt": "(best quality:1), (high quality:1), detailed/(extreme, highly, ultra/), realistic, 1girl/(beautiful, delicate, perfect/)",
"negative_prompt": "(worst quality:1), (low quality:1), (normal quality:1), lowres, signature, blurry, watermark, duplicate, bad link, plump, bad anatomy, extra arms, extra digits, missing finger, bad hands, bad feet, deformed, error, mutation, text",
"clip_skip": 1,
"width": 512,
"height": 768,
"size_step": 64,
"steps": 20,
"cfg": 7,
"ad_nums": 2,
"ad_model": ["face_yolov8n.pt", "hand_yolov8n.pt"],
"cn_nums": 3,
"cn_type": "Canny",
"gallery_height": 600,
"lora_weight": 0.8,
"hidden_models": ["stable_cascade_stage_c", "stable_cascade_stage_b", "svd_xt_1_1", "control_v11p_sd15_canny", "control_v11f1p_sd15_depth", "control_v11p_sd15_openpose"]
}
samplers = []
response = requests.get(url=f"{url}/sdapi/v1/samplers").json()
for i in range(len(response)):
samplers.append(response[i]["name"])
schedulers = []
response = requests.get(url=f"{url}/sdapi/v1/schedulers").json()
for i in range(len(response)):
schedulers.append(response[i]["label"])
upscalers = []
response = requests.get(url=f"{url}/sdapi/v1/upscalers").json()
for i in range(len(response)):
upscalers.append(response[i]["name"])
sd_models = []
sd_models_list = {}
response = requests.get(url=f"{url}/sdapi/v1/sd-models").json()
for i in range(len(response)):
path, sd_model = os.path.split(response[i]["title"])
sd_model_name, sd_model_extension = os.path.splitext(sd_model)
if not sd_model_name in default["hidden_models"]:
sd_models.append(sd_model)
sd_models_list[sd_model] = response[i]["title"]
sd_models = sorted(sd_models)
sd_vaes = ["Automatic", "None"]
response = requests.get(url=f"{url}/sdapi/v1/sd-vae").json()
for i in range(len(response)):
sd_vaes.append(response[i]["model_name"])
embeddings = []
response = requests.get(url=f"{url}/sdapi/v1/embeddings").json()
for key in response["loaded"]:
embeddings.append(key)
extensions = []
response = requests.get(url=f"{url}/sdapi/v1/extensions").json()
for i in range(len(response)):
extensions.append(response[i]["name"])
loras = []
loras_name = {}
loras_activation_text = {}
response = requests.get(url=f"{url}/sdapi/v1/loras").json()
for i in range(len(response)):
lora_name = response[i]["name"]
lora_info = requests.get(url=f"{url}/tacapi/v1/lora-info/{lora_name}").json()
if lora_info and "sd version" in lora_info:
lora_type = lora_info["sd version"]
lora_name_type = f"{lora_name} ({lora_type})"
else:
lora_name_type = f"{lora_name}"
loras.append(lora_name_type)
loras_name[lora_name_type] = lora_name
if "activation text" in loras_activation_text:
loras_activation_text[lora_name_type] = lora_info["activation text"]
xyz_args = {}
xyz_plot_types = {}
last_choice = "Size"
response = requests.get(url=f"{url}/sdapi/v1/script-info").json()
for i in range(len(response)):
if response[i]["name"] == "x/y/z plot":
if response[i]["is_img2img"] == False:
xyz_plot_types["txt2img"] = response[i]["args"][0]["choices"]
choice_index = xyz_plot_types["txt2img"].index(last_choice) + 1
xyz_plot_types["txt2img"] = xyz_plot_types["txt2img"][:choice_index]
else:
xyz_plot_types["img2img"] = response[i]["args"][0]["choices"]
choice_index = xyz_plot_types["img2img"].index(last_choice) + 1
xyz_plot_types["img2img"] = xyz_plot_types["img2img"][:choice_index]
if "adetailer" in extensions:
ad_args = {"txt2img": {}, "img2img": {}}
ad_skip_img2img = False
ad_models = ["None"]
response = requests.get(url=f"{url}/adetailer/v1/ad_model").json()
for key in response["ad_model"]:
ad_models.append(key)
if "sd-webui-controlnet" in extensions:
cn_args = {"txt2img": {}, "img2img": {}}
cn_types = []
cn_types_list = {}
response = requests.get(url=f"{url}/controlnet/control_types").json()
