
IoTDB 入门教程 基础篇①——时序数据库为什么选IoTDB ?



文章目录
- 一、前文
- 二、性能排行第一
- 三、完全开源
- 四、数据文件TsFile
- 五、乱序数据高写入
- 六、其他
- 七、参考
一、前文
IoTDB入门教程——导读
关注博主的同学都知道,博主在物联网领域深耕多年。
时序数据库,博主已经用过很多,从最早的InfluxDB,到后期的TDengine,以及现在的IoTDB。
- 最早是没得选,只能用InfluxDB。
- 后面是有的选,换了TDengine。
- 现在是选择太多,择优选了IoTDB。
各个时序数据库的厂家,随着版本更新,性能越来越强,越来越好用,也越来越易用。
本文主要讲述IoTDB的优势,时序数据库选择困难症的同学可以看看。已经选定IoTDB的同学可以直接看后面的应用实战。
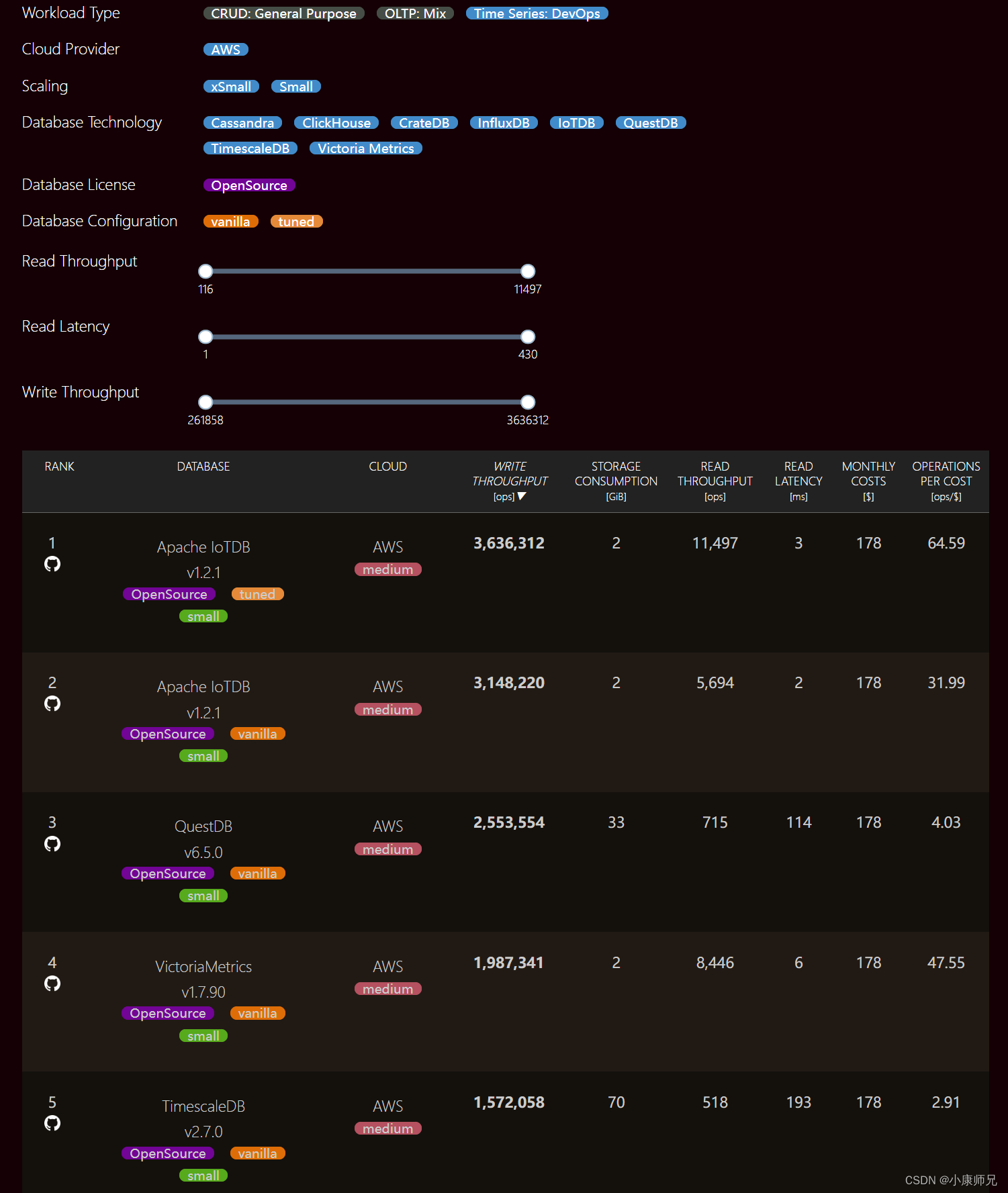
二、性能排行第一
正如俗语所言:“是骡子是马,拉出来遛遛。”
benchANT,一家位于德国的权威机构,专注于云设施和数据库性能评估。
benchANT 数据库性能排行榜链接:https://benchant.com/ranking/database-ranking
Workload Type选择Time Series: DevOps。
时序数据的特点显著,包括测量点众多、上报频率高以及数据规模庞大等。
因此,时序数据库面临的挑战也不容小觑:必须保证高频写入的速度、海量数据查询的迅捷以及数据存储成本的优化。
鉴于这些独特的需求,选择性能强大的时序数据库变得至关重要。
毕竟,如果MySQL能够满足这些要求,我们也不会特意去寻找更适合的时序数据库了。
三、完全开源
-
从数据文件到分布式,不依赖第三方系统,国产自研,完全开源。
-
Apache 基金会唯一时序数据库 Top-Level 项目Apache / IoTDB。
-
产学研结合, 拥有 30+ 时序数据管理领域发明专利,在数据库顶会发表 10+ 篇论文。
-
发源于清华大学,其核心团队成立了天谋科技(北京)有限公司,专注 IoTDB 产品的打磨。
四、数据文件TsFile
物联网时序数据文件格式:Apache / TsFile
众所周知,数据文件如何高效的压缩和读写是数据库设计的一大关键。
而数据文件又处于很底层,大部分数据库厂家不对外提供这方面的资料。
但是IoTDB却把这方面的项目独立出来,成为又一个Apache Top-Level 项目Apache / TsFile。实在是不得不佩服。
TsFile是一种为时间序列数据设计的列式存储文件格式,它支持高效压缩、高读写吞吐量,并且兼容多种框架,如Spark和Flink。TsFile很容易集成到物联网大数据处理框架中。