for key in response["control_types"]:
cn_types.append(key)
cn_types_list[key] = response["control_types"][key]
cn_default_type = default["cn_type"]
cn_module_list = cn_types_list[cn_default_type]["module_list"]
cn_model_list = cn_types_list[cn_default_type]["model_list"]
cn_default_option = cn_types_list[cn_default_type]["default_option"]
cn_default_model = cn_types_list[cn_default_type]["default_model"]
def save_image(image, part1, part2):
counter = 1
image_name = f"{part1}-{part2}-{counter}.png"
while os.path.exists(os.path.join(output_dir, image_name)):
counter += 1
image_name = f"{part1}-{part2}-{counter}.png"
image_path = os.path.join(output_dir, image_name)
image_metadata = PngImagePlugin.PngInfo()
for key, value in image.info.items():
if isinstance(key, str) and isinstance(value, str):
image_metadata.add_text(key, value)
image.save(image_path, format="PNG", pnginfo=image_metadata)
def pil_to_base64(image_pil):
buffer = io.BytesIO()
image_pil.save(buffer, format="png")
image_buffer = buffer.getbuffer()
image_base64 = base64.b64encode(image_buffer).decode("utf-8")
return image_base64
def base64_to_pil(image_base64):
image_binary = base64.b64decode(image_base64)
image_pil = Image.open(io.BytesIO(image_binary))
return image_pil
def format_prompt(prompt):
prompt = re.sub(r"\s+,", ",", prompt)
prompt = re.sub(r"\s+", " ", prompt)
prompt = re.sub(",,+", ",", prompt)
prompt = re.sub(",", ", ", prompt)
prompt = re.sub(r"\s+", " ", prompt)
prompt = re.sub(r"^,", "", prompt)
prompt = re.sub(r"^ ", "", prompt)
prompt = re.sub(r" $", "", prompt)
prompt = re.sub(r",$", "", prompt)
prompt = re.sub(": ", ":", prompt)
return prompt
def post_interrupt():
global interrupt
interrupt = True
requests.post(url=f"{url}/sdapi/v1/interrupt").json()
def gr_update_visible(visible):
return gr.update(visible=visible)
def ordinal(n: int) -> str:
d = {1: "st", 2: "nd", 3: "rd"}
return str(n) + ("th" if 11 = 0:
gen_type = "img2img"
if input_image is None:
return None, None, None
else:
gen_type = "txt2img"
progress(0, desc=f"Loading {sd_model}")
payload = {
"sd_model_checkpoint": sd_models_list[sd_model],
"sd_vae": sd_vae,
"CLIP_stop_at_last_layers": clip_skip,
"randn_source": randn_source
}
requests.post(url=f"{url}/sdapi/v1/options", json=payload)
if interrupt == True:
return None, None, None
progress(0, desc="Processing...")
images = []
images_info = []
if not input_image is None:
input_image = pil_to_base64(input_image)
for i in range(batch_count):
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"batch_size": batch_size,
"seed": seed,
"sampler_name": sampler_name,
"scheduler": scheduler,
"steps": steps,
"cfg_scale": cfg_scale,
"width": width,
"height": height,
"init_images": [input_image],
"denoising_strength": denoising_strength,
"alwayson_scripts": {}
}
if "adetailer" in extensions:
payload = add_adetailer(payload, gen_type)
if "sd-webui-controlnet" in extensions:
payload = add_controlnet(payload, gen_type)
payload = add_xyz_plot(payload, gen_type)
response = requests.post(url=f"{url}/sdapi/v1/{gen_type}", json=payload)
images_base64 = response.json()["images"]
for j in range(len(images_base64)):
image_pil = base64_to_pil(images_base64[j])
images.append(image_pil)
image_info = get_png_info(image_pil)
images_info.append(image_info)
if image_info == "None":
if save_images == "Yes":
if gen_type in xyz_args:
save_image(image_pil, "XYZ_Plot", "grid")
else:
save_image(image_pil, "ControlNet", "detect")
else:
seed = re.findall("Seed: [0-9]+", image_info)[0].split(": ")[-1]
if save_images == "Yes":
save_image(image_pil, sd_model, seed)
seed = int(seed) + 1
progress((i+1)/batch_count, desc=f"Batch count: {(i+1)}/{batch_count}")
if interrupt == True:
return images, images_info, datetime.datetime.now()
return images, images_info, datetime.datetime.now()
def gen_clear_geninfo():
return None
def gen_update_geninfo(images_info):
if images_info == [] or images_info is None:
return None
return images_info[0]
def gen_update_selected_geninfo(images_info, evt: gr.SelectData):
return images_info[evt.index]
def gen_blocks(gen_type):
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
prompt = gr.Textbox(placeholder="Prompt", show_label=False, value=default["prompt"], lines=3)
negative_prompt = gr.Textbox(placeholder="Negative prompt", show_label=False, value=default["negative_prompt"], lines=3)
if gen_type == "txt2img":
input_image = gr.Image(visible=False)
else:
input_image = gr.Image(type="pil")
with gr.Tab("Generation"):
with gr.Row():
sd_model = gr.Dropdown(sd_models, label="SD Model", value=sd_models[0])
sd_vae = gr.Dropdown(sd_vaes, label="SD VAE", value=sd_vaes[0])
clip_skip = gr.Slider(minimum=1, maximum=12, step=1, label="Clip skip", value=default["clip_skip"])
with gr.Row():
sampler_name = gr.Dropdown(samplers, label="Sampling method", value=samplers[0])
scheduler = gr.Dropdown(schedulers, label="Schedule type", value=schedulers[0])
steps = gr.Slider(minimum=1, maximum=100, step=1, label="Sampling steps", value=default["steps"])
with gr.Row():
width = gr.Slider(minimum=64, maximum=2048, step=default["size_step"], label="Width", value=default["width"])
batch_size = gr.Slider(minimum=1, maximum=8, step=1, label="Batch size", value=1)
with gr.Row():
height = gr.Slider(minimum=64, maximum=2048, step=default["size_step"], label="Height", value=default["height"])
batch_count = gr.Slider(minimum=1, maximum=100, step=1, label="Batch count", value=1)
with gr.Row():
cfg_scale = gr.Slider(minimum=1, maximum=30, step=0.5, label="CFG Scale", value=default["cfg"])
if gen_type == "txt2img":
denoising_strength = gr.Slider(minimum=-1, maximum=1, step=1, value=-1, visible=False)
else:
denoising_strength = gr.Slider(minimum=0.0, maximum=1.0, step=0.01, label="Denoising strength", value=0.7)
with gr.Row():
randn_source = gr.Dropdown(["CPU", "GPU"], label="RNG", value="CPU")
seed = gr.Textbox(label="Seed", value=-1)
if "adetailer" in extensions:
with gr.Tab("ADetailer"):
if gen_type == "img2img":
with gr.Row():
ad_skip_img2img = gr.Checkbox(label="Skip img2img", visible=True)
ad_skip_img2img.change(fn=ad_update_skip_img2img, inputs=ad_skip_img2img, outputs=None)
for i in range(default["ad_nums"]):
with gr.Tab(f"ADetailer {ordinal(i + 1)}"): ad_blocks(i, gen_type)
if "sd-webui-controlnet" in extensions:
with gr.Tab("ControlNet"):
for i in range(default["cn_nums"]):
with gr.Tab(f"ControlNet Unit {i}"): cn_blocks(i, gen_type)
if not loras == [] or not embeddings == []:
with gr.Tab("Extra Networks"):
if not loras == []:
lora = gr.Dropdown(loras, label="Lora", multiselect=True, interactive=True)
lora.change(fn=add_lora, inputs=[prompt, lora], outputs=prompt)
if not embeddings == []:
embedding = gr.Dropdown(embeddings, label="Embedding", multiselect=True, interactive=True)
embedding.change(fn=add_embedding, inputs=[negative_prompt, embedding], outputs=negative_prompt)
with gr.Tab("X/Y/Z plot"): xyz_blocks(gen_type)
with gr.Column():
with gr.Row():
btn = gr.Button("Generate | 生成", elem_id="button")
btn2 = gr.Button("Interrupt | 终止")
gallery = gr.Gallery(preview=True, height=default["gallery_height"])
image_geninfo = gr.Markdown()
images_geninfo = gr.State()
update_geninfo = gr.Textbox(visible=False)
gen_inputs = [input_image, sd_model, sd_vae, sampler_name, scheduler, clip_skip, steps, width, batch_size, height, batch_count, cfg_scale, randn_source, seed, denoising_strength, prompt, negative_prompt]
btn.click(fn=gen_clear_geninfo, inputs=None, outputs=image_geninfo)