- 高效的存储和压缩:TsFile采用了先进的压缩技术来最大限度地减少存储需求,从而减少了磁盘空间消耗并提高了系统效率。
- 灵活元数据组织管理:TsFile允许在不预先定义模式的情况下直接写入数据,支持数据灵活获取。
- 高性能时间范围查询:高性能时间范围查询
- 大数据生态无缝集成:TsFile能够与现有的时间序列数据库(如IoTDB)、数据处理框架(如Spark和Flink)无缝集成。
TsFile API 快速上手
讲到这里又不得不提到TDengine,TDengine虽然版本更新很快,性能也很强。
但是他们底层数据文件也经常修改,不仅2.x与3.x版本的数据文件不兼容,3.0.0.1版本与3.0.2.0版本的数据文件也不兼容。
因为3.0.0.1的底层数据文件不稳定,所以后面版本就及时做了大改,所以导致的不兼容。
底层数据文件不稳定就很容易出现大问题,数据丢失,数据无法正常迁移等等。
这里也没有踩踏TDengine的意思,TDengine也很好,只不过通过对比,感觉IoTDB更好。
一群清华的硕士博士做出来的东西,确实靠谱。
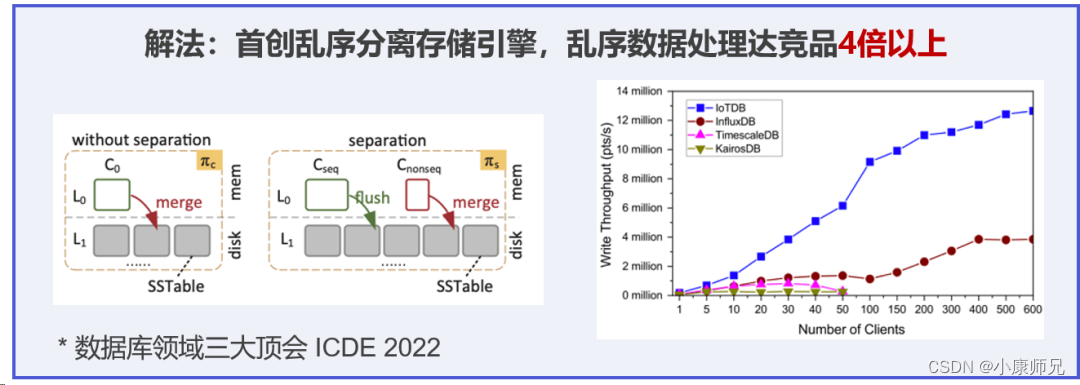
五、乱序数据高写入
IoTDB不仅支持高频的数据写入,还支持乱序数据写入。
乱序数据是指:早产生的数据后到了,晚产生的数据先到了
这是我们在实际应用中经常遇到的场景,会带来一些困扰,虽然不痛,但也很烦。
IoTDB首创了乱序分离存储引擎用独有的顺乱序判断的机制,将顺序数据与乱序数据分开,并通过多种空间合并的方法,去消除乱序数据。
六、其他
IoTDB不仅功能丰富,而且具有诸多优势和亮点。只不过这些博主目前暂时用不到,所以这里就快速过一下,留个印象,后面实际项目有需要的时候自然会想起来。
- 全面的端-边-云协同模式:IoTDB支持边缘模式、单机模式以及分布式架构,为用户提供了灵活多样的部署选项。
- 专为物联网打造:IoTDB拥有设备测点物联网数据模型、IoTLSM物联网存储引擎和IoTConsensus物联网共识协议,确保数据在物联网环境中的高效管理和传输。
- 卓越的性能表现:通过已有案例展示,IoTDB能够轻松管理亿级序列,实现数千万点/秒的吞吐能力,并提供高达十倍的压缩比,大大提升了数据处理效率。
- 树形时序数据模型:IoTDB采用树形结构进行时序数据建模,确保这些关键数据能够被有效、有序地管理和查询。
- 智能分析功能(AINode):IoTDB积极拥抱AI技术,提供了智能化的分析功能。它涵盖了多种适用于时序数据的算法和自研模型,能够实现序列预测、异常检测等高级分析场景,为用户提供深入的洞察力。
- 强大的处理能力:IoTDB支持丰富的时序特性查询和分析功能,满足用户在各种复杂场景下的数据处理需求。
七、参考
时序数据库IoTDB:功能详解与行业应用
觉得好,就一键三连呗(点赞+收藏+关注)
-