btn.click(fn=generate, inputs=gen_inputs, outputs=[gallery, images_geninfo, update_geninfo])
btn2.click(fn=post_interrupt, inputs=None, outputs=None)
gallery.select(fn=gen_update_selected_geninfo, inputs=images_geninfo, outputs=image_geninfo)
update_geninfo.change(fn=gen_update_geninfo, inputs=images_geninfo, outputs=image_geninfo)
return demo
def extras(input_image, upscaler_1, upscaler_2, upscaling_resize, extras_upscaler_2_visibility, enable_gfpgan, gfpgan_visibility, enable_codeformer, codeformer_visibility, codeformer_weight):
if input_image is None:
return None
input_image = pil_to_base64(input_image)
if enable_gfpgan == False:
gfpgan_visibility = 0
if enable_codeformer == False:
codeformer_visibility = 0
payload = {
"gfpgan_visibility": gfpgan_visibility,
"codeformer_visibility": codeformer_visibility,
"codeformer_weight": codeformer_weight,
"upscaling_resize": upscaling_resize,
"upscaler_1": upscaler_1,
"upscaler_2": upscaler_2,
"extras_upscaler_2_visibility": extras_upscaler_2_visibility,
"image": input_image
}
response = requests.post(url=f"{url}/sdapi/v1/extra-single-image", json=payload)
images_base64 = response.json()["image"]
image_pil = base64_to_pil(images_base64)
if save_images == "Yes":
save_image(image_pil, "Extras", "image")
return image_pil
def extras_blocks():
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
input_image = gr.Image(type="pil")
with gr.Row():
upscaler_1 = gr.Dropdown(upscalers, label="Upscaler 1", value="R-ESRGAN 4x+")
upscaler_2 = gr.Dropdown(upscalers, label="Upscaler 2", value="None")
with gr.Row():
upscaling_resize = gr.Slider(minimum=1, maximum=8, step=0.05, label="Scale by", value=4)
extras_upscaler_2_visibility = gr.Slider(minimum=0, maximum=1, step=0.001, label="Upscaler 2 visibility", value=0)
enable_gfpgan = gr.Checkbox(label="Enable GFPGAN")
gfpgan_visibility = gr.Slider(minimum=0, maximum=1, step=0.001, label="GFPGAN Visibility", value=1)
enable_codeformer = gr.Checkbox(label="Enable CodeFormer")
codeformer_visibility = gr.Slider(minimum=0, maximum=1, step=0.001, label="CodeFormer Visibility", value=1)
codeformer_weight = gr.Slider(minimum=0, maximum=1, step=0.001, label="Weight (0 = maximum effect, 1 = minimum effect)", value=0)
with gr.Column():
with gr.Row():
btn = gr.Button("Generate | 生成", elem_id="button")
btn2 = gr.Button("Interrupt | 终止")
extra_image = gr.Image(label="Extras image")
btn.click(fn=extras, inputs=[input_image, upscaler_1, upscaler_2, upscaling_resize, extras_upscaler_2_visibility, enable_gfpgan, gfpgan_visibility, enable_codeformer, codeformer_visibility, codeformer_weight], outputs=extra_image)
btn2.click(fn=post_interrupt, inputs=None, outputs=None)
return demo
def get_png_info(image_pil):
image_info=[]
if image_pil is None:
return None
for key, value in image_pil.info.items():
image_info.append(value)
if not image_info == []:
image_info = image_info[0]
image_info = re.sub(r"", image_info)
image_info = re.sub(r"\n", "
", image_info)
else:
image_info = "None"
return image_info
def png_info_blocks():
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
input_image = gr.Image(value=None, type="pil")
with gr.Column():
png_info = gr.Markdown()
input_image.change(fn=get_png_info, inputs=input_image, outputs=png_info)
return demo
with gr.Blocks(css="#button {background: #FFE1C0; color: #FF453A} .block.padded:not(.gradio-accordion) {padding: 0 !important;} div.form {border-width: 0; box-shadow: none; background: white; gap: 0.5em;}") as demo:
with gr.Tab("txt2img"): gen_blocks("txt2img")
with gr.Tab("img2img"): gen_blocks("img2img")
with gr.Tab("Extras"): extras_blocks()
with gr.Tab("PNG Info"): png_info_blocks()
demo.queue(concurrency_count=100).launch(inbrowser=True)
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



